1. 깊이 우선 탐색(DFS)
시간 복잡도 : O(V+E), V : 노드 수, E : 에지 수
스택의 특징인 LIFO로 인해, 깊이 우선 탐색이 된다.
gif script_1)
아래 gif는 낮은 숫자부터 조사하는 경우 DFS를 사용한 것으로, 탐색 순서가 [1-2-3-4-5-6-7-8-9-10]과 같다.
gif script_2)
딱히 낮은 숫자부터 조사하는 경우가 아니며, 스택의 LIFO 구조를 사용한다면, 탐색 순서가 [1-9-10-5-8-6-7-2-3-4]가 되었을 것이다.
(STACK 구조(LIFO)를 재귀함수로 이용하여 구현한 ex_1)의 코드에 아래 gif의 그래프를 대입해보면 알 수 있다.)
→ 탐색 순서는 다르지만, 결국 모든 경우에 대한 탐색을 깊이 우선적으로 수행했기 때문에 같은 DFS를 활용했다고 볼 수 있을 것이다.
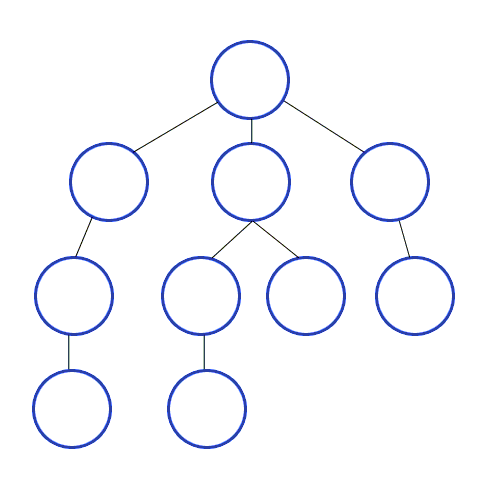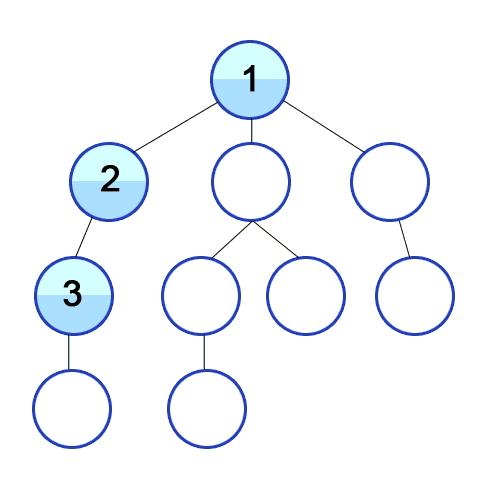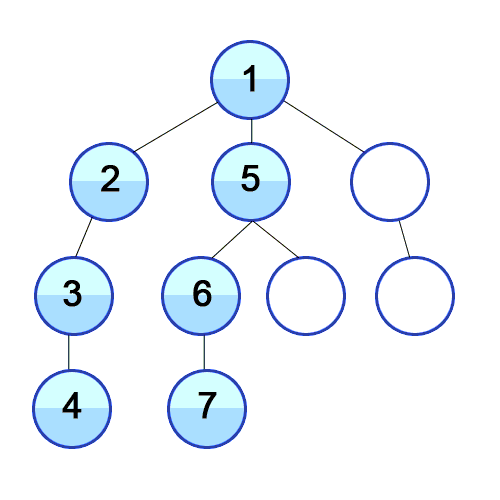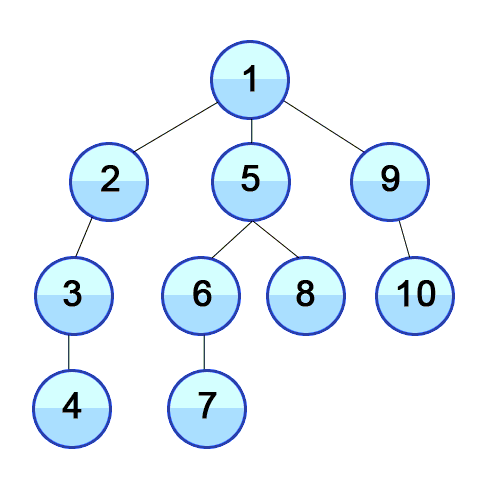
ex_1) DFS 구현 설명(재귀를 이용하고, stack의 특징(gif script_2와 같은 내용용)을 구현)
스택에서 꺼내면서, 해당 노드의 인접 노드를 스택에 삽입한다.
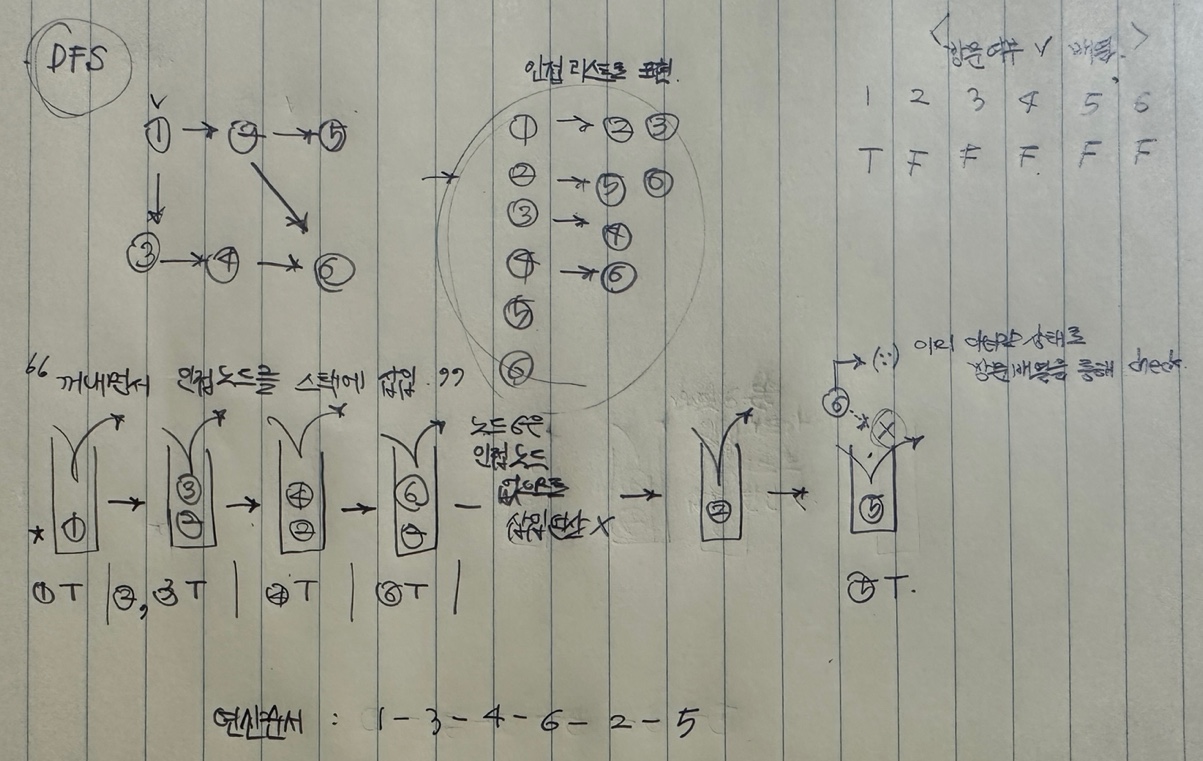
#include <iostream>
#include <vector>
using namespace std;
// index 1부터 이용하기 위해서 사이즈를 한 칸 더 키워 생성한다.
bool visited[7];
vector<int> graph[7];
void dfs(int x)
{
// 방문한 경우, visited 배열의 항을 true로 변환
visited[x] = true;
// 인접한 노드의 사이즈만큼 탐색
// 하지만 dfs의 원래 구조인 stack의 특징(LIFO)을
// 생각하여 graph[x]의 뒤에서부터 탐색해보았다.
for (int i = graph[x].size() - 1; i >= 0; i--)
{
int y = graph[x][i];
// 방문하지 않았던 경우라면, 아래 코드 실행
if (!visited[y])
cout << y << " ";
dfs(y);
}
}
int main(void)
{
// 그래프 정의
graph[1].push_back(2);
graph[1].push_back(3);
graph[2].push_back(5);
graph[2].push_back(6);
graph[3].push_back(4);
graph[4].push_back(6);
// 1부터 시작하도록 하므로 1 출력 후 시작
cout << 1 << " ";
dfs(1);
// 1 3 4 6 2 5
}ex_2) 번호가 낮은 인접노드부터 방문하는 경우(stack의 특징을 온전하게 이용하지 않았으나, 결국 그래프의 가장 아래를 찍고 오므로, DFS를 구현한 것으로 본다.)
#include <iostream>
#include <vector>
using namespace std;
// index 1부터 이용하기 위해서 사이즈를 한 칸 더 키워 생성한다.
bool visited[9];
vector<int> graph[9];
void dfs(int x)
{
// 방문한 경우, visited 배열의 항을 true로 변환
visited[x] = true;
cout << x << " ";
// 인접한 노드의 사이즈만큼 탐색
for (int i = 0; i < graph[x].size(); i++)
{
int y = graph[x][i];
// 방문하지 않은 경우면, 아래 코드 실행
if (!visited[y])
dfs(y);
}
}
int main(void)
{
// 그래프 정의
graph[1].push_back(2);
graph[1].push_back(3);
graph[2].push_back(5);
graph[2].push_back(6);
graph[3].push_back(4);
graph[4].push_back(6);
dfs(1);
// 1 2 5 6 3 4
}책(DO it! 알고리즘 코딩테스트 with C++)에 있는 예시 설명 부분에 코드가 없어서, ex_1)을 통해 직접 재귀함수를 통해 구현해보았다. stack<int> stk이런 식으로 stack을 설정해두고, stk.push(), stk.pop(), stk.top()등을 활용하여 구현해보는 것도 좋을 것 같다.
+) STACK 활용 DFS 참고 : https://doing-nothing.tistory.com/48

@sonyrainy
덕분에 좋은 정보 얻어갑니다, 감사합니다.