Self-supervised Pre-training Models
Recent Trends
-
Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder and decoder in recent NLP applications as well as in other areas.
-
Training deeply stacked Transformer models via a self-supervised learning framework has significantly advanced various NLP tasks through transfer learning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA, …
-
Other applications are fast adopting the self-attention and Transformer architecture as well as self-supervised learning approach, e.g., recommender systems, drug discovery, computer vision, …
-
As for natural language generation, self-attention models still requires a greedy decoding of words one at a time.
<SOS> 토큰을 항상 시작으로 한다는 범위를 벗어나지는 못 했다.
GPT-1
Improving Language Understanding by Generative Pre-training
- GPT-1
-
It introduces special tokens, such as <S> /<E>/ $, to achieve effective transfer learning
during fine-tuning -
It does not need to use additional task-specific architectures on top of transferred
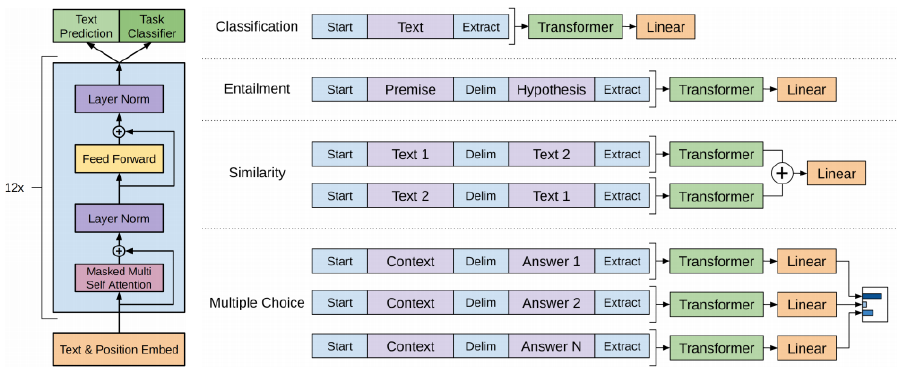
-
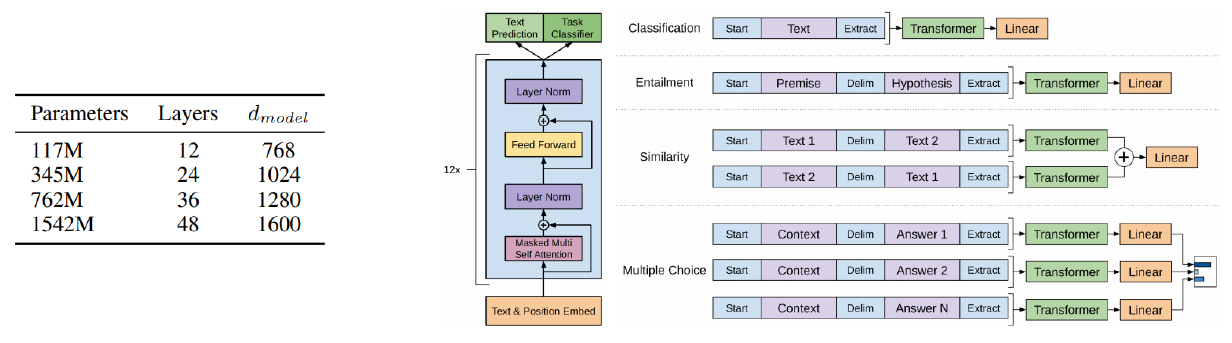
위 그림에서와 같이 문장의 마지막에 Extract 토큰을 추가해서 이 토큰만을 Linear transformation을 하고, 여기서 Classification(감정분석)이나 Entailment(논리), Similarity(유사도) 등을 결과로 추출한다. Similarity의 경우 'John은 어제 결혼했다.'와 '누군가는 어제 결혼 했다.'의 문장이 있으면 두 문장 사이에 delimiter 토큰을 넣고 하나의 sequence로 만든후 Extract 토큰을 추출한다.
-
다음 단어를 예측하는 Text precision과 Task Classifier를 동시에 수행한다.
-
별도의 labeling 된 데이터 없이 다음 sequence를 예측하도록 학습되기 때문에, 대규모 데이터로 학습이 가능하다. 실제로 labeling 된 데이터는 별로 없기 때문에 이렇게 대규모로 pre-trained 된 모델을 사용하고 원래 text prediction layer는 떼어내고, main task를 위한 layer(주제 분류, 감정분석 등)를 쌓아서 transfer learning을 통해 원하는 task를 수행하도록 학습한다. 이 때 pre-trained 모델의 learning rate는 상대적으로 낮게 설정하여, 일반화 가능한 지식이 유지될 수 있도록 한다.
-
12-layer decoder-only transformer
-
12 head / 768 dimensional states
-
GELU activation unit
-
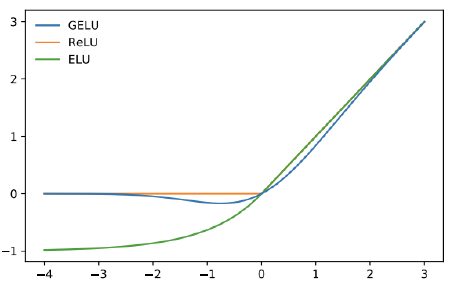
-
Experimental Results
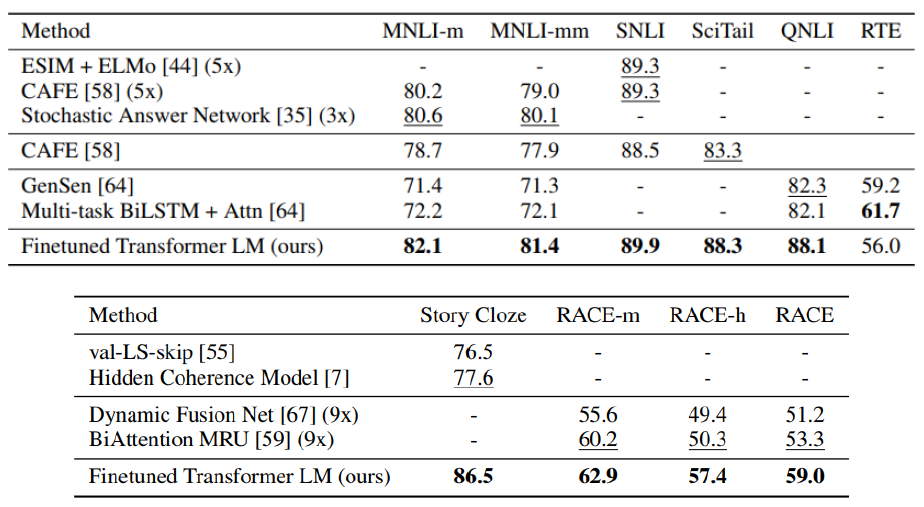
이처럼 pre-trained 된 모델을 사용하는게 상대적으로 소량의 labeling된 task만을 위해 modeling 된 customized 모델보다 정확도가 높은 것이 확인된다.
BERT
Pre-training of Deep Bidirectional Transformers for Language Understanding
- Learn through masked language modeling task
- Use large-scale data and large-scale model
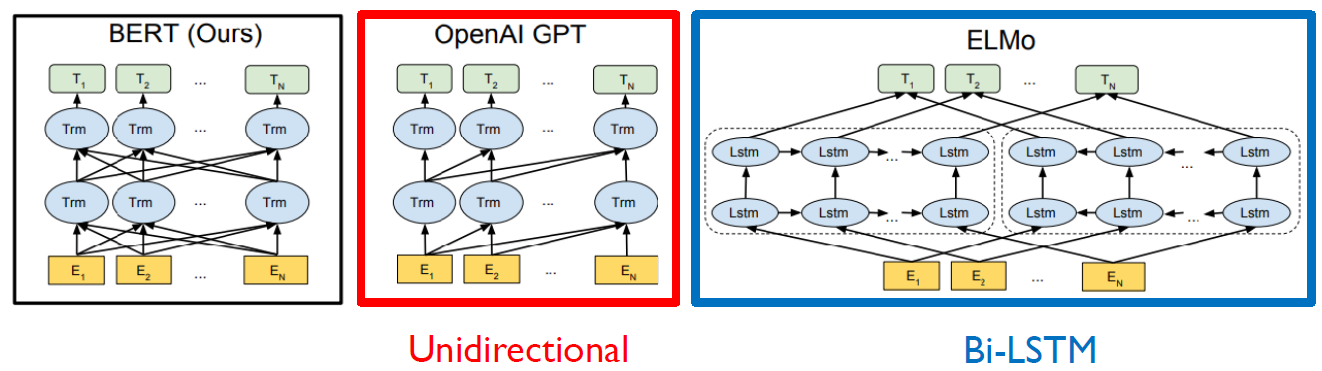
Transformer 이전에 LSTM 기반의 인코더로 pre-training한 ELMo라는 모델도 있었다. 이 LSTM 인코더가 transformer로 대체되었다.
Masked Language Model
-
Motivation
Language models only use left context or right context, but language understanding is bidirectional
우리가 영어 문장을 해석할 때 모르는 단어가 나와도 앞 뒤 문맥으로 파악하듯이 언어를 이해하는 것은 양방향으로 진행된다. -
If we use bi-directional language model?
Problem: Words can “see themselves” (cheating) in a bi-directional encoder
Pre-training Tasks in BERT
- Masked Language Model (MLM)
- Mask some percentage of the input tokens at random, and then predict those masked tokens.
- 15% of the words to predict
몇 %의 단어를 mask로 치환해서 맞추게 할지는 사전에 결정해줘야 하는 하이퍼 파라미터이다.- 80% of the time, replace with [MASK]
- 10% of the time, replace with a random word
- 10% of the time, keep the sentence as same
- Next Sentence Prediction (NSP)
- Predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence

- Predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence
Masked Language Model
- How to
- Mask out % of the input words, and then predict the masked words
- e.g., use k= 15%
mask로 치환하는 비율을 높게하면 주어진 문장에서 mask를 파악하기에 충분한 정보가 제공되지 않을 수 있다. 반대로 비율을 작게하면 예를 들어 100단어 중에서 1단어만 mask해서 맞추게 하면 transformer model이 100단어를 encoding하는 과정도 학습시간이 오래 걸리는데, 단순히 1 단어만 맞추게 하는 것은 학습 효율이 떨어지게 된다. (학습 시간이 오래 걸린다.)
BERT에서는 15%가 적절한 비율이라는 결론을 도출했다.

-
Problem
Mask token never seen during fine-tuning
pre-training 과정에서는 주어진 문장에서 평균적으로 15% 단어가 masking된 단어로 이루어져있는 문장에 익숙해지도록 모델이 학습되는데, 이 모델을 main task에 수행할 때는 mask라는 토큰은 더이상 등장하지 않게 된다.
train에서 나오는 양상이나 패턴이 main task를 수행할 때 주어지는 입력에 대한 문장과는 다른 특성을 보여 학습을 방해하거나, 성능을 올리는데 방해요소가 될 수 있다. -
Solution
15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead:-
80% of the time, replace with [MASK]
went to the store → went to the [MASK] -
10% of the time, replace with a random word
다른 단어를 원래 있어야 하는 단어로 복원해줄 수 있도록, 문제의 난이도를 올려서 학습한다.
went to the store → went to the running
I love this movie → I him this movie -
10% of the time, keep the same sentence
원래 문장을 주고나서 이 문장은 바뀌는거 없이 그대롤 출력되야 한다고 학습시킨다.
went to the store → went to the store
-
Next Sentence Prediction
To learn the relationships among sentences, predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence
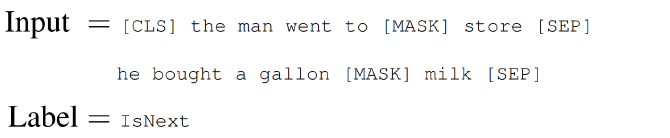

GPT의 Extract 토큰 역할을 하는 <CLS> 토큰을 넣어주는데, GPT와는 달리 문장의 앞 부분에 넣어준다. 그리고 각 문장이 끝날 때 <SEP> 토큰을 넣어준다. 그리고 이 sequence로 binary classification을 수행하여 문맥상 다음에 오는 문장이 맞는지 아닌지 학습한다.
BERT Summary
- Model Architecture
- BERT BASE: L = 12, H = 768, A = 12
- BERT LARGE: L = 24, H = 1024, A = 16
- L은 Self-Attention layer의 수
A는 각 Layer별로 정의된 Attention Head의 수
H는 각 Self-Attention에서 동일하게 유지되는 encoding 벡터의 차원 수
- Input Representation
- WordPiece embeddings (30,000 WordPiece)
Word 별로의 embedding이 아닌 이를 더 쪼갠 각각의 sequence를 sub-word라는 단위로 embedding을 한 후 입력 벡터로 넣어준다. 예를 들어 pre training이라는 단어가 있다면 이를 pre와 training 이라는 word로 나눈다.
- Learned positional embedding
positional embedding도 먼저 정해진 값이 아니라 학습에 의해 정해지져 더해진다.
- [CLS] – Classification embedding
- Packed sentence embedding [SEP]
문장의 끝마다 나오는 토큰
- Segment Embedding
- WordPiece embeddings (30,000 WordPiece)
- Pre-training Tasks
- Masked LM
- Next Sentence Prediction
Input Representation
The input embedding is the sum of the token embeddings, the segmentation embeddings and the position embeddings
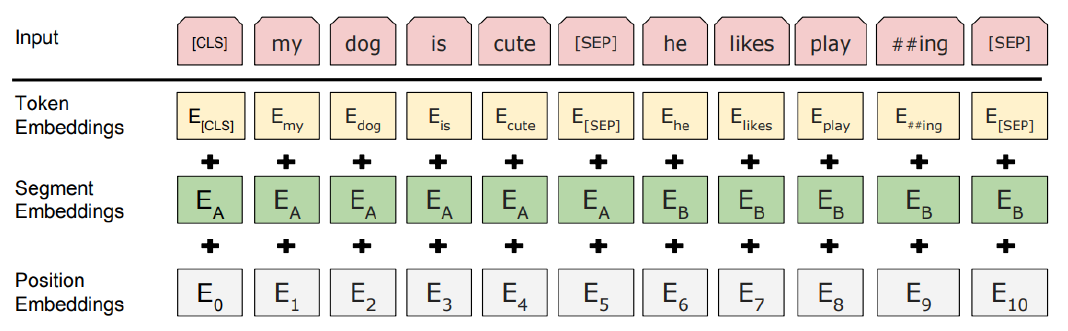
문장 레벨에서의 position을 반영한 벡터인 segmet embedding 벡터도 positional embedding 벡터와 같이 더해준다. 각 벡터는 합해지기 때문에 차원이 동일해야 한다.
Fine-tuning Process
Transfer Learning

- Sentence Pair Classification Tasks
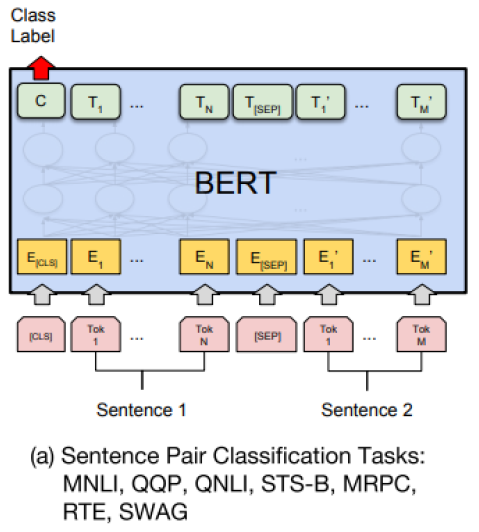
두 개의 문장을 <SEP> 토큰으로 구분지어 하나의 sequence로 만든 후 BERT를 통해 Encoding을 하고 나서, CLS에 해당하는 벡터를 output layer에 입력으로 주어 다 수 문장에 대한 예측 task를 수행한다.
- Single Sentence Classification
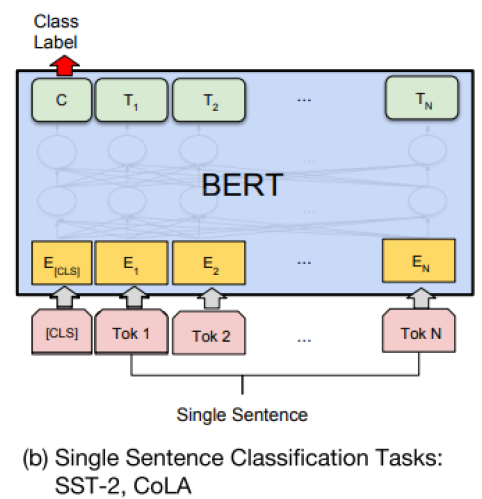
단일 문장에 대한 task는 문장을 하나만 주고 앞에 <CLS> 토큰을 입력으로 주고 BERT를 통과시켜 얻은 <CLS> 에 해당하는 벡터를 output layer의 입력으로 준다.
- Singgle Sentence Tagging Tasks
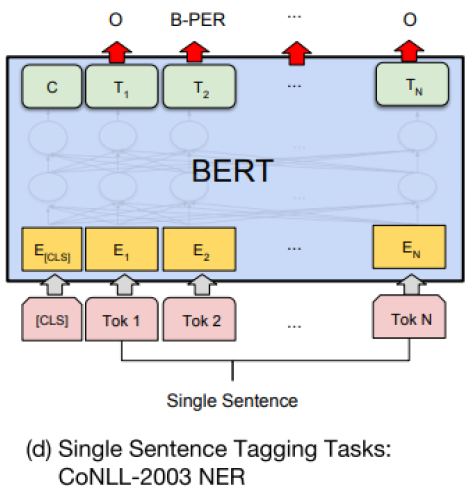
주어진 문장에서 각 각의 단어들에 대한 품사, 문장 성분을 예측하는 경우 (단어별 classification) 각 <CLS>토큰을 포함한 word 별 토큰의 encoding 벡터가 얻어지면 그 벡터들을 동일한 output layer에 통과시켜 각 word별 prediction을 수행한다.
BERT vs GPT-1
-
Comparison of BERT and GPT-1
- Training-data size
GPT is trained on BookCorpus(800M words) ; BERT is trained on the BookCorpus and Wikipedia (2,500M words) - Training special tokens during training
BERT learns [SEP],[CLS], and sentence A/B embedding during pre-training
- Training-data size
-
Batch size
BERT – 128,000 words ; GPT – 32,000 words -
Task-specific fine-tuning
GPT uses the same learning rate of 5e-5 for all fine-tuning experiments
BERT chooses a task-specific fine-tuning learning rate.
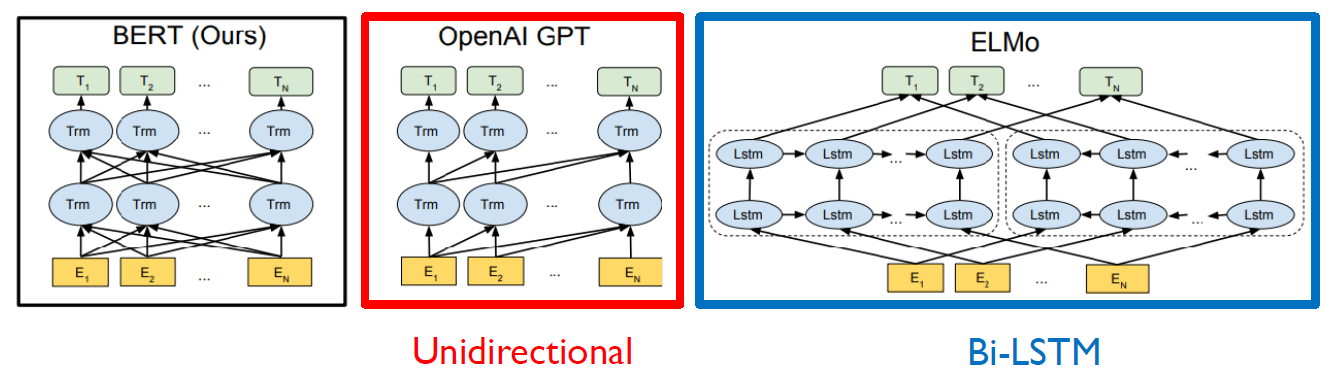
GPT는 주어진 sequence를 encoding 할 때 바로 다음 단어를 예측해야 하는 task를 진행하기 때문에 특정한 time step에서 그 다음에 나타나는 단어로의 접근을 허용하면 안 된다. 그래서 transformer의 decoder처럼 masked self attention을 사용한다.
그러나 BERT의 경우 mask로 치환된 토큰들을 예측하기 때문에 mask 단어를 포함하여 전체 주어진 모든 단어들에 접근이 가능하다. 그래서 transformer의 encoder에서 사용되는 self attention module을 사용한다.
GLUE Benchmark Results
여러 task들을 한 곳에 모아놓은 Benchmark data set을 GLUE 데이터라고 한다.
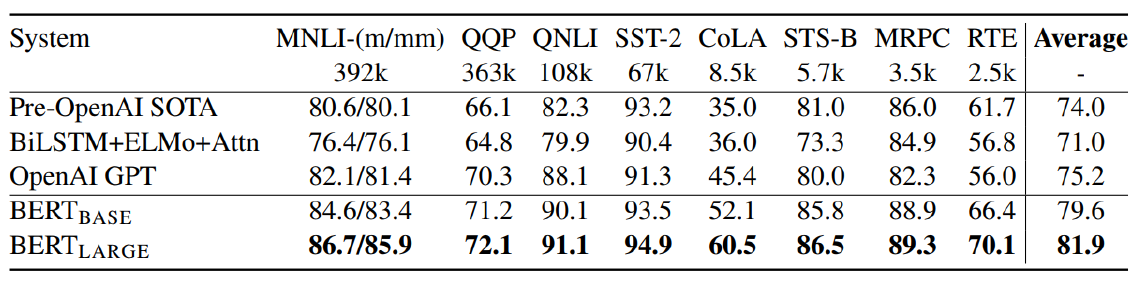
위 결과를 보면 BERT가 각 task에 대해서 성능이 좋은 것을 알 수 있다.
Machine Reading Comprehension (MRC), Question Answering
질의응답의 형태인데 질문만 주어지고 그 질문에 대한 답을 예측하는게 아니라 주어진 지문이 있을 떄 지문을 잘 이해하고 질문에서 필요로 하는 정보를 잘 추출할 수 있는 기계 독해에 기반한 질의응답이다.

SQuAD
스탠포드에서 만든 질문과 답변에 대한 데이터 set으로 Stanford Question Answering Dataset의 약자이다. https://rajpurkar.github.io/SQuAD-explorer/ 이 링크를 통해 들어가면 SQuAD 2.0 버전과 1.1 버전에 대한 leaderboard 점수를 확인할 수 있다. (BERT라는 단어가 들어간 모델이 많이 보인다.)
SQuAD 1.1
지문에서 답을 찾을 수 있는 질문만 입력으로 주어진다.

- main task를 수행하는 layer가 작동하는 방식
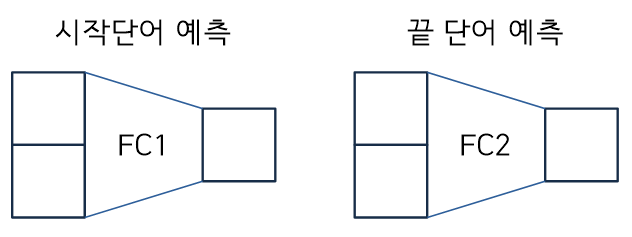
먼저 질문과 지문을 <SEP> 토큰으로 이어주고 제일 앞에 <CLS> 토큰을 넣는다. 이 때 각 단어별 최종 encoding 벡터가 나오면 이를 공통된 output layer를 통해서 스칼라 값을 뽑도록 한다.
예를 들어 각각 encoding 벡터가 2차원으로 나오게 된 경우 output layer는 단순히 이 2차원 벡터를 단일한 차원의 스칼라 값으로 변경해주는 Fully Connected Layer가 된다. 이 때 Fully Connected Layer가 학습되는 파라미터가 된다. 각 스칼라 값을 얻은 후에는 softmax를 통과시켜 주고, answer가 시작하는 단어(위 문장에선 first)의 logic 값을 100%에 가까워 지도록 softmax loss를 통해 학습한다. 그리고 answer가 끝나는 단어를 예측하는 또 하나의 output layer를 통해 ground truth 단어를 예측하도록 학습한다.
SQuAD 2.0
지문에서 답을 찾을 수 없는 질문도 입력으로 주어진다.
- Use token 0 ([CLS]) to emit logit for “no answer”
- “No answer” directly competes with answer span
- Threshold is optimized on dev set
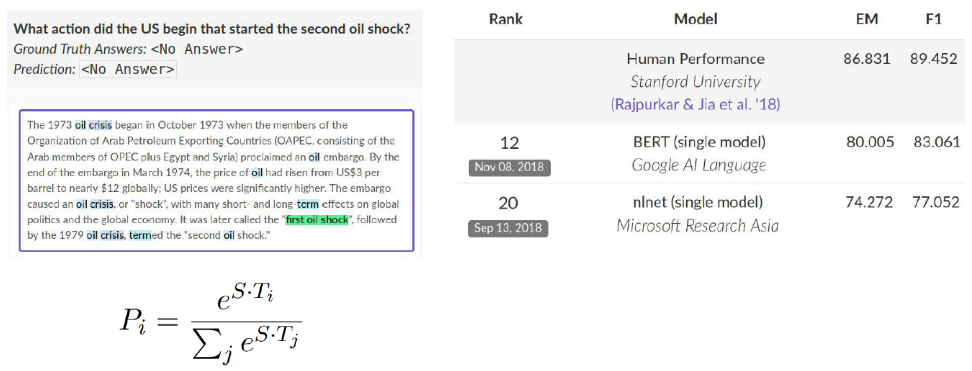
[CLS] 토큰을 binary classification을 통해 answer가 지문에 있는지 없는지를 판단하고, 없으면 'no answer'를 출력하고 있으면 SQuAD 1.1 처럼 답의 첫 문장과 끝 문장을 찾는다.
On SWAG
- Run each Premise + Ending through BERT
- Produce logit for each pair on token 0 ([CLS])
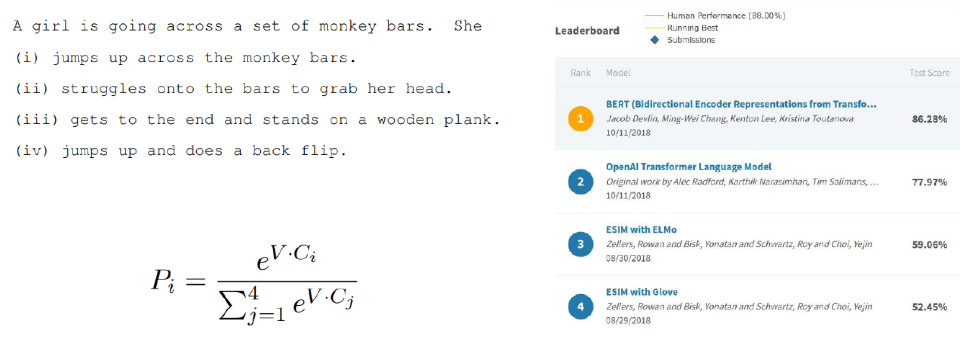
주어진 문장과 선택해야 하는 각각의 문장을 하나의 sequence로 만들고 각각의 <CLS>가 encoding된 벡터를 얻는다. 그리고 이를 동일한 Fully Connected Layer를 통해 4개의 스칼라 값으로 변환하고, softmax를 통과시켜 예측을 한다.
Ablation Study
-
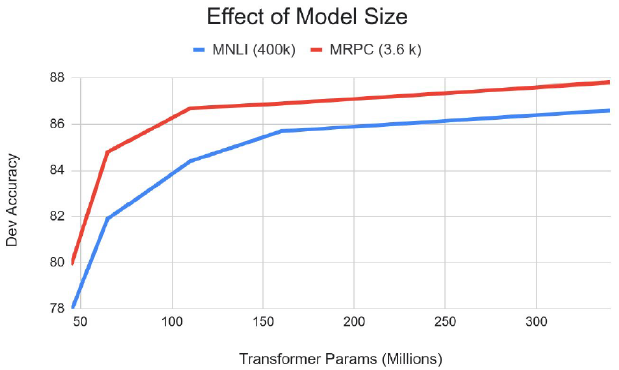
Big models help a lot
- Going from 110M to 340M params helps even on datasets with 3,600 labeled examples
- Improvements have not asymptoted
파라미터 수를 키울 수록 모델의 성능이 올라간다고 알려져있다. 그렇기 때문에 GPU 자원을 최대로 이용할 수 있을 때까지 model 크기를 늘릴 수 있다면 늘리는 것이 좋다고 전망된다.
Advanced Self-supervised Pre-training Models
GPT-2
Language Models are Unsupervised Multi-task Learners
- Just a really big transformer LM(Language Model)
GPT-1과 같이 다음 단어를 예측하는 task를 수행한다.
- Trained on 40GB of text
- Quite a bit of effort going into making sure the dataset is good quality
- Take webpages from reddit links with high karma
- Language model can perform down-stream tasks in a zero-shot setting - without any parameter or architecture modification
Downstream Task: 자연어 처리분야에서 언어모델을 pre-train 방식을 이용해 학습을 진행하고, 그 후에 원하고자 하는 task를 fine-tuning 방식을 통해 모델을 업데이트 하는 방식을 사용한다. 이 떄 task를 down-stream task라 한다.
zero-shot setting

위 문장들은 GPT-2 에게 첫 문단을 주었을 때, GPT-2가 생성한 문단들이다.
Motivation (decaNLP)
- The Natural Language Decathlon: Multitask Learning as Question Answering
- Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher
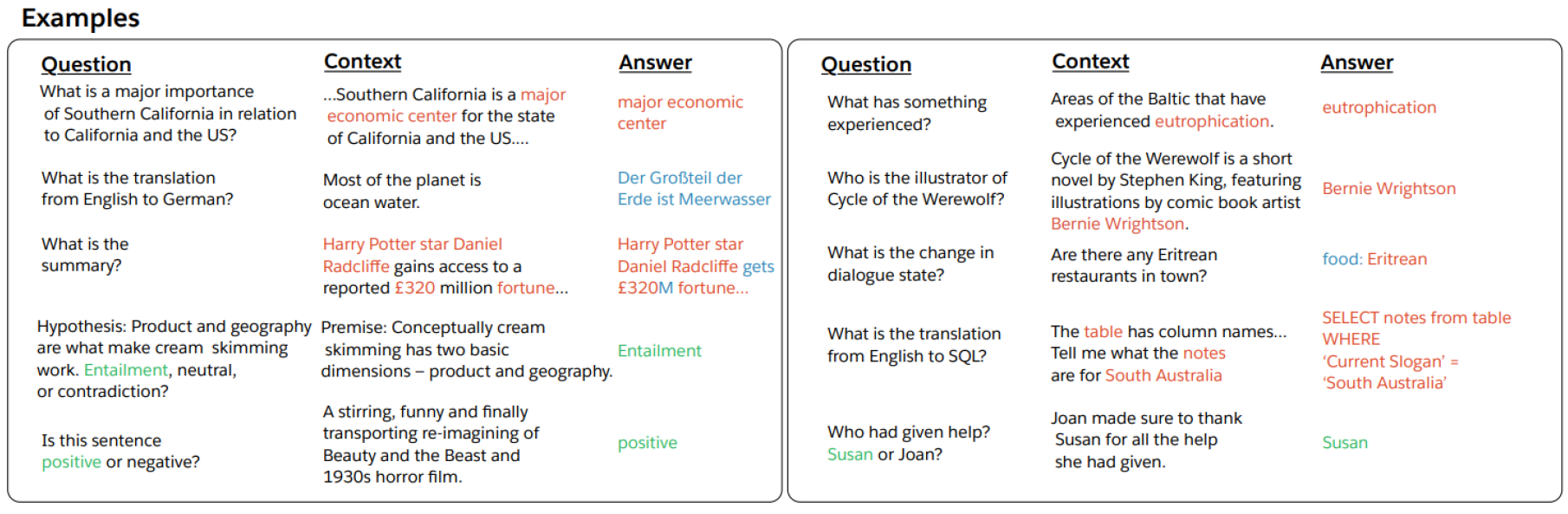
'모든 자연어 처리에 대한 task들이 질의응답 형식으로 바뀔 수 있다.' 는 아이디어
Sentence: I love this movie
Question: What do you think about this movie in terms of positive or negative sentiment?
주어진 문단이 있을 때
Question: What is the summarization above the paragraph?
번역 문장
Question: What is the translated sentence in Korean?
Datasets
- A promising source of diverse and nearly unlimited text is web scrape such as common crawl
They scraped all outbound links from Reddit, a social media platform, WebText
레딧에서 어떤 질문에 대한 많은 호응을 얻은 답변이 외부링크를 포함해서 주어졌을 때 해당 링크를 크롤링했다. (잘 쓰여져 있을 문서일 확률이 높다.)- 45M links
- Scraped web pages which have been curated/filtered by humans
- Received at least 3 karma (up-vote)
- 8M removed Wikipedia documents
- Use dragnet and newspaper to extract content from links
- 45M links
- Preprocess
- Byte pair encoding (BPE)
subword level에서의 word embedding (BERT의 word piece와 비슷하다.) - Minimal fragmentation of words across multiple vocab tokens
- Byte pair encoding (BPE)
Model
- Modification
- Layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network
- Additional layer normalization was added after the final self-attention block.
- Scaled the weights of residual layer at initialization by a factor of where is the number of residual layer
모델의 위쪽으로 갈 수록 scaled 되어 선형변환되는 값들이 점점 더 0에 가까워지도록, 위쪽 layer의 역할이 점점 더 줄어들 수 있도록 model을 구성
Question Answering
- Use conversation question answering dataset(CoQA)
- Achieved 55 score, exceeding the performance 3 out of 4 baselines without labeled dataset
- Fine-tuned BERT achieved 89 performance
Summarization
- CNN and Daily Mail Dataset
- Add text TL;DR: after the article and generate 100 tokens
TL이나 DR 토큰을 뉴스 기사 뒤에 붙인 뒤 100개의 토큰을 만든다. - (TL;DR: Too long, didn’t read)
- Add text TL;DR: after the article and generate 100 tokens

Translation
- User WMT14 en-fr dataset for evaluation
- Use LMs on a context of example pairs of
the format:
- English sentence = French sentence - Achieve 5 BLEU score in word-by-word substitution
- Slightly worse than MUSE (Conneau et al., 2017)
- Use LMs on a context of example pairs of

예시의 각 문장들을 보면 in French라는 문장이 포함되어있는 것을 볼 수 있는데 이처럼 Question 형식으로 task를 수행하도록 한다. (번역)
GPT-3
Language Models are Few-Shot Learners
Language Models are Few-shot Learners
-
Scaling up language models greatly improves task-agnostic, few-shot performance
-
An autoregressive language model with 175 billion parameters in the few-shot setting
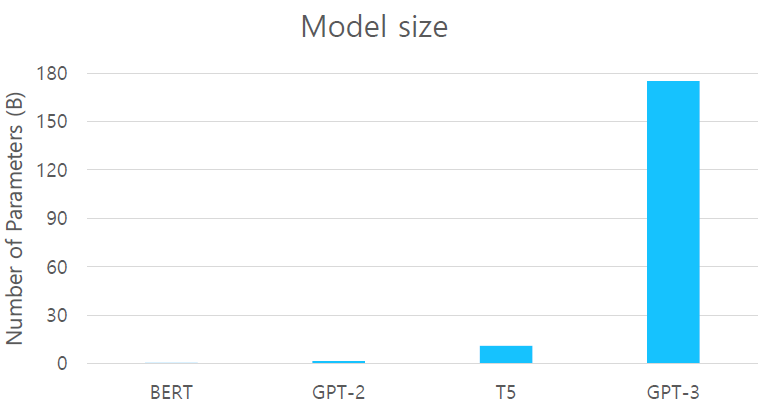
모델의 구조적인 측면에서 GPT-2에서 특별한 점이 개선한 것이 아니라 model의 size 자체를 키워서 비교할 수 없을 정도로 파라미터 수를 키운 것이다. (self-Attention block을 높이 쌓았다.) -
96 Attention layers, Batch size of 3.2M
-
Prompt
the prefix given to the model -
Zero-shot
Predict the answer given only a natural language description of the task -
One-shot
See a single example of the task in addition to the task description -
Few-shot
See a few examples of the task

학습시킬 때 영어를 불어로 바꾸는 downstream task를 거치지 않았는데도 번역이 가능한 것을 볼 수 있다.
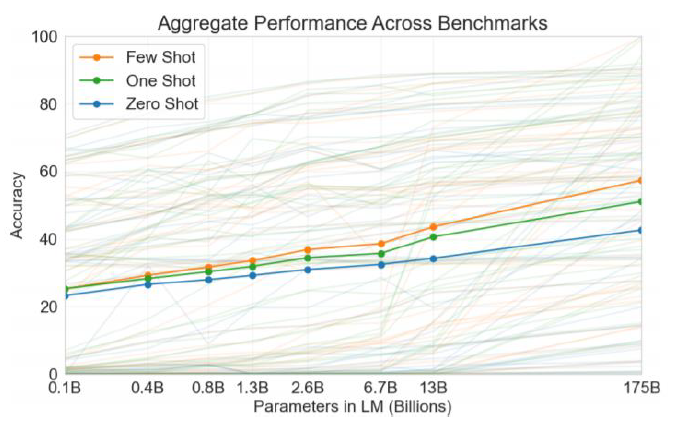
- Zero-shot performance improves steadily with model size
- Few-shot performance increases more rapidly
ALBERT
A Lite BERT for Self-supervised Learning of Language Representations
Is having better NLP models as easy as having larger models?
- Obstacles
- Memory Limitation
- Training Speed
- Solutions
- Factorized Embedding Parameterization
- Cross-layer Parameter Sharing
- (For Performance) Sentence Order Prediction
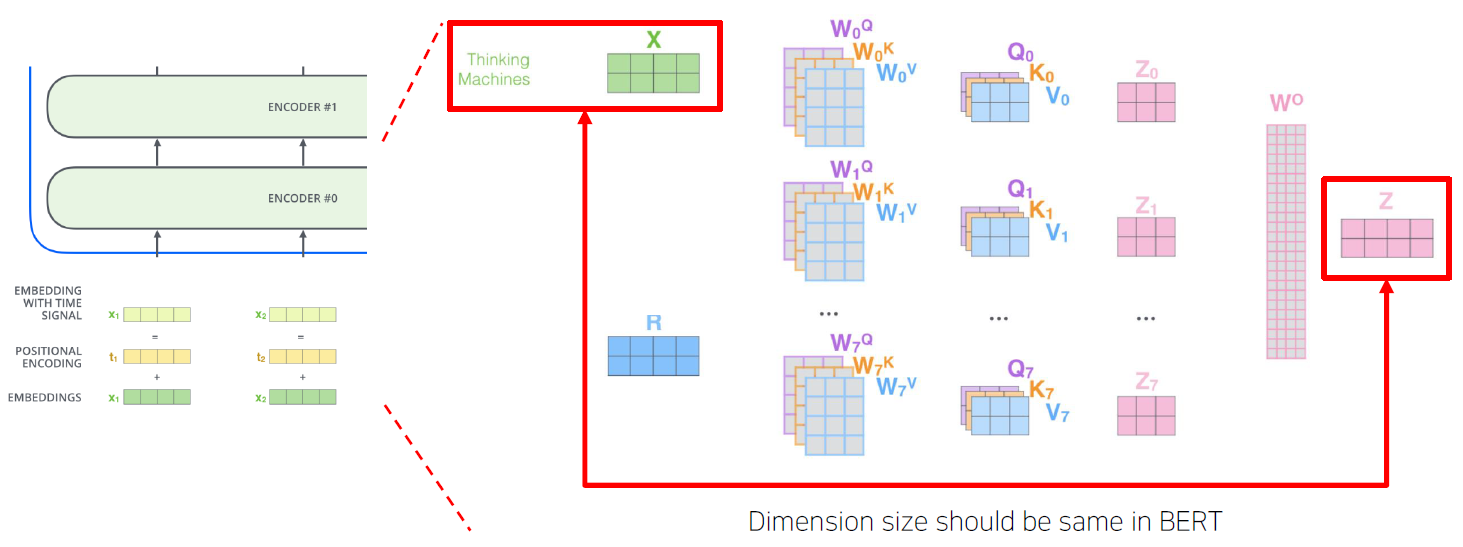
Factorized Embedding Parameterization
Embedding 벡터는 서로 독립적이기 때문에 context를 고려한 벡터보다 정보가 상대적으로 적다. 그래서 이 embedding 벡터의 차원수를 줄이는 것이다.
context 정보를 보관하는데 4차원 벡터가 필요하다면 embedding 벡터의 차원 수를 2차원으로 줄이고 이 벡터에 행렬곱을 해주어, context의 정보도 담을 수 있도록 차원수를 늘려준다.
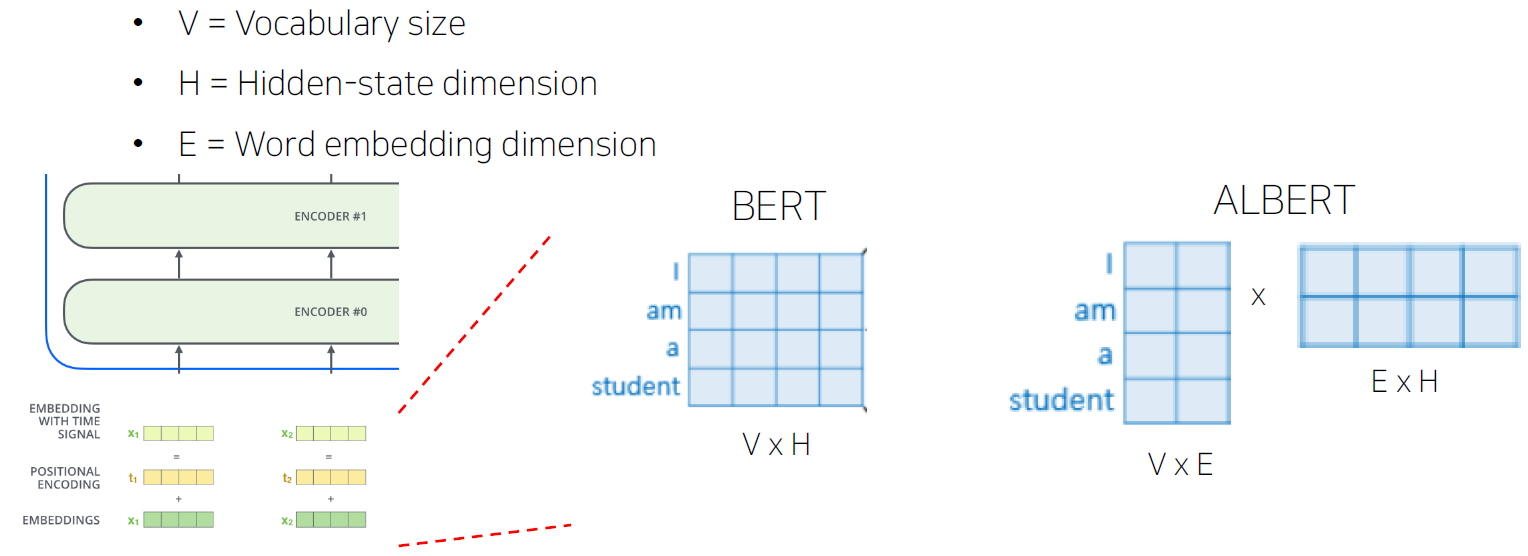
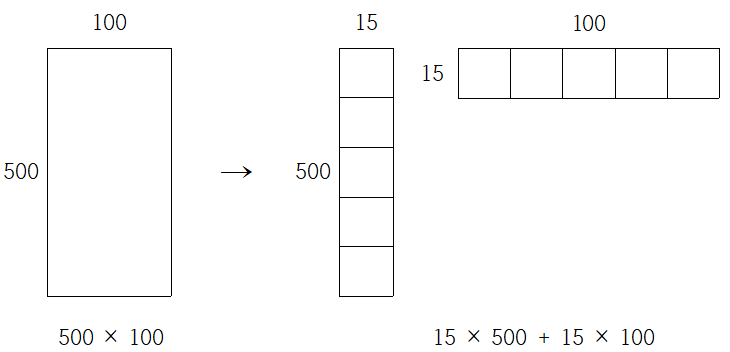
- 파라미터수 계산
Cross-layer Parameter Sharing
self-attention layer들이 적층될 때, 각 를 층별로 따로 두는 것이 아니라 같은 파라미터를 공유한다.
- Shared-FFN: Only sharing feed-forward network parameters across layers
- Shared-attention: Only sharing attention parameters across layers
- All-shared: Both of them
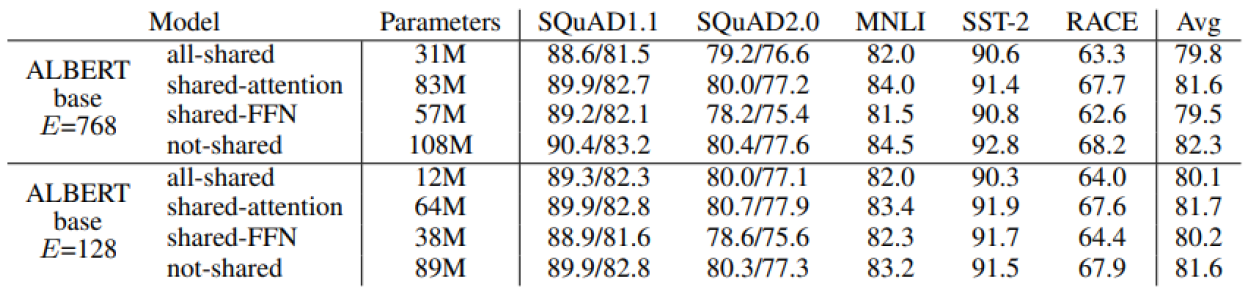
위 표를 보면 공유해서 줄인 파라미터 수와 성능을 확인해보면, 파라미터수는 크게 줄었지만, 성능은 크게 줄지 않은 것을 확인할 수 있다.
Sentence Order Prediction
기존의 BERT 모델에서는 문장과 문장을 <SEP> 토큰으로 연결해주고, 이 문장들이 연결되는 문장인지를 확인하도록 pre-train 되었다. 그러나 주제가 다른 문장, 예를 들어 경제와 수학의 문장을 하나씩 가져와 input으로 주면 입력들이 구성된 단어 자체가 주제별로 크게 상이할 수 밖에 없어 모델이 학습하는 게 굉장히 단순해질 수 있다.
여기에 착안하여 ALBERT는 문장간 순서를 고려하여 문장1 다음에 문장2가 오는게 정답이라면, 문장2 다음에 문장1이 나올 경우 같은 주제라도 오답이라고 분류하도록 학습하였다.
- Next Sentence Prediction pretraining task in BERT is too easy
- Predict the ordering of two consecutive segments of text
- Negative samples the same two consecutive segments but with their order swapped

NSP와 SOP 아무것도 학습시키지 않은 모델 None과 NSP와 SOP의 성능을 비교 분석한 위 표를 보면 NSP는 masked 데이터만 학습시킨 모델보다 오히려 성능이 떨어질 때도 있는 것이 보이는데, SOP의 경우에는 성능이 전체적으로 오른게 보인다.
GLUE Results
다양한 자연어 처리에 대한 task를 benchmark dataset으로 포함하는 GLUE dataset
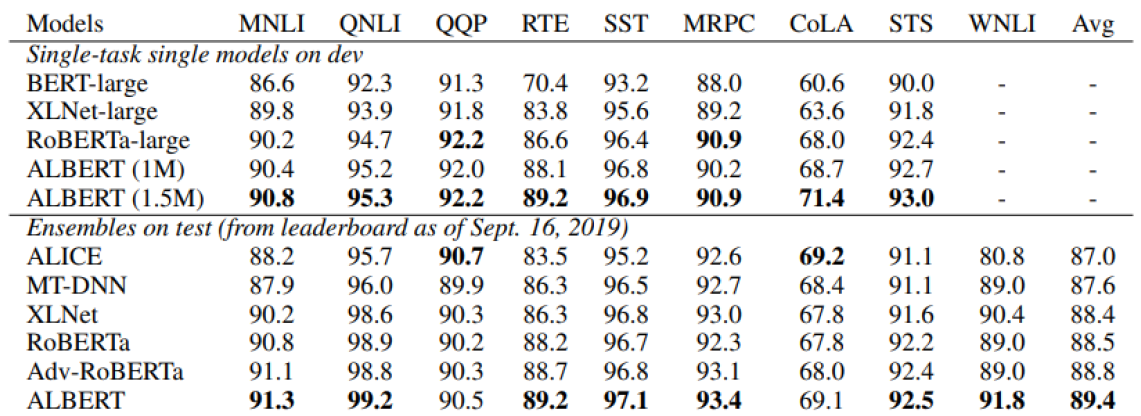
ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- Learn to distinguish real input tokens from plausible but synthetically generated replacements
- Pre-training text encoders as discriminators rather than generators
- Discriminator is the main networks for pre-training.
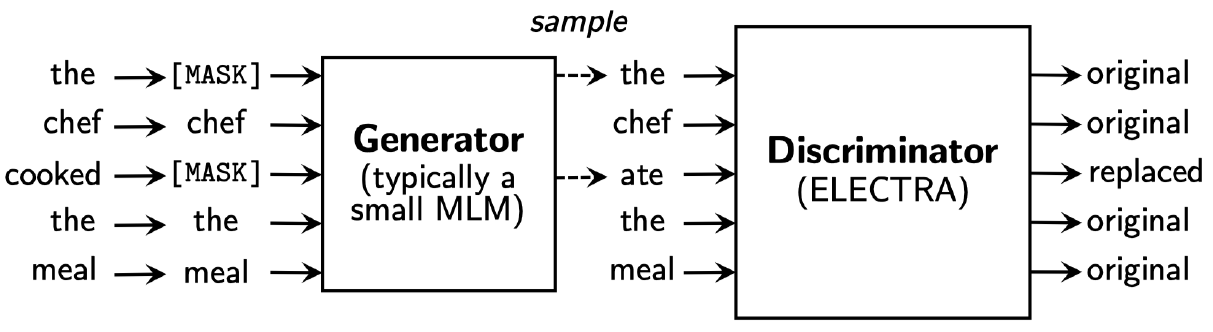
Generative Adversarial Networks 의 아이디어에서 착안한 모델로 Generator가 mask된 단어들을 예측해서 채워넣고, Discriminator가 이 예측된 단어들이 original단어인지 replaced 단어인지 예측한다.
- Replaced token detection pre-training vs masked language model pre-training
Outperforms MLM-based methods such as BERT given the same model size, data, and compute
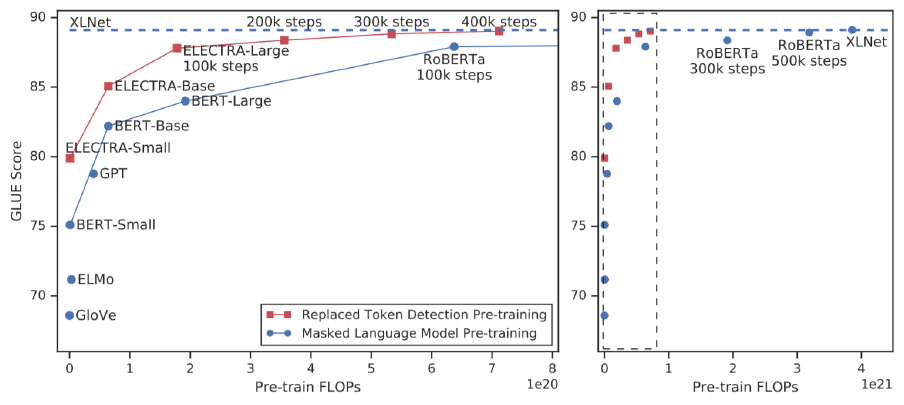
학습에 필요한 계산량(가로축)이 많아질수록, 모델의 성능이 점점 더 올라간다. 이 중 ELECTRA는 같은 계산량에 비해 다른 모델들 보다 좋은 성능을 보인다.
Light-weight Models
Knowledge distillation
미리 잘 학습된 큰 네트워크(Teacher network)의 지식을 실제로 사용하고자 하는 작은 네트워크(Student network) 에게 전달하는 것
- DistillBERT (NeurIPS 2019 Workshop)
트랜스포머 모델의 구현체를 라이브러리 형태로 손쉽게 쓸 수 있도록 제공해주는 huggingface에서 발표한 논문- A triple loss, which is a distillation loss over the soft target probabilities of the teacher model leveraging the full teacher distribution
- teacher모델이 student 모델을 가르친다고 개념을 생각하면 되는데, teacher가 I go home을 입력으로 받아 I의 입력이 결과값으로 go를 예측하는데 vocab size가 5일 때 [0.15 , 0.7, 0.03, 0.02, 0.1]으로 go의 확률을 예측한다면, student의 ground truch를 이 softmax 확률값으로 학습시켜주어 student가 teacher의 특징을 모사할 수 있도록 해준다.
- TinyBERT (Findings of EMNLP 2020)
- Two-stage learning framework, which performs Transformer distillation at both the pre-training and task-specific learning stages
- softmax로 나오는 결과들 말고도 의 파라미터들을 통해 나오는 각 layer의 output의 hidden state 벡터들도 유사해지도록 학습을 진행한다. teacher의 중간 layer에서 I의 output 벡터가 3차원으로 [0.1, 0.7, -1.1] 로 주어진다면, student의 중간 layer도 I의 output으로 이를 따라하도록 MSE loss를 사용하여 학습시킨다.
- student의 hidden state 벡터의 차원이 달라도 학습할 수도 있다. 이 때는 teacher의 벡터를 선형변환시켜 student의 벡터가 나오도록 Fully Connected Layer의 파라미터를 학습시켜 차원의 miss match를 해결한다.
Fusing Knowledge Graph into Language Model
Language 모델들은 주어진 지문에서의 지식은 활용할 수 있지만, 외부지식은 활용하지 못 하는 한계가 존재한다. 예를 들어 어떤 문서에 땅을 파다라는 문장이 나오고 문맥상 꽃을 심기 위해서 일때, 그리고 다시 한번 땅을 파다라는 문장이 나오고 문맥상 건물을 짓기위해서 일 때가 있다. 이 때 지문에 무엇으로 땅을 팠는지 나오지 않는다면 일반적으로 사람은 꽃을 심기 위해 땅을 파는 것은 작은 삽으로 팠다고 생각하고, 건물을 짓기위해 땅을 팔 때는 포크레인 같은 기구를 사용했다고 생각하지만 여러 Language model 들은 지문에 나와있지 않기 때문에 답을 할 수 없다. 즉, 사람처럼 갖고 있는 상식이나 외부지식들을 이용할 수 있도록 Knowledge Graph로 잘 정의하고 이를 model에 결합하여 사용할 수 있도록 한다.
- ERNIE: Enhanced Language Representation with Informative Entities (ACL 2019)
- Informative entities in a knowledge graph enhance language representation
- Information fusion layer takes the concatenation of the token embedding and entity embedding
- KagNET: Knowledge-Aware Graph Networks for Commonsense Reasoning(EMNLP 2019)
- A knowledge-aware reasoning framework for learning to answer commonsense
questions - For each pair of question and answer candidate, it retrieves a sub-graph from an external knowledge graph to capture relevant knowledge
- A knowledge-aware reasoning framework for learning to answer commonsense

Thank you for sharing this insightful breakdown of self-supervised pre-training models! Your detailed explanation of GPT-1 and BERT, along with their pre-training tasks like Masked Language Modeling and Next Sentence Prediction, provides a clear understanding of their architectures and applications. It's evident that these models have significantly advanced various NLP tasks through transfer learning.For professionals and teams aiming to deepen their knowledge and practical skills in AI, participating in an executive AI workshop can be highly beneficial. Such workshops offer hands-on experience and strategic insights into AI implementation, aligning with the trends and technologies you've discussed.