https://arxiv.org/abs/2305.15614
Abstract
- Self-supervised learning (SSL)은 기계 학습에서 강력한 도구이지만, 학습된 representation과 그 기반이 되는 메커니즘을 이해하는 것은 여전히 어려운 과제
- 본 논문은 다양한 모델, 아키텍처 및 하이퍼파라미터를 포괄하는 SSL로 훈련된 representation에 대한 깊은 경험적 분석을 제시
- SSL 훈련 과정에서 semantic label에 따라 샘플을 클러스터링하는 것을 자연스럽게 용이하게 만든다는 점을 밝혀냄
- 이는 SSL 목표의 regularization term에 의해 놀랍게도 주도됨
- 이 클러스터링 과정은 downstream task를 향상시키는 데 뿐만 아니라 데이터 정보를 압축하는 데도 기여
- 더 나아가, SSL로 훈련된 representation이 random class보다 semantic class와 더 밀접하게 일치한다는 것을 입증
- 이 논문의 연구 결과는 SSL의 representation에 학습 메커니즘과 다양한 클래스 세트에 대한 성능에 미치는 영향에 대한 유용한 통찰력을 제공
1. Introduction
- SSL은 지난 몇 년 동안 상당한 진전을 이루어 왔으며, 많은 downstream task에서 supervised baseline의 성능에 거의 근접하고 있음
- 그러나 모델의 복잡성과 labeled training data의 부족으로 인해 학습된 representation과 그 기반이 되는 메커니즘을 이해하는 것은 계속된 어려움을 겪고 있음
- 더구나, SSL에서 사용되는 pretext task은 종종 특정 downstream task과 직접적인 관련성이 부족하여 학습된 representation을 해석하는 것을 더욱 복잡하게 만듦
- 그러나 Supervised classification에서 학습된 representation의 구조는 종종 매우 간단
- 최근 연구에서는 학습의 최종 단계에서 발생하는 "신경 붕괴(neural collapse)"라는 범용적인 현상을 관찰
- 신경 붕괴는 최상위 레이어 임베딩의 여러 속성을 드러냄
- 예를 들어, 같은 클래스의 샘플을 같은 점에 매핑하고 클래스 간의 margin을 최대화하며 activation과 최상위 레이어 weight matrix 간의 특정 이중성을 강조
- 나중에 수행된 연구에서는 네트워크의 중간 레이어에서 관련된 속성을 특성화하였음
- 현대적인 SSL 알고리즘은 일반적으로 두 가지 중요한 구성 요소를 결합한 loss function를 최소화
- 하나는 증강된 샘플을 클러스터링하는 데 사용되는 것 (invariance constraint)
- 하나는 representation collapse를 방지하는 데 사용되는 것 (regularization constraint)
Main contribution
1) Clustering
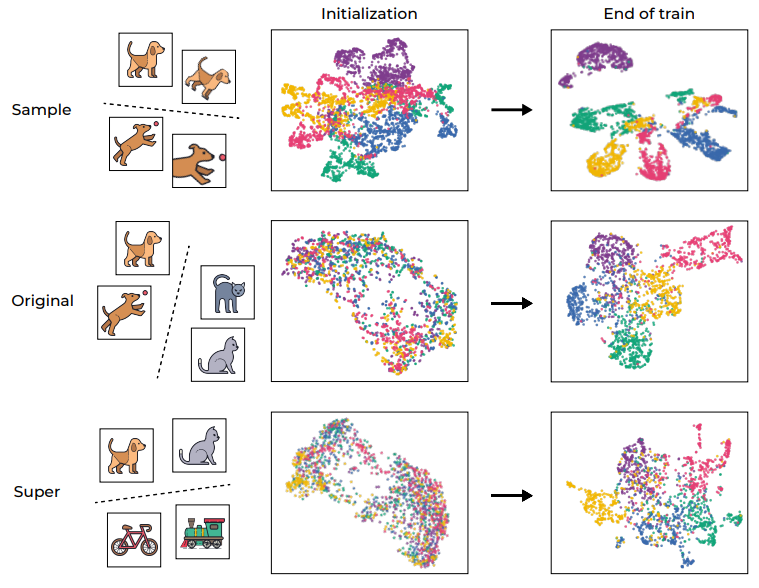
- 그림에서 볼 수 있듯이, supervised classification와 유사하게, SSL로 훈련된 representation function는 증강된 훈련 샘플의 feature 임베딩이 같은 이미지에 속하는 경우 해당 평균 주변에 클러스터링되는 중심점과 유사한 기하학적 구조를 보임
- 흥미로운 점은 학습의 후반부에서 semantic class에 대한 비슷한 추세도 나타난다는 것
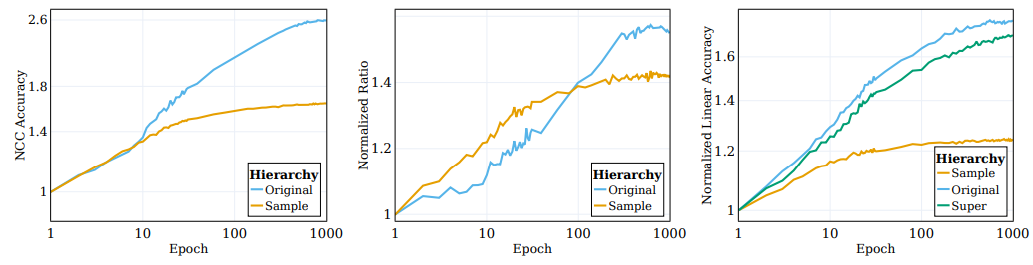
- 그림 (가운데)에서 sample-level 클래스와 원래 대상에 대한 이 비율을 모니터링하며 초기화 값에 대한 정규화 값을 사용
- SSL 학습이 진행됨에 따라 NCC 정확도와 linear 정확도 간의 차이가 좁아지면서, 증강된 샘플이 점점 sample identify 정보와 semantic 속성을 기반으로 더 많이 클러스터링됨을 나타냄
2) The role of regularization
- (그림 왼쪽) SSL로 학습된 representation에서 semantic class를 추출하는 정확도는 샘플 식별 정보에 기반하여 증강된 훈련 샘플을 클러스터링한 후에도 계속해서 향상되는 것을 보여줌
- 보이는 바와 같이, 정규화 제약은 데이터를 임베딩 공간에서 semantic 속성으로 클러스터링하는 데 중요한 역할을 함
3) Impact of randomness
- SSL로 학습된 representation function은 semantic class와 높은 상관 관계를 가짐
- 이 주장을 뒷받침하기 위해, 목표값의 무작위성이 미리 학습된 representation으로부터 학습 능력에 어떻게 영향을 미치는지를 연구
- 그림에서 보듯이, 목표값이 덜 무작위적이고 의미적으로 더 의미 있는 방향으로 향할수록 목표값과 학습된 representation 간의 정렬이 크게 향상됩
4) Learning hierarchic representations
- SSL 알고리즘들이 계층적 클래스를 나타내는 representation을 어떻게 배우는지 연구
- sample level (sample identity), semantic class (다른 종류의 동물과 차량과 같은) 및 high-level class (예: 동물 및 차량)와 같은 여러 계층을 고려
- 그림에 나와 있는 것처럼 네트워크 내부로 깊이 들어갈수록 각 층의 군집화 및 분리 능력이 향상되는 것을 관찰
2. Background and Related Work
1) Self-Supervised Learning
1-1) Variance-Invariance-Covariance Regularization (VICReg)
-
VICReg은 SSL 학습에 널리 사용되는 방법으로, 입력 데이터와 해당 데이터의 증강된 버전에 대한 representation을 생성. VICReg은 두 가지 주요 측면을 최적화하려고 함:
-
불변성 손실 (Invariance loss) - 임베딩 쌍 간의 평균 제곱 유클리드 거리로, 원본 입력과 증강된 입력의 representation 간의 일관성을 보장
-
정규화 (Regularization) - 두 요소로 구성되며, 분산 손실 (variance loss)은 표준 편차를 제약하는 힌지 손실(hinge loss)을 통해 배치 차원에서 분산을 증가시키는 것을 촉진하며, 공분산 손실 (covariance loss)은 임베딩의 공분산 행렬의 비대각 원소에 패널티를 부여하여 특성 간의 상관성을 줄이려고 함
-
이로써 VICReg 손실 함수가 생성
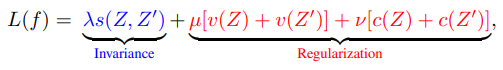
1-2) A Simple Framework for Contrastive Learning of Visual Representations (SimCLR)
- SimCLR은 대조 손실 함수(contrastive loss function)를 최소화하는 또 다른 인기 있는 접근 방식
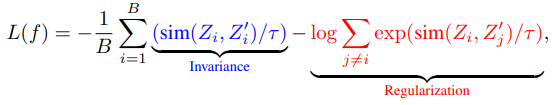
2) Neural Collapse and Clustering
- 최근 논문 [Papyan et al., 2020]에서는 classification task 용으로 학습된 deep 네트워크가 주목할만한 행동을 나타내는 것이 확인
- 이는 동일한 클래스의 학습 샘플의 최상위 레이어 feature 임베딩이 해당 클래스의 평균 주변에 집중되는 경향을 보인다는 것
- 본 논문에서는 SSL로 학습된 representation 함수에서 유사한 군집화 경향이 sample-level(증강에 관한)과 semantic-level 양쪽에서 발생하는지 여부를 탐구하고자 함
- 이러한 속성을 측정하기 위해 다음과 같은 metric을 사용
- class-distance normalized variance (CDNV)
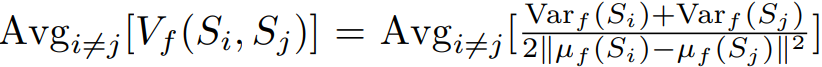
- 여기서 µf(S)와 Varf(S)는 균일 분포 U[{f(x) | x ∈ S}]의 평균과 분산을 나타냄
- 더 약한 군집화 개념은 nearest class-center (NCC) separability (분리 가능성) [Galanti et al., 2022]으로, 학습 샘플의 feature 임베딩이 중심과 유사한 기하학을 형성하는 정도를 측정
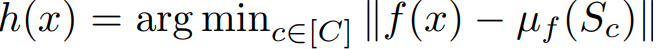
- 이 속성을 측정하기 위해 NCC 학습 및 테스트 정확도를 계산
- 이것들은 간단히 NCC 분류기의 정확도율임
- 최근 논문 [Dubois et al., 2022]은 이상적인 SSL-학습된 representation이 동시에 데이터를 여러 동등 클래스로 군집화한다고 주장
- 이것은 NCC 정확도가 높게 나타나는 다양한 방법으로 데이터를 분류할 수 있다는 것을 의미
3) Reverse Engineering Neural Networks
- 최근에는 신경망을 역공학으로 분석하는 것이 신경망이 예측하고 의사 결정을 내리는 방식을 설명하는 접근 방식으로 주목을 받고 있음
- 그러나 SSL에 의해 생성된 representation 함수의 feature를 특성화하는 것은 여전히 열린 문제임
- 이러한 복잡성의 주요 원인 중 하나는 pretext task과 이미지 증강에 의존하는 것
- 예를 들어, SSL의 성공을 완전히 이해하기 위해서는 pretext task과 downstream task 사이의 관계를 이해하는 것이 중요
- SSL로 representation을 올바르게 학습시키는 방법은 아직 불분명
- 따라서 SSL 알고리즘은 다양한 종류의 loss와 최적화 기술을 포함
- 또한 contrastive learning과 non-contrastive learning 방법으로 학습된 representation 사이의 차이가 명확하지 않음
- 본 논문에서는 다양한 유형의 클래스에 대한 클러스터링 속성을 조사함으로써 SSL로 학습된 representation을 이해하기 위한 새로운 노력을 기울임
3. Problem Setup
1) Data and augmentations
- 본 논문의 모든 실험에서는 CIFAR100 이미지 분류 데이터셋을 사용
- 모델을 학습하기 위해 우리는 SimCLR에서 소개된 이미지 증강 프로토콜을 사용
- 분석을 단순화하고 잠재적인 분포 변화의 영향을 최소화하기 위해 특히 CIFAR-100 데이터셋에서 모델의 성능을 평가
2) Backbone architecture
- 모든 실험에서는 백본으로 RES-L-H 아키텍처를 사용했으며, 여기에는 두 개의 레이어로 구성된 MLP 헤드가 결합
3) Linear probing
- Representation function에서 추출하는 효과를 평가하기 위해 linear probing을 사용
- 이 접근법에서 representation 위에 linear classifier를 학습
4) Sample level classification
- 목표는 주어진 representation function이 동일한 이미지에서 유래한 다양한 증강을 올바르게 분류하고 다른 이미지의 증강과 구별하는 능력을 평가하는 것
- 이를 돕기 위해 sample-level separability을 평가하기 위해 특별히 설계된 새로운 데이터셋을 구축
- 학습 데이터셋은 CIFAR-100 학습 세트에서 가져온 500개의 무작위 이미지로 구성
- 각 이미지는 특정 클래스를 나타내며 100가지 다른 증강을 거침
- 따라서 학습 데이터셋은 총 50000개의 샘플을 포함하는 500개의 클래스로 구성
4. Unraveling the Clustering Process in Self-Supervised Learning
- SSL 학습 과정은 sample-leve에서 다른 증강을 가진 동일한 이미지를 클러스터로 성공적으로 묶어냄
- 더 주목할 만한 점은 학습 과정이 학습 중에 레이블이 없더라도 표준 CIFAR-100 데이터셋의 원래 '의미 있는 클래스(semantic classes)'를 클러스터로 묶는다는 것
- 흥미롭게도 high-level hierarchy도 효과적으로 클러스터로 묶임
1) Implicit information compression in SSL training
- SSL 학습 내에서의 클러스터링 프로세스를 조사한 후, 학습 과정 중의 정보 압축을 분석하는 것에 주의
- 위에서 설명한 바와 같이, 효과적인 압축은 종종 이점이 있는 동시에 실용적인 representation을 낳음
- 그럼에도 불구하고, SSL 학습 과정 중에 이러한 압축이 실제로 발생하는지 여부는 아직 대부분 미정
- 이에 대한 이해를 돕기 위해, 상호 정보 신경 추정 (Mutual Information Neural Estimation, MINE) [Belghazi et al., 2018]을 사용
- 이 방법은 학습 과정 중에 입력과 해당 임베디드 representation 간의 상호 정보를 추정하기 위해 설계된 방법
- 이 지표는 representation의 복잡성 수준을 효과적으로 측정하며, 기본적으로 얼마나 많은 정보 (비트 수)를 인코딩하는지를 보여줌
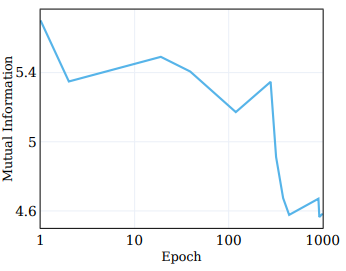
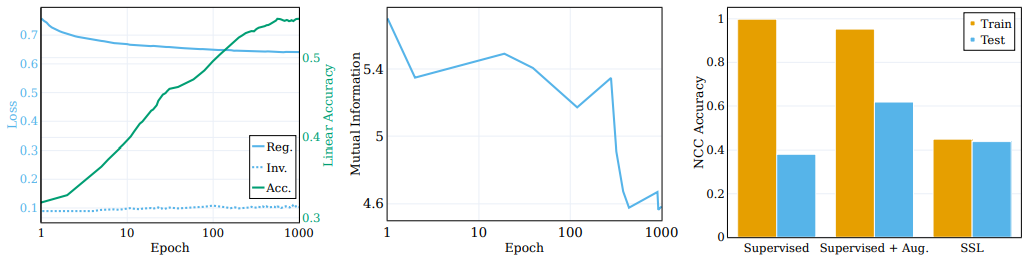
- 위 그림은 5개의 다른 MINE 초기화 시드를 통해 계산한 average mutual information
- 학습 과정은 상당한 압축을 나타내며, 결과적으로 매우 간결하게 학습된 representation을 만들어 냄
- 이 관찰은 클러스터링과 관련된 이전 연구 결과와 원활하게 일치하며, 더 밀집하게 클러스터링된 representation은 더 압축된 정보를 나타냄
2) The role of regularization loss
- 목적 함수를 무변성과 정규화 항으로 분해하고 학습 과정 동안의 그들의 동작을 관찰
- µ = λ = 25 및 ν = 1을 사용하여 [Bardes et al., 2022]에서 제안한대로 VICReg를 사용하여 RES-5-250 네트워크를 학습
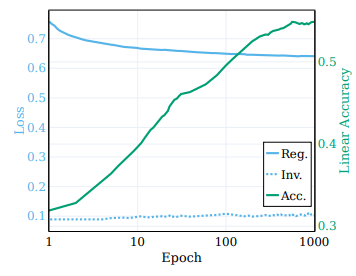
- 위 그림은 이 비교를 제시하며, loss 항과 원래 semantic target에 대한 선형 테스트 정확도의 진행 상황을 나타냄
- 일반적으로 생각되는 반면, 무변성 loss는 학습 과정 중에 크게 향상되지 않음
- 대신, loss의 향상은 정규화 loss을 최소화함으로써 달성
- 이 관찰은 무변성 loss에 의해 주도되는 샘플별 클러스터링 프로세스가 학습 초기에 포화되는 것과 일치
3) Comparing supervised learning and SSL clustering
- 깊은 신경망 분류기는 학습 샘플을 클래스별로 중심점에 클러스터링하는 경향이 있음
5. Exploring Semantic Class Learning and the Impact of Randomness
- semantic 클래스는 입력 데이터의 내재 패턴에 의해 정의된 범주를 나타내며 입력과 타겟 간의 의미 있는 관계를 설정
- 반면에 무작위 타겟은 이러한 분명한 패턴이 없어 입력과 타겟 간의 무작위 연결을 생성하게 됨
- 이 섹션에서는 모델이 원하는 타겟을 학습하는 데 무작위성의 영향을 탐구
- 다양한 정도의 무작위성을 가진 타겟 시스템 시리즈를 만들고, 학습된 representation에 미치는 영향을 조사
- Epoch 0에서 네트워크는 결정적이지만 보이는 대로 무작위 레이블을 생성하여 높은 무작위성을 나타냄
- 학습이 진행됨에 따라 레이블은 덜 무작위해지며 실제 타겟과 일치하는 타겟으로 수렴
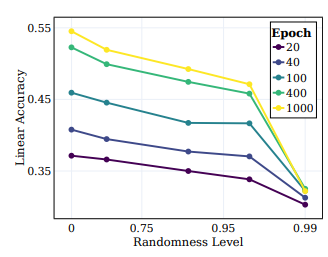
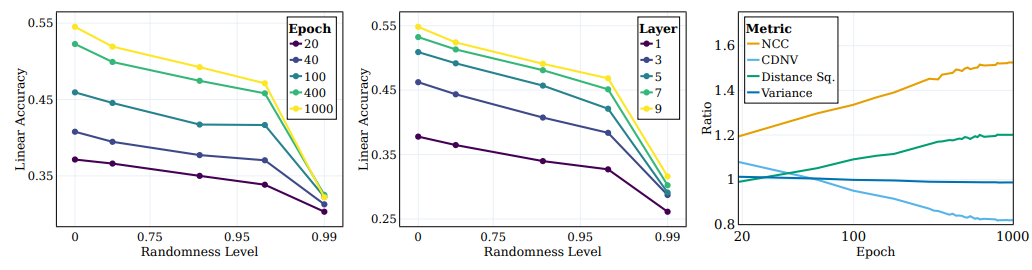
- 위 그림은 다양한 무작위 타겟에 대한 선형 테스트 정확도를 보여줌
- 각 선은 서로 다른 무작위성 수준에 대한 서로 다른 SSL 학습 단계에서의 정확도를 나타냄
- 모델은 학습 중에 "semantic" 클래스에 더 가까운 클래스를 효과적으로 캡처하며, 무작위 타겟에 대한 중요한 성능 향상을 보이지 않음
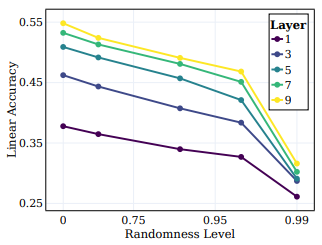
- 위 그림에서 볼 수 있듯이, 무작위성이 감소함에 따라 모든 레이어에서 선형 테스트 정확도가 일관되게 향상되며, 깊은 레이어가 모든 클래스 유형에서 우수한 성능을 보이며 시맨틱 클래스에 가까운 클래스에서 성능 격차가 확대됨
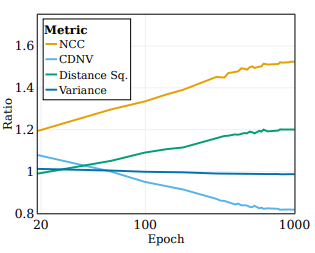
- 분류 정확도 이외에도 원하는 representation은 타겟에 대한 클러스터링의 높은 정도를 나타내야 함
- 위 그림은 이러한 비율을 나타내며, 훈련 중에 NCC, CDNV의 비율이 증가함에 따라 representation이 데이터를 시맨틱 타겟 대 무작위 타겟에 따라 점점 더 클러스터링하는 것을 보여줌
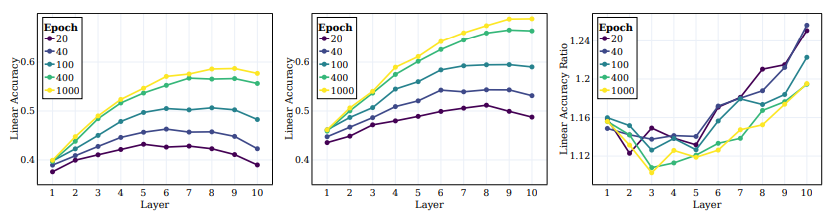
6. Learning Class Hierarchies and Intermediate Layers
- 초기 레이어는 주로 저수준 특성에 집중하며, 더 깊은 레이어는 더 추상적인 특성을 포착
- 네트워크가 더 높은 수준의 계층적 특성을 학습하고 어떤 레이어가 이러한 특성과 더 잘 상관되는지 조사
- 선형 테스트 정확도를 계산하고, 세 가지 계층에 대해 측정
- Sample-level, Original 100개의 클래스 및 20개의 Super 클래스
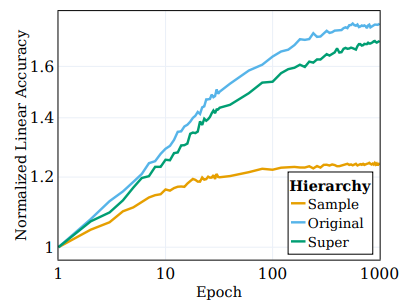
- 위 그림에서는 이러한 양을 세 가지 다른 클래스 집합에 대해 계산한 결과를 그림
- Sample-level 클래스와 대조적으로, Original 클래스와 Super 클래스에 대한 성능이 모두 학습 중에 크게 향상된 것을 관찰
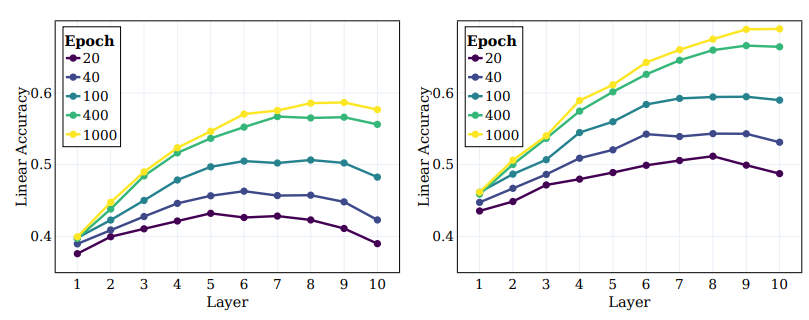
- SSL로 학습된 모델의 중간 레이어의 동작 및 다른 계층의 타겟을 캡처하는 능력을 조사
- 위 그림에서는 학습의 여러 단계에서 모든 중간 레이어에 대한 선형 테스트 정확도를 플롯하고 원래 타겟 및 Super 클래스에 대해 측정한 결과를 나타냄
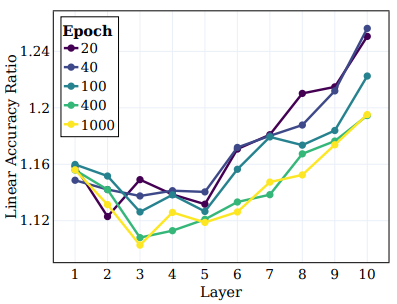
- 위 그림에서는 Super 클래스와 Original 클래스 간의 비율을 나타냄
- 이러한 결과들로부터 여러 결론을 얻을 수 있음
- 먼저, 초기 레이어에서부터 더 깊은 레이어로 이동함에 따라 클러스터링이 지속적으로 향상되며 학습 과정에서 더 두드러짐을 관찰
- 또한 supervised learning 시나리오와 유사하게, SSL 학습 중에 네트워크의 선형 정확도가 각 레이어에서 향상되는 것을 발견
- 특히 original 클래스의 경우, 최종 레이어가 최적이 아닌 것으로 나타남
7. Conclusions
- 이 논문에서는 SSL로 학습된 representation과 semantic 클래스와 관련된 클러스터링 특성에 대한 포괄적인 경험적 탐구를 실시
- 연구 결과는 SSL 알고리즘에서 정규화 제약 조건의 흥미로운 영향을 보여줍
- 정규화는 주로 representation 붕괴를 방지하기 위해 사용되지만, 정확하게 클러스터링된 증강 학습 샘플을 기반으로 학습된 representation과 semantic 클래스 간의 일치도를 향상시킴
- 논문에서 supervised learning 환경과 SSL 환경 간의 유사점을 관찰했지만, 여전히 많은 질문이 남아 있음
- 그 중 가장 중요한 질문은 SSL 알고리즘이 왜 semantic 클래스를 학습하는지에 대한 질문임
- 비록 이 논문은 이 현상을 정규화 제약 조건과 연결하는 강력한 증거를 제시하지만, 이 조건이 어떻게 데이터를 semantic 클래스에 대한 클러스터링으로 관리하고 어떤 종류의 클래스가 학습되는지에 대한 설명은 여전히 불분명
- 데이터가 어떤 유형의 클래스로 클러스터링되는지에 대한 더 깊은 이해와 신경 붕괴와 전이 학습 간의 연결은 SSL로 학습된 representation을 downstream task에 대한 전이 가능성을 이해하는 데 도움이 될 수 있음

AI Research Engineer