https://arxiv.org/abs/2204.07141
1. Introduction
Self-Supervised Learning in Vision: Masked Denoising과 Joint-Embedding
- Self-Supervised Learning (SSL) 은 대량의 라벨 없이 이미지 표현을 학습하는 핵심 전략으로, 다운스트림 태스크에 적은 라벨로 효과적으로 적용 가능
- 핵심 아이디어: 입력 일부 제거 → 결측 내용 예측
- Auto-regressive 모델, Denoising Auto-encoders: 픽셀/토큰 수준에서 결측 예측
- Masked Auto-Encoders (MAE):
- 랜덤 마스킹된 패치 재구성 → ViT 기반 성공적 적용
- 장점: 대규모 모델 학습 가능, 대량 라벨 fine-tuning 시 SOTA 성능
- 한계:
- 저수준 픽셀 세부사항 모델링 → 의미적 추상화(classification)에 불필요
- Off-the-shelf 표현 약함 → low-shot 설정에서 과적합
- 광범위한 fine-tuning 필수
- Joint-Embedding Architectures:
- 재구성 회피, Siamese Networks 기반
- 동일 이미지의 두 뷰(views)에 대해 유사한 임베딩 출력
- 뷰 생성: hand-crafted transforms (random scaling, cropping, color jitter 등)
- 장점: 고수준 의미적 표현(high semantic level), 강력한 off-the-shelf 성능
- 단점: 로컬 구조(rich local structure) 무시 → 일부 태스크에서 한계
- 핵심 아이디어: 입력 일부 제거 → 결측 내용 예측
Proposed Method: Masked Siamese Networks (MSN)
- 본 연구는 픽셀/토큰 재구성 없이 마스크 denoising 아이디어를 활용하는 Masked Siamese Networks (MSN) 제안
- 핵심 설계:
- 입력 이미지의 두 뷰 생성
- 한 뷰는 패치 무작위 마스킹, 다른 뷰는 변경 없음
- ViT 기반 인코더가 두 뷰에 대해 유사한 임베딩 출력하도록 학습
- Denoising 과정: 입력 수준 예측 없음 → 표현 수준에서 암시적 수행
- 마스킹된 뷰의 표현 = 비마스킹 뷰의 표현
- 시각적 효과: Figure 2에서 MSN의 denoising 효과 정성적 입증
- 핵심 설계:
- 실험적 기여:
- 강력한 off-the-shelf 표현 학습 → low-shot 예측에서 탁월 (Figure 1 참조)
- ImageNet 1% low-shot:
- MSN ViT-B/4 (patch 4×4) → 75.7% top-1
- 기존 SOTA 컨볼루션 모델 (800M 파라미터) 능가, 10배 적은 파라미터
- 극저 라벨 설정 (1~5 images/class):
- MSN ViT-L/7 → 5 images/class로 72.1% top-1
- DINO 대비 +8%p, 새로운 SOTA
- 계산 효율성:
- 70% 패치 마스킹 → ViT 인코더는 보이는 패치 처리
- 비마스킹 joint-embedding 대비 50% 계산/메모리 절감
- ViT-L/7 사전 학습: 18 AWS p4d-24xlarge (마스킹 없으면 42대 필요)
결론적으로, MSN은 마스킹 + joint-embedding 결합으로 의미적 표현, low-shot 성능, 계산 효율성 동시 달성
→ 기존 마스크 기반 방법의 재구성 부담 제거, 라벨 효율적 학습의 새로운 패러다임 제시
2. Prerequisites
Problem Formulation
- 대량의 비라벨 이미지 와 소량의 라벨 이미지 () 주어짐
- 의 이미지는 와 일부 중복 가능
- 목표:
- 에서 사전 학습(pre-training)으로 표현 학습
- 를 사용해 감독 태스크(supervised task)로 표현 적응
Siamese Networks
-
목표: 동일 이미지의 두 뷰(views)에 대해 유사한 임베딩 출력하는 인코더 학습
- 인코더 → 뷰 , 각각 처리
- Anchor 표현
- Target 표현
- 핵심: 뷰 간 차이에 불감(invariant)하도록 유도
- 인코더 → 뷰 , 각각 처리
-
인코더 구조: 일반적으로 딥 네트워크, 파라미터
-
주요 도전 과제: 표현 붕괴(representation collapse)
- 인코더가 입력 무관하게 상수 임베딩 출력하는 현상 방지 필요
-
붕괴 방지 기법:
- Contrastive Loss: 서로 다른 이미지의 임베딩 명시적 반발
- Information Maximization: 평균 예측의 엔트로피 최대화 또는 임베딩을 구면에 균일 분포
- Asymmetric Architecture:
- Stop-gradient, Momentum Encoder 사용
- Decorrelation: 임베딩 벡터 성분 간 상관성 최소화 → 샘플 간 중복 감소
Vision Transformer (ViT)
- 인코더 아키텍처: 표준 ViT 사용
- 입력 처리 과정:
- 이미지 → 비중첩 패치(non-overlapping patches) 추출 (해상도 )
- 선형 레이어 → 패치 토큰 생성
- 학습 가능한 위치 임베딩(positional embeddings) 추가
- 추가 [CLS] 토큰 삽입 → 전체 시퀀스 정보 집약 목적
- Transformer 레이어 스택:
- 각 레이어: Self-Attention + Fully-Connected Layer + Skip Connection
- Self-Attention: 전체 시퀀스에 어텐션 메커니즘 적용 → 표현 갱신
- 출력: [CLS] 토큰의 최종 표현 → 인코더 출력 임베딩으로 사용
3. Masked Siamese Networks
MSN 학습 절차 개요
-
Masked Siamese Network (MSN) 은 invariance-based 사전 학습 + mask denoising 결합
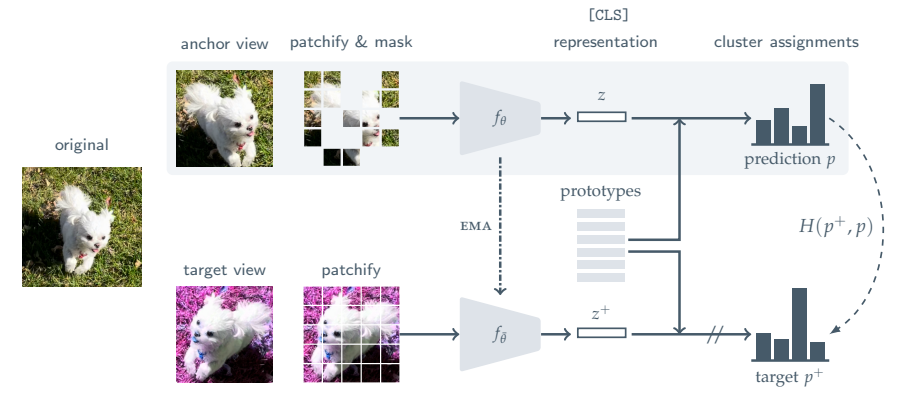
-
핵심 흐름:
- 랜덤 데이터 증강 → 이미지의 두 뷰 생성: anchor view, target view
- anchor view에만 랜덤 마스크 적용, target view는 변경 없음
- 클러스터링 기반 SSL 과 유사하게, 프로토타입(prototypes) 집합에 대한 소프트 분포(soft-distribution) 계산
- 마스킹된 anchor 뷰 표현 → 비마스킹 target 뷰와 동일한 프로토타입 할당
- 표준 cross-entropy loss 로 최적화
-
기존 masked image modeling과의 차별점:
- Generative 아님, Discriminative 접근
- 마스킹된 패치의 픽셀/토큰 직접 예측 없음
- Loss는 [CLS] 토큰 출력에 직접 적용
Input Views
- 미니배치 샘플링: 개 이미지
- 에 대해 이미지
- 뷰 생성:
- Target view : 랜덤 증강 적용
- Anchor view (): 각각 독립적 증강
Patchify and Mask
- 패치화(Patchify): 각 뷰 → 비중첩 패치 시퀀스 변환
- 마스킹(Masking): anchor 뷰에만 적용
- : 마스킹된 anchor 패치 시퀀스
- : 비마스킹 target 패치 시퀀스
- 마스킹으로 인해 시퀀스 길이 달라질 수 있음

- 마스킹 전략:
- Random Masking
- 시퀀스 전반에 걸쳐 비연속적 패치 무작위 드롭
- Focal Masking
- 연속적인 로컬 블록 무작위 선택 → 해당 영역 주변 모든 패치 드롭
- Random Masking
Encoder
- Anchor Encoder → 마스킹된 anchor 뷰 처리
- Target Encoder → 비마스킹 target 뷰 처리
- : anchor 인코더 파라미터의 EMA(Exponential Moving Average)로 갱신
- 공통 구조: ViT trunk, 출력은 [CLS] 토큰 표현
Similarity Metric and Predictions
- 학습 가능한 프로토타입 ()
- 예측 분포 계산:
- Anchor 예측 :
- : 온도 파라미터
- Target 예측 :
- : target sharpening → 저엔트로피 예측 유도
- 붕괴 방지에 필수 (Appendix B 이론적 증명)
- : target sharpening → 저엔트로피 예측 유도
- Anchor 예측 :
Training Objective
-
기본 손실: anchor 예측과 target 예측 간 cross-entropy
-
ME-MAX 정규화 (Mean Entropy Maximization):
- 전체 anchor 예측 평균:
- 엔트로피 최대화 → 최대화 (즉, 최소화)
- 프로토타입 고르게 활용 유도
- 전체 anchor 예측 평균:
-
최종 목적함수 (최소화):
- : ME-MAX 가중치
- Gradient는 anchor 예측에만 전파, target 예측은 stop-gradient
결론적으로, MSN은 마스킹된 뷰의 표현 정렬 + 프로토타입 기반 클러스터링 + 엔트로피 정규화로
→ 저수준 재구성 없이도 강력한 의미적 표현 학습, 붕괴 방지, 계산 효율성 동시에 달성
4. Related Work
4.1. View-Invariant Joint Embedding Architectures
- 비지도 사전 학습은 view-invariant 표현 학습 + joint embedding 아키텍처로 급진전
- DINO 가 가장 유사
- Siamese Network + cross-entropy loss + momentum encoder
- Multi-crop training → focal masking 형태, 단 비마스킹 anchor 뷰 필수
- MSN과의 관계:
- DINO의 일반화 → random / focal masking 모두 활용, 비마스킹 anchor 불필요
- Gradient는 anchor 예측에만 전파 → 마스킹 뷰 활성화만 저장
- 계산 및 메모리 요구량 대폭 감소
- 붕괴 방지 메커니즘 차이:
- DINO: centering + sharpening
- MSN: entropy maximization (ME-MAX)
- 실험 결과: MSN은 다양한 감독 수준(supervision degree)에서 DINO 우위
- DINO 가 가장 유사
4.2. Generative Masked Image Modeling
- 입력 일부 제거 → 재구성 예측하는 SSL 전통
- 초기 접근:
- 색상화(colorization): 증강 채널 예측
- Context Encoders: 주변 기반으로 결측 이미지 영역 생성
- 최근 ViT 기반 MIM:
- 마스크 노이즈 적용 → 픽셀 수준(MAE 등) 또는 토크나이저 기반(BEiT 등) 결측 값 예측
- 초기 접근:
- MSN과의 차별점:
- 입력 수준 예측 없음
- 노이즈 입력의 전역 표현 = 원본 입력의 전역 표현 되도록 암시적 denoising
- 저수준 픽셀 모델링 회피
4.3. Joint-Embedding + Denoising 하이브리드 접근
-
최근 연구 동향: joint-embedding + denoising 결합 탐구
- 공통 방식:
- 마스킹 패치 → 학습 가능한 마스크 토큰 대체
- 패치 수준 벡터 출력 → target encoder의 해당 패치 토큰과 직접 매칭
- 추가 손실:
- iBOT, SplitMask: 전역 표현([CLS] 또는 평균 풀링)에 joint-embedding loss 적용
- SplitMask: 패치 수준 손실로 비라벨 사전 학습 데이터 감소 가능성 입증
- data2vec: 비전, 음성, 텍스트 등 다중 모달리티 적용 가능성 제시
- 공통 방식:
-
MSN과의 핵심 차이:
- 패치 수준 손실 전혀 사용 안 함 → 전역 뷰 표현만 정렬
- 마스킹된 패치 완전 무시 → 계산 및 메모리 효율성 극대화
- ViT-L/7 학습 시 70% 이상 패치 마스킹 → 메모리/연산량 50% 절감
결론적으로, MSN은 DINO의 계산 효율적 일반화 + MIM의 재구성 부담 제거 + 하이브리드 접근의 패치 손실 배제로
→ 라벨 효율성(labeled data reduction)에 초점, off-the-shelf 표현 강화, 스케일링 우수성 달성
5. Results
평가 설정
- 사전 학습 데이터: ImageNet-1K
- 기본 하이퍼파라미터:
- 배치 크기: 1024
- 각 이미지당 anchor 뷰: 1 random mask + 10 focal mask
- 마스킹 비율: 모델 크기에 따라 최적화 (대형 모델일수록 더 많은 패치 드롭 유리)
- 구현 세부사항: Appendix A 참조
5.1. Label-Efficient Learning
5.1.1. Extreme Low-Shot (1~5 images/class)
-
극저 라벨 평가: ImageNet-1K 사전 학습 모델 → 1, 2, 5 라벨/클래스로 분류 성능 측정
-
비교 대상:
- Joint-embedding: DINO
- Auto-encoding: MAE
- Hybrid: iBOT (joint-embedding + 패치 수준 토큰 손실)
- 공식 릴리스 모델 사용
-
적응 프로토콜:
- Joint-embedding (MSN, DINO): 가중치 고정 + 선형 분류기 학습
- MAE: Partial fine-tuning (마지막 블록 + 헤드 미세조정), 단 ViT-H/14 또는 1 image/class는 선형 분류기
- 과적합 방지를 위해 ViT-H/14는 선형 프로브 사용 (Appendix C 상세 비교)
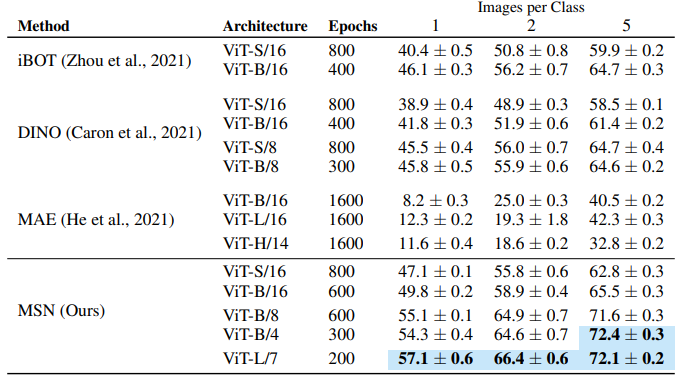
Table 1: Extreme Low-Shot ImageNet-1K (Top-1 Accuracy)
(1, 2, 5 images/class)
- 주요 관찰:
- MSN, 모든 감독 수준에서 타 방법 압도
- 라벨 감소 시 성능 격차 확대 → 라벨 효율성 극대화
- 모델 크기 증가 효과:
- 깊은 모델 + 작은 패치 크기 → 저라벨 설정에서 더 큰 이득
- Joint-embedding > Auto-encoding:
- Invariance 기반 유도 편향 → 저라벨 환경에서 강건한 의미적 표현
- 픽셀 재구성 손실 → 저수준 표현 → low-shot에서 과적합 취약
5.1.2. 1% ImageNet-1K
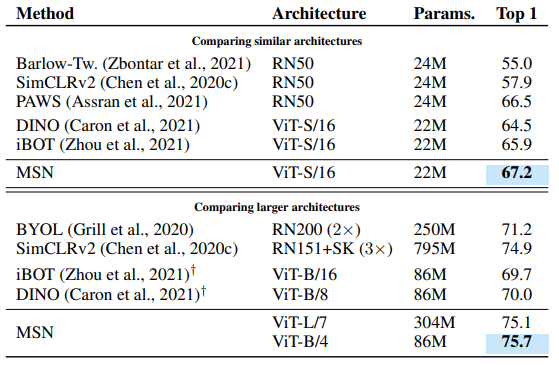
Table 2: 1% ImageNet-1K (Top-1 Accuracy)
- 기준 SOTA: 76.6% (멀티스테이지 반감독, ResNet-152 3× wide + self-distillation)
- MSN ViT-B/4 → 75.7% top-1
- 800M 파라미터 ConvNet SOTA 능가
- fine-tuning 없이, 파라미터 대폭 감소
- 동일 FLOP 비교 → MSN, 기존 SSL 방법 일관된 우위
5.2. Linear Evaluation and Fine-tuning
5.2.1. Linear Evaluation (100% ImageNet-1K)
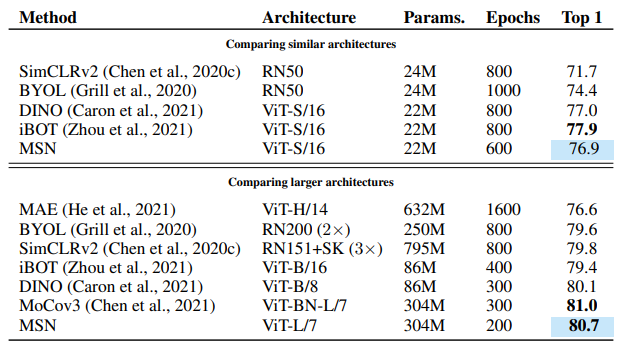
Table 3: ImageNet-1K Linear Probing (Top-1 Accuracy)
- MSN 최고 성능: 80.7% top-1
- SOTA와 경쟁력 있는 성능
5.2.2. Fine-Tuning (100% ImageNet-1K)
- 모델: ViT-B/16
- 프로토콜: 동일 fine-tuning 설정 (Appendix A)
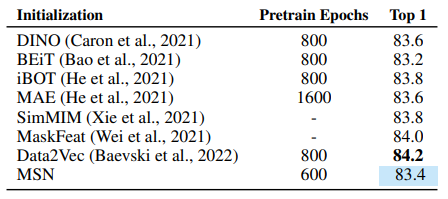
Table 4: ImageNet-1K Fine-tuning (Top-1 Accuracy)
- MSN, joint-embedding (DINO) 및 generative (MAE) 와 경쟁력 동등
- 라벨 풍부 환경에서도 견고함 입증
MSN은 극저 라벨 ~ 전체 라벨에 이르는 광범위한 감독 스펙트럼에서
→ SOTA 수준 off-the-shelf 표현, 라벨 효율성 극대화, 스케일링 우수성 동시 달성
→ 마스킹 + joint-embedding의 시너지로 새로운 SSL 패러다임 제시
5.3. Transfer Learning
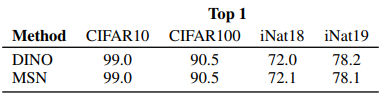
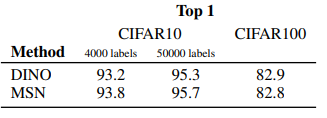
Table 5 & 6: Transfer Learning on CIFAR10, CIFAR100, iNaturalist
(ViT-B/16, ImageNet-1K 사전 학습)
- 모든 태스크 + 감독 수준에서 MSN = DINO 또는 우위
- CIFAR10/100, iNaturalist 전반에 걸쳐 경쟁력 또는 SOTA
- 추가 이점: MSN 사전 학습은 anchor 마스킹으로 DINO보다 계산 비용 낮음
- 메모리 및 연산 효율성 우수
5.4. Ablations
- 평가 방식: 1% ImageNet-1K 라벨 (~13 imgs/class) → 가중치 고정 + 로지스틱 회귀 분류기
5.4.1. Combining Random and Focal Masking

Table 7: Masking 전략 비교 (1% Low-shot Top-1 Accuracy)
- 주요 인사이트:
- Random Masking 필수 → No Masking보다 항상 우수
- Focal Masking 단독 사용 → 전역 뷰 손실 → 성능 저하
- Random + Focal 조합 → 최적의 균형, 가장 강력한 표현
5.4.2. Random Masking Ratio vs. Model Size
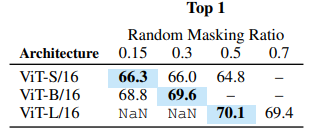
Table 8: 모델 크기별 최적 Random Masking 비율 (1% Low-shot)
- 대형 모델일수록 높은 마스킹 비율 선호
- ViT-L/7: 70% 이상 마스킹 → 최적 성능
- 모델 용량 증가 → 더 많은 패치 드롭 허용, 정보 병목 유도 → 의미적 표현 강화
5.4.3. Data Augmentation Strategy

Table 9: 뷰 생성 전략 비교 (1% Low-shot Top-1 Accuracy)
- 색상 공유 → 색상 통계 쇼트컷 → 붕괴
- 기하 증강 독립 적용 → 뷰 불변성 학습 필수, low-shot 성능 극대화
5.4.4. Random Masking Compute and Memory
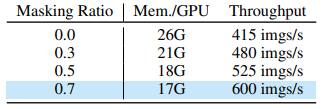
Table 10: ViT-L/7 사전 학습 효율성 (AWS p4d-24xlarge, batch=2/GPU)
- 70% 마스킹 → 메모리/연산량 50% 절감
- ViT-L/7 full-precision (patch 7×7) 사전 학습:
- MSN: 18대 머신
- No Masking (배치 1024): 42대 이상 필요
- ViT-L/7 full-precision (patch 7×7) 사전 학습:
- 10 focal view는 마스킹 비율과 무관 → global anchor 뷰 마스킹만으로 효율성 극대화
MSN은 Random + Focal 마스킹 조합, 모델 크기 맞춤 마스킹 비율, 독립 기하 증강, 고비율 마스킹을 통해
→ 극저 라벨 성능, 전이 학습, 계산 효율성 동시 달성
→ 마스킹 기반 joint-embedding의 설계 원칙 명확히 정립
6. Conclusion
-
Masked Siamese Networks (MSN) 제안
- 마스크 denoising 아이디어 활용, 픽셀/토큰 수준 재구성 완전 배제
- 핵심 기여:
- 강력한 off-the-shelf 표현 학습 → 라벨 효율적 학습(label-efficient)에서 SOTA 또는 압도적 우위
- Joint-embedding 아키텍처의 확장성(scalability) 동시 개선
- 마스킹된 anchor 뷰 처리 → 계산/메모리 50% 이상 절감
- 대형 ViT 모델도 소수 GPU 클러스터로 사전 학습 가능
-
한계 및 미래 연구 방향:
- 뷰 불변성(view-invariance) 기반 → 데이터 변환(data transformations) 명시 필요
- 최적 변환/불변성은 데이터셋 및 태스크 의존적일 수 있음
- 향후 계획:
- 유연한 변환 학습 메커니즘 탐구
- 등변 표현(equivariant representations) 도입 검토
- 뷰 불변성(view-invariance) 기반 → 데이터 변환(data transformations) 명시 필요
