https://arxiv.org/abs/2401.08541
Abstract
- 본 논문은 AIM을 제안, 이는 자동 회귀 목적(Autoregressive objective)으로 사전 훈련된 시각 모델의 집합
- 이 모델들은 텍스트 모델인 대형 언어 모델(Large Language Models, LLMs)에서 영감을 받았으며 비슷한 확장 특성을 나타냄
- 구체적으로 두 가지 주요 발견을 강조
(1) Visual feature의 성능은 모델 용량과 데이터 양과 함께 확장되는 것
(2) Objective 함수의 가치는 모델의 Downstream task에서의 성능과 관련이 있음 - 20억 개의 이미지에서 70억 개의 파라미터 AIM을 사전 훈련하여 ImageNet1k에서 84.0%의 정확도를 달성하는 것을 보여줌
- 흥미롭게도, 이러한 규모에서도 성능의 포화(Saturation) 징후를 관찰하지 못하며, 이는 AIM이 대규모 시각 모델을 훈련하는 새로운 지평선을 대표할 수 있다는 가능성을 시사
- AIM의 사전 훈련은 LLM의 사전 훈련과 유사하며, 규모에 맞춰 훈련을 안정화시키기 위한 이미지별 전략이 필요하지 않음
1. Introduction
- 최근 대형 언어 모델(LLMs)의 혁명으로 인해, 사전 학습 작업에 중립적인 모델을 사전 훈련하는 것이 자연어 처리의 표준이 됨
- 이러한 성공에 기여하는 주요 요인 중 하나는 Capacity(즉, 매개 변수 수) 또는 사전 학습 데이터의 양이 증가함에 따라 일관되게 개선할 수 있는 능력임
- 이러한 모델의 확장 행동(Scaling behavior)은 두 가지 주요 이유가 있음
1) 간단한 목적으로 학습되었지만(즉, 문장에서 다음 단어를 예측하는 것), 긴 문맥에서 복잡한 패턴을 학습할 수 있음
2) 이 Autoregressive objective의 확장성은 특정 아키텍처와 특히 Transformers와 함께 사용될 때 주로 관찰 - Transformer 아키텍처는 Vision Transformers(ViT)의 성공과 함께 컴퓨터 비전과 같은 다른 영역에서도 성공적으로 사용됨
- 따라서 LLMs의 결과를 일반화하기 위한 첫 번째 단계로, ViT 모델을 Autoregressive objective로 학습시켜 동일한 확장성을 갖는 표현 학습 면에서 경쟁력 있는 성능을 보여주는지 탐색
- 본 논문에서는 대규모 visual feature에 대한 대규모 사전 학습을 위한 자기회귀 접근 방식인 Autoregressive Image Models(AIM)을 제안
- ViT, 대규모 웹 데이터 컬렉션 및 최근 LLM 사전 학습의 최신 기술이 포함
2. Related Work
Autoregressive models
- Autoregressive 모델들은 대부분의 연구가 언어 모델링이나 음성에서 나왔지만, 이미지에 대한 이 접근 방식의 잠재력을 탐색한 연구는 거의 없음
Vanden Oord et al.는 이미지에 적합한 아키텍처, 예를 들어 CNN을 사용하여 구축된 Autoregressive 모델이 보다 일반적인 아키텍처인 RNN보다 크게 향상된 것을 보여줌
Self-supervised pre-training
- 다양한 proxy tasks에 중점을 둔 다양한 접근 방식이 사용
Noroozi와 Favaro는 이미지 패치의 순서를 재배열하는 방법을 학습, 다른 연구들은 클러스터링을 사용
- 또 다른 인기있는 접근 방법은 각 이미지를 식별하는 것을 목표로 하는 예측 코딩과 유사한 대조적 목적을 사용하는 것
가장 최근의 대조적인 접근 방식은 DINO, BYOL 또는 iBot 등을 포함
- 본 논문에서 가까운 작업은 BERT에서 영감을 받음
여기서 패치는 이산(discrete) 또는 픽셀 형태의 auto encoder로 마스킹되고 예측
Other generative pre-training
- Autoregressive 모델링은 생성 모델링의 한 형태이며, 시각적 특성을 학습하기 위해 고려된 몇 가지 다른 생성적 접근 방식이 있음
- 첫 번째 범주는 사전 텍스트 작업이 어떤 방식의 오토 인코딩을 활용
예를 들어, noise는 salt and pepper 또는 masking과 같은 것
- 다른 작업은 생성적 적대 신경망(GANs)을 활용
가장 유명한 것은 BigGAN으로, 이는 큰 GAN을 훈련하고 이미지 판별자를 재사용하여 이미지 특성을 생성
더 최근에는 Diffusion MAE가 이미지 특성을 학습하기 위해 diffusion 모델을 사용
Pre-training at scale
- 시각적 특성의 사전 학습을 비지도 학습으로 확장하는 작업
- 이 분야에서 가장 주목할 만한 작업 중 하나는 DINOv2
142M개의 이미지와 460M개의 매개 변수를 가진 모델에 iBot 방법을 확장하여 최고의 SSL feature를 생성
3. Pre-training Dataset
- 본 논문에서는 Fang et al. 소개한 DFN 데이터셋에서 모델을 사전 학습
- 이 데이터셋은 Common Crawl로부터 추출된 128억 개의 이미지-텍스트 쌍으로 구성
- 데이터는 NSFW 콘텐츠를 제거하고 얼굴을 흐리게(blur faces) 하며, 평가 세트와의 중복을 제거하여 오염을 줄이는 전처리가 이루어 짐
- 데이터 필터링 네트워크는 이미지와 해당 캡션 간의 정렬 점수에 따라 128억 개의 샘플을 순위 매김
- DataComp 12.8B 데이터셋에서 상위 15%의 샘플을 유지하여 DFN2B라고 불리는 20억 개의 이미지 하위 집합이 추출
- 개인 정보 및 안전 필터링을 제외하고, 이 프로세스에는 이미지 콘텐츠에 기반한 추가적인 선별이 포함되지 않음
- 텍스트가 필요하지 않기 때문에, 이 방법은 캡션과 짝지어지지 않은 이미지 컬렉션 또는 DataComp 12.8B의 나머지와 같이 이미지-텍스트 정렬이 낮은 이미지 컬렉션을 사용하여 사전 학습될 수 있음
- LLM 사전 학습의 일반적인 관행에 영감을 받아
사전 학습 중에는 DFN-2B에서 확률 p = 0.8로 이미지를 샘플링
ImageNet-1k에서는 확률 p = 0.2로 이미지를 샘플링 - 이러한 데이터셋을 DFN-2B+이라고 함
4. Approach
4.1. Training Objective
- 학습의 목표는 이미지 패치의 시퀀스에 적용된 standard autoregressive model과 동일
- 이미지 x는 K개의 겹치지 않는 패치 x_k, k ∈ [1, K]로 나누어 짐
- 이들은 함께 토큰의 시퀀스를 형성
- 이 시퀀스 순서가 모든 이미지에 걸쳐 고정되어 있고, 기본적으로는 raster (row-major) 순서를 사용
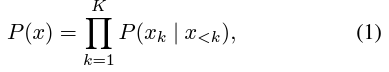
- 여기서 x<k는 첫 번째 k-1개 패치의 집합을 의미, k번째 패치를 예측하는 데 사용되는 문맥
- 언어 모델링과는 달리, 시퀀스는 메모리에 맞는 길이 K로 고정되어 있으므로 문맥 길이를 잘라내는 필요가 없음
- 이미지 집합 X에 대한 training loss는 negative log-likelihood (NLL)로 정의
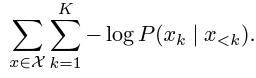
- 이 목적 함수를 무한한 이미지 집합에 대해 최소화하는 것은 이론적으로는 실제 기저(underlying) 이미지 분포를 학습하는 것과 동등
Prediction loss
- 학습 목표는 주어진 분포 P(xk|x<k)의 선택에 대응하는 일련의 loss의 특정 변형을 자연스럽게 만듦
- 기본적으로는 He et al.의 방법과 유사한normalized pixel-level regression loss를 채택
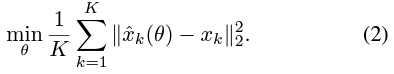
4.2. Architecture
- backbone으로는 ViT를 채택
- 언어 모델링에서의 공통적인 실천법을 따르고, 깊이(depth)보다는 너비(width)를 확장하는 것을 우선
- Table 1에서는 AIM의 설계 매개변수 개요를 제공하며, 각 모델 용량에 대한 데이터 양 및 최적화 체계를 포함

- 전체 모델은 Figure 2에서 설명

- 입력 이미지는 겹치지 않는 패치로 분할되고 선형으로 임베딩
- 패치 feature는 선행 위치에 대한 관찰을 방지하기 위해 인과적으로 마스킹된 self-attention 작업을 가진 transformer에 공급
- 그 후, 매개 변수가 많은 MLP가 각 패치 특성을 독립적으로 처리하고 최종적으로 픽셀 공간으로 투영
- 타겟은 입력 시퀀스를 왼쪽으로 한 위치 이동시킨 것에 해당하며, 이는 모델이 다음 패치를 "raster order"로 예측하도록 요구
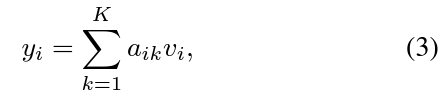
- 사전 학습 중에는 이전 패치가 주어졌을 때 패치의 확률을 모델링하기 위해 self-attention 레이어에 인과적 마스크를 적용
- 더 정확히는, self-attention 레이어가 주어졌을 때, 패치 i의 임베딩은 위와 같이 계산
Prefix Transformer
- PrefixLM 제안에 따라 시퀀스의 초기 패치를 고려하여, 즉 Prefix로, 나머지 패치를 예측하기 위한 문맥으로 고려
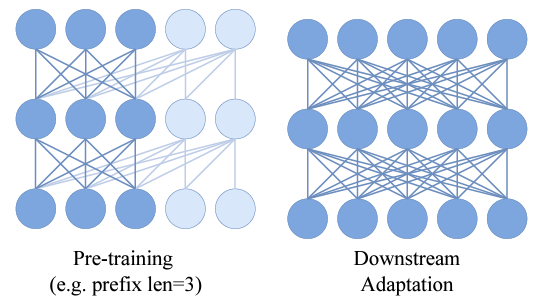
- 사전 학습 중에는 prefix 길이 S를 균일하게 샘플링
- 첫 번째 S개의 패치에 대한 어텐션은 양방향으로 설정되고, 이미지의 나머지 패치에 대해서만 loss 계산
- Downstream task에 대한 adaption 중에는 이렇게 함으로써 attention casual mask를 제거할 수 있으며, 이는 Downstream task의 성능을 향상시킴
MLP prediction heads
- 사전 학습 중 특정 예측 헤드를 채택하는 것은 일반적인 방법
- 이러한 헤드는 downstream task로 전환될 때 버려짐
- 이 헤드의 목적은 트렁크 기능이 사전 학습 목표에 너무 특수화되는 것을 방지하여 downstream transfer에 더 적합하게 만드는 것
5. Results
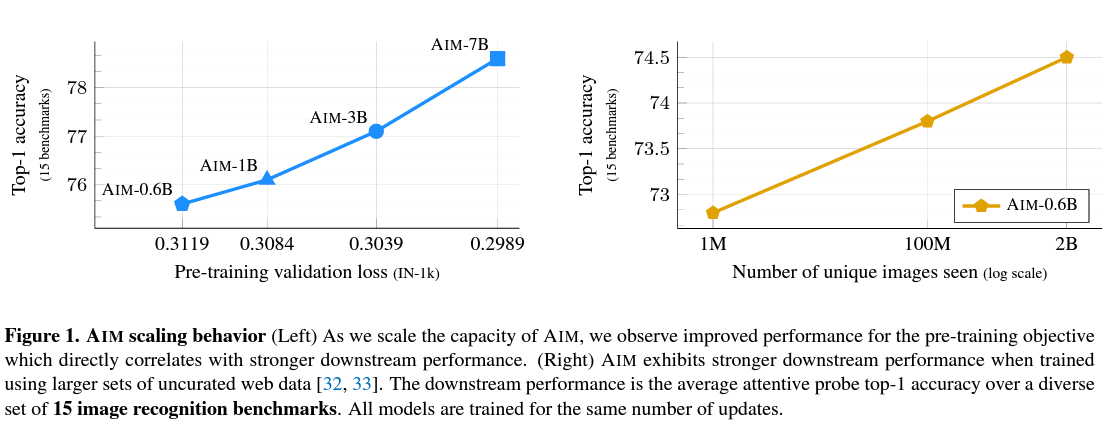
5.1. Impact of scaling
- 매개변수 및 학습 데이터 측면에서 확장할 때의 영향을 측정
- 스케일링이 손실 함수 값에 미치는 영향을 분석
Loss and performance during training
- Figure 4에서 각 모델에 대해 사전 학습 Loss 값과 검증 세트의 분류 정확도를 학습 반복 횟수의 함수로 측정

Number of parameters
- 모델 용량을 확장할수록 downstream task의 loss 값과 정확도가 향상되는 것을 관찰
- 이 관찰은 LLMs에서 관찰된 경향과 일관성이 있으며, 이는 강한 표현(stronger representations)을 학습하도록 우리의 목적 함수를 최적화하는 결과로 직접 연결될 수 있음
Number of images
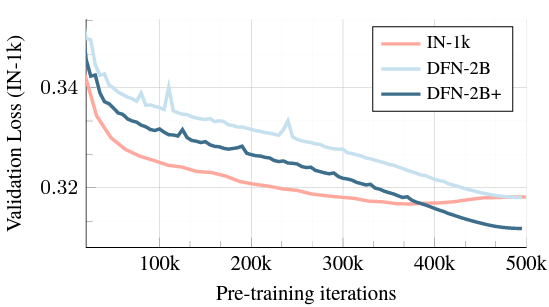
- 위 그림에서, IN-1k를 사용한 사전 학습이 AIM-0.6B 모델에서도 과적합을 유발
- 다른 한편으로는 uncurated DFN-2B 데이터 세트를 사용한 사전 학습은 과적합을 방지하지만 분포 변화로 인해 유사한 지점으로 수렴
- 주로 DFN-2B로 구성된 데이터 혼합물인 DFN2B+에서의 사전 훈련은 IN-1k 샘플의 소규모 존재로 인해 최상의 성능을 보여줌
Compute-optimal pre-training
- DFN-2B+를 사용하여 학습할 때 과적합의 징후를 관찰하지 않기 때문에, 사전 학습 일정의 길이를 연장하는 영향을 조사
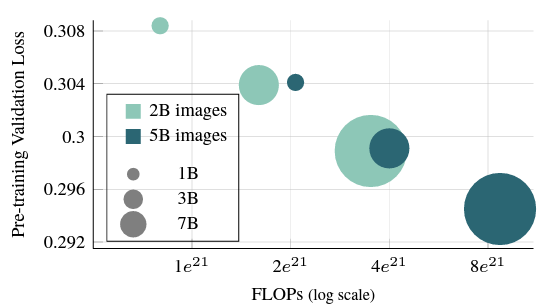
- 위 그림에서 사전 학습 일정의 길이를 500k에서 1.2M 반복까지 증가시키는 영향을 연구
- 즉, 사전 학습 중에 본 이미지의 수가 2B에서 5B로 증가
- 더 긴 학습으로 사전 학습된 모델이 상당히 낮은 검증 손실을 달성한다는 것을 관찰
- 흥미롭게도, 더 낮은 용량의 모델이 더 긴 일정으로 학습될 때 더 높은 용량의 모델보다 유사한 수준의 validation loss을 달성하는 것을 발견
- 이 결과는 Hoffmann 등의 연구와 일관성이 있으며, AIM이 유사한 스케일링 법칙을 따를 수 있다는 것을 시사
5.4.Comparison with other methods
- Table 6에서 AIM의 주의적 프로브 성능을 다른 최신 기법과 비교
- 이 비교는 Appendix A에 자세히 기술된 15가지 다양한 벤치마크를 통해 이루어 짐
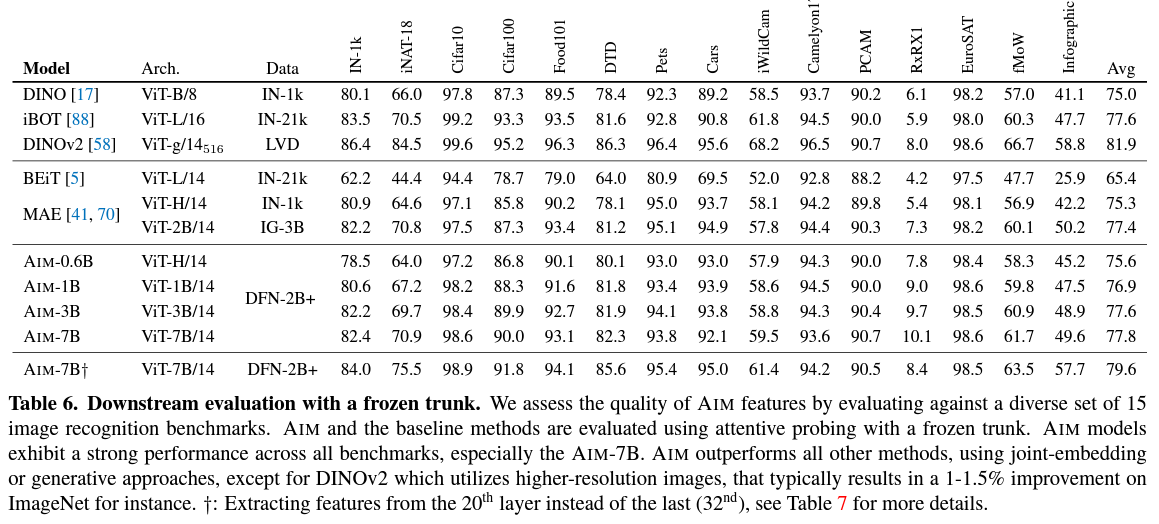
Generative methods
- AIM은 다른 생성 방법들에 비해 강력한 성능을 제공
- AIM은 BEiT 보다 큰 폭으로 성능이 우수
- AIM-0.6B는 MAE-H와 동등한 용량을 가진 모델과 비교하여 모든 벤치마크를 평균하면 더 나은 성능을 제공
- IG-3B, Instagram의 30억 장 이미지로 사전 훈련된 MAE-2B 모델과 비교
- AIM-3B 및 AIM-7B가 MAE-2B를 모두 능가하는 것으로 나타났으며, 특히 AIM-7B는 특히 큰 개선을 보여줌
- AIM과 마찬가지로 두 가지 다른 생성적 접근법인 BEiT 및 MAE도 attentive probing을 통해 이득을 얻어 generative 및 joint embedding 방법 간의 격차를 줄이는 데 도움이 됨
Joint embedding methods
- AIM은 DINO, iBOT, 그리고 DINOv2와 같은 joint embedding 방법과 경쟁력 있는 성능을 제공
- 모든 벤치마크를 평균한 정확도 측면에서 AIM은 DINO와 iBOT을 능가
- 그러나 AIM은 해상도가 더 높은 입력을 평가하여 결과를 얻는 DINOv2에는 뒤쳐짐
- AIM이 이러한 경쟁력 있는 성능을 달성하는 데는 더 높은 용량의 trunk를 사용하는 것
- 그럼에도 불구하고, AIM의 사전 학습은 훨씬 간단하며 매개변수 및 데이터 측면에서 쉽게 확장할 수 있으며 일관된 개선을 제공
- 반면에, DINOv2와 같은 최신의 joint embedding 방법은 강력한 성능을 얻기 위해 multi-crop augmentation, KoLeo 정규화, LayerScale, Stochastic Depth, teacher momentum 및 weight decay, 그리고 고해상도 fine-tuning과 같은 다양한 기교에 매우 의존
Extracting stronger features
- 사전 학습 목적의 생성적 특성이 downstream task의 판별적인(discriminative) feature와 본질적으로 다르기 때문에, 마지막 레이어의 feature와 비교하여 보다 얕은 레이어에서 보다 높은 품질의 특성을 추출할 수 있음을 관찰

- 따라서, 가장 의미 있는 내용을 담고 있는 feature가 반드시 마지막 레이어 주변에 집중되지는 않을 수 있음
6. Discussion
- 이 논문에서는 감독 없이 규모 있는 시각 모델의 사전 학습을 위한 간단하고 확장 가능한 방법을 제시
- 사전 학습 중 generative autoregressive objective을 활용하고 downstream task에 더 잘 적응하기 위해 여러 기술적 기여를 제안
- 결과적으로, Autoregressive Image Models에 대한 몇 가지 원하는 특성을 관찰
1) 모델의 용량은 각 모델 규모에 대해 안정성 유도 기술이나 많은 모델 규모에 대한 하이퍼파라미터의 범위 조정을 사용하지 않고도 손쉽게 70억 개의 매개변수로 확장될 수 있음
2) AIM의 사전 학습 작업에 대한 성능은 downstream 성능과 강한 상관 관계를 갖음
3) AIM은 15개의 recognition 벤치마크에서 강력한 성능을 발휘하여 MAE와 같은 이전 최신 기법을 능가하고 generative 및 joint embedding 사전 학습 접근법 간의 격차를 크게 줄임
4) 매개변수나 데이터의 규모를 확장함에 따라 포화(saturation)의 명확한 징후를 관찰하지 못했으며, 더 큰 모델을 더 긴 일정으로 훈련시킬 경우 더 많은 성능 향상이 가능할 것으로 보임 - AIM이 객체 중심(object-centric) 이미지에 편향되지 않거나 캡션에 강하게 의존하지 않는 현존하는 데이터셋을 효과적으로 활용하는 확장 가능한 비전 모델에 대한 미래 연구의 씨앗으로 기여하길 희망
