https://www.youtube.com/watch?v=amTJyIE1wO0
기본적 은행 -> 모노리식 (Monolithic)
은행 최초 msa 전환기
코어 뱅킹 시스템을 왜 마이크로 서비스로 전환하게 되었을까?
은행에는 크게
현재 은행 시스템 크게 2개 서버 중심 아키텍쳐
- 채널계 : 고객 요청 코어뱅킹 서버로 전달
- 코어뱅킹 (계정계) : 금원 관련 메인 비지니스 로직 처리 (모노리식 Monolithic)
→ 차세대 시스템 아키텍쳐 (2개 서버 쓰는 방식) 2000년부터
그 이유는? 은행 시스템 변천사 보면 됨.
다양한 거래 요청을 한곳에서 처리할 수 있도록
20년 전 → 현재의 모바일 트렌드와는 맞지 않음
왜 수십년 지속되었는지?
- 보수적 금융권 - 수십년 검증된 아키텍쳐 바꾸고 싶지 않아서
- 표준화 잘 되어있어서 개발 환경 빠르게 적응 가능
토스 뱅크의 경우
- 채널계 : msa 환경
- 코어뱅킹 시스템 : redis, kafka 같은 모던 기술
모노리식으로 구성된 코어 뱅킹 시스템은 1개 서버, 1개 db 사용하기 때문에
트랜잭션 처리가 용이 (네트워크 구조 단순)
but 트래픽 몰리면 특정 코어뱅킹 서버만 스케일 아웃 못함
- 서버 1개이기 떄문에 장애 서비스 외 다른 서비스의 영향도 제한 불가
→ 안정성 부족
즉, 1개의 코어뱅킹 서버에서 모든 트랜잭션 처리하고 있음 → 1개의 코어뱅킹 서비스에서 장애 발생 → 전 업무 마비되는 구조
모바일 위주로 대량의 트래픽 처리해야하는 구조에는 현재의 거대한 모노리식 아키텍쳐로는 한계가 있음
4세대 (2022~)
아키텍쳐를 채널, 코어뱅킹간 경계를 허문 도메인 중심 msa 아키텍쳐로 설계
지금 이자 받기 서비스 : 한달에 한번 받던 이자를 → 원하는 시점에 언제든
기존에는 모노리식 코어뱅킹 시스템의 일부로 운영중 → 매일 70만명 → 여기에 트래픽 몰려서 전체 서비스 장애로 전파
해당 구조에서는 트래픽 위해 전체 코어뱅킹 서버 증설해야 했음 (비효율적)
트래픽 높은 이자 지급 도메인을 피크타임에 유연하게 스케일 아웃 할 수 있고 + 장애가 다른 서비스 장에로 이어지지 않도록
독럽적 마이크로 서비스로 전환 결정
< 개발방법>
기술스택 : 토스뱅크 채널 서버에서 사용하고 있는 기술 대부분 채택
쿠버네티스 위에 스프링 부트, 코틀린, jpa 기반 +
비동기 메시지 처리, 캐싱 : kafka, redis
1번째 고민 : 현재 모노리식으로 강결합 되어 있는 업무별 비지니스 의존성 어느 정도까지 느슨하게 할 지? →
이자 조회 위해서 필요한 도메인
- 고객 (정보 조회)
- 상품 (금리 조회)
- 회계 (이자 회계 처리)
이걸 다 하나의 마이크로 서버에서 처리하는 것은 msa 장점 활용하지 ㄴ못할 것 판단 → 도메인 단위로 서비스를 나누자
- 기존 : 하나의 트랜잭션으로 처리 (7:34)
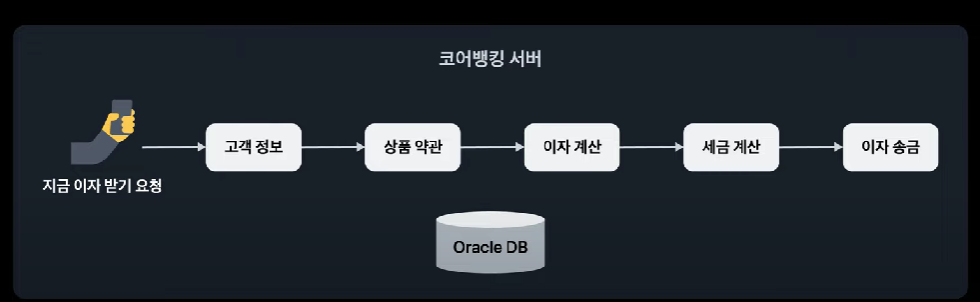
- 새로운 코어뱅킹 아키텍쳐 : 트랜잭션으로 묶지 않아도 되는 도메인은 별도 마이크로 서버로 구성, 각 서버의 api 호출 통해서 비지니스 의존성 느슨하게 가져가도록 구성.
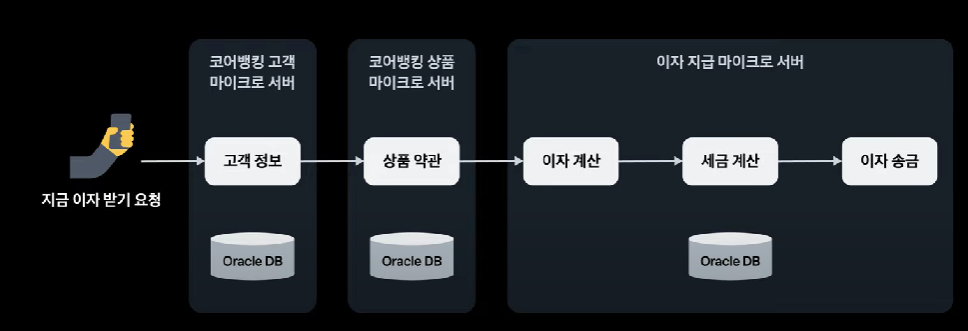
<실제 이자지급 서버 어떻게 개발했는지>
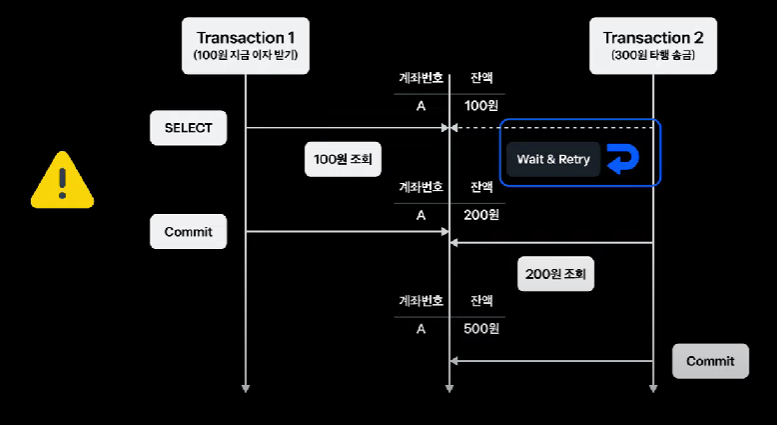
- 동시성 제어 : 은행 시스템 안정성과 직결
- 게좌 잔액 갱신 : 매우 많은 트랜잭션 (앱 거래, atm, 은행통한 입금, 자동 이체 등)
- 일반적 redis global lock 만으로는 은행 시스템 환경에서 동시성 제어 이슈 해결 어려움
- → 동시성 이슈 해결이 코어 뱅킹의 필수 조건!
- 문제 해결 위해 redis global lock + jpa에 @lock (어노테이션, db 단에서 동시성 제어 위해)
- db lock 사용 시 주의해야 하는 점 → lock 잡아야 하는 데이터 명확히 식별해야 함 + 갱신하는 데이터에 대해서만 락 획득해야 함.
- → 그래야 데드락과 시스템 성능 저하 예방 가능.
- 트랙잭션 2의 동시성 발생했을 때 t1 끝날때까지 기다릴 수 있도록 재시도 할 수 있는 로직과 적절한 타임아웃 적용 → 고객을 락 걸린지도 모르게 안정적으로 구현
-
kafka 활용한 비동기 트랜잭션 구현
-
기존 뱅킹 시스템 → 1번의 이자 지금 위해 20개 테이블에 80번 update, insert 이뤄지는 복잡한 구조 → 정규화, 인덱스 잘 해도 속도 느림.
-
기존 트랜잭션에서 분리 가능한 테이블은 카프카 아용해 트랜잭션에서 분리!
-
분리 기준 : db 쓰기 지연이 발생했을때 고객 통장 데이터가 시시간으로 문제 발생하는가?
-
반드시 트랜잭션 보장되어야 하는 데이터 모델 // 즉시성 요하지 않는 모델 (세금 처리처럼 지금 이자 받기 트랜잭션과 묶이지 않아도 되는 데이터 모델의 dml) →트랜잭션 분리
-
기존 이자 받기 트랜잭션 : 80회 dml →
-
이자 받기 트랜잭션 : 50회 dml + 세금 30회 dml
-
-
redis 활용한 캐싱 전략
- 기존 이자 계산 : rdb 기반 일자별 래 내역 db를 조회해서 연산
- → 거래 할때마다 계좌의 매일매일 거래 내역 참조해서 이자와 세금 계산 (오래 걸림) → 정산도 비슷한 구조로 했음?
- 하루에 1번만 이자 받기 가능
- redis 활용시 하루에 db/io 1번만 발생시킬 수 있음!
- 기존 : 고객이 계좌 상 탭 접근시마다 이자 계산 위한 db/io 발생
- 개선 : 고객이 하루 중 처음 상세 탭 접근할때만 db에 접근하도록 구현 → 이자 예상 조회 결과 redis에 캐싱하도록 구현.
- 고객 2번째 접근 부터는 redis 에 저장되어있던 이자 계산 결과 그대로 리턴하도록 함 (불필요한 db 리소스 낭비 예방) → cms에서도 잔액, 등등 조회 페이지 접근시마다 계산했는데 redis 캐싱 사용했으면 더 빨랐을 것.
- redis에 캐싱된 이제 데이터 만료일 하루로 설정 → 이자 금액 잘못 계산 원천 방지
- → 이자 데이터 정합도 안정 보장
<기존 시스템 안정적으로 마이그레이션 하는 방법>
이자 받기 거래를 코어 뱅킹 서버에서 → 이자 지금 마이크로 서버로 전환하기 위해 순차 배포 과정 필요
api 안정적 전환 위해 이자 조회 거래 적용 → 지금 이자 받기 거래 적용
