알고리즘
1.[알고리즘] 정렬(버블, 선택, 삽입)

1. 버블 정렬(O(n^2)) >두 인접한 데이터의 크기를 비교하여 정렬한다. ex) 백준 2750번 2. 선택 정렬(O(n^2)) >첫 기준 인덱스 값을 선택하여 그것을 나머지와 하나하나 비교하며 정렬한다. ex) 백준 1427번 3. 삽입 정렬(O(n^2))
2.[알고리즘] 정렬(퀵, 병합, 기수)
1. 퀵 정렬(O(nlogn), O(n^2)) >평균 : O(nlogn), 최악 : O(n^2) >기준값(pivot)을 설정하여 데이터를 2개의 집합으로 나누며 정렬하는 방법이다. 아래 gif는 pivot을 맨 뒤로 두고 정렬을 진행하는 경우이다. ex) {3, 7
3.[알고리즘] 깊이 우선 탐색(DFS)
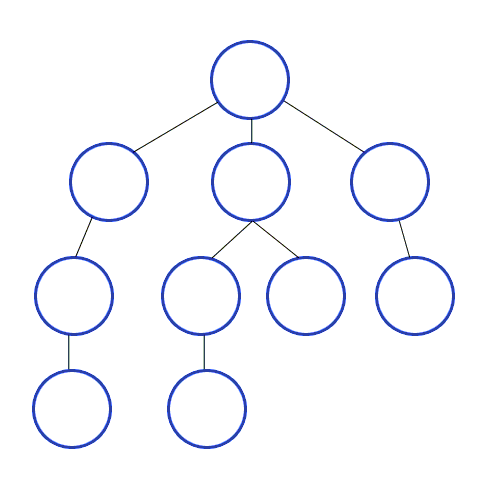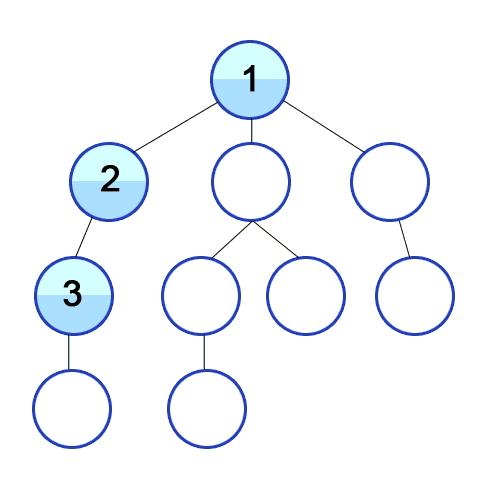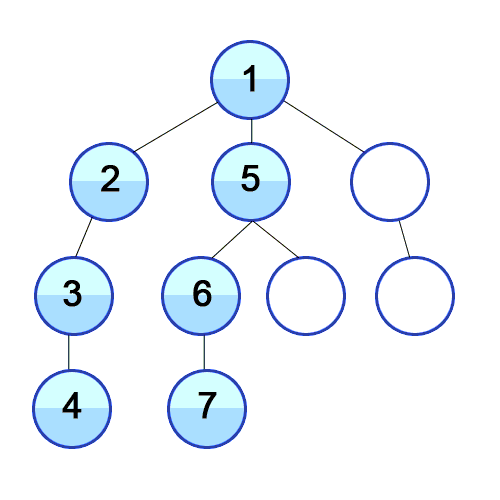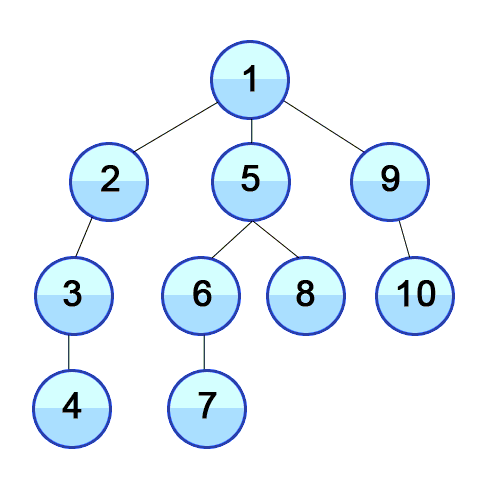
시간 복잡도 : O(V+E), V : 노드 수, E : 에지 수 스택의 특징인 LIFO로 인해, 깊이 우선 탐색이 된다.아래 gif는 낮은 숫자부터 조사하는 경우 DFS를 사용한 것으로, 탐색 순서가 1-2-3-4-5-6-7-8-9-10과 같다.딱히 낮은 숫자부터 조사
4.[알고리즘] 그리디 알고리즘(Greedy Algorithm)
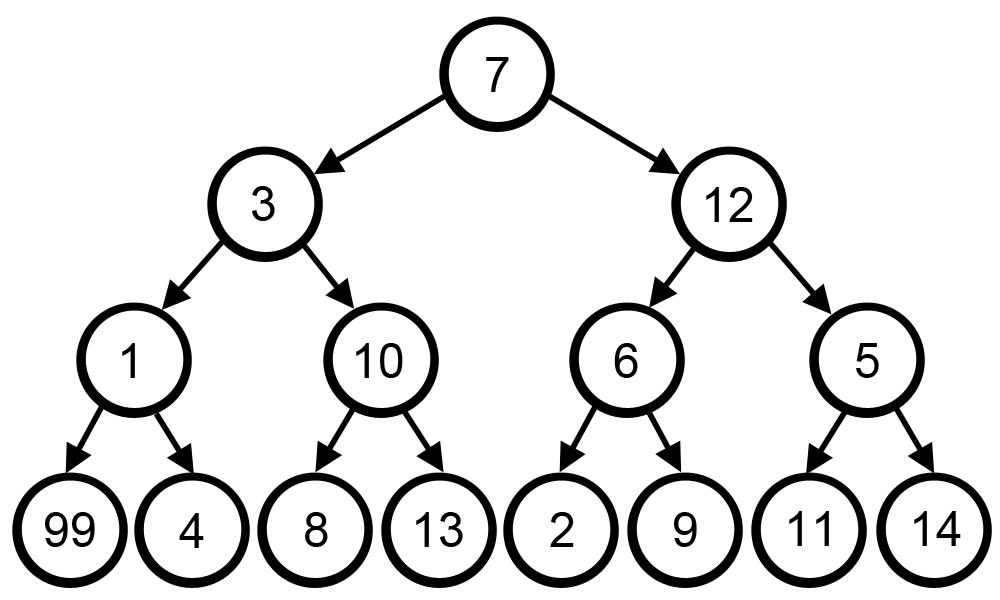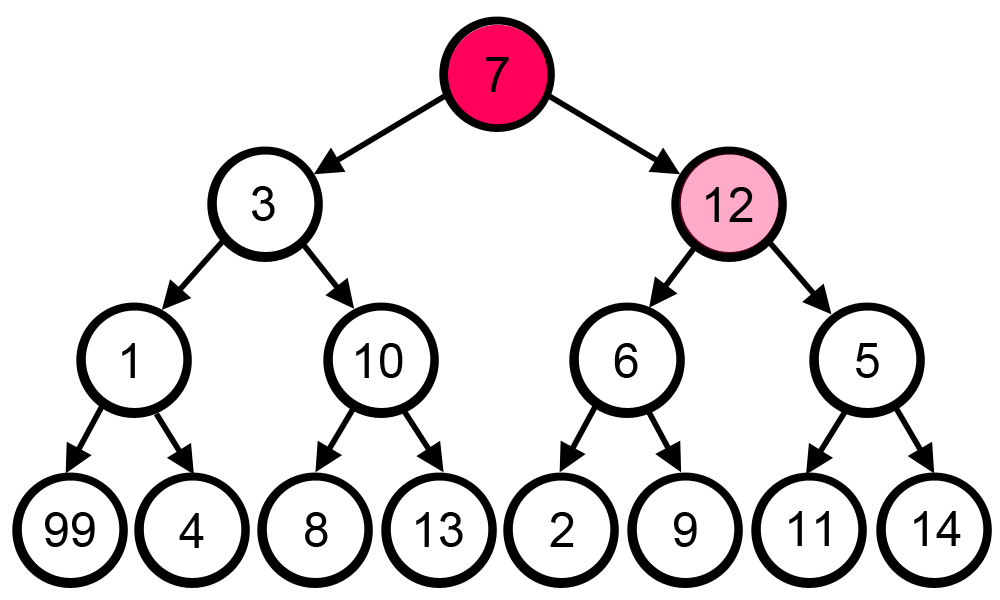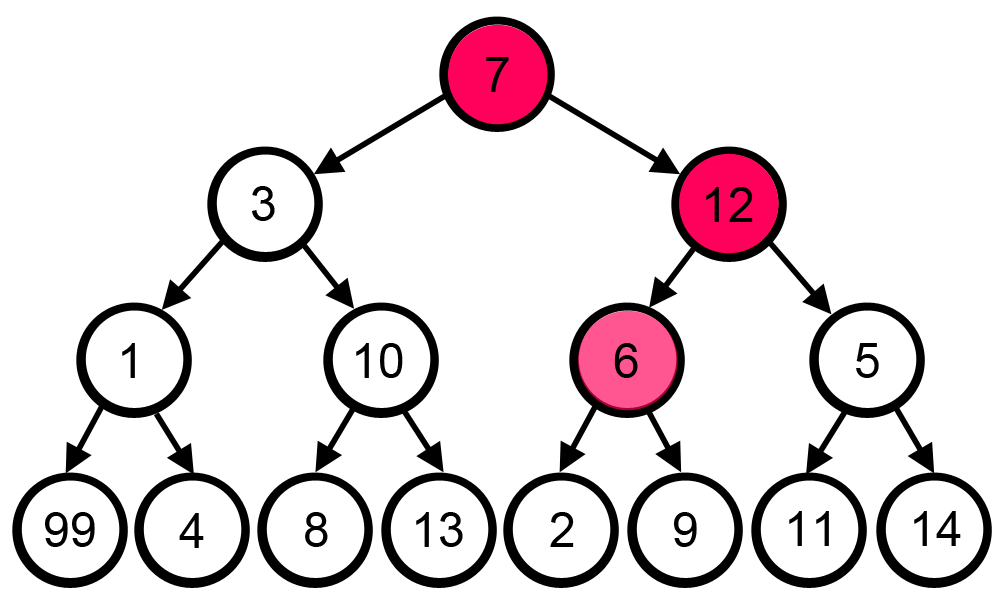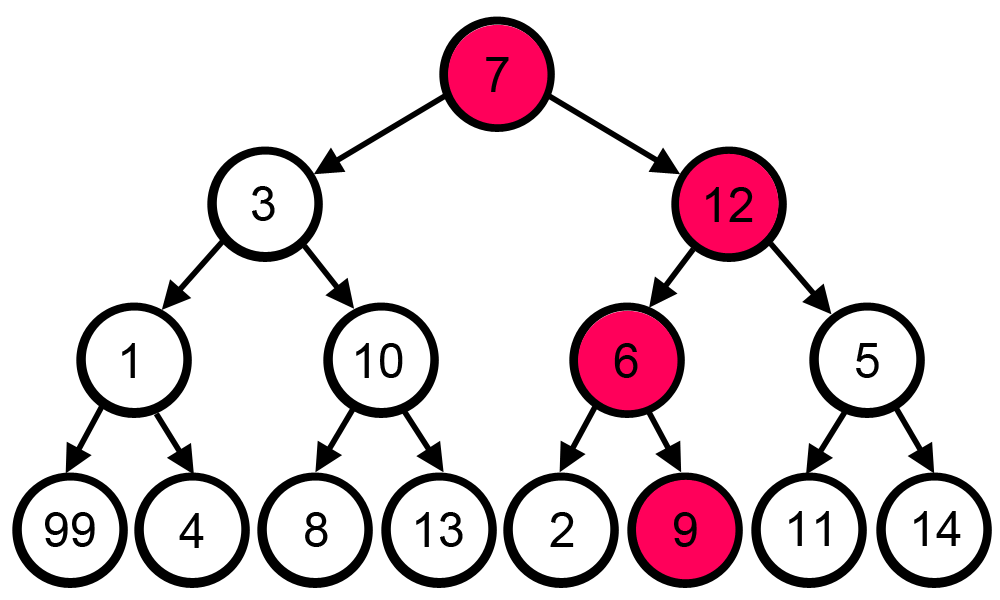
매 순간마다 눈 앞에 보이는 최선의 상황을 선택하며 최종 답으로 도달하는 방법이다.시간 복잡도 : 상황에 따라 다양하지만, 보통 O(N), O(NlogN)지나가는 전체 노드의 합이 최대가 되도록 하고 싶은 경우라고 가정 했을 때, 아래 gif에서는 눈 앞의 큰 노드 값
5.[알고리즘] 이진 탐색(Binary Search)
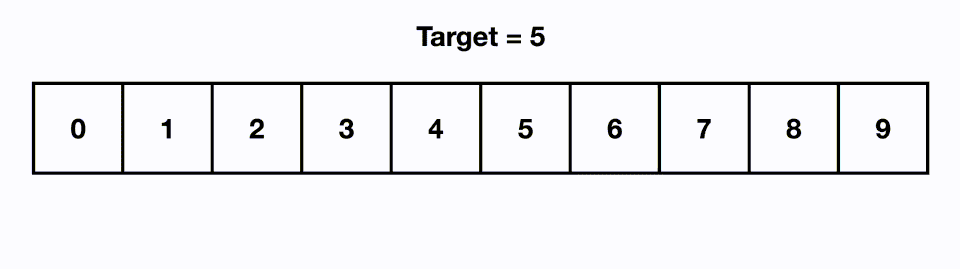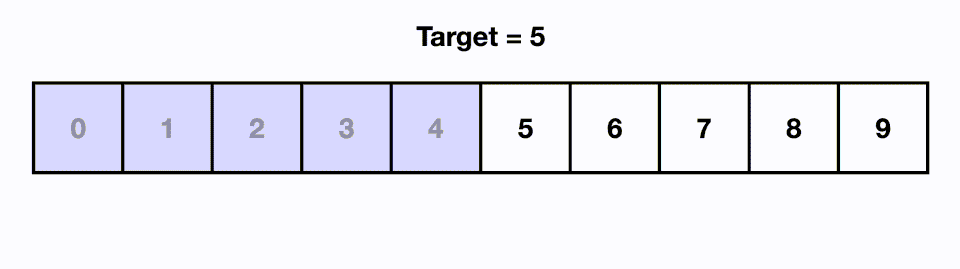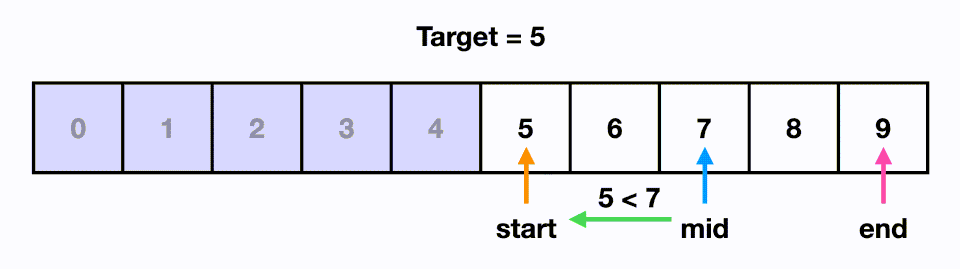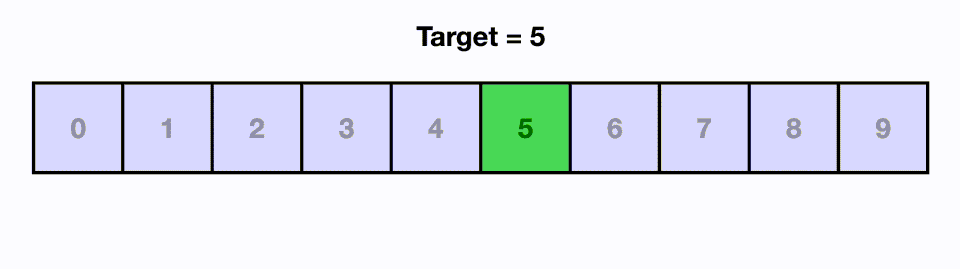
시간 복잡도 : O(logN) 데이터가 정렬된 상태에서 원하는 값을 찾아내는 알고리즘이다.정렬된 리스트에서의 중앙값과 찾고자 하는 값을 비교하고, 리스트의 크기를 절반씩 줄이면서 대상을 찾는다.1) 5라는 값을 찾는 경우, 0~9 리스트에서 mid인 4와 5를 비교한다
6.[알고리즘] 다익스트라 알고리즘(Dijkstra Algorithm)
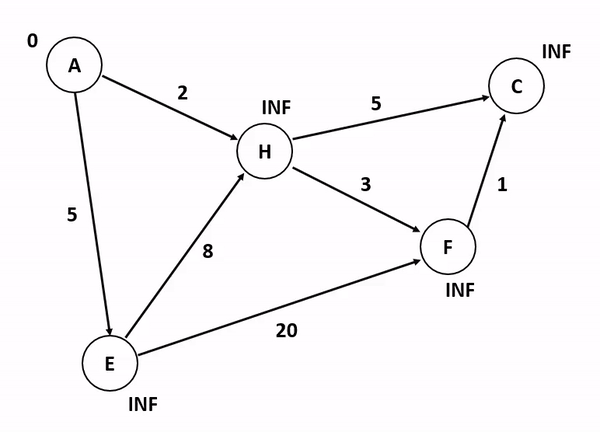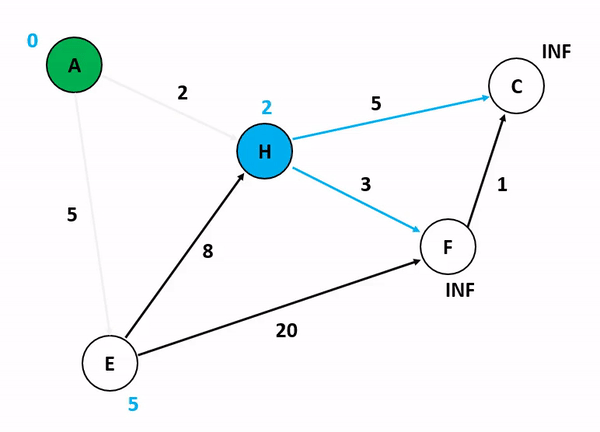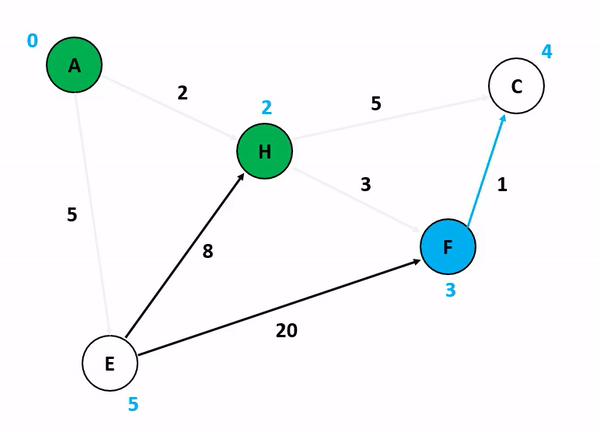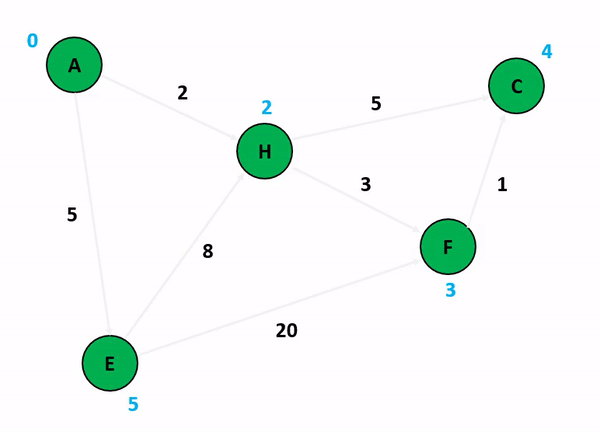
그래프에서 최단 거리를 구하는 알고리즘이다.시간 복잡도 : O(ElogV), (노드 수 : V, 에지 수 : E)시작점으로부터 조사하여, 최단 거리를 구한다.시작점이 있으며, 음수 간선이 없는 경우에 사용한다. 거리에 START부터 연결된 것들의 간선을 di 배열에 넣
7.[알고리즘] 백준 1854번(다익스트라 알고리즘)
푼 문제와 정답 코드는 해당 링크 참고 문제) 백준 1853다익스트라 알고리즘 활용1) 다익스트라 알고리즘을 활용할 때, 마지막에 출력하는 배열 d에 '시작점으로 각 노드까지로 가는 거리의 최소값'을 대입하는 것을 이해했었다.2) 따라서, 배열 d를 2차원 배열로 생성
8.[알고리즘] 벨만-포드 알고리즘(Bellman-Ford Algorithm)

시간 복잡도 : O(VE) 최단거리를 구하는 알고리즘으로, 다익스트라 알고리즘과 다르게 음수의 간선이 존재하는 경우에도 수행 가능하다. 최단거리에 대한 갱신을 N-1번 반복해야 한다. 음수가 없다고 생각했을 때, 최소한 N-1번 반복해야 시작점으로부터 각 노드별 최단
9.[알고리즘] 플로이드-워셜 알고리즘(Floyd-Warshall Algorithm)
시간 복잡도 : O(V^3) (V : 노드 수) 모든 노드 간 최단 경로를 탐색하는 알고리즘이다.시간 복잡도가 크기 때문에, 보통 NODE가 100~200 정도이다. N=1000 정도라면 다른 알고리즘을 생각해볼 법한데, 1000^3번의 연산은 시간초과가 발생할 여지가
10.[알고리즘] 동적 계획법(Dynamic Programming)
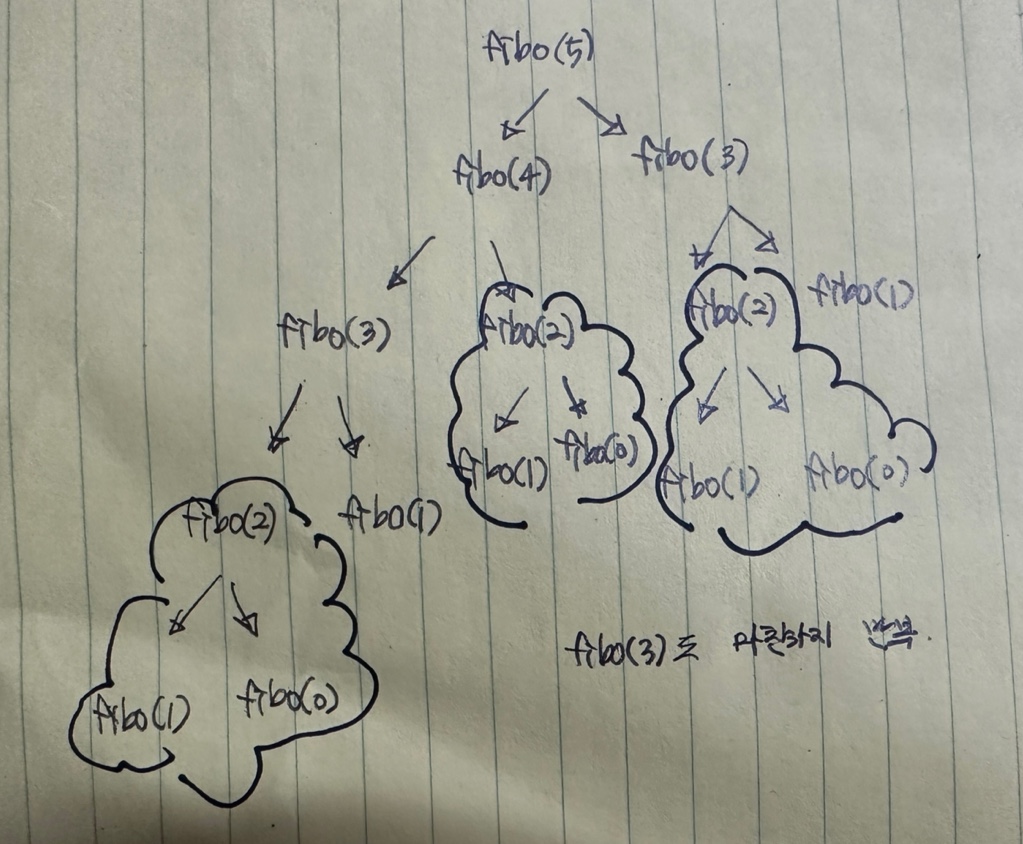
주어진 문제를 더 작은 문제로 나누고, 작아진 문제들을 해결함으로써 원래 문제를 해결해나가는 방식이다.보통 배열을 만들어 값을 저장하고, 그것들을 통해 답을 구하는 편이다.피보나치 수열을 통해 동적 계획법 구현을 이해해볼 수 있다.fibo(5)을 구한다고 볼 때, fi
11.[알고리즘] 분할정복? 그리고 동적계획법
그 자체로 해결하기 힘든 문제를 작은 문제로 분할하여 해결하는 방법이다.divide : 기존 문제를 작은 부분 문제로 나눈다.conquer : 각 부분 문제를 해결(정복)한다.combine : 부분 문제들의 답을 통해 기존 문제를 해결한다.정복하는 것도 작은 divid
12.[알고리즘] 너비 우선 탐색(BFS)
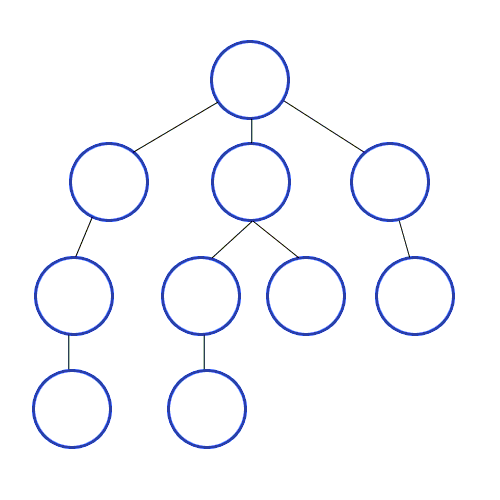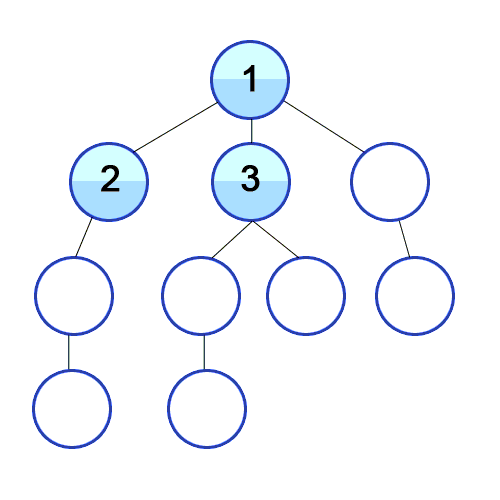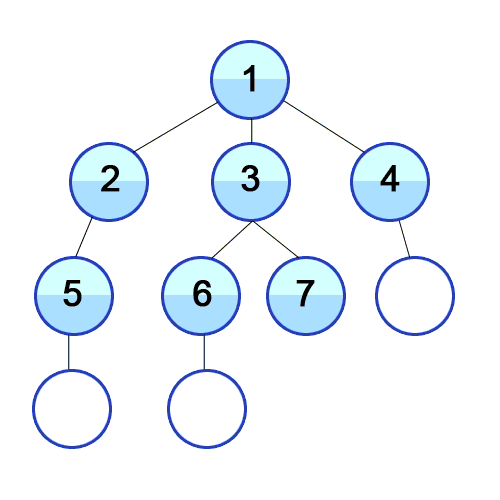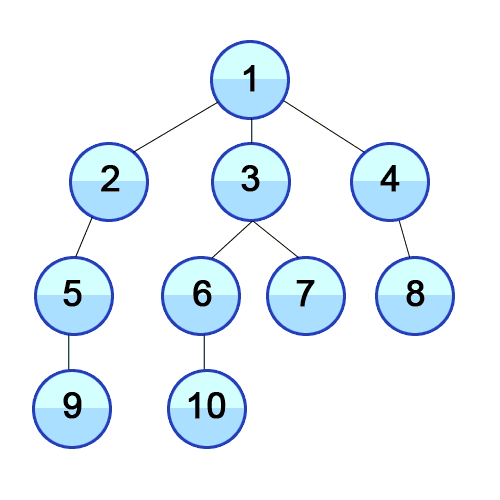
시간 복잡도 : O(V+E), V : 노드 수, E : 에지 수 큐의 특징인 FIFO를 활용하여 BFS를 구현한다.시작 노드에서 연결된 노드 중 방문되지 않은 노드를 방문하고 차례대로 큐에 삽입되는 식으로 진행된다.아래 추가 설명 有1\. queue(FIFO)에서 하나