Intro
Natural language processing
Low-level parsing
- Tokenization(단어 토큰화), stemming(단어 어근 추출)
Word and phrase level
-
Named entity recognition(NER)
단일 단어, 여러 단어로 이루어진 고유명사를 인식(ex New York Times) -
part-of-speech(POS) tagging
단어들의 품사를 인식(형용사, 부사, 명사, 형용사가 누굴 꾸미는지) -
noun-phrase chunking
-
dependency parsing
-
coreference resolution
Sentence level
-
Sentiment analysis(감정 분석)
-
machine translation
적절한 어순을 고려한 번역
Multi-sentence and paragraph level
-
Entailment prediction
두 문장간의 논리적인 관계를 예측
어제 John이 결혼했다. 어제 누군가 한명 결혼했다. (참)
어제 John이 결혼했다. 어제 아무도 결혼하지 않았다. (모순) -
question answering
구글에 where did napoleon die 라는 검색어를 치면 이에 해당하는 답을 찾아준다.(키워드가 포함된 문서를 검색하고, 주어진 질문에 대한 답을 찾아 보여준다.) -
dialog systems
챗봇과 같은 대화 시스템 -
summarization
주어진 문서를 한줄로 요약
Text mining
-
Extract useful information and insights from text and document data
e.g., analyzing the trends of AI-related keywords from massive news data -
Document clustering (e.g., topic modeling)
e.g., clustering news data and grouping into different subjects -
Highly related to computational social science
e.g., analyzing the evolution of people’s political tendency based on social media data
Information retrieval
- Highly related to computational social science
- This area is not actively studied now
- It has evolved into a recommendation system, which is still an active area of research
Trends of NLP
-
Word embedding
Text data can basically be viewed as a sequence of words, and each word can be represented as a vector through a technique such as Word2Vec or GloVe. -
RNN-family models (LSTMs and GRUs), which take the sequence of these vectors of words as input, are the main architecture of NLP tasks.
-
Overall performance of NLP tasks has been improved since attention modules and Transformer models, which replaced RNNs with self-attention, have been introduced a few years ago.
-
As is the case for Transformer models, most of the advanced NLP models have been originally developed for improving machine translation tasks.
-
In the early days, customized models for different NLP tasks had developed separately.
-
Since Transformer was introduced, huge models were released by stacking its basic module, self-attention, and these models are trained with large-sized datasets through language modeling tasks, one of the self-supervised training setting that does not require additional labels for a particular task.
e.g., BERT, GPT-3 … -
Afterwards, above models were applied to other tasks through transfer learning, and they outperformed all other customized models in each task.
-
Currently, these models has now become essential part in numerous NLP tasks, so NLP research become difficult with limited GPU resources, since they are too large to train.
(Google, Facebook, OpenAi 처럼 자본력과 데이터가 뒷받침 되어야 한다.)
Bag-of-Words
딥러닝 이전에 활용되던 기법
- Step 1. Constructing the vocabulary containing unique words
- Example sentences
“John really really loves this movie“, “Jane really likes this song” - Vocabulary
{“John“, “really“, “loves“, “this“, “movie“, “Jane“, “likes“, “song”}
- Example sentences
- Step 2. Encoding unique words to one-hot vectors
- Vocabulary
{“John“, “really“, “loves“, “this“, “movie“, “Jane“, “likes“, “song”}
Word vector John [1 0 0 0 0 0 0 0] really [0 1 0 0 0 0 0 0] loves [0 0 1 0 0 0 0 0] this [0 0 0 1 0 0 0 0] movie [0 0 0 0 1 0 0 0] Jane [0 0 0 0 0 1 0 0] likes [0 0 0 0 0 0 1 0] song [0 0 0 0 0 0 0 1] - For any pair of words, the distance is 2
- For any pair of words, cosine similarity is 0
- Vocabulary
-
A sentence/document can be represented as the sum of one-hot vectors
-
Sentence 1
“John really really loves this movie“
John + really + really + loves + this + movie: [1 2 1 1 1 0 0 0] -
Sentence 2
“Jane really likes this song”
Jane + really + likes + this + song: [0 1 0 1 0 1 1 1]
-
NaiveBayes Classifier for Document Classification
Bag-of-Words for Document Classification
-
Bayes’ Rule Applied to Documents and Classes
-
For a document d and a class c

-
For a document d, which consists of a sequence of words w, and a class c
-
The probability of a document can be represented by multiplying the probability of each word appearing
-
Conditional independence assumption
-
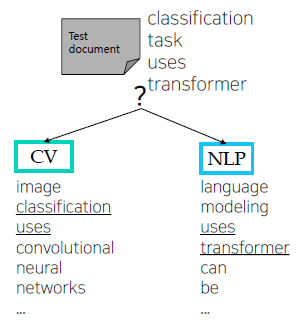
Example
| Doc(d) | Document (words, w) | Class (c) | |
|---|---|---|---|
| Training | 1 | Image recognition uses convolutional neural networks | CV |
| 2 | Transformer can be used for image classification task | CV | |
| 3 | Language modeling uses transformer | NLP | |
| 4 | Document classification task is language task | NLP | |
| Test | 5 | Classification task uses transformer | ? |
For each word , we can calculate conditional probability for class c
, where is occurrences of in documents of topic
| Word | Prob | Word | Prob |
|---|---|---|---|
For a test document = “Classification task uses transformer”
We calculate the conditional probability of the document for each class
We can choose a class that has the highest probability for the document
확률을 계산할 때, CV나 NLP에 존재하지 않는 단어면 0으로 처리되어, 앞뒤에 어떤 값이 곱해져도 0이 될 수 있어, 여러 regularization 기법이 사용된다.
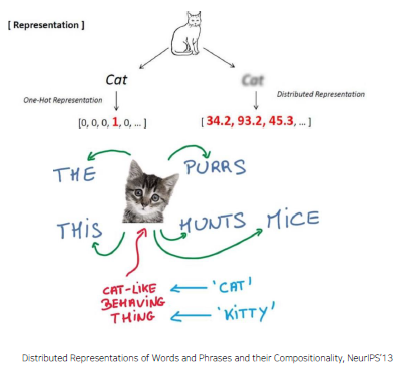
Word Embedding
Express a word as a vector
-
'cat' and 'kitty' are similar words, so they have similar vector representations short distance
-
'hamburger' is not similar with 'cat' or 'kitty’, so they have different vector representations far distance
Word2Vec
An algorithm for training vector representation of a word from context words (adjacent words)
-
Assumption: words in similar context will have similar meanings
-
e.g.
- The cat purrs.
- The cat hunts mice.
Idea
Suppose we read the word “cat”. What is the probability that we’ll read the word w nearby?

Distributional Hypothesis
- The meaning of “cat” is captured by the probability distribution
How Word2Vec Algorithm Works
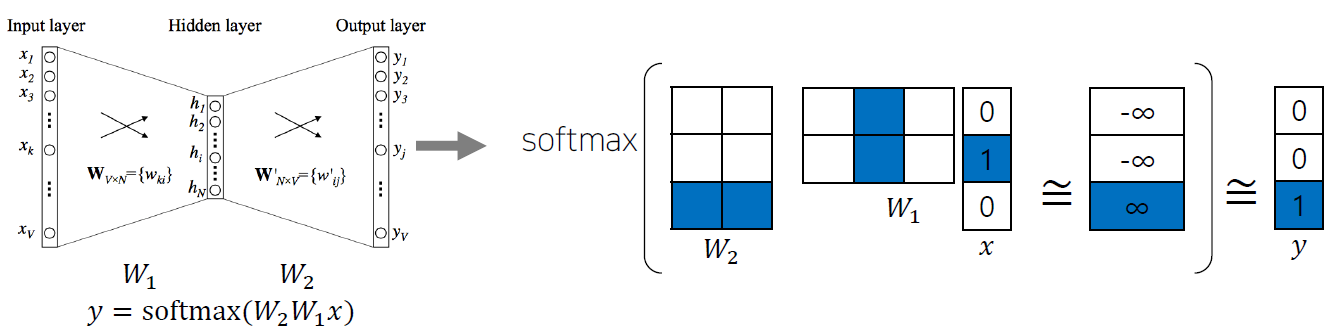
Sentence : “I study math.”
-
Vocabulary: {“I”, “study” “math”}
-
Input: “study” [0, 1, 0]
-
Output: “math” [0, 0, 1]
-
Columns of and rows of represent each word
-
E.g., ‘study’ vector : 2nd column in , ‘math’ vector : 3rd row in .
-
The ‘study’ vector in and the ‘math’ vector in should have a high inner-product value.
-
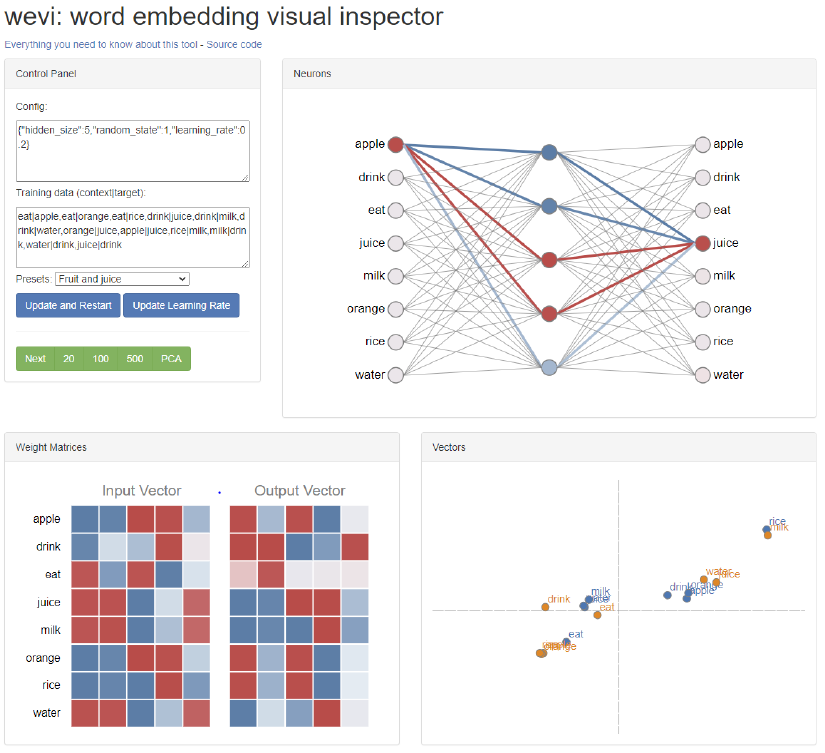
https://ronxin.github.io/wevi/
- A vector representation of ‘eat’ in has similar pattern with vectors of ‘apple’, ‘orange’, and ‘rice’ in
- When the input is 'eat', the model can predict 'apple', 'orange’, or 'rice’ for output, because the vectors have high inner product values
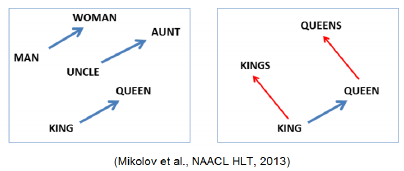
Property of Word2Vec
-
The word vector, or the relationship between vector points in space, represents the relationship between the words.
-
The same relationship is represented as the same vectors.
-
e.g.,
vec[queen] – vec[king] = vec[woman] – vec[man]
-
Korean Word2Vec : http://w.elnn.kr/search
