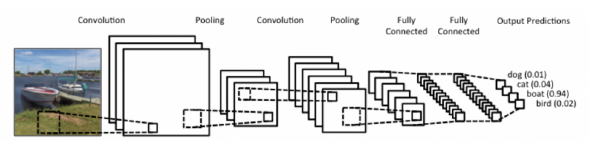
CNN
Convolution
-
Continuous convolution
-
Discrete convolution
-
2D image convolution
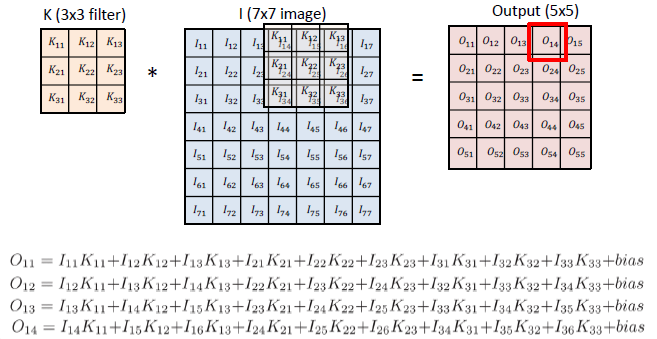
RGB Image Convolution
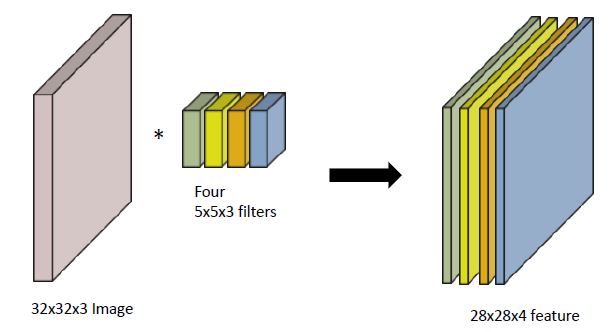
Stack of Convolutions
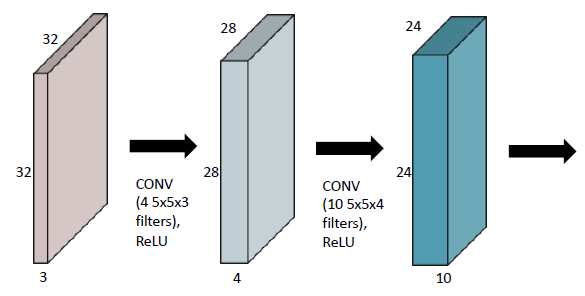
Convolutional Neural Networks
CNN consists of convolution layer, pooling layer, and fully connected layer.
-
Convolution and pooling layers: feature extraction
-
Fully connected layer: decision making (e.g. lassification)
- 점점 사라지고 있는 추세 (혹은 최소화) - 파라미터 숫자에 의존한다.
- 학습하고자 하는 모델(SVM, Neuralnetwork, Decision Tree)의 파라미터 숫자가 늘어날수록 학습이 어렵고, generalization performance가 떨어진다고 알려져있다.
- 같은 모델을 만들더라도 최대한 모델을 깊게 만들어 Convolution Layer를 많이 사용하는 방향, 즉 파라미터 숫자를 줄이는 방향으로 발전하고 있다.
Stride
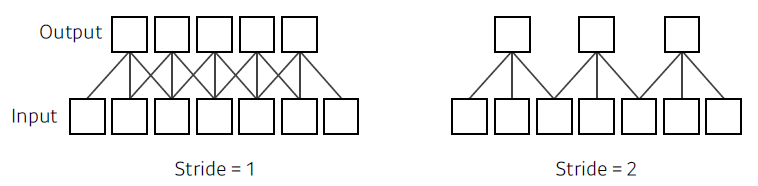
- 차원이 늘어날수록 stride의 파라미터가 늘어난다.
ex) 1D: (1), 2D: (2, 2)
Padding
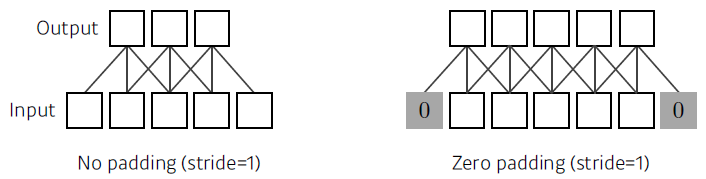
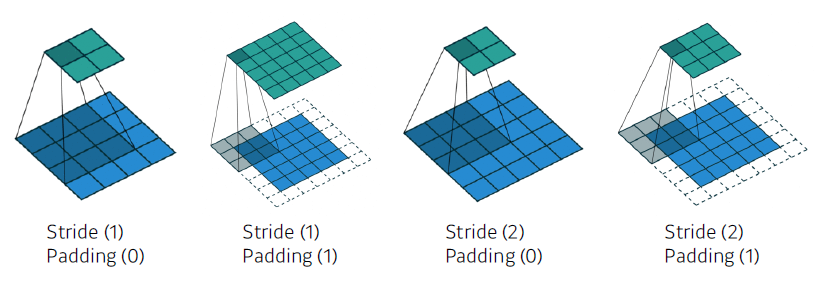
Convolution Arithmetic
Padding (1), Stride (1), 3 × 3 Kernel
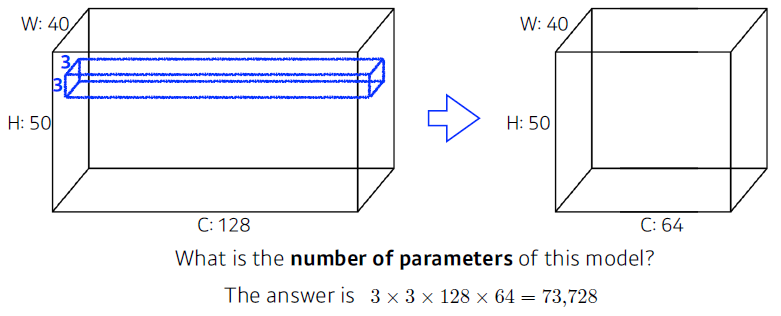
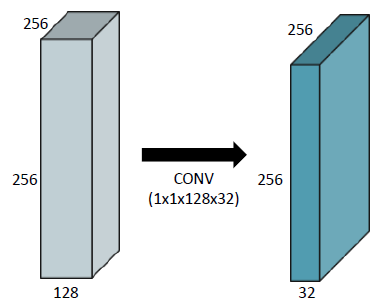
1x1 Convolution
Dimension reduction (channel Depth)
- To reduce the number of parameters while increasing the depth
- e.g. bottleneck architecture
Modern CNN
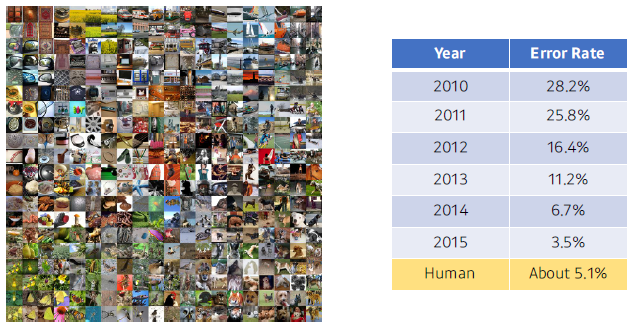
ImageNet Large-Scale Visual Recognition Challenge
- Classification / Detection / Localization / Segmentation
- 1,000 different categories
- Over 1 million images
- Training set: 456,567 images
AlexNet
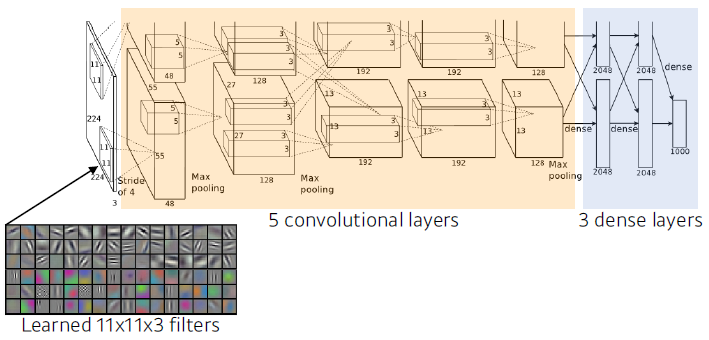
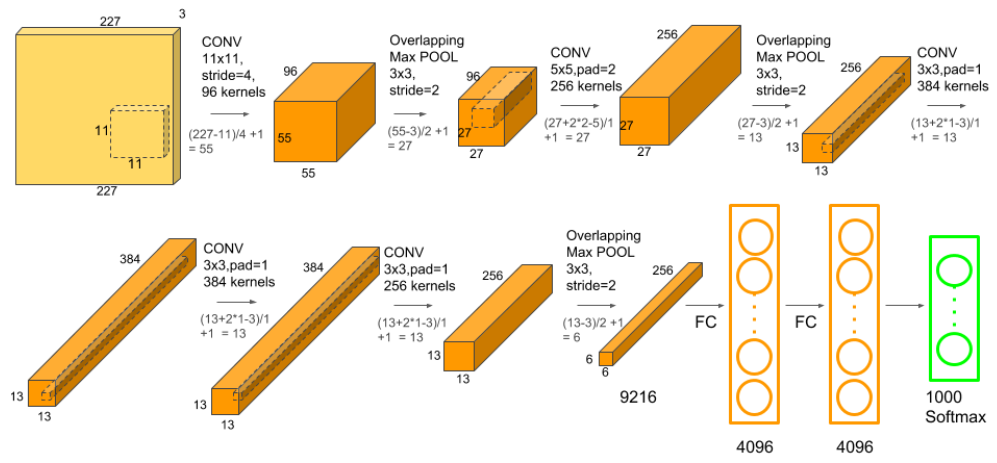
- Key ideas
- Rectified Linear Unit (ReLU) activation
- GPU implementation (2 GPUs)
- Local response normalization, Overlapping pooling
- Data augmentation
- Dropout
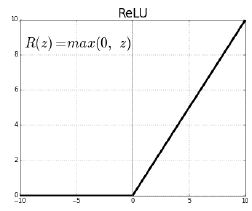
- ReLU Activation
- Preserves properties of linear models
- Easy to optimize with gradient descent
- Good generalization
- Overcome the vanishing gradient problem
VGGNet
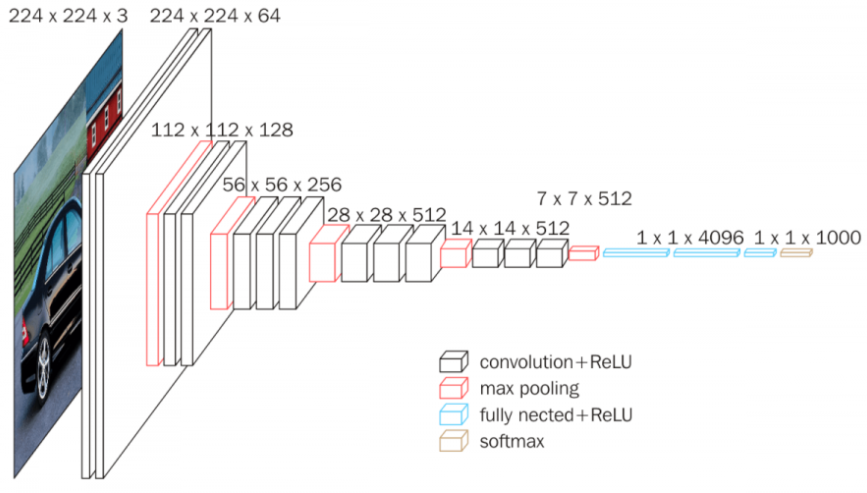
- Key ideas
- Increasing depth with convolution filters (with stride 1)
- 1x1 convolution for fully connected layers
- Dropout (p=0.5)
- VGG16, VGG19
- Why 3 × 3 convolution?
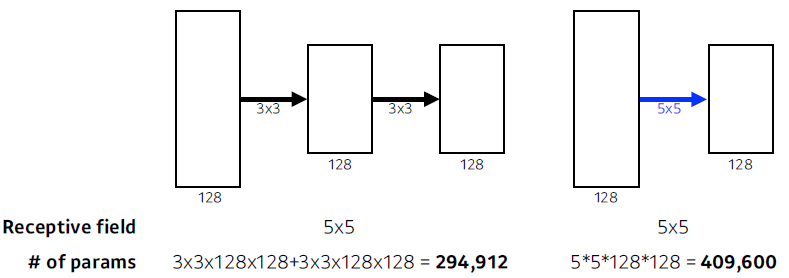
- Receptie field
Output Layer의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
GoogLeNet
GoogLeNet won the ILSVRC at 2014
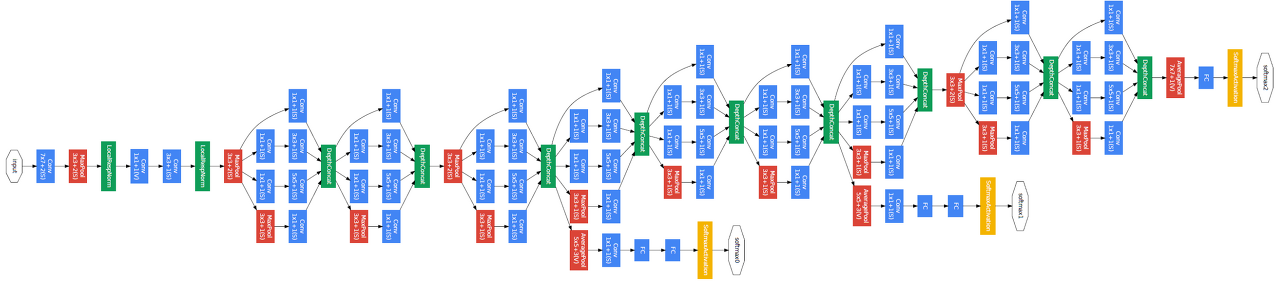
-
combined network-in-network (NiN) with inception blocks
-
Inception blocks
하나의 입력이 들어왔을 때 여러개로 퍼졌다가 하나로 합쳐진다.
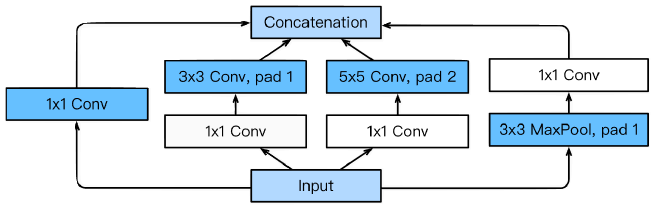
- benefits of the inception block
- Reduce the number of parameter.
- 1x1 convolution (channel-wise dimension reduction)
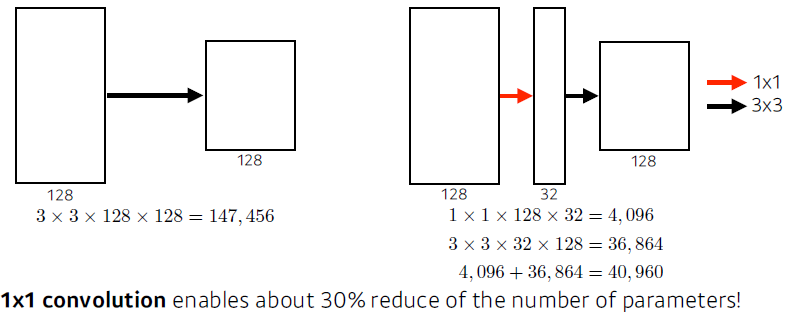
- benefits of the inception block
- Parameter
- AlexNet (8-layers): 60M
- VGGNet (19-layers): 110M
- GoogLeNet (22-layers): 4M
ResNet
Deeper neural networks are hard to train
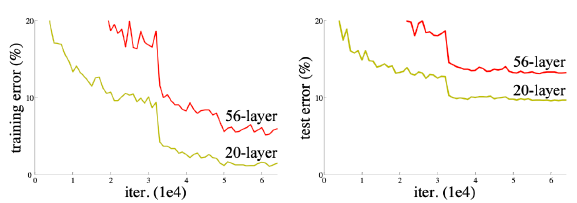
-
Overfitting is usually caused by an excessive number of parameters.
(위의 경우는 여전히 테스트 데이터의 에러도 줄어들고 있으므로 overfitting은 아니다.) -
과적합(overfitting)은 기계 학습(machine learning)에서 학습 데이터를 과하게 학습(overfitting)하는 것을 뜻한다. 일반적으로 학습 데이터는 실제 데이타의 부분 집합이므로 학습데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 된다.
Add an identity map (skip connection)
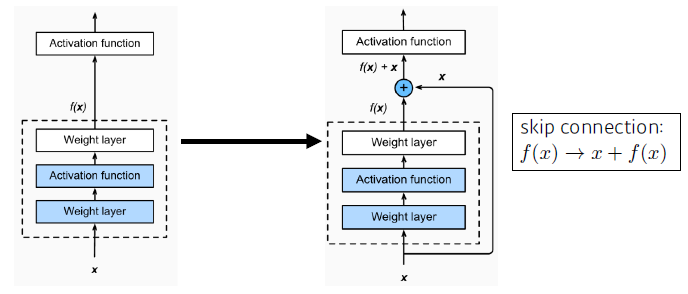
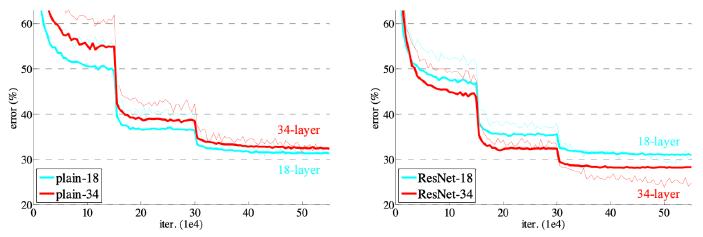
- 네트워크를 더 깊게 쌓을 수 있는 가능성이 생겼다.
- f(x)는 차이(Residual)만 학습하게 된다?
- Add an identity map after nonlinear activations
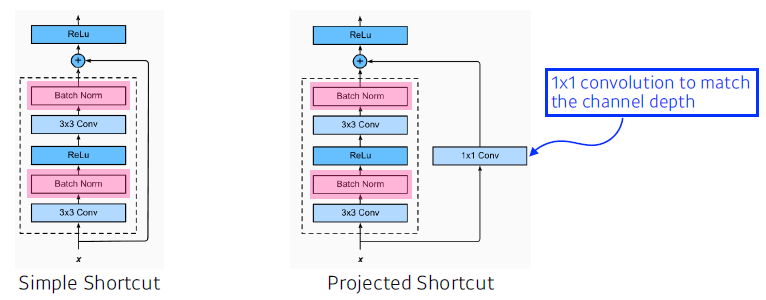
-
Bottleneck architecture
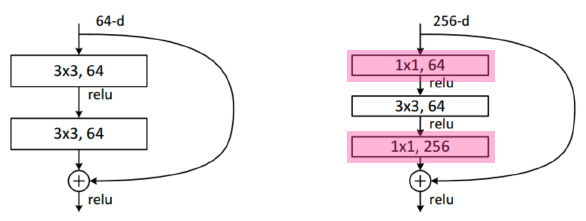
-
Performance increases while parameter size decreases
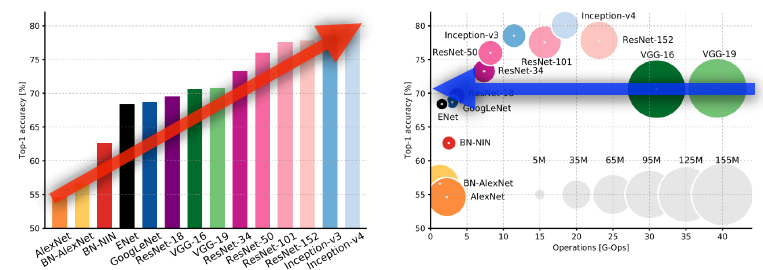
- Resnet에 대한 추가적인 정보
https://89douner.tistory.com/64
DenseNet
- DenseNet uses concatenation instead of addition
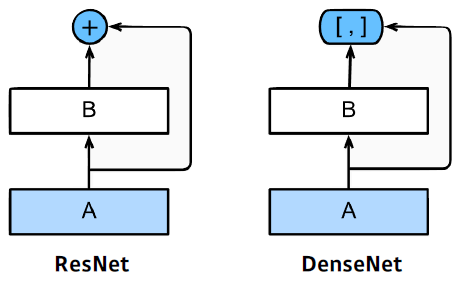
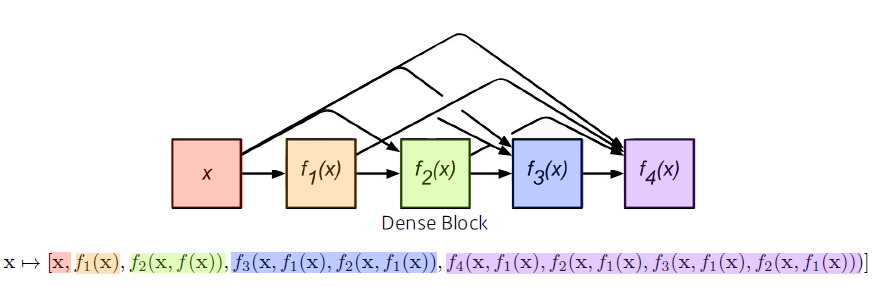
- Dense Block
- Each layer concatenates the feature maps of all preceding layers.
- The number of channels increases geometrically.
- Transition Block
- BatchNorm -> 1x1 Conv -> 2x2 AvgPooling
- Dimension reduction

Summary
- VGG: repeated 3x3 blocks
- GoogLeNet: 1x1 convolution
- ResNet: skip-connection
- DenseNet: concatenation
Computer Vision Applications
Semantic Segmentation
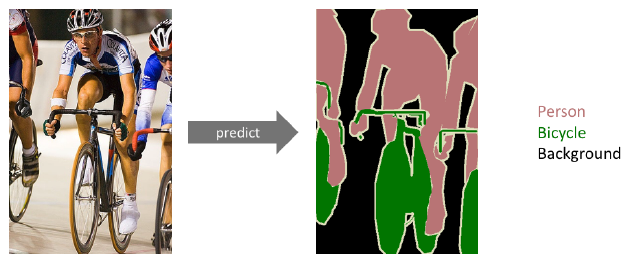
- ordinary CNN
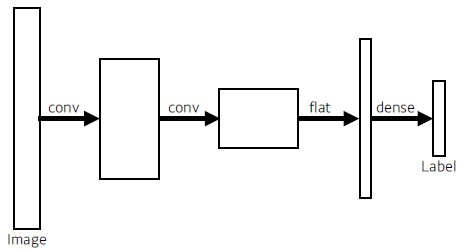
Fully Convolutional Network
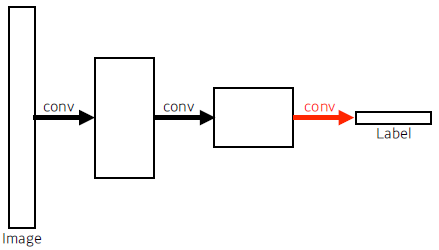

-
# of parameters
- Left: 4 x 4 x 16 x 10 = 2,560
- Right: 4 x 4 x 16 x 10 = 2,560
-
This process is called convolutionalization.
-
Transforming fully connected layers into convolution layers enables a classification net to output a heap map.
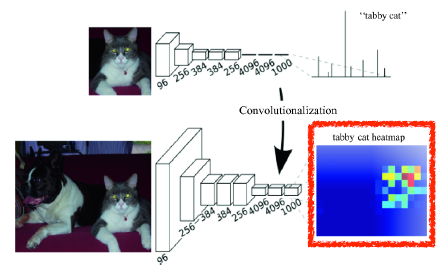
- While FCN can run with inputs of any size, the output dimensions are typically reduced by subsampling. So we need a way to connect the coarse output to the dense pixels.
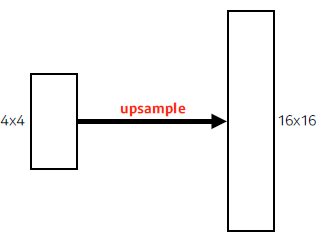
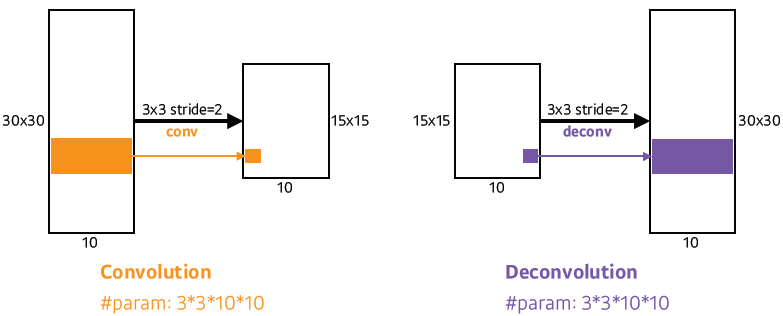
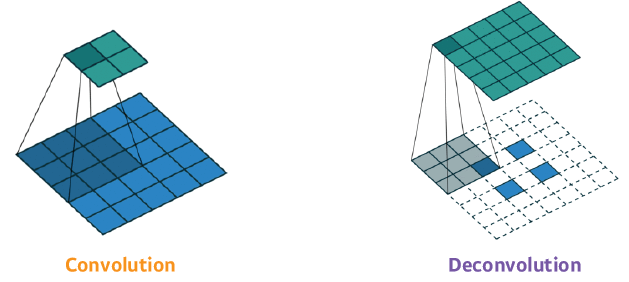
Deconvolution (conv transpose)
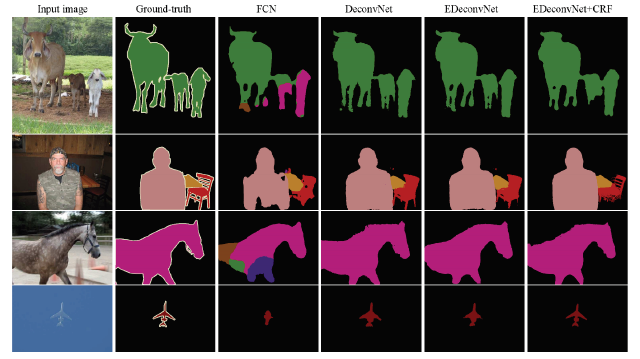
Result
Detection
R-CNN
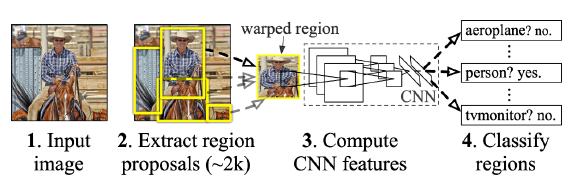
R-CNN (1) takes an input image, (2) extracts around 2,000 region proposals (using Selective search), (3) compute features for each proposal (using AlexNet), and then (4) classifies with linear SVMs

SPPNet
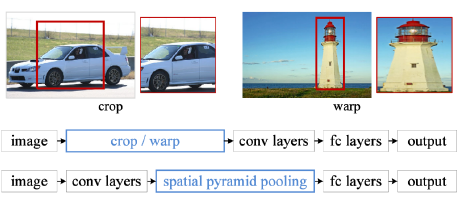
In R-CNN, the number of crop/warp is usually over 2,000 meaning that CNN must run more than 2,000 times (59s/image on CPU). However, in SPPNet, CNN runs once.
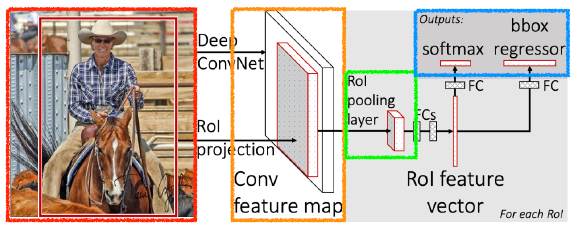
Fast R-CNN
- Takes an input and a set of bounding boxes.
- Generated convolutional feature map
- For each region, get a fixed length feature from ROI pooling
- Two outputs: class and bounding-box regressor.
Faster R-CNN
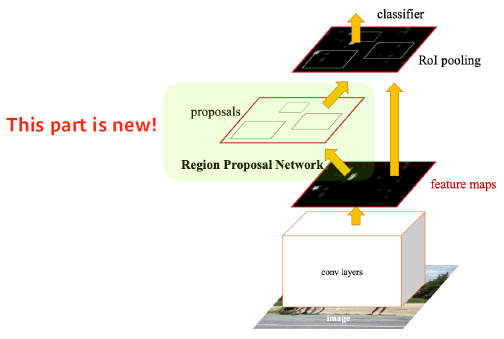
Faster R-CNN = Region Proposal Network + Fast R-CNN
- Region Proposal Network
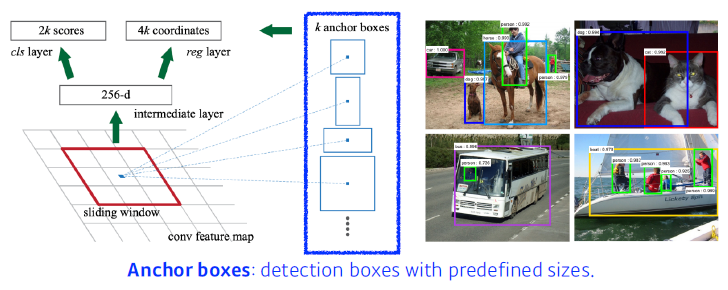
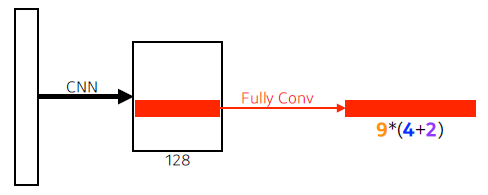
- 9: Three different region sizes with three different ratios
- (128, 256, 512) x (1:1, 1:2, 2:1) = 3 x 3 = 9
- 4: four bounding box regression parameters
- 2: box classification (whether to use it or not)

YOLO
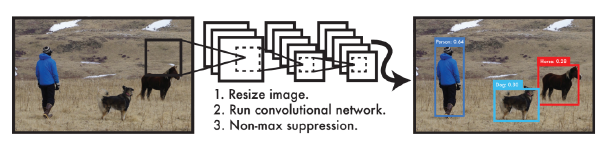
- YOLO (v1) is an extremely fast object detection algorithm.
- baseline: 45fps / smaller version: 155fps
- baseline: 45fps / smaller version: 155fps
- It simultaneously predicts multiple bounding boxes and class probabilities.
- No explicit bounding box sampling (compared with Faster R-CNN)
- No explicit bounding box sampling (compared with Faster R-CNN)
- Given an image, YOLO divides it into SxS grid. If the center of an object falls into the grid cell, that grid cell is responsible for detection.
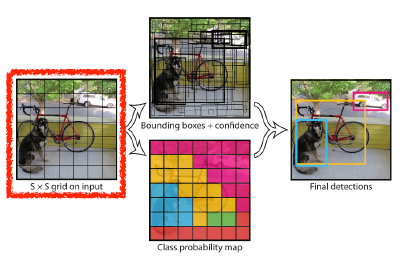
- Each cell predicts B bounding boxes (B=5).
- Each bounding box predicts
- box refinement (x / y / w / h)
- confidence (of objectness)
- Each bounding box predicts
-
Each cell predicts C class probabilities.
-
In total, it becomes a tensor with S x S x (B*5 + C) size.
- S x S: Number of cells of the grid
- B*5: B bounding boxes with offsets (x,y,w,h) and confidence
- C: Number of classes

