[논문 정리] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
https://arxiv.org/abs/2301.08243
1. Introduction
Self-Supervised Learning in Computer Vision: Two Major Paradigms
- 컴퓨터 비전에서 Self-Supervised Learning (SSL) 은 라벨 없이 이미지로부터 표현을 학습하는 핵심 접근법으로, 크게 두 가지 패밀리로 나뉨
- Invariance-based Methods
- 동일 이미지의 다중 뷰(views)를 생성하고, 인코더가 유사한 임베딩을 출력하도록 최적화
- 뷰 생성은 hand-crafted augmentations 사용
- 예: Random scaling, cropping, color jittering, Gaussian blur, solarization 등
- 고수준 의미적 표현(high semantic level)을 학습하나, 다음 한계를 가짐
- 강한 편향(strong biases) 도입 → 특정 다운스트림 태스크나 데이터 분포 변화 시 성능 저하
- 추상화 수준 일반화 어려움 → 예: Image classification vs. Instance segmentation은 서로 다른 불변성 필요
- 다른 모달리티(e.g., audio)로의 일반화 불가능
- Generative Methods
- 입력의 일부를 제거/손상(masking/corruption)하고 손상된 내용을 예측하도록 학습
- 특히 Masked Denoising
- Pixel-level 또는 Token-level에서 랜덤 마스킹된 패치를 재구성
- 장점
- 적은 사전 지식(less prior knowledge) 필요
- 모달리티 일반화 용이 (이미지 외에도 적용 가능)
- 단점
- 결과 표현은 저수준 의미적 수준(lower semantic level)
- Off-the-shelf 평가(linear probing) 및 제한된 감독 전이(semi-supervised)에서 invariance 기반 방법에 뒤짐
- 전체 이점 활용을 위해 복잡한 적응(end-to-end fine-tuning) 필수
- Invariance-based Methods
Proposed Method: I-JEPA
- 본 연구는 추가적인 사전 지식(hand-crafted augmentations) 없이 의미적 수준 높은 SSL 표현을 학습하는 방법을 탐구
- I-JEPA (Image-based Joint-Embedding Predictive Architecture) 제안
- 추상적 표현 공간(abstract representation space)에서 결측 정보 예측
- 예: 하나의 context block 주어지고, 동일 이미지 내 다양한 target block의 표현을 예측
- Target 표현은 학습된 target-encoder network에 의해 계산
- 핵심 설계 선택
- 추상적 예측 목표(Abstract Prediction Targets)
- Pixel/token 공간 예측(generative)과 달리, 불필요한 픽셀 수준 세부사항 제거 → 더 의미적 특징(semantic features) 학습 유도
- Multi-block Masking Strategy
- 충분히 큰 target block 예측
- 정보성 있는(spatially distributed) context block 사용
- 대규모 target block 예측의 중요성 입증
- 추상적 예측 목표(Abstract Prediction Targets)
- 광범위한 실험 평가를 통해 다음 주요 관찰 도출
- I-JEPA는 hand-crafted 뷰 증강 없이 강력한 off-the-shelf 표현 학습
- ImageNet-1K Linear Probing, Semi-supervised 1%, Semantic Transfer에서 MAE 등 pixel-reconstruction 방법 능가
- Semantic Task에서 invariance 기반 방법과 경쟁력 있음
- 저수준 비전 태스크(object counting, depth prediction)에서 더 우수한 성능
- 단순한 모델 + 덜 엄격한 유도 편향(less rigid inductive bias) → 더 넓은 태스크 적용 가능
- 확장성 및 효율성 입증
- ViT-H/14를 ImageNet에서 사전 학습 시 1200 GPU hours 미만 소요
- iBOT의 ViT-S/16 대비 2.5배 빠름
- MAE의 ViT-H/14 대비 10배 이상 효율적
- 표현 공간 예측 → 전체 계산량 대폭 감소
- ViT-H/14를 ImageNet에서 사전 학습 시 1200 GPU hours 미만 소요
- I-JEPA는 hand-crafted 뷰 증강 없이 강력한 off-the-shelf 표현 학습
결론적으로, I-JEPA는 의미적 표현 학습과 계산 효율성, 태스크 일반화를 동시에 달성하는 새로운 SSL 패러다임 제시
3. Method
I-JEPA: Image-based Joint-Embedding Predictive Architecture
- I-JEPA 는 Vision Transformer (ViT) 기반의 Joint-Embedding Predictive Architecture (JEPA) 구현
- Context Encoder, Target Encoder, Predictor 모두 ViT 구조 사용
- 각 레이어: Self-Attention → MLP
- MAE 와의 유사성: 마스킹 기반 비대칭 인코더-디코더 구조
핵심 차이: 비생성적(non-generative), 표현 공간(representation space)에서 예측
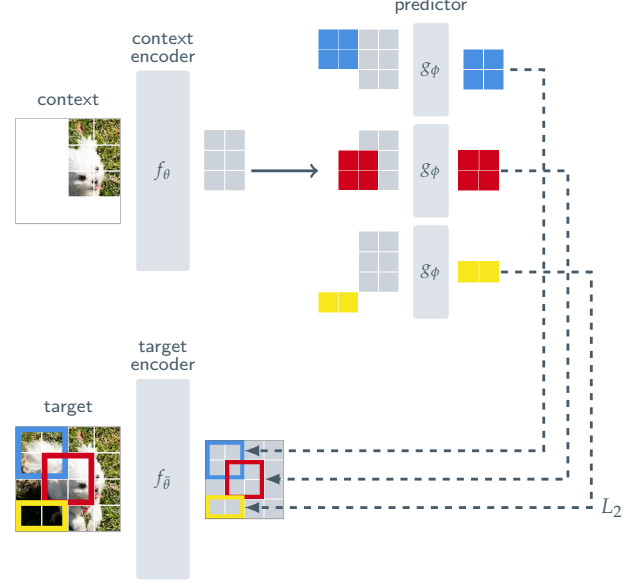
3.1. Targets
- 목표: 동일 이미지 내 다양한 target block의 표현을 예측
- Target 생성 과정:
- 입력 이미지 → 개의 비중첩 패치(non-overlapping patches)로 분할
- Target Encoder 통과 → 패치 수준 표현
- 에서 M개 (중첩 가능) 블록 무작위 샘플링
- 각 블록 에 대한 마스크:
- 블록 표현
- 하이퍼파라미터
M = 4(기본값)- Aspect Ratio:
(0.75, 1.5)사이 무작위 - Scale:
(0.15, 0.2)사이 무작위
핵심 설계
- 입력 마스킹이 아닌 출력 마스킹 → 고수준 의미적 표현(high semantic level) 보장
3.2. Context
- 단일 context block 로부터 target 예측
- Context 생성 과정
- 이미지에서 하나의 블록 샘플링
- Scale:
(0.85, 1.0) - Aspect Ratio:
1.0(정사각형) - 마스크:
- Scale:
- Target 블록과 중첩 제거 → 비자명한 예측 태스크 보장

- 마스킹된 context → Context Encoder 통과
- 이미지에서 하나의 블록 샘플링
3.3. Prediction
- 입력: Context 표현 + 각 target 위치에 대한 마스크 토큰
- 마스크 토큰: 공유 학습 가능 벡터 + 위치 임베딩
- Predictor
- M번 반복 예측
3.4. Loss
-
Loss Function: 예측된 패치 표현과 target 표현 간 평균 L2 Distance
-
학습 대상 파라미터
- Predictor
- Context Encoder
-
Target Encoder 업데이트
- Exponential Moving Average (EMA) of context encoder parameters
→ ViT 기반 JEA 학습 안정화에 필수
- Exponential Moving Average (EMA) of context encoder parameters
4. Related Work
4.1. Generative Self-Supervised Learning: From Denoising to Masked Modeling
-
시각 표현 학습은 결측/손상된 감각 입력을 예측하는 방식으로 오랜 연구 전통 보유
-
초기 접근
- Denoising Autoencoders: 무작위 노이즈로 입력 손상 → 원본 복원
- Context Encoders: 주변 컨텍스트 기반으로 전체 이미지 영역 회귀
- Colorization as Denoising: 흑백 → 컬러 변환을 denoising 태스크로 재정의
-
최근 Masked Image Modeling (MIM)
- Vision Transformer (ViT) 기반 결측 패치 재구성
- MAE (Masked Autoencoders)
- 효율적 아키텍처: 인코더는 보이는 패치만 처리
- Pixel 공간 재구성 → 대규모 라벨 데이터 end-to-end fine-tuning 시 강력한 성능 + 우수한 스케일링 특성
- BEiT
- 토큰화된 공간(tokenized space)에서 결측 패치 예측
- 고정된 Discrete VAE (250M 이미지 학습)로 패치 토큰화
- 단점: Pixel-level 사전 학습이 fine-tuning 성능에서 BEiT 능가
- SimMIM
- HoG (Histogram of Gradients) 특징 공간 기반 재구성 목표
- Pixel 공간 대비 일부 이점 입증
공통 한계
- 저수준 픽셀/토큰 재구성 → 의미적 표현 학습 제한
- 광범위한 fine-tuning 없이는 다운스트림 태스크에서 약한 off-the-shelf 성능
4.2. Joint-Embedding Predictive & Multi-Modal Approaches
- 가장 유사한 연구
- data2vec
- Online target encoder로 계산된 결측 패치 표현 예측
- Hand-crafted augmentations 배제 → 비전, 텍스트, 음성 등 다양한 모달리티 적용 가능
- 유망한 초기 결과 보고
- Context Autoencoders
- Encoder-Decoder 구조
- 재구성 손실 + 정렬 제약(alignment constraint) 합 최적화
- 표현 공간에서 결측 패치 예측 가능성 강제
- data2vec-v2 (동시 연구):
- 다양한 모달리티를 위한 효율적 아키텍처 탐구
- data2vec
4.3. Joint-Embedding Architectures with View Invariance
-
Hand-crafted augmentations 기반 의미적 표현 학습
- DINO, MSN, iBOT
- 다중 뷰(multiple views) 생성 → 불변성 학습
- MSN
- 사전 학습 중 마스킹을 추가 증강으로 활용
- iBOT
- data2vec 스타일 패치 재구성 손실 + DINO 불변성 손실 결합
- DINO, MSN, iBOT
-
공통 문제
- 입력 이미지당 다중 뷰 처리 → 스케일링 저하
- 계산 비용 급증
-
I-JEPA의 차별점
- 단일 뷰(single view)만 처리
- ViT-Huge/14 (I-JEPA) 가 ViT-Small/16 (iBOT) 보다 적은 계산량 소요
- 확장성 + 효율성 동시 달성
5. Image Classification
Evaluation Setup
- 사전 학습 데이터셋: ImageNet-1K
- 모델 해상도: 기본
224 × 224(특별 언급 시448 × 448) - 프로토콜:
- Linear Probing: 사전 학습 가중치 고정 → 전체 ImageNet-1K 라벨로 선형 분류기 학습
- Partial Fine-tuning / Low-Shot: 제한된 라벨(1%)로 모델 적응
- 비교 대상:
- Augmentation-free 방법: MAE, CAE, data2vec
- Hand-crafted augmentation 사용: DINO, MSN, iBOT
- 구현 세부사항: Appendix A 참조
5.1. ImageNet-1K Linear Probing
Table 1: ImageNet-1K Linear Evaluation (Top-1 Accuracy)
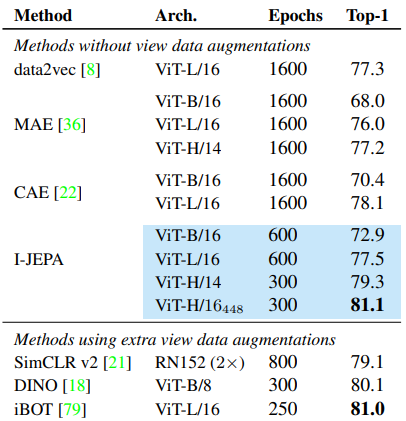
- 주요 관찰
- I-JEPA는 hand-crafted augmentation 없이 MAE, CAE, data2vec 대비 최대 +5.1%p 성능 향상
- 계산 효율성: 동일 성능 수준에서 3배 이상 빠른 사전 학습
- 스케일 이점
- ViT-H/16 @ 448×448 → iBOT과 동등 성능, 단 300 epoch만 학습
- ViT-H/14 기준, iBOT보다 2.5배 적은 계산량
5.2. Low-Shot ImageNet-1K (1% Labels)
Table 2: 1% ImageNet-1K (Top-1 Accuracy)
(~12–13 images/class, best of linear probe or fine-tune)
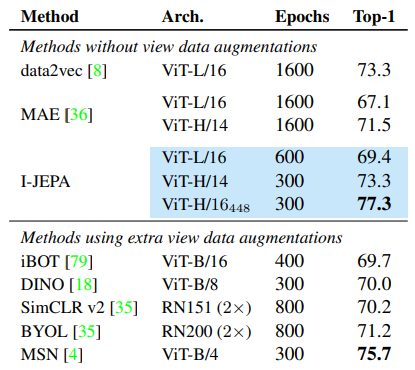
- 주요 관찰
- I-JEPA (ViT-H/14) → data2vec ViT-L/16과 동등 성능, 계산량은 현저히 적음
- 고해상도 입력 (448×448) 적용 시
- Hand-crafted augmentation 사용 방법(MSN, DINO, iBOT) 능가
- 77.3% → 새로운 SOTA
5.3. Transfer Learning via Linear Probing
Table 3: Downstream Classification (Linear Probe, Top-1 Accuracy)
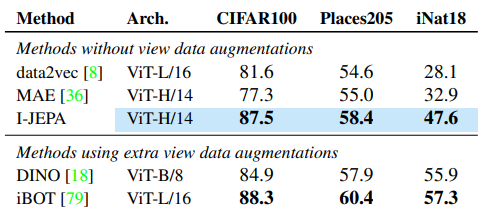
-
주요 관찰
-
Augmentation-free 방법 중 압도적 우위 (MAE, data2vec 대비 +2~8%p)
-
Hand-crafted augmentation 사용 방법과의 격차 대폭 축소
- CIFAR100, Place205에서 DINO 능가
- iBOT과의 격차 최소화 (특히 Place205, iNaturalist)
-
의미적 표현의 강력한 일반화 능력 입증
방법 학습 목표 결과 표현의 성질 DINO/iBOT 전역 CLS 토큰 불변성 고수준 의미는 강함
→ "이건 고양이" 판단은 잘함MAE 픽셀 재구성 저수준 텍스처는 잘함
→ "고양이 털 색깔"은 잘 복원I-JEPA 표현 공간에서 지역 블록 예측 고수준 의미 + 중간 수준 구조
→ "고양이의 머리-몸통-꼬리 관계"까지 이해→ Transfer task(CIFAR, Flowers, Place205, iNat18)는 "세부적인 의미적 구분"이 필요
→ I-JEPA는 의미적 계층 구조(semantic hierarchy)를 더 잘 캡처
-
6. Local Prediction Tasks
Low-Level & Dense Prediction에서의 우수성
- I-JEPA는 의미적 표현(semantic representations)을 학습하여
→ MAE, data2vec 등 기존 augmentation-free 방법 대비 이미지 분류 성능 대폭 향상
→ 스케일링 이점으로 hand-crafted augmentation 사용 view-invariance 방법(DINO, iBOT)과의 격차 해소 및 일부 능가 - 본 섹션 기여
I-JEPA는 고수준 의미적 표현뿐 아니라 저수준 지역적 특징(local image features)도 효과적으로 학습
→ 저수준 밀집 예측 태스크(low-level dense prediction)에서 view-invariance 기반 방법 능가
6.1. Evaluation Setup
- 태스크:
- Object Counting (Clevr/Count)
- Depth Prediction (Clevr/Dist)
- 데이터셋: Clevr
- 합성 장면, 정밀한 ground-truth 제공
- 프로토콜: Linear Probing
- 사전 학습 후 인코더 가중치 고정
- 상위에 선형 모델 학습
6.2. Results
Table 4. Low-level local prediction tasks with linear probe on Clevr
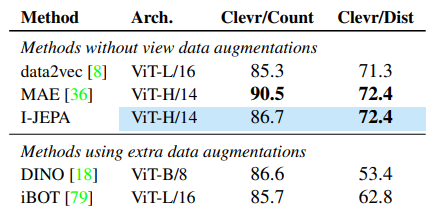
- 주요 관찰
- Clevr/Count (Object Counting):
- I-JEPA: 86.7% → data2vec +1.4%p, MAE -3.8%p (MAE가 우세)
- DINO, iBOT과 유사 수준 유지
- Clevr/Dist (Depth Prediction):
- I-JEPA: 72.4% → data2vec, MAE와 동등
- DINO (+19.0%p), iBOT (+9.6%p) 대비 압도적 우위
- 저수준 공간 구조(spatial structure) 학습에서 강력한 일반화
- Clevr/Count (Object Counting):
- 핵심 인사이트
- View-invariance 방법(DINO, iBOT)은 전역 불변성 추구 → Depth 예측에서 지역 정렬 약화
- DINO, iBOT 같은 이미지의 여러 뷰(augmented views)를 만들고, 모두 같은 전역 임베딩(global representation)을 출력하도록 강제
- 즉, 인코더는 모든 뷰가 동일한 고차원 벡터를 내도록 학습
- 전역적 의미 불변성(global semantic invariance) 추구
- 예를 들어 "이 이미지는 고양이인가?" 같은 고수준 의미적 판단에 강력
- I-JEPA는 지역 블록 간 예측 태스크 → 정밀한 로컬 피처 + 공간 관계 동시 캡처
- MAE는 픽셀 재구성으로 Count에서 강세, Depth는 I-JEPA와 동률
- View-invariance 방법(DINO, iBOT)은 전역 불변성 추구 → Depth 예측에서 지역 정렬 약화
7. Scalability
7.1. Model Efficiency
- I-JEPA는 기존 SSL 방법 대비 높은 확장성(scalability)과 계산 효율성 입증
- 1% ImageNet-1K semi-supervised 성능 vs. GPU hours
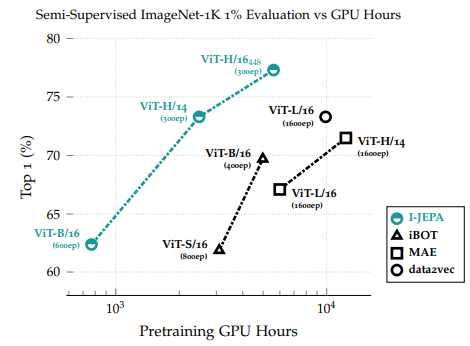
- 주요 관찰
- vs. Reconstruction-based (MAE)
- 표현 공간 예측 → iteration당 7% 느림
- 그러나 5배 빠른 수렴 → 실제 계산량 3배 이상 절감
- vs. View-invariance (iBOT)
- 다중 뷰 처리 제거 → 단일 뷰 입력
- ViT-H/14 (I-JEPA) < ViT-S/16 (iBOT) in compute
→ 거대 모델도 소형 모델보다 효율적
- vs. Reconstruction-based (MAE)
7.2. Scaling Data and Model Size
Table 5. Transfer learning with increased pretraining data (IN1K → IN22K)

- 결과
- IN22K (21배 데이터) → 의미적 태스크(Place205, iNat18) 및 저수준 태스크(Clevr) 동시 향상
- 다양성 증가 → 일반화 능력 강화
- ViT-G/16 → 의미적 태스크에서 대폭 향상 (+2.5~3.3%p)
- 저수준 태스크는 성능 하락 또는 정체
- 이유: 더 큰 패치 크기 (16×16) → 지역적 정밀도 손실
- 로컬 예측 태스크(counting, depth)에 불리
10. Conclusion
- 핵심 기여
- 표현 공간 예측(Representation Space Prediction)
- Pixel 재구성(MAE 등) 대비 5배 빠른 수렴
- 고수준 의미적 표현(high semantic level) 학습
- 단일 뷰 + 지역 예측 아키텍처
- View-invariance 기반 방법(DINO, iBOT)과의 의존성 제거
- 계산 효율성 대폭 향상 (ViT-H/14 < ViT-S/16 iBOT)
- 광범위한 태스크 성능
- 의미적 태스크: Linear probing, low-shot, transfer → SOTA 또는 격차 해소
- 저수준 밀집 예측: Object counting, depth → view-invariance 방법 압도
- 스케일링: 데이터·모델 크기 증가 시 일관된 성능 향상
- 표현 공간 예측(Representation Space Prediction)
