Generative Models Part 1
Learning a Generative Model
- Suppose we are given images of dogs.
- We want to learn a probability distribution such that
- Generation: If we sample ~ , should look like a dog (sampling).
- Density estimation: should be high if looks like a dog, and low otherwise (anomaly detection).
- Also known as, explicit models.
- Unsupervised representation learning: We should be able to learn what these images have in common, e.g., ears, tail, etc (feature learning).
- Then, how can we represent ?
Basic Discrete Distributions
- Bernoulli distribution: (biased) coin flip
- = {, }
- Specify . Then .
- Write: ~ .
- Categorical distribution: (biased) m-sided dice
- = {}
- Specify ,such that
- Write: ~
- Example
- Modeling an RGB joint distribution (of a single pixel)
- (r, g, b) ∼ p(R,G, B)
- Number of cases?
- How many parameters do we need to specify?
- Modeling an RGB joint distribution (of a single pixel)
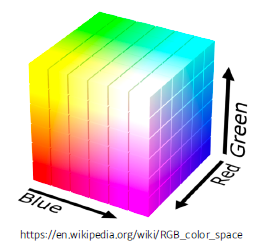
- Example
- Suppose we have of binary pixels (a binary image).
- How many possible states?
- Sampling from generates an image.
- How many parameters to specify ?
- How many possible states?
- Suppose we have of binary pixels (a binary image).
Structure Through Independence
- What if are independent then?
- How many possible states?
- How many parameters to specify ?
- entries can be described by just numbers! But this independence assumption is too strong to model useful distributions.
Conditional Independence
-
Three important rules
- Chain rule:
- How many parameters?
: 1 parameter
: 2 parameters ( and )
: 4 parameters Hence, , which is the same as before.
- How many parameters?
- Bayes rule:
- Conditional independence:
- Chain rule:
-
Now, suppose (Markov assumption), then
-
How many parameters?
-
Hence, by leveraging the Markov assumption, we get exponential reduction on the number of parameters.
-
Auto-regressive models leverage this conditional independency.
Auto-regressive Model

- Suppose we have binary pixels.
- Our goal is to learn over
- How can we parametrize ?
- Let's use the chain rule to factor the joint distribution.
- This is called an autoregressive model.
- Note that we need an ordering of all random variables.

초보 개발자입니다