베이즈 통계학
조건부 확률
조건부 확률 는 사건 가 일어난 상황에서 사건 가 발생할 확률
-
베이즈 정리는 조건부 확률을 이용하여 정보를 갱신하는 방법을 알려준다.
-
라는 새로운 정보가 주어졌을 때 부터 를 계산하는 방법을 제공한다.

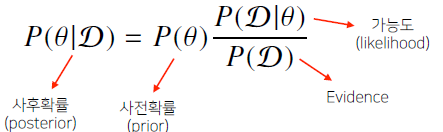
: 새로 관찰하는 데이터
: hypothesis, 모델링하는 이벤트, 모수
-
오탐율(False alarm)이 오르면 테스트의 정밀도(Precision)가 떨어진다.
-
Confusion Matrix
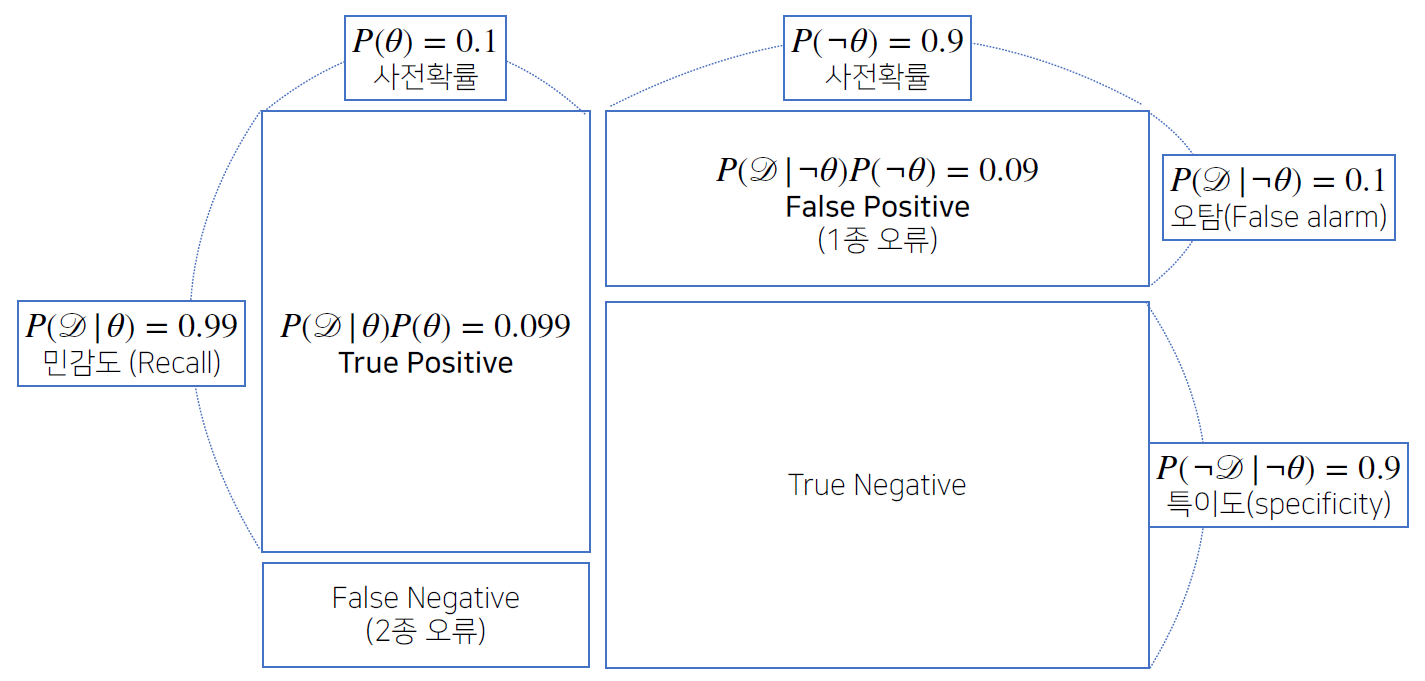
정밀도
-
베이즈 정리를 통해 새로운 데이터가 들어왔을 때 앞서 계산한 사후확률을 사전확률로 사용하여 갱신된 사후확률을 계산할 수 있습니다.

-
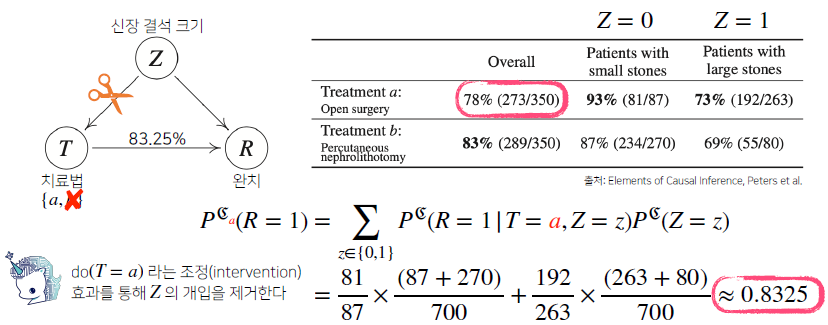
조건부 확률은 유용한 통계적 해석을 제공하지만 인과관계(causality)를 추론할 때 함부로 사용해서는 안 됩니다. (데이터가 많아져도 조건부 확률만 가지고 인과관계를 추론하는 것은 불가능합니다.)
인과관계
-
인과관계는 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요합니다. (인과관계만 고려해서 예측모형을 만들면 높은 예측정확도를 담보하기는 어렵다)
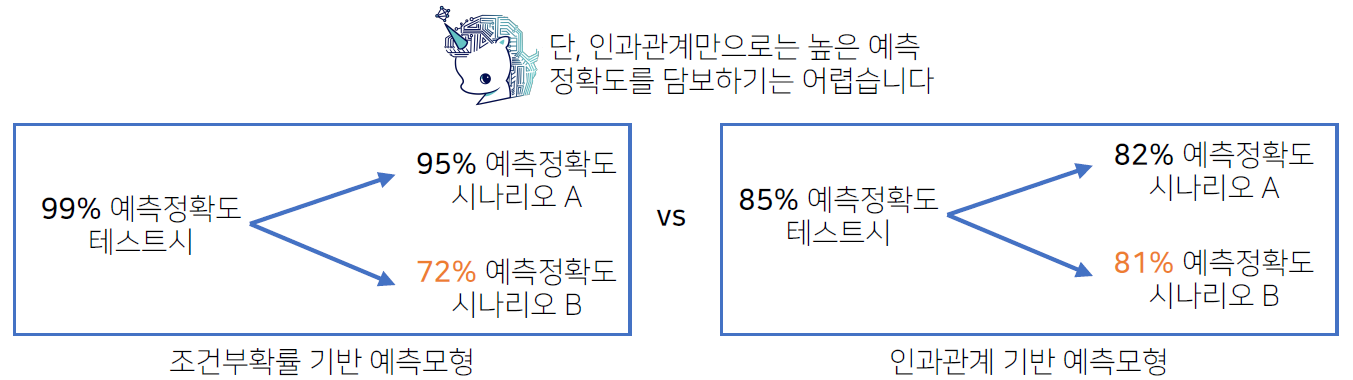
-
인과관계를 알아내기 위해서는 중첩요인(confounding factor)의 효과를 제거하고 원인에 해당하는 변수만의 인과관계를 계산해야 합니다.
대표적인 예: 키(T)와 지능지수(R)와의 관계는 키가 T가 클수록 R이 높게 나오지만 이는 나이라는 중첩효과를 제거하지 않아서이다. 키가 크다고 지능 지수가 높은것은 아니다.

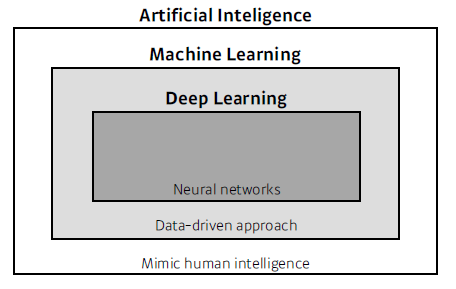
Deep Learning Basic
Introduction
What make you a good deep learner?
- Implementation Skills
- Math Skills (Linear Algebra, Probability)
- Knowing a lot of recent Papers
Key Components of Deep Learning
- The data that the model can learn from
- The model how to transform the data
- The loss function that quantifies the badness of the model
- The algorithm to adjust the parameters to minimize the loss
Data
Data depend on the type of the problem to solve
Model
Loss
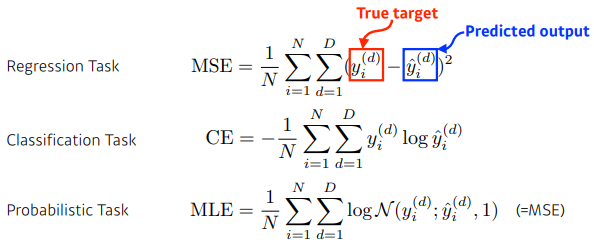
The loss function is a proxy of what we want to achieve
- 각 loss function이 각 상황마다 항상 적용되는 것은 아니다.
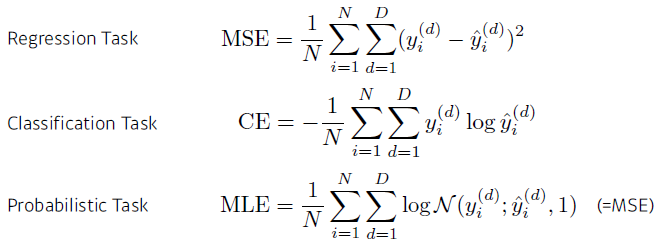
Optimization Algorithm
Deep Learning History
- 2012 AlexNet
- 2013 DQN
- 2014 Encoder / Decoder, Adam Optimizer
- 2015 Generative Adversarial Network, Residual Networks
- 2017 Transformer
- 2018 BERT (fine-tuned NLP models)
- 2019 BIG Language Models (GPT-3)
- 2020 Self Supervised Learning (SimCLR)
PyTorch
- Numpy 구조를 가지는 Tensor 객체로 array 표현
- 자동미분을 지원하여 DL 연산을 지원
- 다양한 형태의 DL을 지원하는 함수와 모델을 지원
Deep Learning
Neural Networks
Neural networks are computing systems vaguely inspired by the biological neural networks that constitute animal brains
Neural networks are function approximators that stack affine transformations followed by nonlinear transformations
Linear Neural Networks
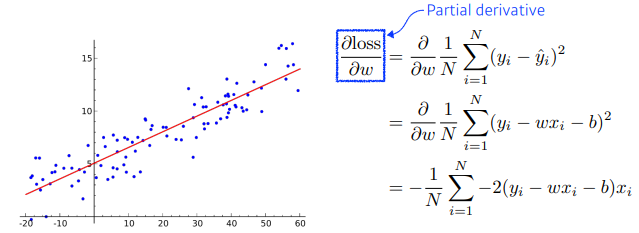
- One way of interpreting a matrix is to regard it as a mapping between two vector spaces
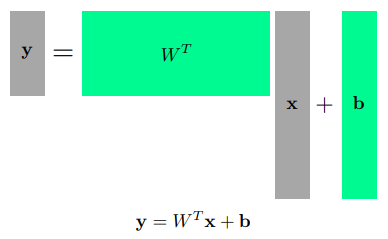
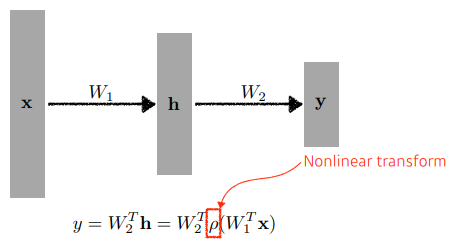
- loss function이 어떤 성질을 가지고 있고, 왜 원하는 결과로 나오는지 알아야한다.