https://arxiv.org/abs/2306.05411
Abstract
- Vision-specific concepts인 '영역(region)'과 같은 것들은 객체 감지(object detection)와 같은 작업으로 일반적인 기계 학습 프레임워크를 확장하는 데 중요한 역할을 해옴
- Supervised learning을 위한 region-based detector의 성공과 contrastive learning의 intra-image 방법의 발전을 고려할 때, 우리는 reconstructive pre-training을 위한 region의 사용을 탐구
- Masked Autoencoding (MAE)를 기준으로 하고 영감을 받은 것으로 시작하여, 우리는 image와 region 간의 일대다 매핑에 대응하기 위해 맞춤형 병렬 pre-text task를 제안
- 이러한 region은 unsupervised 방식으로 생성될 수 있으므로, 우리의 접근 방식(R-MAE)은 MAE로부터의 광범위한 적용 가능성을 유지하면서도 보다 'region에 대한 인식'이 높음
- 본 논문에서 제안하는 R-MAE는, MAE에 비해 1.3%의 오버헤드를 갖는 효과적이고 효율적인 변형에 수렴
- 더불어, 이는 다양한 pre-training 데이터 및 downstream detection 및 segmentation 벤치마크에 일반화될 때 일관된 양적 개선을 보임
- 마지막으로, R-MAE의 동작 및 잠재력을 이해하기 위한 광범위한 qualitative visualizations를 제공
1. Introduction
- 컴퓨터 비전 및 특히 object detection과 같은 localization-geared task에 대해서는 ‘region’이라는 개념 중 하나가 있음
- 인간의 지각이 유사한 요소와 부분을 그룹화하여 복잡한 장면과 객체를 해석한다고 가정
- 이 가설은 R-CNN 시리즈에 의해 실험적으로 검증되었음
- 그럼에도 불구하고, region-refinement는 사람이 만든 주석에 기반한 최고의 성능 detector에서 여전히 필수 구성 요소로 남아 있음
- Masked Autoencoding(MAE)와 같은 reconstructive pre-training method는 더욱 효과적으로 입증되어 빠른 수렴을 넘어서 detection 정확도의 상한을 향상 시킴
- 아래 오른쪽 그림 처럼, 이러한 프레임워크에 어떻게 region을 도입할 수 있는지와 그것이 downstream 성능을 더욱 개선할 수 있는지는 아직 명확하지 않음
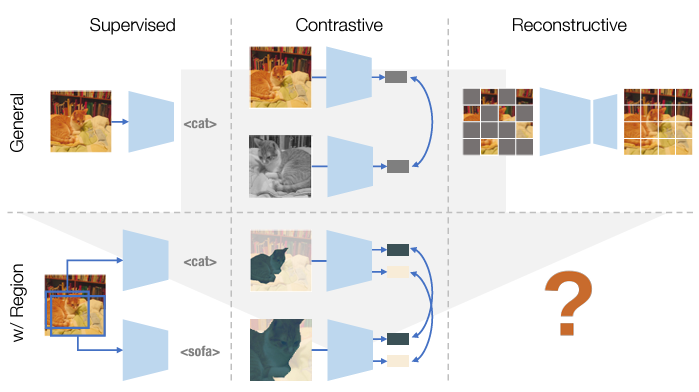
- 이 논문의 목표는 이 공백 (Masking)을 채우는 것
- 대표적인 기준으로서 MAE를 시작으로하고, MAE 스타일의 pre-computed된 region의 사용을 탐색
- 구체적으로는 'masked Region Autoencoding' (RAE)라는 pre-text task를 제안
- MAE와 유사하게, RAE도 reconstructive
- 그러나 MAE와 달리, RAE는 영역 또는 'region map'에 중점을 둠
- 이는 pixel이 region에 속하는지 여부를 나타내는 binary value map으로 region을 나타냄
2. Related Work
- 먼저 컴퓨터 비전에서 인기를 끌게 된 region의 두 가지 내재적 특성을 검토
Local
- 이미지는 일반적으로 기계 학습 알고리즘에서 전체적인 엔티티로 취급
- 현실 세계의 사진은 풍부한 공간 구조를 가지며 동일한 장면에서 local contents가 다양할 수 있음
- 이는 특히 지역 관심 영역(Region-of-Interest, RoI) 연산이 region feature map에 적용될 때 잘 알려진 R-CNN 시리즈에 대한 강력한 동기부여가 됨
- 반면에, reconstructive method는 denoising autoencoder와 같이 2D 구조를 보존
- 따라서 region이 이런 관점에서 어떻게 더 도움이 될 수 있는지는 아직 명확하지 않음
Object-centric
- 어쩌면 이것이 region이 MAE와 만나는 더욱 동기부여적인 이유일지도 모름
- Reconstructive learning은 자연어 representation의 pre-training에서 우세한 패러다임
- 그리고 꾸준한 진전이 이루어지고 있음에도 불구하고, 컴퓨터 비전 모델들은 여전히 뒤쳐지고 있음
- 두 분야 간의 중요한 차이점 중 하나는 언어가 의미 있는 단어로 구성되어 있지만 이미지는 픽셀로 기록된 raw signal 이라는 것
3. Approach
Background on Masked Autoencoding
- Masked Autoencoding (MAE)는 이미지의 일부를 균일하게 마스킹하고 원시 픽셀 값을 직접 예측하여 재구성하는 방식으로 학습 (Autoencoder)
- 이미지는 기본적으로 높은 마스크 비율 βI(예: 75%)을 사용
- Reconstruction은 간단한 l2 loss와 실제 값과 비교
- Pre-training 이후, 픽셀 인코더는 downstream task를 위한 visual backbone으로 사용
3.1 RAE: MASKED REGION AUTOENCODING
Region maps
- Masked region autoencoding을 수행하기 위해, 먼저 MAE를 따라가서 그것들을 'image-like' 하게 준비
- 구체적으로, 각 region은 이미지와 유사한 크기의 binary value region map으로 나타낼 수 있음
- Map 상의 각 요소는 해당 위치가 region에 속하는지 여부를 나타내는 0 또는 1의 값으로 구성
- 부분적으로 보이는 region map(마스크 비율 βR)가 주어졌을 때, 모델에게 pixel에 대해 MAE가 하는 것과 동일하게 예측하도록 요청
Architecture
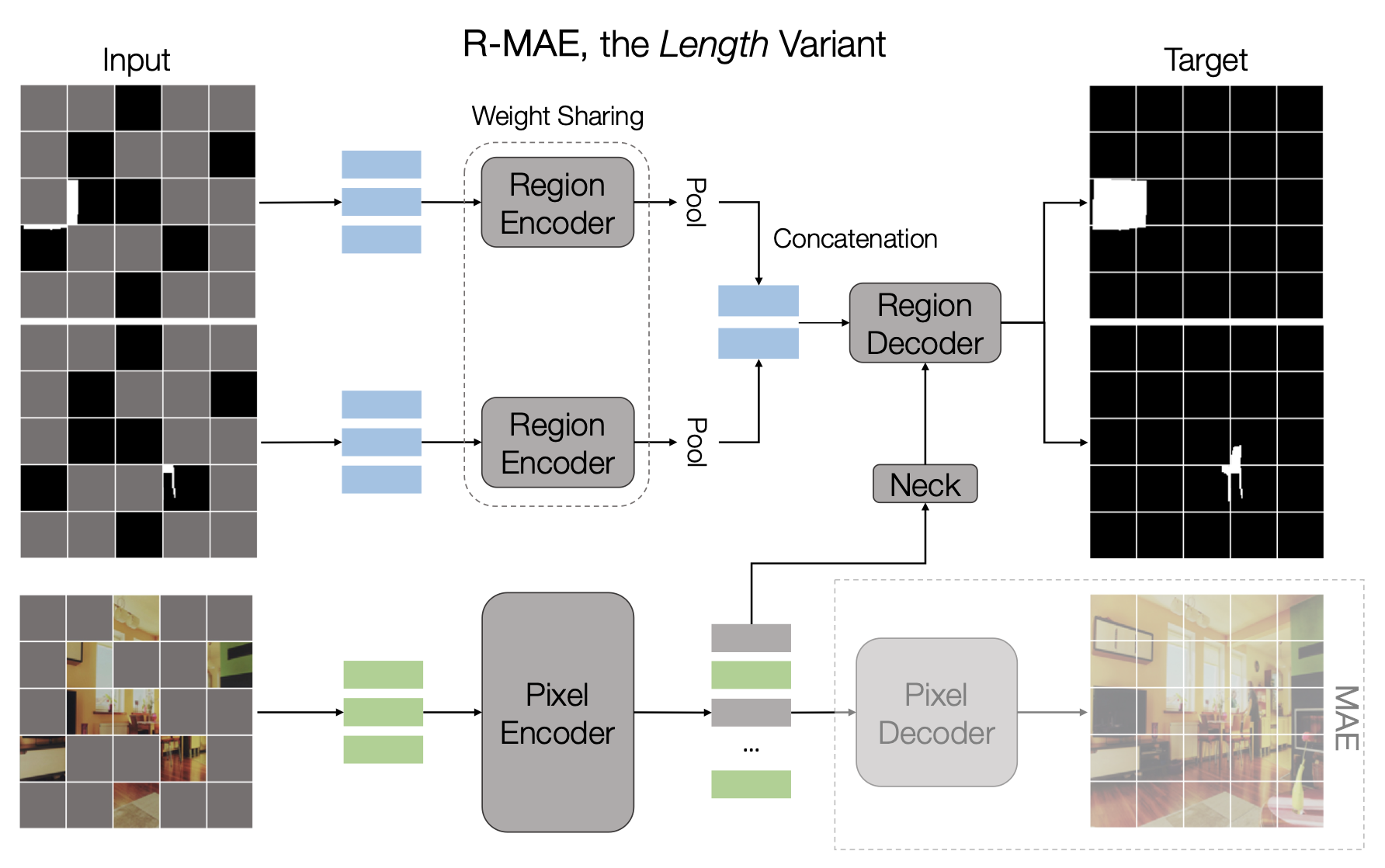
- MAE와 유사하게, region autoencoding을 위한 encoder와 decoder로 구성
- MAE와 같이 ViT 블록 사용
- 그러나 region encoder-decoder 쌍만으로는 충분하지 않음
- 궁극적인 목표는 pre-trained pixel encoder를 얻는 것이기 때문
- 따라서 pixel encoder를 유지하고, 차원을 맞추기 위해 단일 ViT 블록의 neck을 사용하고 (선택적으로) 정보를 전파한 후 region decoder로 입력
- 이러한 구성은 또한 효과적으로 pixel에서 사용 가능한 풍부한 context 정보를 사용하여 encoder를 pre-training
One-to-many mapping
- Region은 pixel-based MAE에 추가적인 모달리티로 간주될 수 있지만, 여기서 다루는 문제는 이러한 관점만으로 완전히 포착될 수 없는 독특한 도전을 제시
- 다른 모달리티(예: depth 또는 semantic maps)와 비교했을 때, 이미지와 region 간의 mapping은 일대다로 구성
(하나의 pixel은 알려지지 않은 수의 region에 속할 수 있음)
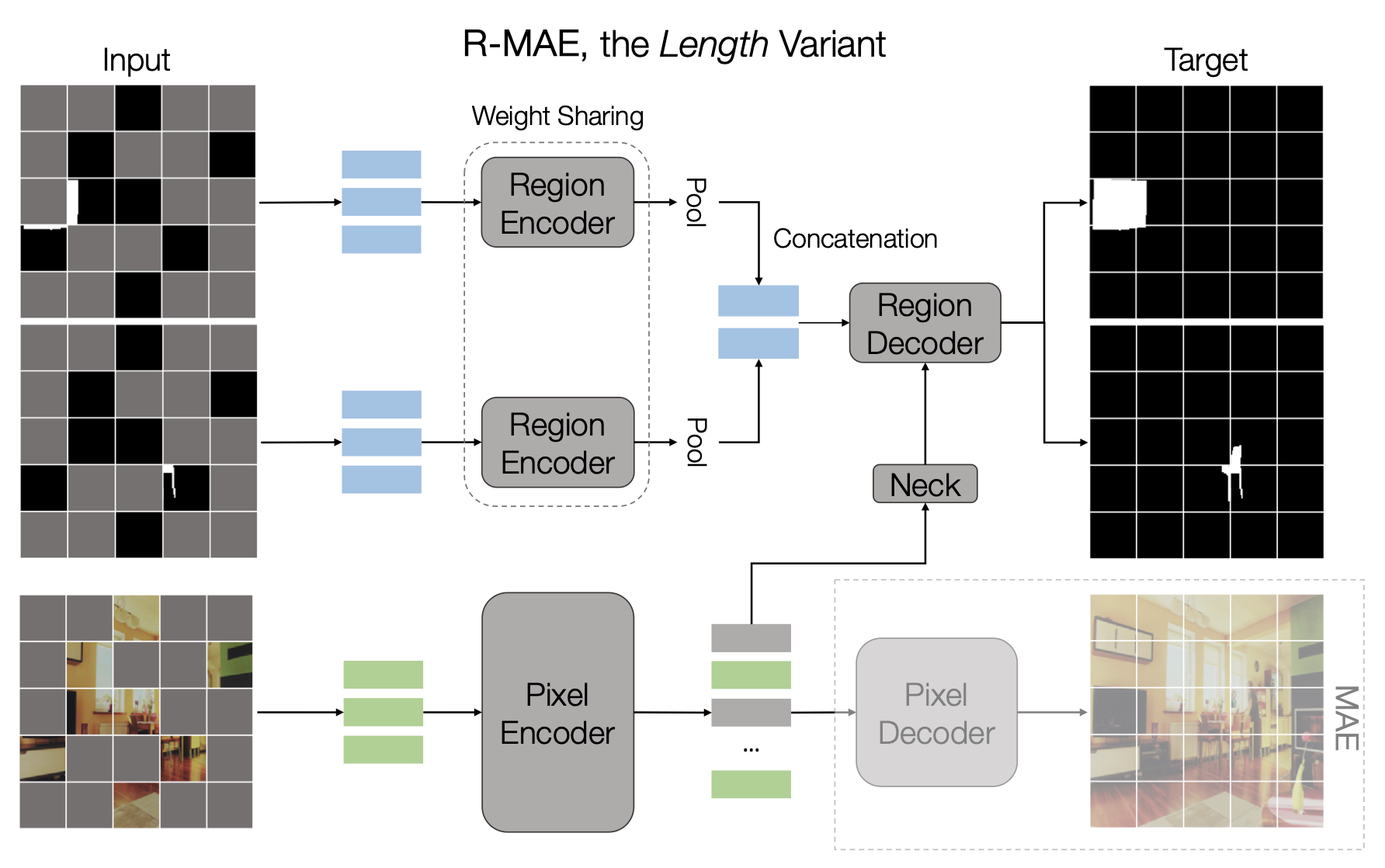
Regions as queries – the length variant
- 최종 아이디어는 DETR 시리즈에서 영감을 받았고, 'object queries'를 사용하여 object를 decoding 함
- 간략히 말하면, 각 region은 먼저 encoding되어 1차원 embedding으로 pooling
- 그런 다음 다양한 region embedding이 일련의 length axis를 따라 연결되어 'region query'를 형성
- 마지막으로, 이러한 region query는 pixel encoder의 출력에서 region map을 decoding 함
- 마지막 decoder block은 region query를 공간적으로 확장하는 역할을 담당
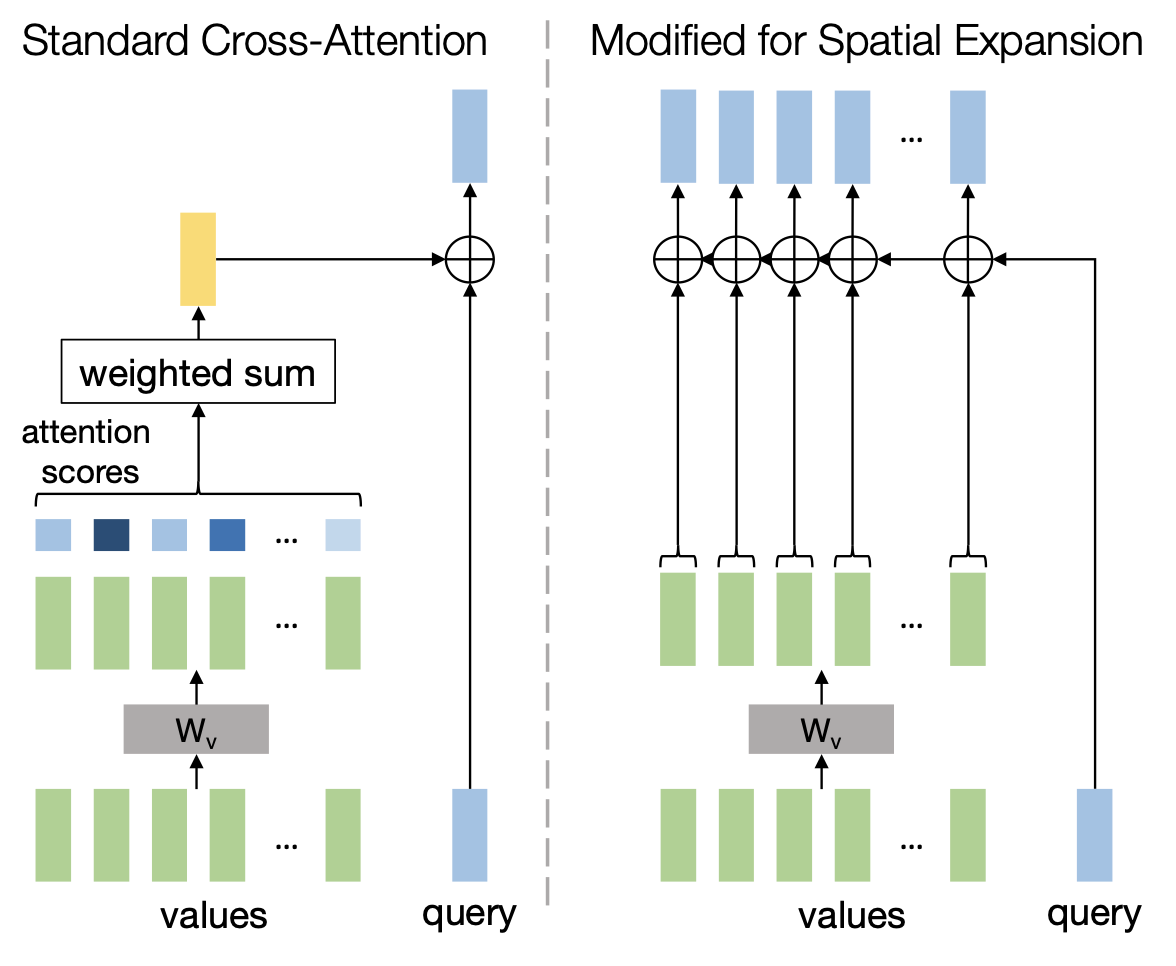
- Standard attention layer는 출력을 생성하기 위해 value 위에 weighted sum을 계산 (위 그림의 왼쪽)
- Query를 직접 모든 value에 추가하여 확장 (위 그림의 오른쪽)
- 그 후에는 작은 MLP head가 추가되어 이러한 공간적으로 확장된 feature를 기반으로 region map을 예측
- 이러한 변형은 region의 수 k에 대한 선형 복잡성을 완화시키고, 순열에 대한 원하는 특성을 유지하게 됨
Loss
- L2 loss는 real-valued pixel 예측에 적합하지만, 기본적으로 이진 분류에 효과적인 cross-entropy loss을 binary-valued region에 대해 사용
3.2 R-MAE: REGIONS MEET MAE
- 주의할 점은 다음과 같음
(i) Pixel branch는 region branch로 전달되지만 그 반대는 그렇지 않음
(ii) 마스크는 information leak을 방지하고 더 challenging pre-text task를 만드는 데 도움이 되도록 두 branch 사이에서 공유

- 흥미로운 점은 위 그림에서 R-MAE를 사용하여 pre-train 된 ViT feature가 supervised 없이, 이미지로 계산 가능한 region map를 사용하여 학습될 때, instance-aware 능력이 더 강화된다는 것임
- 특히, 이러한 ViT feature는 query를 기준으로 reconstruction(MAE (He et al., 2022)) 및 contrastive (MoCo v3 (Chen et al., 2021)) methods에 비해 더 많이 object에 집중하는 attention map을 보여줌
- R-MAE로 pre-train 된 ViT feature는 attention map을 통해 그것의 localization capabilitie을 드러내며, 서로 다른 위치의 object에 집중적으로 초점을 맞춤
4. EXPERIMENTS
Source of regions
- 기본적으로, Felzenswalb-Huttenlocher (FH) 알고리즘 (Felzenszwalb & Huttenlocher, 2004)으로부터 생성된 map를 사용
- 이 알고리즘은 unsupervised learning을 통해 이미지에서 생성되며 빠르고 효율적이며 전체 이미지를 다루기 때문에 클래식한 region proposal 방법임
- COCO 데이터 세트의 ground truth annotation인 panoptic region과 SAM 모델 (Kirillov et al., 2023)에서 생성된 region과 같은 다양한 소스에서 영역을 제거하기도 함
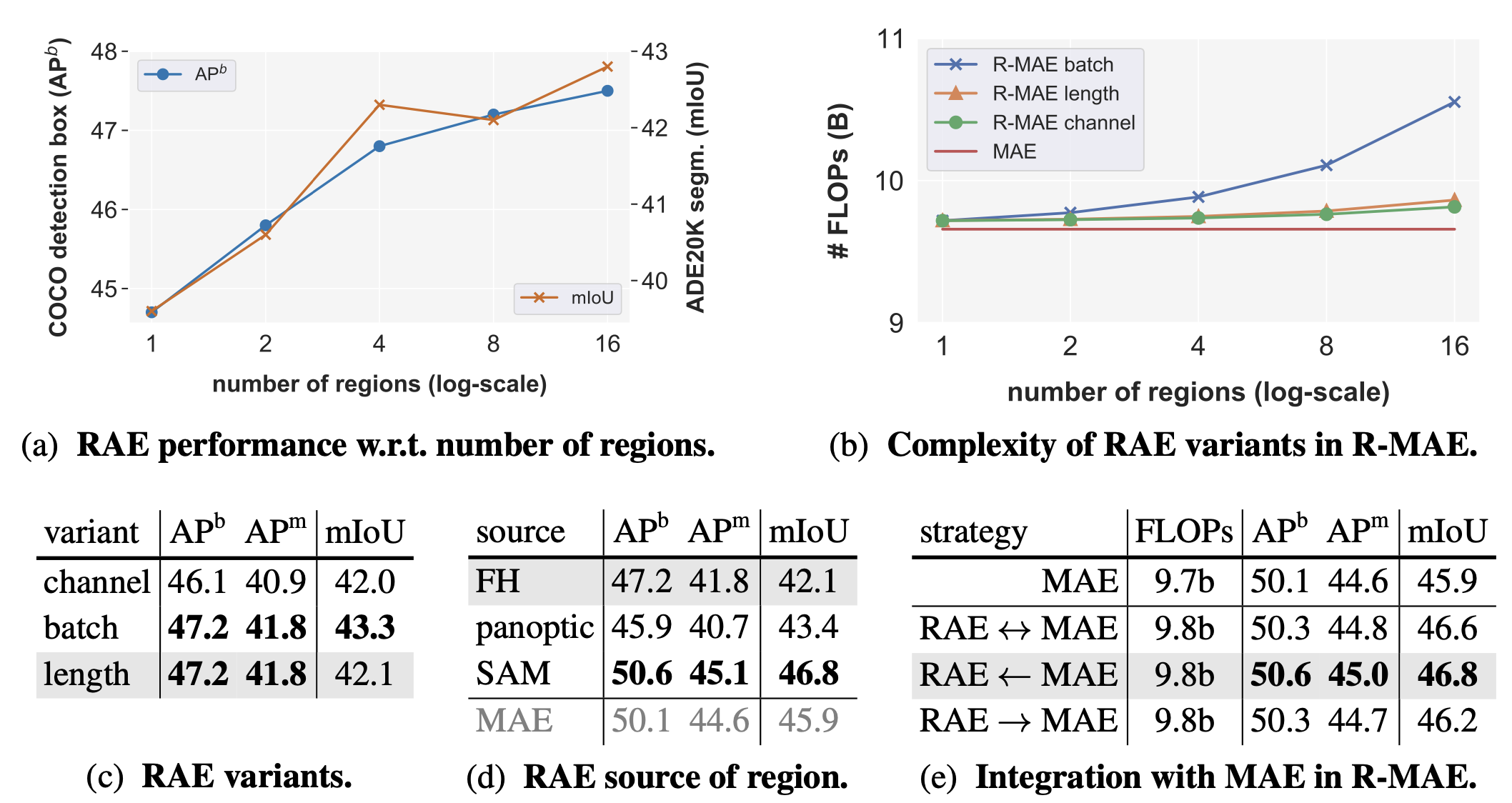
- 위의 테이블에서 (a)에서는 이미지당 region의 수에 관한 RAE의 성능을 보여줌. RAE는 pre-training 중에 이미지 당 더 많은 region을 샘플링 할 때 개선됨
- (b)와 (c)에서는 채널 변형이 아키텍처의 중간 블록에서 계산을 공유하기 때문에 효율적이지만, 성능은 뒤처지는 것으로 나타남. 이는 하나의 이미지 내에서 여러 region map의 순열 동치성을 학습하는 것이 어렵다는 것을 증명
- (d)에서는 다양한 소스에서 생성된 region을 사용한 RAE의 성능을 비교:
- FH region은 기본 설정으로, COCO의 panoptic region 및 SAM에서 생성된 region
- Panoptic region은 semantic segmentation에서만 성능을 개선하는 반면, SAM의 region map은 기본 FH region에 비해 모든 task에서 RAE의 성능을 크게 향상
- 놀랍게도, SAM region만 사용한 RAE는 MAE보다 성능이 우수하며, 계산 요구 사항이 적었음
- (e)에서 R-MAE라는 전체 pre-training 파이프라인의 결과를 보여줌. 이 파이프라인은 RAE와 MAE를 통합하여 구성. 구체적으로, R-MAE에서는 MAE의pixel reconstruction과 masked region autoencoding을 함께 최적화 함
5. CONCLUSION
- 간단하면서도 효과적인 접근 방식인 R-MAE를 통해 MAE(He et al., 2022)의 중요한 비전 개념인 "region"을 탐구
- Quantitative and qualitative 결과를 통해, R-MAE가 실제로 더 'region-aware'이 높으며, downstream 성능을 일관되게 개선할 수 있음을 보임
Limitations
- Region은 word와 유사한 점이 있지만(예: 이산적인 측면), region이 아직도 부족할 수 있는 word의 다른 측면도 있음(예: 충분한 의미론적 정보를 제공하는지 논란이 될 수 있음)
- 따라서 이 연구는 여전히 NLP에서 대형 언어 모델에 대한 word와의 격차를 실제로 메우기 위한 첫 번째 단계임
- 그러나 컴퓨터 비전에서 word의 시각적 동의어를 발견하는 데 있어서 탐구 가치가 있음
- SAM(Kirillov et al., 2023)에서 나온 region은 R-MAE의 성능을 크게 향상시키지만, SAM 자체는 MAE에서 초기화되며, 계산 비용이 많이 들며, 사람이 학습에 참여해야 하는 대규모 학습이 필요
- 다음 연구는 SAM region이 도움이 되는 진정한 이유를 찾고, 이 파이프라인의 복잡성을 최소화하는 것

AI Research Engineer