https://arxiv.org/abs/2205.08534
1. Introduction
Vision Transformer and Its Evolution
-
Transformer Success in Computer Vision
- Transformer는 동적 모델링 능력과 어텐션 메커니즘의 long-range dependency를 활용해 다양한 computer vision 분야에서 주목할 만한 성과를 달성
- Vision transformer(ViT), Swin 등 Vision Transformer는 object detection 및 semantic segmentation 작업에서 CNN을 능가하며 state-of-the-art(SOTA) 성능을 기록
- Vision Transformer는 두 가지 주요 계열로 나뉨
- Plain ViT: 비전 특화 가정을 포함하지 않는 vanilla transformer 모델
- Hierarchical Variants: Swin 및 기타 모델은 지역적 spatial operation을 통해 vision-specific inductive bias를 도입해 더 나은 성능을 제공
-
Advantages of Plain ViT
- 자연어 처리(NLP)에서 유래한 plain ViT는 입력 데이터 가정이 없어 patch embedding, 3D patch embedding, token embedding 등 다양한 tokenizer와 유연하게 통합 가능
- 이 유연성은 이미지, 비디오, 텍스트 등 multi-modal 데이터를 활용한 pre-training을 지원하며 semantically rich representation을 학습하도록 도움
-
Limitations of Plain ViT
- Plain ViT는 이미지 특화 prior knowledge 부족으로 object detection, semantic segmentation 같은 dense prediction 작업에서 느린 수렴과 낮은 성능을 보임
- 이에 따라 vision-specific transformer와 경쟁하기 어려움
Proposed Approach: Vision Transformer Adapter (ViT-Adapter)
-
Motivation
- NLP 분야의 adapter에서 영감을 받아 plain ViT와 vision-specific transformer 간 dense prediction 작업 성능 격차를 원래 ViT architecture 변경 없이 좁히고자 함
- Vision Transformer Adapter (ViT-Adapter)를 제안하며 이는 pre-training 없이 추가 네트워크로 작동해 plain ViT를 downstream dense prediction 작업에 효율적으로 적응시킴
-
ViT-Adapter Framework
- ViT-Adapter는 vision-specific inductive bias를 도입하기 위해 세 가지 맞춤형 모듈로 구성
- Spatial Prior Module: 입력 이미지에서 local semantics(공간 사전 정보)를 포착해 contextual understanding을 향상시킴
- Spatial Feature Injector: 공간 사전 정보를 ViT architecture에 통합해 local 정보를 포함시킴
- Multi-Scale Feature Extractor: Dense prediction 작업에 필수적인 multi-scale feature를 재구성
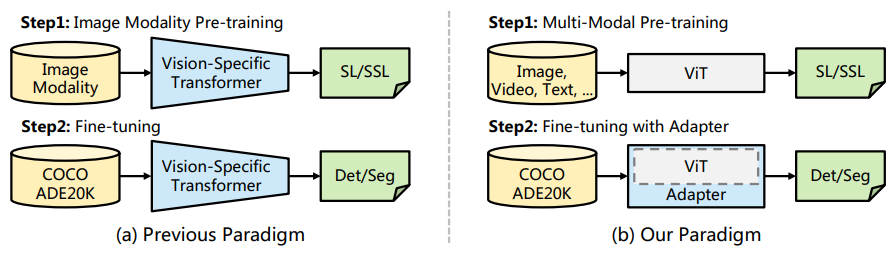
- 기존 패러다임이 ImageNet 같은 대규모 image dataset에서 pre-training 후 fine-tuning을 수행하는 것과 달리 우리 framework는 multi-modal 데이터로 pre-training된 general-purpose plain ViT backbone을 사용
- Randomly initialized ViT-Adapter는 transfer learning 중 image-related prior knowledge를 도입해 dense prediction 작업에 적합하도록 만듦
- ViT-Adapter는 vision-specific inductive bias를 도입하기 위해 세 가지 맞춤형 모듈로 구성
-
Key Contributions
- Novel Paradigm for Vision-Specific Biases:
- Plain ViT에 vision-specific inductive bias를 도입해 standard ImageNet pre-training으로 최근 transformer variant과 동등한 성능을 달성
- Multi-modal pre-training에서 추가적인 이점을 얻음
- Tailored Adapter Modules:
- Spatial prior module과 두 가지 feature interaction operation(spatial feature injector 및 multi-scale feature extractor)을 설계해 ViT architecture를 재설계하지 않고 missing local information을 보완
- Dense prediction 작업을 위한 fine-grained multi-scale feature를 재구성
- Superior Performance on Benchmarks:
- COCO와 ADE20K를 포함한 challenging benchmark에서 ViT-Adapter를 평가
- Fair pre-training 조건에서 기존 vision-specific transformer를 능가하는 성능 달성(그림 2 참조)
- 예: ImageNet-1K Pre-training에서 ViT-Adapter-B는 COCO val에서 49.6 box AP를 달성해 Swin-B를 1.0 포인트 앞섬
- Multi-Modal Pre-training에서 ViT-Adapter-L은 COCO test-dev에서 60.9 box AP를 기록하며 추가 detection 데이터 없이 새로운 SOTA 달성
- Novel Paradigm for Vision-Specific Biases:
2. Related Work
Transformers
- Transformer는 자연어 처리, 컴퓨터 비전, 음성 인식 등 다양한 modality에서 탁월한 성능을 발휘
- Vanilla transformer는 machine translation에서 시작해 NLP task에서 state-of-the-art로 자리 잡음
- ViT는 vanilla transformer를 image classification에 적용한 최초의 모델
- PVT와 Swin은 CNN의 pyramid structure를 활용해 vision-specific inductive bias를 도입
- Conformer는 CNN과 transformer를 결합한 dual network 제안
- BEiT와 MAE는 masked image modeling으로 ViT를 self-supervised learning에 확장하며 plain ViT의 잠재력 입증
- Vision-specific model은 중요하지만 plain ViT는 multi-modal pre-training에 유연해 adapter를 통해 image prior를 추가하며 유연성과 성능 모두 확보
Decoders for ViT
- Dense prediction은 encoder-decoder 구조를 따르며 ViT는 global receptive field로 encoder로 활용
- SETR은 ViT를 backbone으로 사용해 CNN decoder로 semantic segmentation 수행
- Segmenter는 transformer-based decoder로 ViT를 semantic segmentation에 확장
- DPT는 ViT를 monocular depth estimation에 적용해 성능 향상
- 이러한 연구는 task-specific decoder로 ViT의 dense prediction 성능을 개선했으나 single-scale 및 low-resolution representation의 한계는 해결되지 않음
Adapters
- NLP에서 adapter는 transformer encoder에 모듈을 추가해 downstream task 적응을 가속화
- Computer vision에서는 incremental learning과 domain adaptation에 adapter 활용
- CLIP 기반 adapter는 zero-shot 및 few-shot task로 pre-trained knowledge 전이
- ViTDet 등은 upsampling 및 downsampling 모듈로 ViT를 object detection에 적응
- 그러나 regular training(ImageNet pre-training 후 36 epoch fine-tuning)에서 최신 vision-specific model에 비해 성능이 부족
- ViT를 위한 강력한 dense prediction adapter 설계는 여전히 과제
3. Vision Transformer Adapter
3.1 Overall Architecture
- 모델은 Plain ViT와 ViT-Adapter 두 부분으로 구성
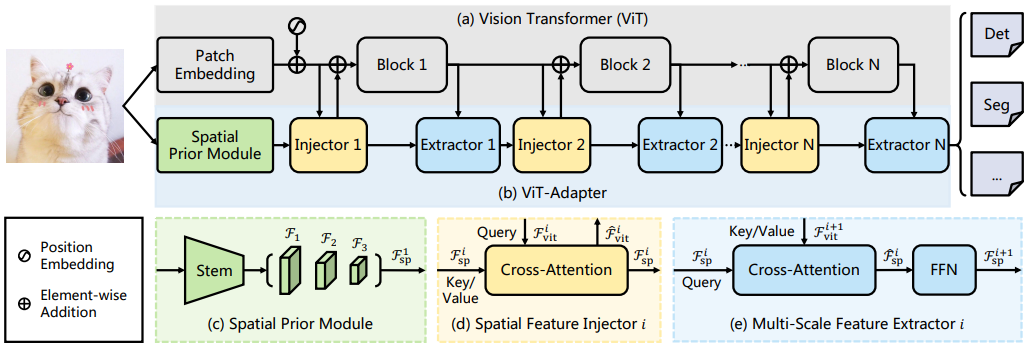
- Plain ViT는 patch embedding과 L개의 transformer encoder layer로 구성
- ViT-Adapter는 세 가지 모듈 포함
- Spatial Prior Module: 입력 이미지에서 spatial feature 포착
- Spatial Feature Injector: spatial prior를 ViT에 주입
- Multi-Scale Feature Extractor: ViT의 single-scale feature에서 hierarchical feature 추출
- ViT 동작
- 입력 이미지를 16×16 non-overlapping patch로 나누고 이를 flatten해 D-dimensional token으로 projection
- feature resolution을 원본 이미지의 1/16으로 축소
- 이후 position embedding을 추가해 L개의 encoder layer로 전달
- ViT-Adapter 동작
- 입력 이미지를 spatial prior module에 전달해 1/8, 1/16, 1/32 resolution의 D-dimensional spatial feature 수집
- 이를 flatten하고 concatenate해 feature interaction 입력으로 사용
- Feature Interaction
- ViT의 transformer encoder를 N개 block(N=4)으로 나누고 각 block에서 spatial feature injector로 spatial prior 주입
- 이후 multi-scale feature extractor로 hierarchical feature 추출
- 최종적으로 1/8-scale feature map을 2×2 transposed convolution으로 upsampling해 1/4-scale feature map 생성
- ResNet과 유사한 feature pyramid(1/4, 1/8, 1/16, 1/32 resolution) 구축해 다양한 dense prediction task에 활용
3.2 Spatial Prior Module
- Convolution은 transformer가 local spatial information을 포착하도록 도움
- Spatial Prior Module(SPM)은 ViT의 원본 architecture 변경 없이 patch embedding과 병렬로 local spatial context 모델링
- SPM은 ResNet에서 차용한 convolutional stem(세 개의 convolution과 max-pooling layer)으로 시작
- Stride-2 3×3 convolution을 쌓아 channel 수를 두 배로 늘리고 feature map 크기 축소
- 마지막으로 1×1 convolution 적용해 feature map을 D dimension으로 projection
- 결과로 1/8, 1/16, 1/32 resolution의 D-dimensional feature pyramid {F1, F2, F3} 생성
- 이를 flatten하고 concatenate해 feature token 로 feature interaction 입력 생성
3.3 Feature Interaction
- Plain ViT는 weak prior assumption으로 dense prediction task에서 vision-specific transformer에 비해 성능이 떨어짐
- 이를 해결하기 위해 cross-attention 기반 두 모듈(Spatial Feature Injector, Multi-Scale Feature Extractor) 제안
- Spatial Feature Injector
- ViT의 i-th block에서 입력 feature 를 query로, spatial feature 를 key와 value로 사용해 cross-attention으로 spatial feature 주입
- 수식:
- 은 LayerNorm
- 은 sparse attention
- 는 learnable vector로 초기값 0 설정
- Multi-Scale Feature Extractor
- Spatial prior 주입 후 를 i-th block의 encoder layer로 전달해 출력 feature 생성
- 이후 cross-attention과 feed-forward network(FFN)으로 multi-scale feature 추출
- 수식:
- 를 query로, 를 key와 value로 사용하며 sparse attention 적용
- 생성된 는 다음 spatial feature injector의 입력으로 사용
3.4 Architecture Configurations
- ViT-Adapter는 ViT-T, ViT-S, ViT-B, ViT-L 네 가지 ViT 크기에 맞춰 설계
- Adapter의 parameter 수는 각각 2.5M, 5.8M, 14.0M, 23.7M
- Deformable attention을 기본 sparse attention으로 사용하며 sampling point 수는 4, attention head 수는 6, 6, 12, 16으로 설정
- Feature interaction 수 N은 4, 마지막 interaction에서는 multi-scale feature extractor를 세 번 쌓음
- FFN ratio는 계산 비용 절감을 위해 0.25로 설정, 즉 FFN hidden size는 네 가지 adapter에 대해 48, 96, 192, 256

4. Experiments
4.1 Object Detection and Instance Segmentation
- Settings
- 실험은 MMDetection과 COCO Dataset 기반으로 진행
- Mask R-CNN, Cascade Mask R-CNN, ATSS, GFL 네 가지 Mainstream Detector로 ViT-Adapter 평가
- 시간 및 메모리 절감을 위해 L-layer ViT를 14×14 Window Attention으로 수정(L/4 간격 Layer 제외)
- 1× 또는 3× Training Schedule(각각 12 또는 36 Epoch) 사용, Batch Size 16, AdamW Optimizer, 초기 Learning Rate 1×10⁻⁴, Weight Decay 0.05 적용
- Results with ImageNet-1K Pre-training
- DeiT ImageNet-1K Weight(증류 없음)로 ViT-T/S/B 모델 초기화
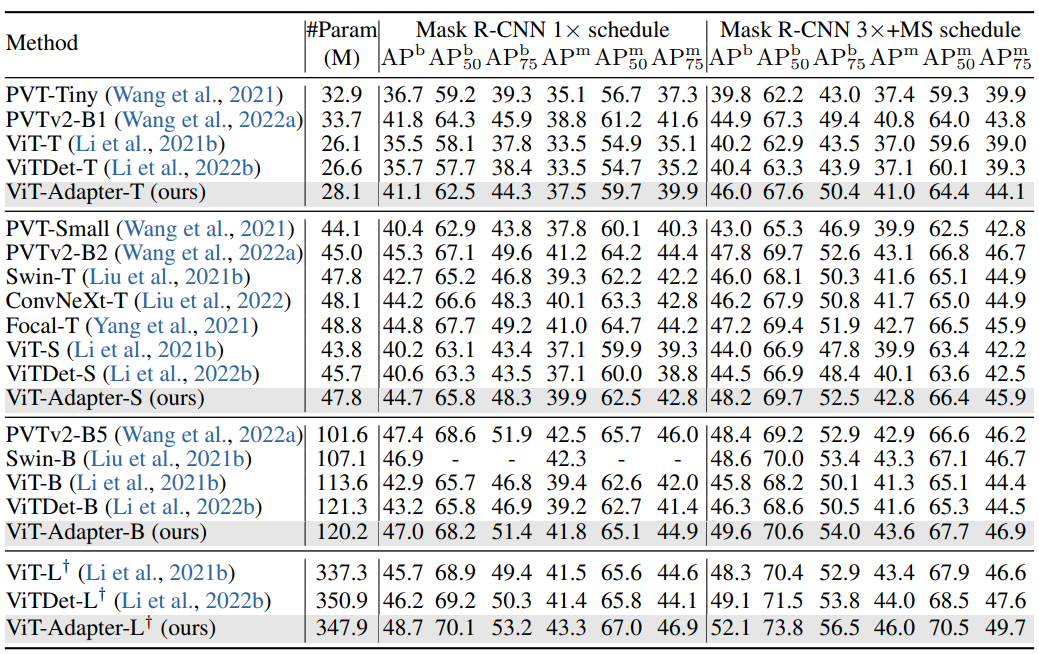
- 위 Table 1과 Table 2는 ImageNet-1K pre-training을 사용한 object detection 및 instance segmentation 실험 결과를 제시
- 모든 ViT-T/S/B 모델은 DeiT의 ImageNet-1K weight(증류 없음)으로 초기화
- 비교 대상은 ViT, ViTDet 및 대표적인 vision-specific backbone(PVT, Swin 등)
- Regular training setting(공정한 비교를 위한 표준 조건)에서 ViT와 ViTDet의 detection 성능이 최신 vision-specific 모델에 비해 열등
- 예: Mask R-CNN 3×+MS schedule에서 ViT-S와 ViTDet-S는 각각 PVTv2-B2보다 3.8 APb, 3.3 APb 낮음
- ViT-Adapter-S는 ViT와 ViTDet를 명확히 상회하며 PVTv2-B2보다 0.4 APb 높음
- Cascade Mask R-CNN, ATSS, GFL 세 detector에서도 유사한 우세성 관찰
- 결과는 ImageNet-1K pre-training만으로 ViT-Adapter가 plain ViT를 vision-specific transformer와 동등 또는 우수한 수준으로 끌어올림을 입증
- DeiT ImageNet-1K Weight(증류 없음)로 ViT-T/S/B 모델 초기화
4.2 Semantic Segmentation
- Settings
- ADE20K dataset과 MMSegmentation codebase로 ViT-Adapter 평가
- Semantic FPN과 UperNet을 기본 framework로 사용
- Semantic FPN은 PVT 설정 따라 80k iteration, UperNet은 Swin 설정 따라 160k iteration 학습
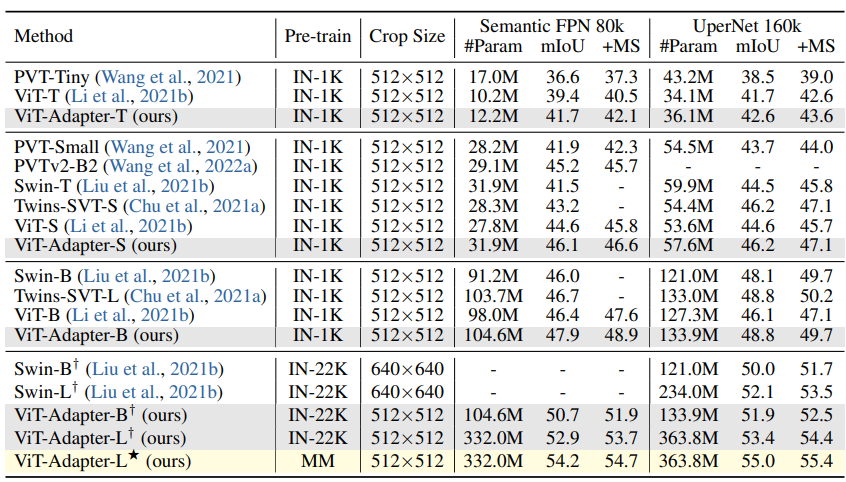
- Results with ImageNet-1K Pre-training
- Single-scale 및 multi-scale(MS) mIoU로 결과 보고
- DeiT ImageNet-1K weight로 ViT-T/S/B 모델 초기화
- 유사 모델 크기에서 ViT 및 vision-specific transformer(PVT, Swin 등)를 상회
- 예: ViT-Adapter-S는 UperNet에서 47.1 MS mIoU 달성, Swin-T를 능가
- ViT-Adapter-B는 49.7 MS mIoU로 ViT-B보다 2.6 포인트 높고 Swin-B, Twins-SVT-L과 동등
- Regular ImageNet-1K pre-training만으로 ViT-Adapter의 효과 및 보편성 입증
- Results with ImageNet-22K Pre-training
- ImageNet-22K weight 사용 시 ViT-Adapter-B†는 UperNet에서 51.9 mIoU, 52.5 MS mIoU 달성, Swin-B†보다 최소 0.8 mIoU 우세
- ViT-Adapter-L†는 53.4 mIoU, 54.4 MS mIoU로 Swin-L†를 크게 앞서
- 다양한 모델 크기에서 일관된 향상은 plain ViT의 단점을 보완해 semantic segmentation에 적합
- Results with Multi-Modal Pre-training
- Uni-Perceiver multi-modal pre-trained weight로 semantic segmentation 수행
- ImageNet-22K을 multi-modal pre-training으로 대체 시 ViT-Adapter-LF가 Semantic FPN과 UperNet에서 각각 1.3 mIoU, 1.6 mIoU 개선
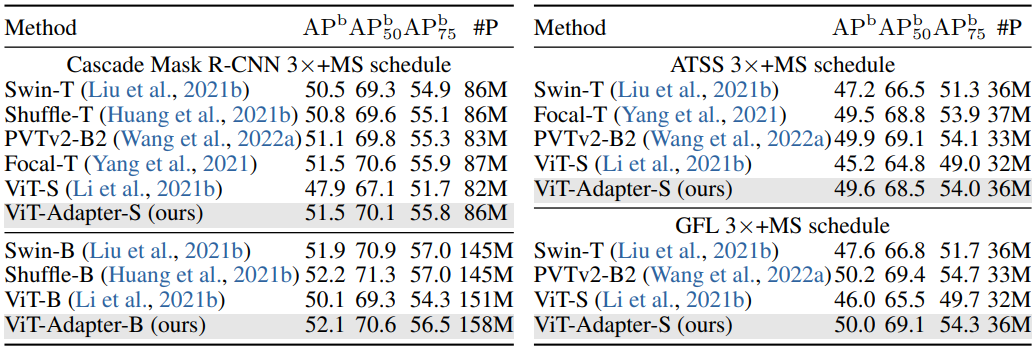
4.3 Comparisons with State-of-the-Arts
- Settings
- ViT-Adapter를 HTC++, Mask2Former, BEiTv2 등 최신 detection/segmentation framework과 결합

- ViT-Adapter를 HTC++, Mask2Former, BEiTv2 등 최신 detection/segmentation framework과 결합
- Results
- Table 5에서 state-of-the-art 성능 도달
- Advanced pre-training 효과도 포함되나 plain backbone detector/segmenter가 hierarchical backbone의 입지를 도전 가능
4.4 Ablation Study
-
ViT vs. ViT-Adapter Feature
- ViT는 low-frequency global signal 학습 특성, CNN은 high-frequency 정보(예: local edge, texture) 추출
- Fourier analysis로 ViT와 ViT-Adapter feature 차이 시각화
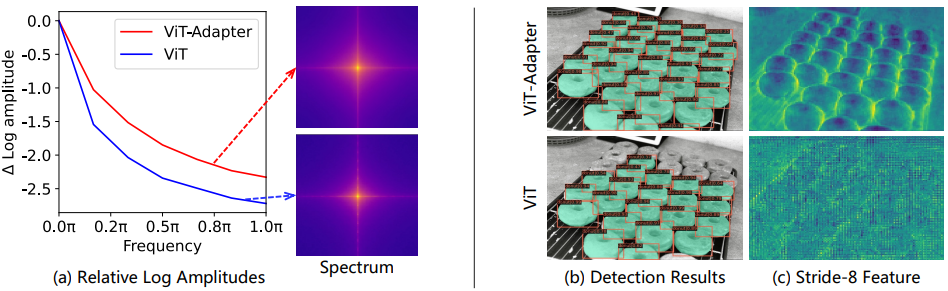
- Figure (a)에서 Fourier spectrum 및 log amplitude 분석 결과 ViT-Adapter가 ViT보다 high-frequency signal 더 포착
- Figure (b)(c)에서 stride-8 feature map 시각화
- ViT feature는 흐릿하고 거칠지만 ViT-Adapter feature는 fine-grained하며 local edge와 texture 풍부
- 이는 ViT에 CNN의 high-frequency 정보 포착 장점 접목
-
Ablation for Components
- ViT-S baseline을 ViT-Adapter-S로 점진적 확장, Mask R-CNN 1× schedule로 학습

- Table (좌측)에서 SPM의 spatial feature resizing 및 추가로 variant 1이 baseline보다 1.4 APb, 0.9 APm 향상, local spatial 정보 중요성 입증
- Variant 2에서 spatial feature injector가 1.0 APb, 0.8 APm 추가 향상, cross-attention이 spatial feature 주입에 유연
- Multi-scale feature extractor로 hierarchical feature 재구성 시 2.1 APb, 1.1 APm 증가, ViT의 single-scale 단점 완화
- 제안된 구성 요소 각각 필요하며 총 4.5 APb, 2.8 APm 개선
- ViT-S baseline을 ViT-Adapter-S로 점진적 확장, Mask R-CNN 1× schedule로 학습
-
Number of Interactions
- Table (우측)에서 interaction 수 영향 분석
- N 증가 시 모델 정확도가 포화되며 추가 interaction이 성능 단조 증가 않음
- 경험적으로 N을 4로 기본 설정
-
Attention Type
- ViT-Adapter-S를 기본 모델로 4가지 attention mechanism 비교

- 위 Table 에서 linear complexity의 sparse attention이 quadratic complexity의 global attention보다 adapter에 적합
- Deformable attention을 기본 구성으로 채택, 향후 고급 attention으로 교체 가능
- ViT-Adapter-S를 기본 모델로 4가지 attention mechanism 비교
5. Conclusion
- 이 연구는 ViT-Adapter라는 새로운 패러다임을 탐구해 plain ViT와 vision-specific transformer 간 dense prediction task 성능 격차를 좁힘
- 원래 architecture를 수정하지 않고 유연하게 image-related inductive bias를 ViT에 주입하며 dense prediction에 필요한 fine-grained multi-scale feature를 재구성
- Object detection, instance segmentation, semantic segmentation에 대한 광범위한 실험 결과 우리 방법이 잘 설계된 vision-specific transformer와 동등 또는 우수한 성능 달성
- Advanced multi-modal pre-training에서 상당한 이점 추가 도출

AI Research Engineer