Object detection
Object detection
What is object detection?
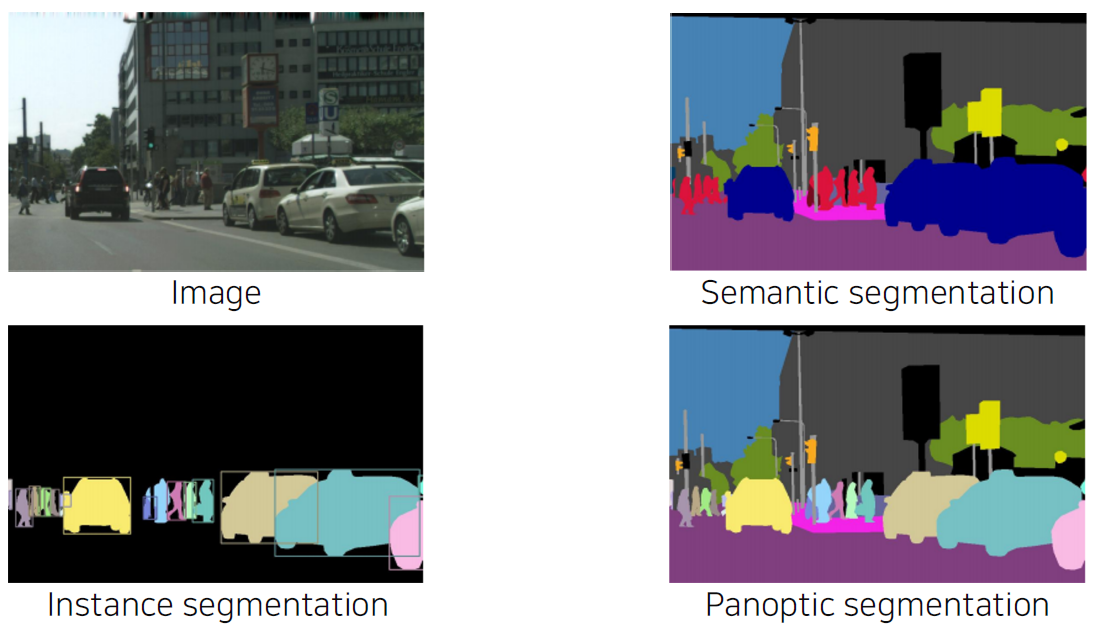
Fundamental image recognition tasks
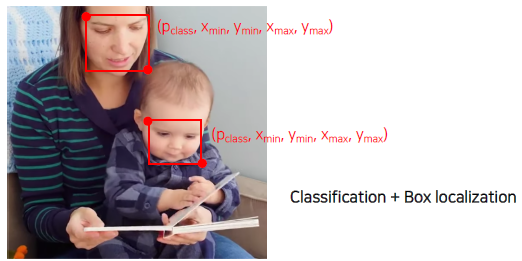
What are the applications of object detection?
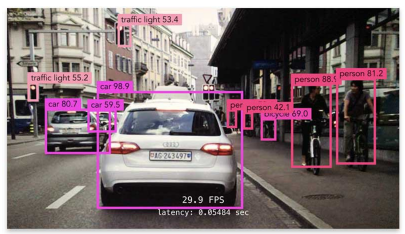
Autonomous driving
Optical Character Recognition (OCR)

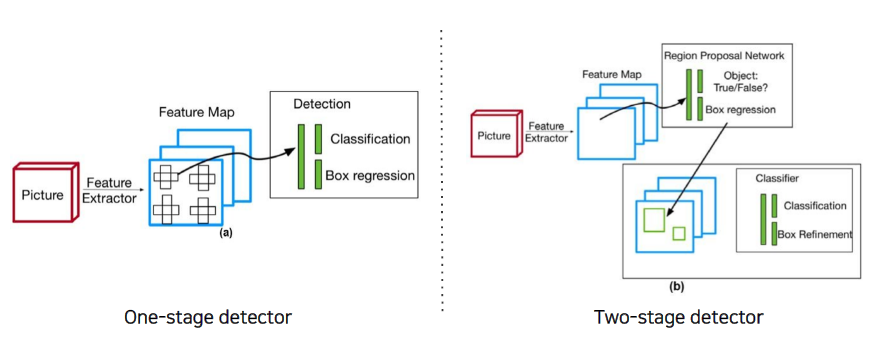
Two-stage detector
Traditional methods hand-crafted techniques
Gradient-based detector (e.g., HOG)
HOG = Histogram of Oriented Gradients, SVM = Support Vector Machine

Selective search
-
Over-segmentation.
영상을 먼저 비슷한 색끼리 잘게 분할한다. -
Iteratively merging similar regions.
잘게 분할된 영역들을 비슷한 영역(색, gradient의 특징 및 분포, ...)들끼리 합친다. -
Extracting candidate boxes from all remaining segmentations.

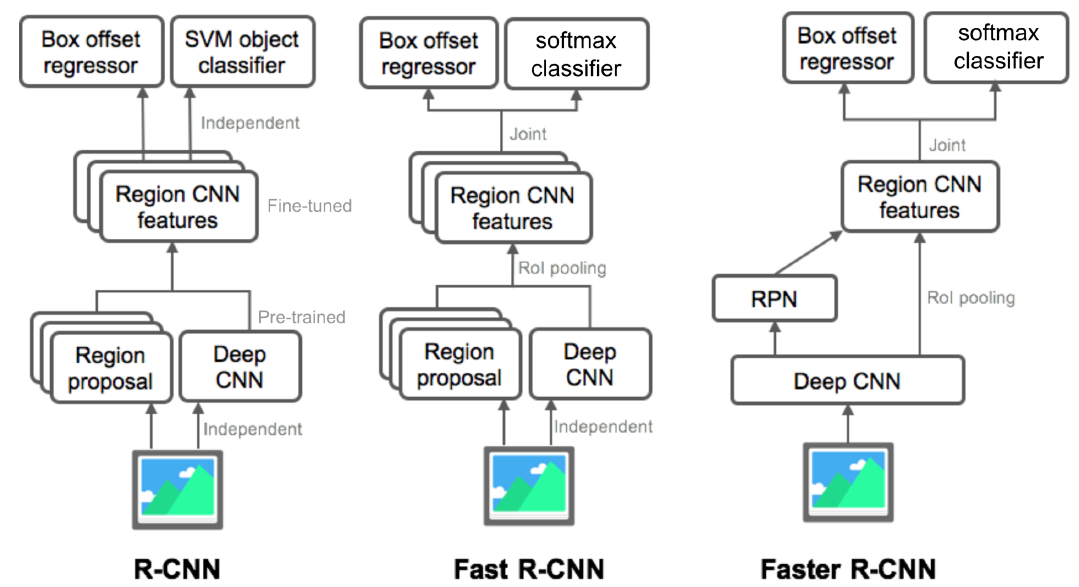
R-CNN
Directly leverage image classification networks for object detection.
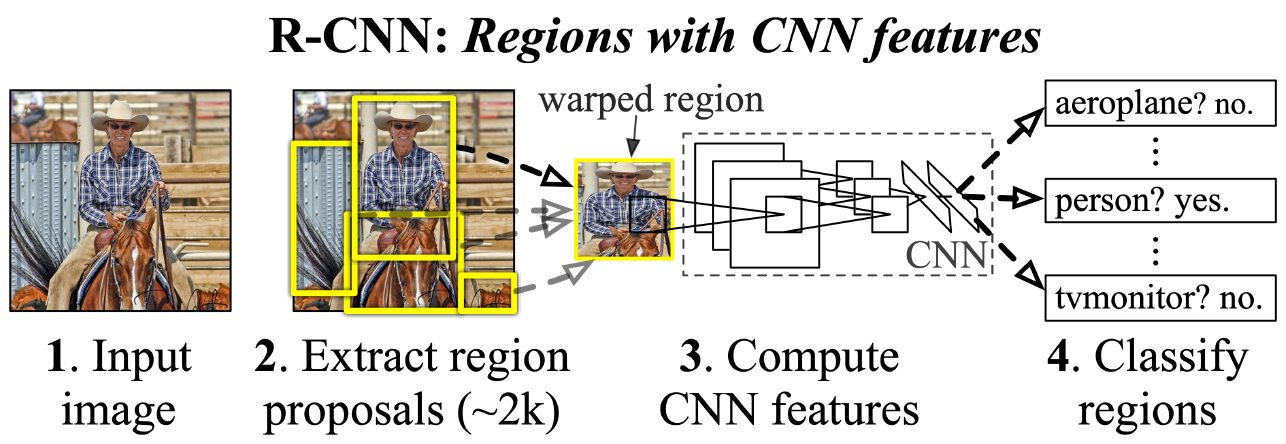
Input image가 들어오면 Selective search로 region proposal을 2,000개 밑으로 추출한다. 그리고 Fully Convolution하지 않기 때문에 입력사이즈를 맞추려고 warping 해주는 단계를 거쳐 CNN 층에 넣어주고 마지막에 SVM을 이용하여 classify 한다. 이 때 각 region proposal 하나하나 마다 모델에 넣어서 processing 하기 때문에 속도가 굉장히 느리다. 그리고 selective search 같은 별도의 hand design 된 알고리즘을 사용해서 학습을 통한 성능향상의 한계가 존재한다.
Fast R-CNN
Recycle a pre-computed feature for multiple object detection.
- Conv. feature map from the original image.
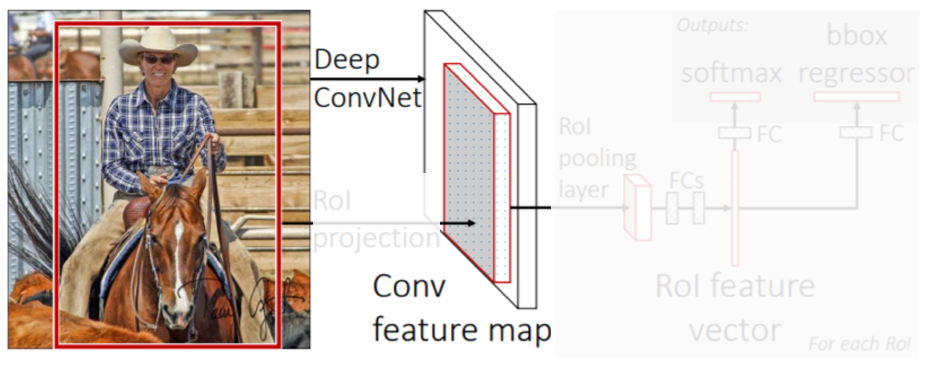
Fully Convolution network는 입력 사이즈에 상관없이 feature map을 추출할 수 있다. 따라서 warping하는 단계가 필요없다.
- RoI feature extraction from the feature map through RoI pooling.
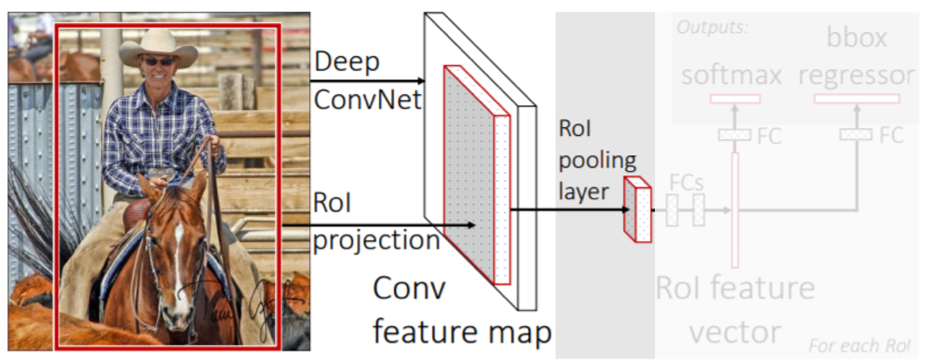
한번 뽑아놓은 feature를 여러번 재활용 하기 위해 제안된 layer. RoI(Region of Interest)는 region proposal이 제시한 물체의 후보 위치들을 의미한다. RoI pooling layer에서 fixed demension을 갖도록 일정 size로 re-sampling한다.
- Class and box prediction for each RoI.
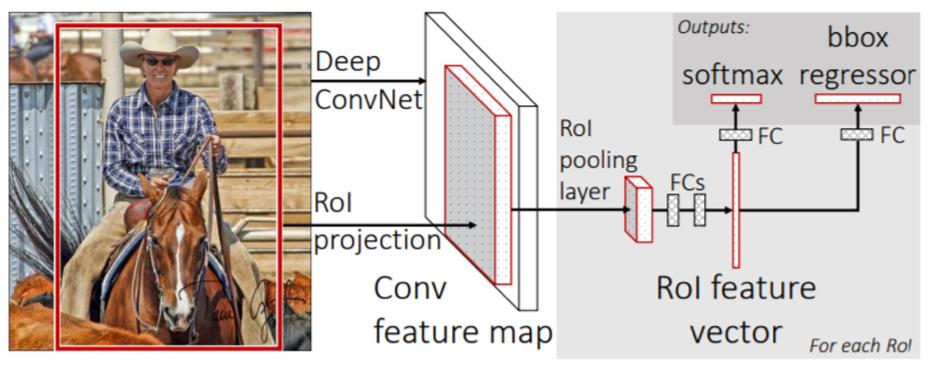
class를 확인하기 위한 softmax와 더 정밀한 bounding box 위치를 추정하기 위한 bounding regression을 수행한다.
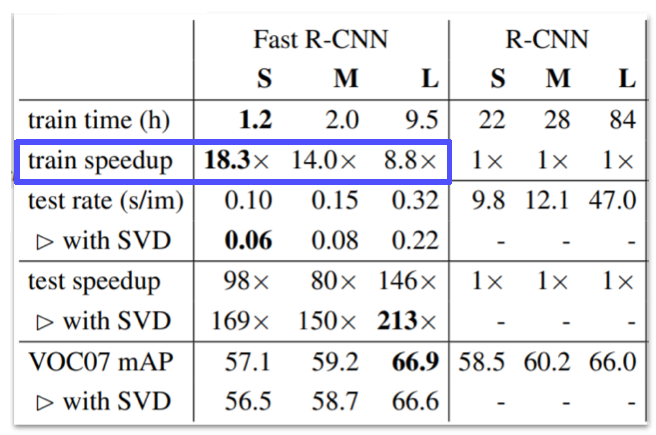
R-CNN보다 속도면에서 엄청난 향상을 이끌어냈다. 그러나 region proposal은 여전히 selective search 같은 알고리즘을 사용했기에 데이터만으로 성능 향상을 높이는데에는 한계가 있다.
Faster R-CNN
End-to-end object detection by neural region proposal.
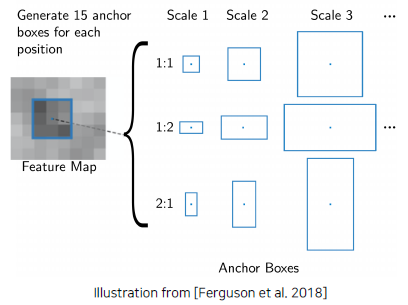
Anchor boxes
- A set of pre-defined bounding boxes
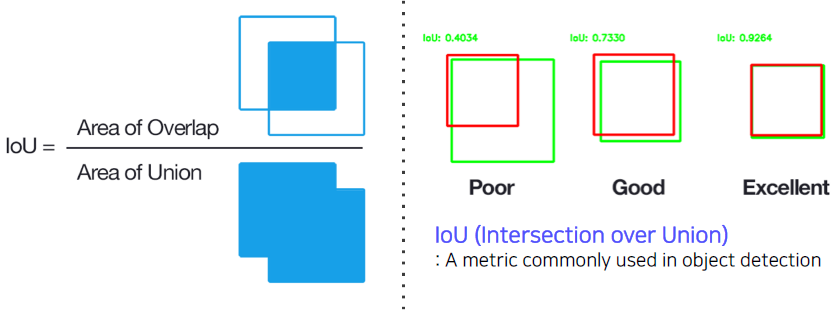
- IoU with GT > 0.7 ⇒ positive sample
- IoU with GT < 0.3 ⇒ negative sample

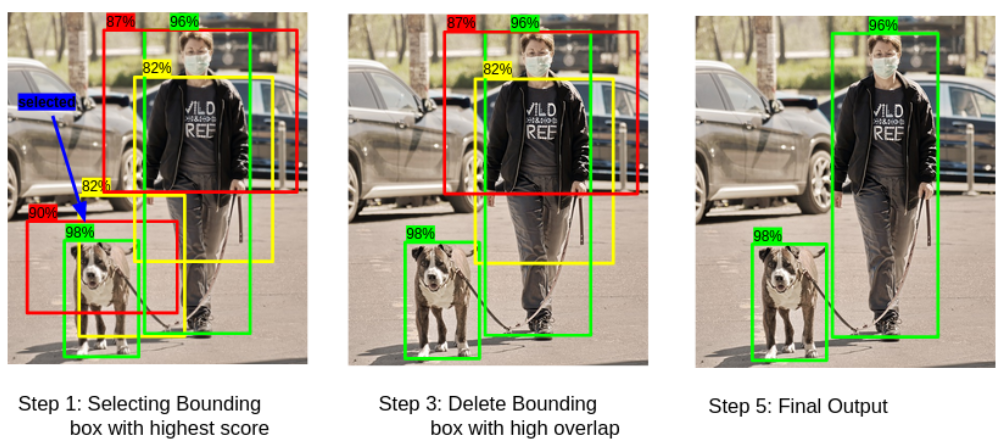
Non-Maximum Suppression (NMS)
Step 1: Select the box with the highest objectiveness score
Step 2: Compare IoU of this box with other boxes
Step 3: Remove the bounding boxes with IoU ≥ 50%
Step 4: Move to the next highest objectiveness score
Step 5: Repeat steps 2-4
Summary of the R-CNN family
Single-stage detector
Comparison with two-stage detectors
One-stage vs two-stage
No explicit RoI pooling
You only look once (YOLO)
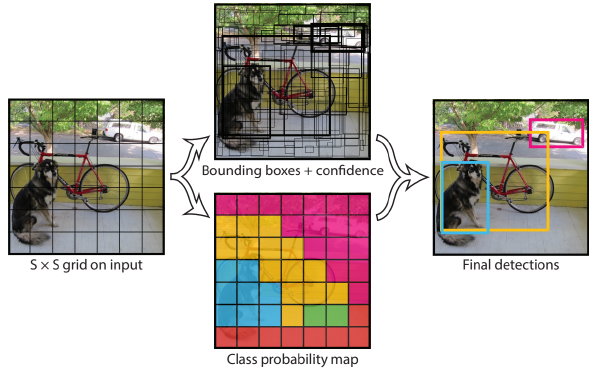
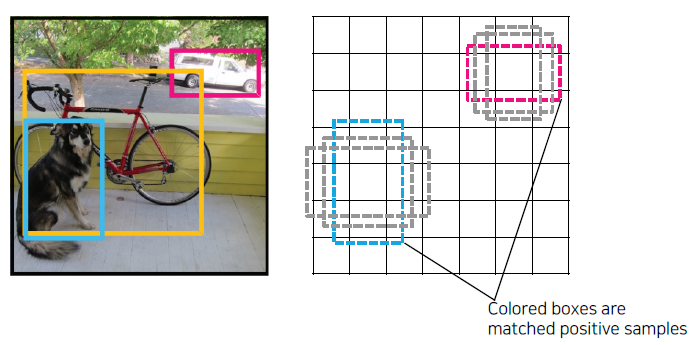
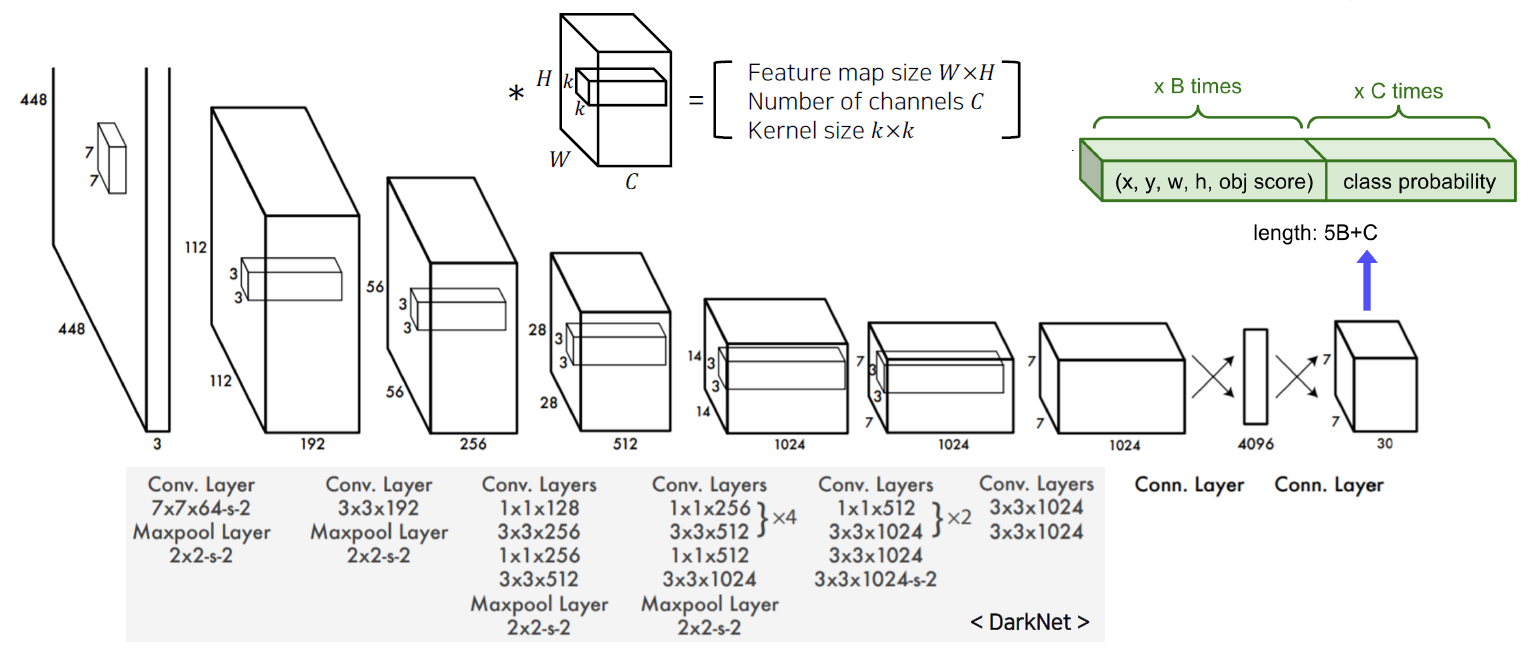
간단한 구조를 갖기 때문에 연산 속도가 빠르다.
마지막 30 채널은 위 모델에서는 bounding box anchor를 2개를 사용하였고 (5x2 = 10), 20개의 class 중에 분류를 진행했기 때문이다. 따라서 10+20 = 30 채널이 output으로 나온다.
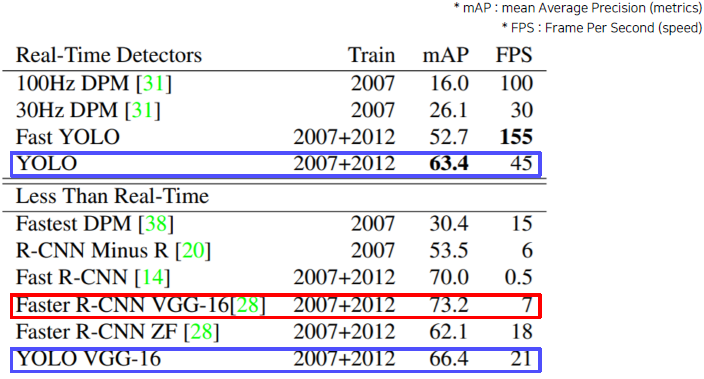
같은 backbone network를 사용하는 경우 Faster R-CNN보다는 성능이 덜 나오지만 real-Time에서도 좋은 성능을 보여준다.
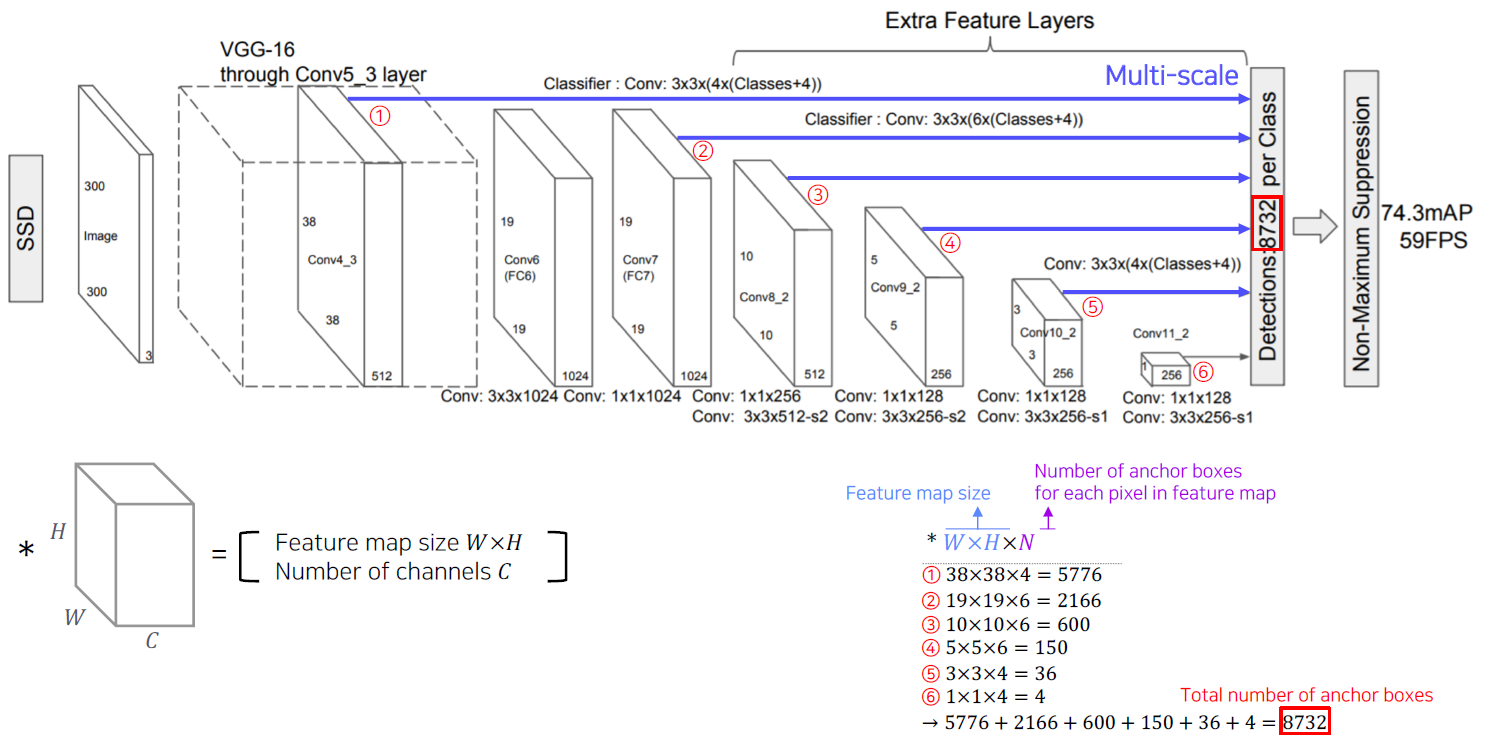
Single Shot MultiBox Detector (SSD)
YOLO는 맨 마지막 Layer에서만 한번 prediction을 하기 때문에 localization 정확도가 떨어지는 결과를 보여준다. 이를 보완하기 위에 SSD가 고안됐다.
SSD는 multi-scale object들을 더 잘 처리하기 위해서 중간 feature map을 각 해상도에 적절한 bounding box들을 출력할 수 있도록 구조를 만들었다.
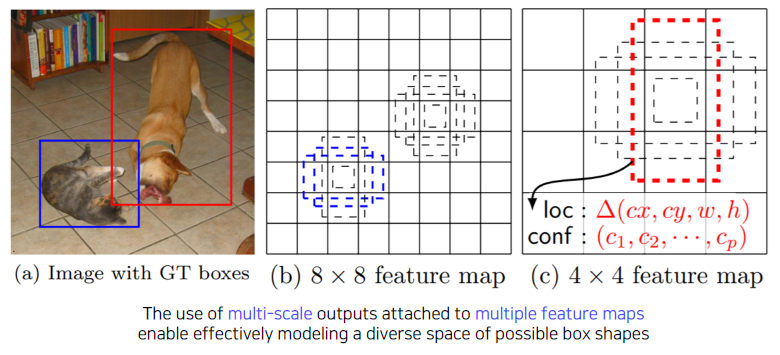
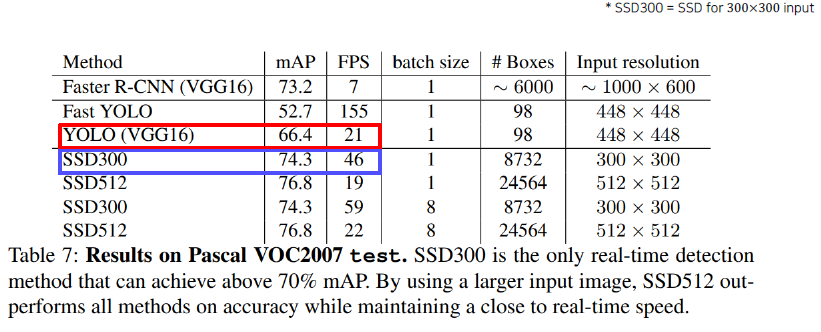
Two-stage detector vs one-stage detector
Class imbalance problem
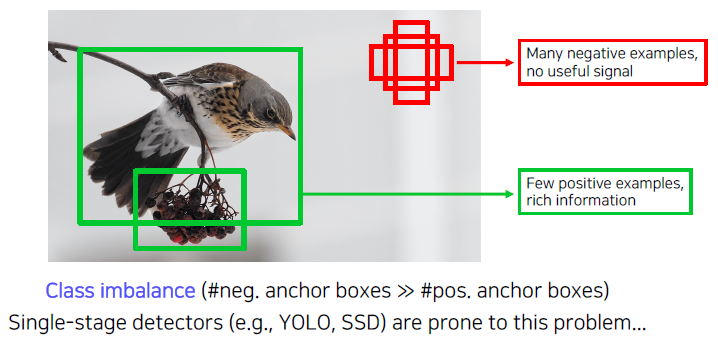
대부분의 이미지에서는 detecting 하려는 부분보다 background 영역(아무런 정보도 없는 영역)이 훨씬 많은 부분을 차지한다.
Focal loss
- Improved cross entropy loss
- Deal with class imbalance
- Over-weights hard or misclassified examples
- Down-weights easy examples
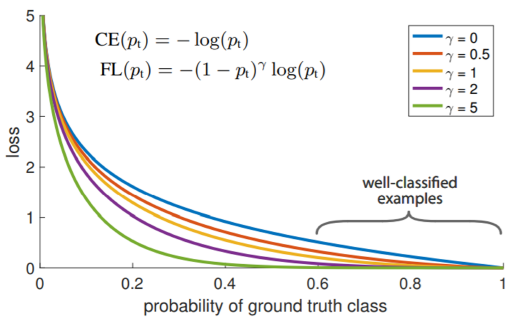
정답에 가까우면 덜 sharp 하게, 정답이 아니면 sharp 하게 gradient를 전달한다. 여기서 주의해야할 점은 loss값이 절대값으로 정해져서 original cross entropy가 더 높은 loss를 갖는 것 아니냐라고 생각할 수 있는 것이다. 하지만 학습에 사용되는 것은 gradient 즉, 기울기 값이기에 감마 값이 높을수록 높은 기울기를 가진다는 것이다.
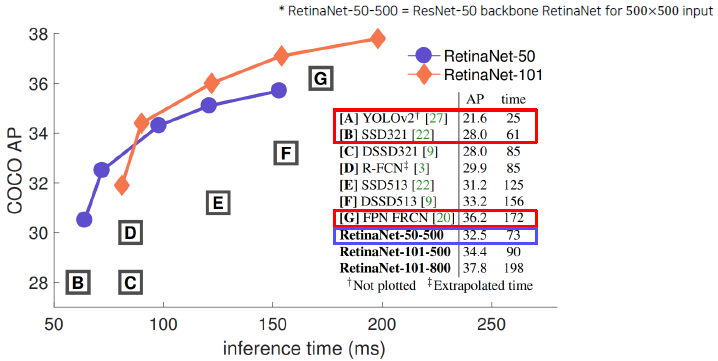
RetinaNet
RetinaNet is a one-stage network
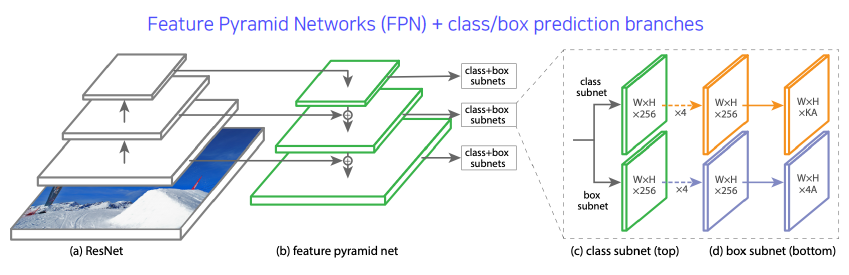
Unet과 비슷한 concept으로 low level과 high level의 특징을 둘 다 잘 활용한다. 다만 concatenation이 아니고 합해진다.
Detection with Transformer
DETR
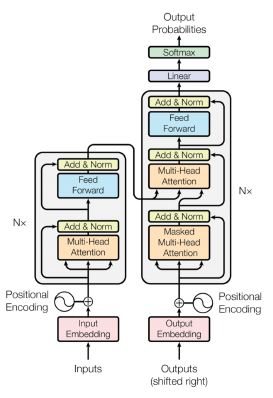
Transformer
Transformer has shown a great success in NLP
Why not extending Transformer to computer vision tasks!
- ViT (Vision Transformer) by Google
- DeiT (Data-efficient image Transformer) by Facebook
- DETR (DEtection TRansformer) by Facebook
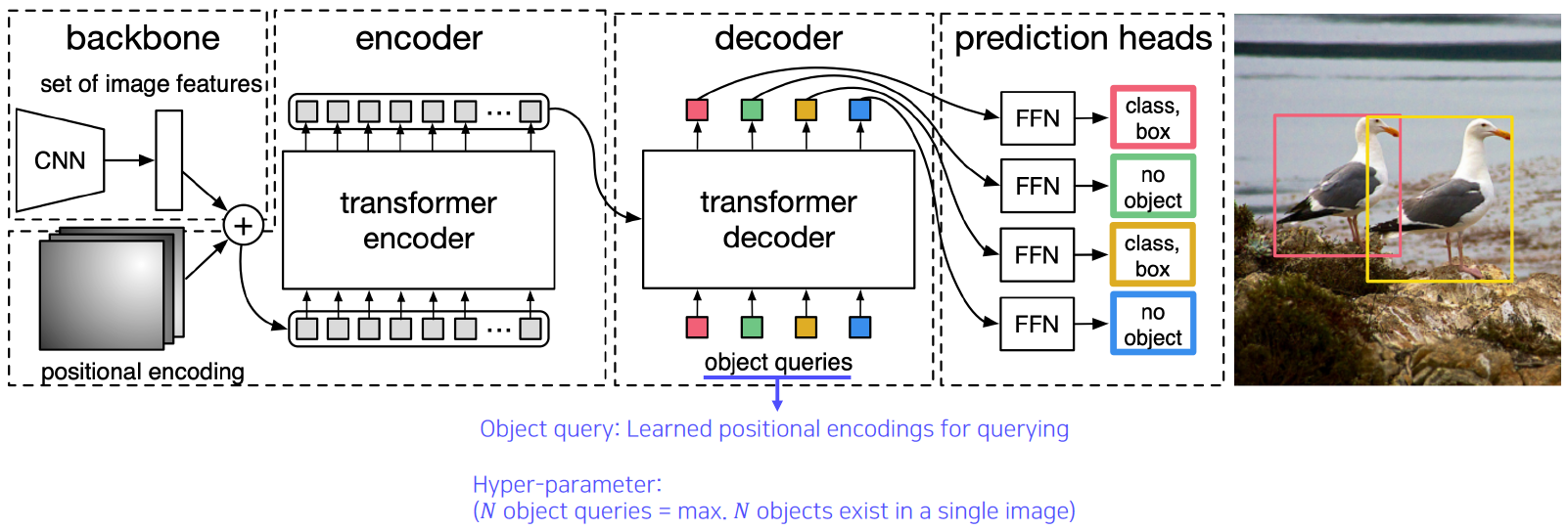
이 때 사용되는 object query도 학습된 encoding 값이다.
Further reading
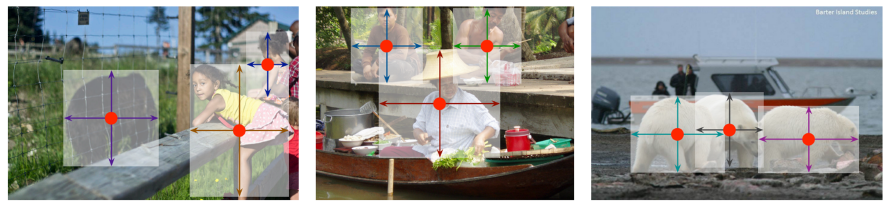
Detecting objects as points
• Bounding box can be represented by other ways (left-top, right-bottom, centroid & size)
• Idea: Let’s detect objects using corresponding points!
CNN Visualization
Visualizing CNN
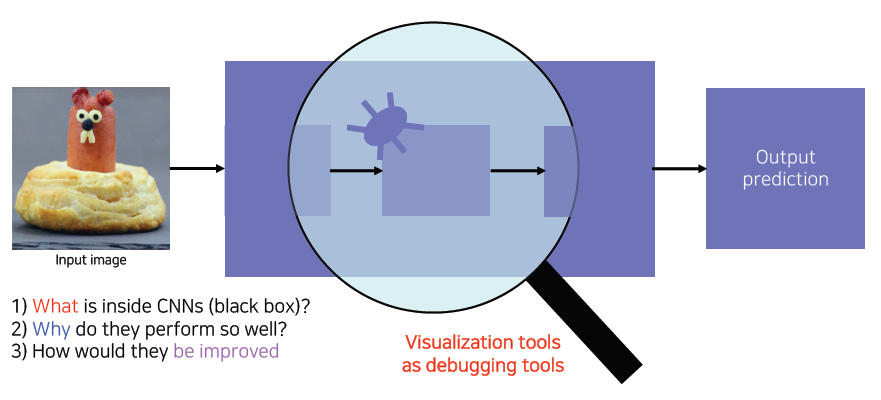
What is CNN visualization?
CNN is a black box
ZFNet example - the winner of ImageNet Challenge 2013
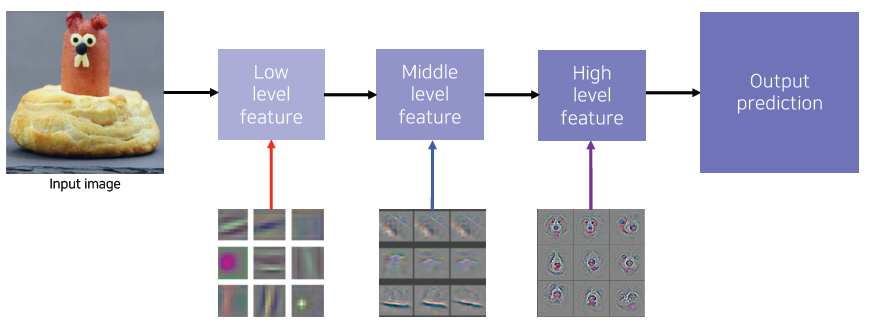
낮은층에서는 방향성이 있는 선을 찾는 filter, 동그란 block을 찾는 filter들이 분포되어있는 것이 보이고, 높은 계층에서는 high level의 의미가 있는 어떤 표현을 학습했다는 것을 확인할 수 있다. ZFNet은 이런 결과를 토대로 눈으로 직접 보면서 CNN을 tuning 했다.
Vanilla example: filter visualization
Filter weight visualization
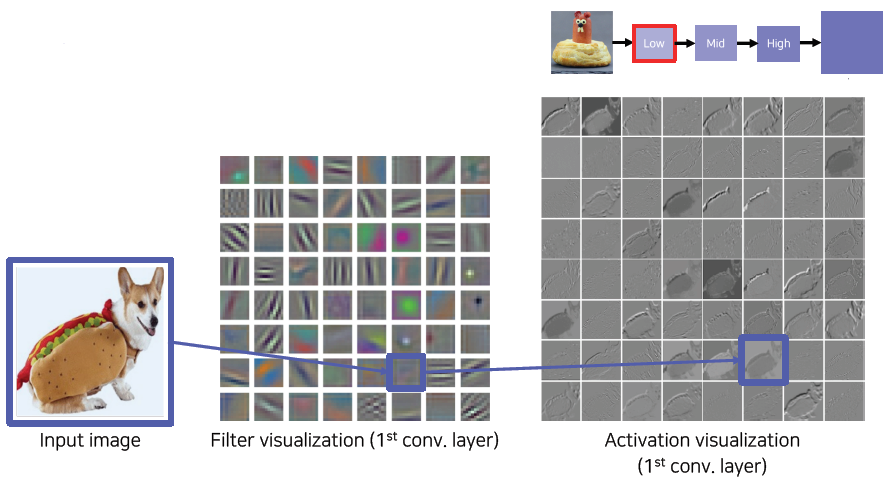
각 필터마다 처리 결과가 한 채널로 나오기 때문에 흑백으로 표현됐다.
high layer로 갈수록 채널수가 늘어나서 사람이 직관적으로 이해하기 힘들다. (첫 layer의 채널 수는 3이다)
How to visualize neural network
Types of neural network visualization
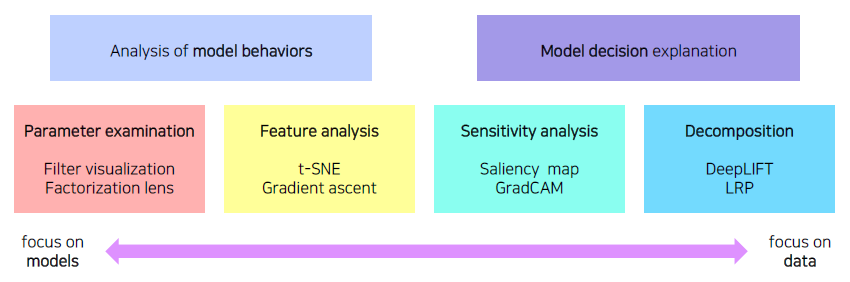
Analysis of model behaviors
Embedding feature analysis 1
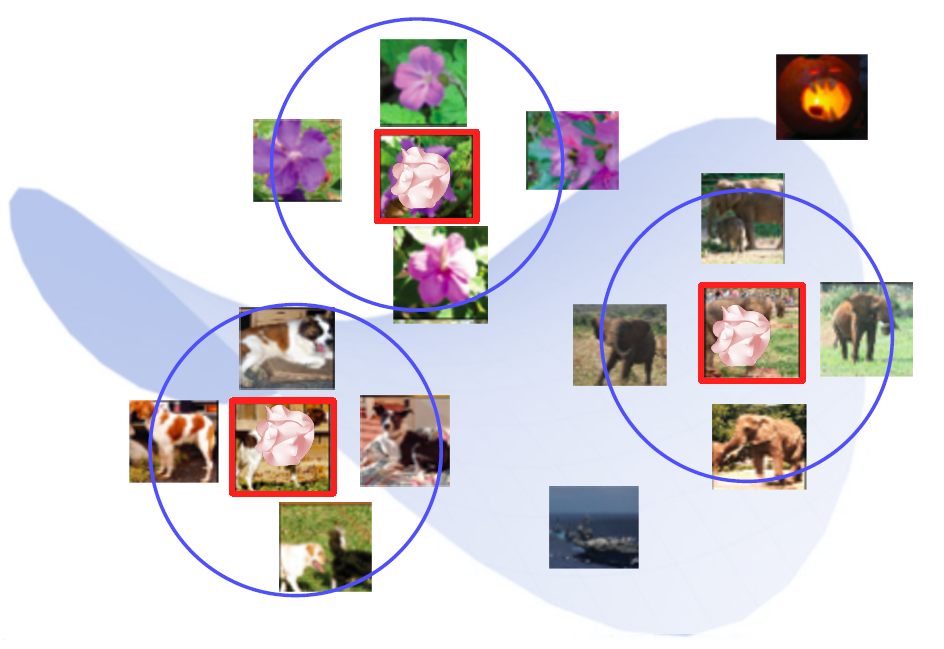
Nearest neighbors (NN) in a feature space - Example

아래 그림은 고차원 공간에 있는 각각의 feature vector를 표현한다.
미리 pre-trained 된 network를 준비하고 마지막 FC layer를 잘라내고, feature를 추출한다.
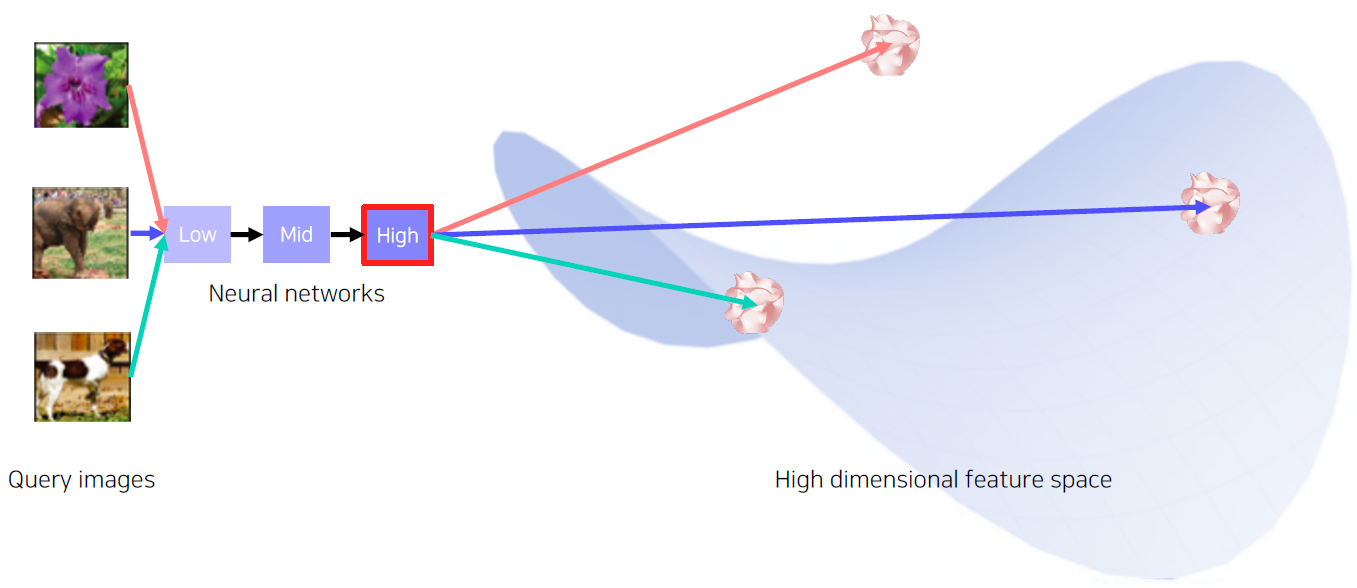
Search the nearest neighbors of features from DB
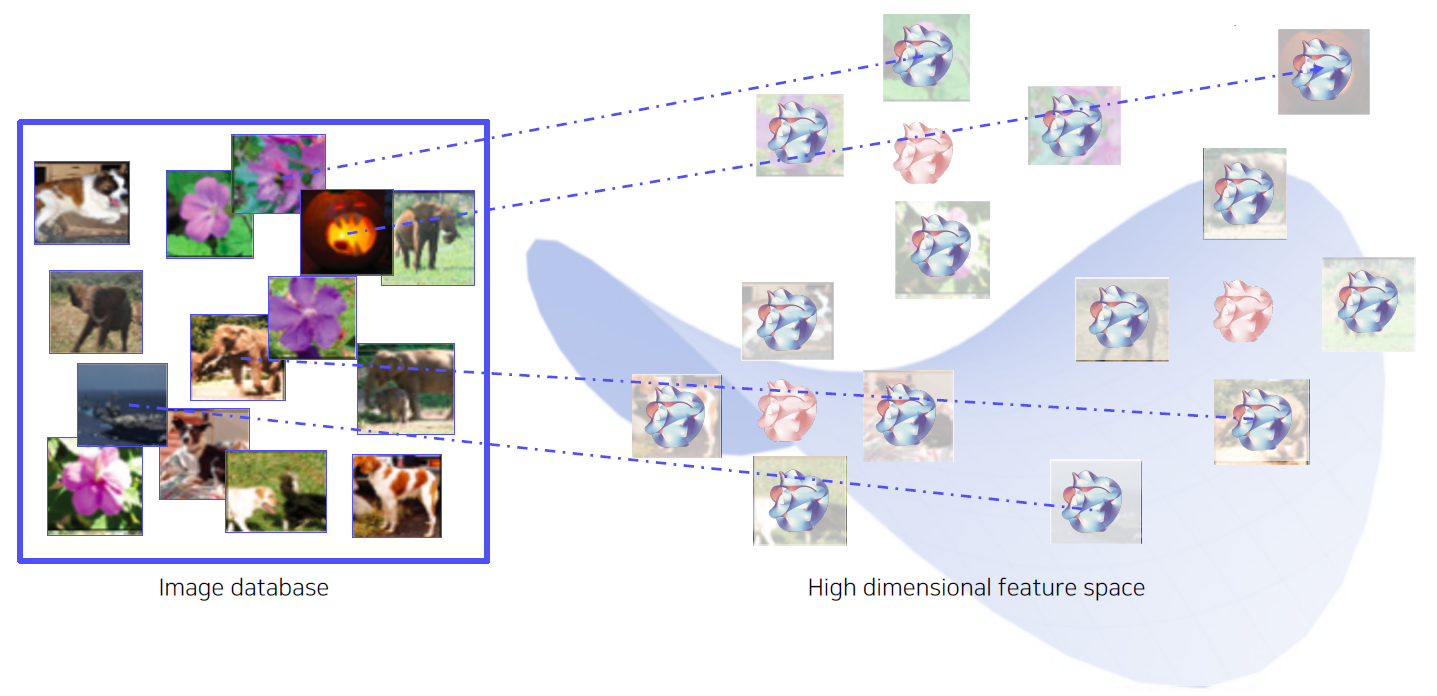
빨간색 feature vector들은 Query image들의 feature vector를 공간 상에 표시한 것이다.
Embedding feature analysis 2
1의 방법에서 처럼 검색된 예제들을 통해서 분석하는 방법은 전체적인 그림을 파악하기 어려운 단점이 있다.
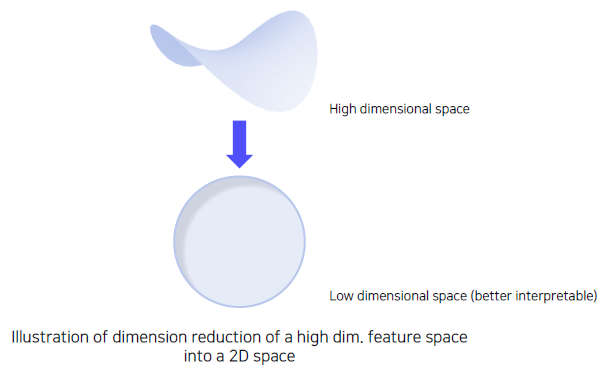
우리가 상상할 수 있는 공간으로 고차원 space에 있는 vector들의 분포를 차원축소를 통하여 눈으로 쉽게 확인할 수 있다.
Dimensionality reduction
t-distributed stochastic neighbor embedding (t-SNE)
t-SNE를 이용한 차원 축소

위 그림을 보면 3, 5, 8이 비슷한 space에 모여있는 것이 보이는데 이는 실제로 3, 5, 8 사이에 밑쪽 부분이 동그란 특징이 존재하기 때문이라고 해석할 수 있다.
Activation investigation 1
Layer activation - Behaviors of mid- to high-level hidden units

위 그림들은 AlexNet의 conv layer의 채널 중 하나를 선택하여 activation을 적당한 값으로 threshold 해주어 mask를 만들고 영상에 덮어씌운 그림이다.
conv5 layer의 138 channel은 얼굴을 찾고, conv5의 53 channel은 계단을 찾는 역할을 하는 것이 보인다.
이 처럼 activation을 분석하여 각 layer의 hidden node들의 역할을 확인할 수 있다. 이를 통해 convolution network는 중간 중간의 hidden unit들의 역할이 다층으로 쌓여서 여기서 얻어진 특징들의 조합으로 물체를 인식한다고 생각할 수 있다.
Activation investigation 2
Maximally activating patches - Example

위 그림은 activation 중 최대값에 해당하는 patch들을 뽑아낸 그림이다.
맨 위쪽에 해당하는 hidden node는 무언가 동그란 강아지 코 같은 모양을 인식하는 역할을 하는 것이 보인다.
Patch acquisition
1) Pick a channel in a certain layer
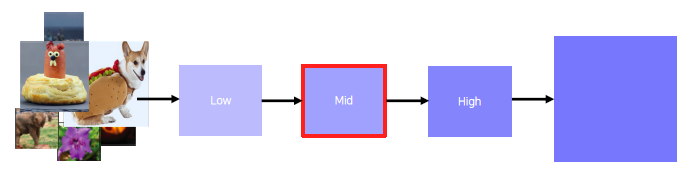
2) Feed a chunk of images and record each activation value (of the chosen channel)
3) Crop image patches around maximum activation values
activation 이 가장 높게 나타난 부분을 입력 도메인의 receptive field에서 계산하여 해당 patch를 얻는다.

Activation investigation 3
Class visualization - Example

위 그림은 네트워크가 기억하고 있는 이미지가 무엇인지 분석한 그림이다. 새 class는 새 비슷한 형태를 출력하는 것이 보이고, dog class는 강아지 모양의 형상을 갖고 있는 것이 보인다. 그리고 새들의 형상에서는 나뭇가지 같은 형상이 보이는 것으로 보이고, 강아지의 형상에서는 사람과 같이 있는 것이 보인다. 이를 통해, 학습된 데이터들이 어떤 방향으로 편향되었는지도 보인다.
Gradient ascent
- Generate a synthetic image that triggers maximal class activation.
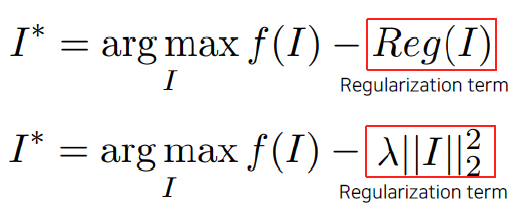
어떤 영상 I를 입력으로 주었을 때 CNN 모델 f를 거쳐서 출력된 하나의 class score(예를 들면 강아지 class에 대한 score)를 입력 이미지 I를 변경하면서 maximize하는 식이다.
랜덤한 영상을 입력으로 넣어주면 당연히 class score는 낮게 나올 수 밖에 없다. 이 때 I를 back propagation을 통해 점수가 높게 나오도록 변경하는 것이다.
argmax 최적화 과정을 거쳐서 나온 출력 I가 너무 큰 값이 나오면 사람이 해석할 수 없는 이미지가 될 수 있다. (비록 모델은 그 이미지를 강아지로 인식하겠지만) 이를 막고 사람이 이해할 수 있는 영상을 만드려고 Regularization term을 추가한다. 이 식은 찾는 영상 각 pixel의 L2 norm의 sum을 나타낸다. 이 때 작아지는 정도를 를 통해 조절한다.
평소 신경망이 학습하는 방식은 loss를 최소화하는 방향으로 최적화하지만, 여기서는 반대로 최대화를 하기 때문에 Gradient ascent라고 부른다.
Image synthesis
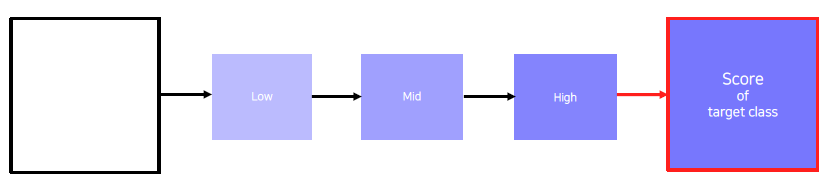
1) Get a prediction score (of the target class) of a dummy image (blank or random initial)
2) Backpropagte the gradient maximizing the target class score w.r.t. the input image
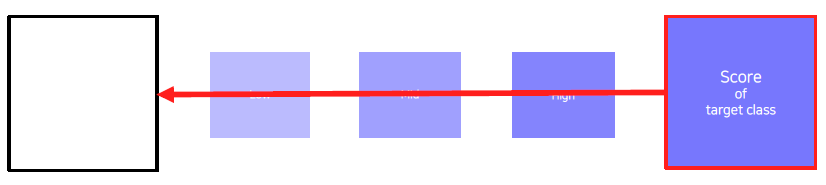
3) Update the current image

3) 에서 얻은 I를 다시 1번의 입력값으로 넣고 반복한다.
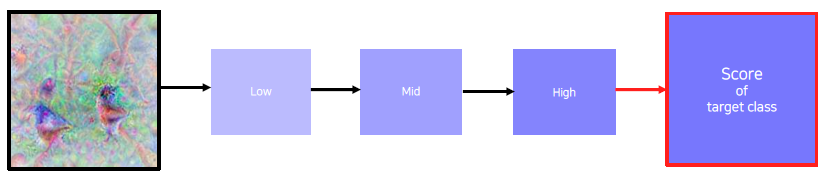
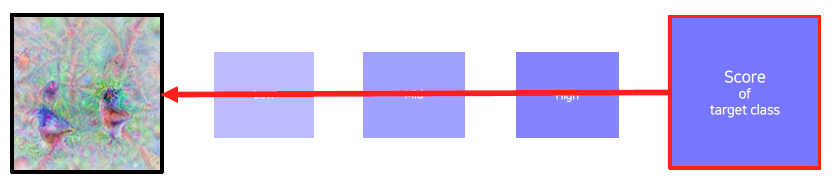

초기 입력값이 그냥 random noise 이미지일 수도 있고, 회색 이미지일 수도 있는데 이런 초기값에 따라 결과가 바뀔 수 있다. 왜냐하면 초기값을 조금씩 변경하면서 점수가 최대화되는 값으로 I가 업데이트 되기 때문이다. 그래서 이런 과정들을 초기값들을 다르게 설정하여 반복하여 한 class에 대한 여러번 반복을 하고, 얻어진 다양한 패턴들을 분석한다.
Model decision explanation
Saliency test 1
Occlusion map
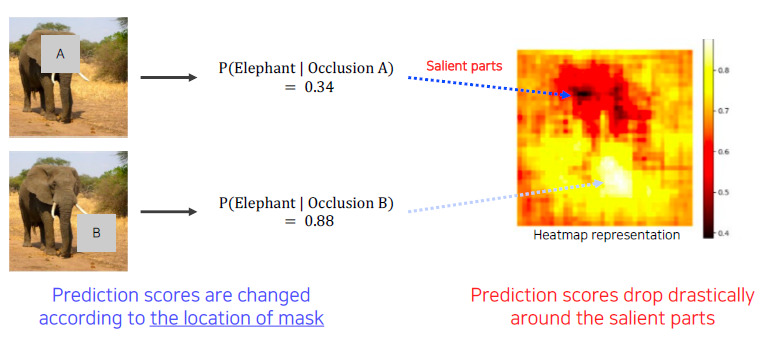
A라는 패치를 이미지의 여러 부분에 놓으면서 그 때의 score 값들을 얻는다. 이런 과정을 patch를 모든 부분에서 옮겨가며 score들을 얻고, 이를 heatmap으로 표시하면 오른쪽 그림과 같이 된다. 여기서 보면 검은색 부분은 점수가 낮게 나온 부분으로 이에 해당하는 영역이 patch로 가려졌을 때, 점수가 낮다는 뜻이다. (물체 인식에 민감한 부분이다.) 즉, 가려진 부분은 신경망이 코끼리를 인식하는데 큰 역할을 한다는 뜻이다.
Saliency test 2
via Backpropagation - Example

Derivatives of a class score w.r.t. input domain
1) Get a class score of the target source image.
2) Backpropagate the gradient of the class score w.r.t. input domain
3) Visualize the obtained gradient magnitude map (optionally, can be accumulated)
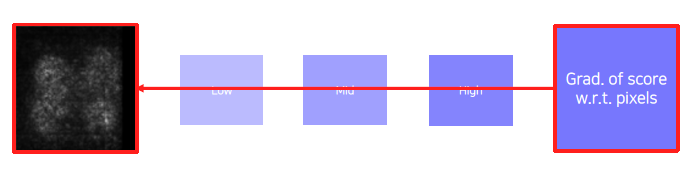
위 방법은 어느 부분을 많이 변경해야 score가 바뀌는지 알려주는 그 gradient의 크기 자체가 중요하다. (그 바뀌어야 하는 부분이 굉장히 민감한 부분이다라고 생각할 수 있다.) 그래서 back propagation 된 gradient를 제곱이나 절대값을 취해주고 그 영역을 표시해준다.
이를 한번만 할 수도 있고, 여러번 반복을 할 수도 있다.
방법이 class visualization과 비슷한데, 차이점은 class visualization은 random한 이미지를 신경망이 잘 인식하도록 변경하는 것이고 위 방식은 특정 이미지를 주고, 모델이 이 이미지를 어떻게 해석하는지를 보는것이다.
Backpropagate features
Rectified unit (backward pass)
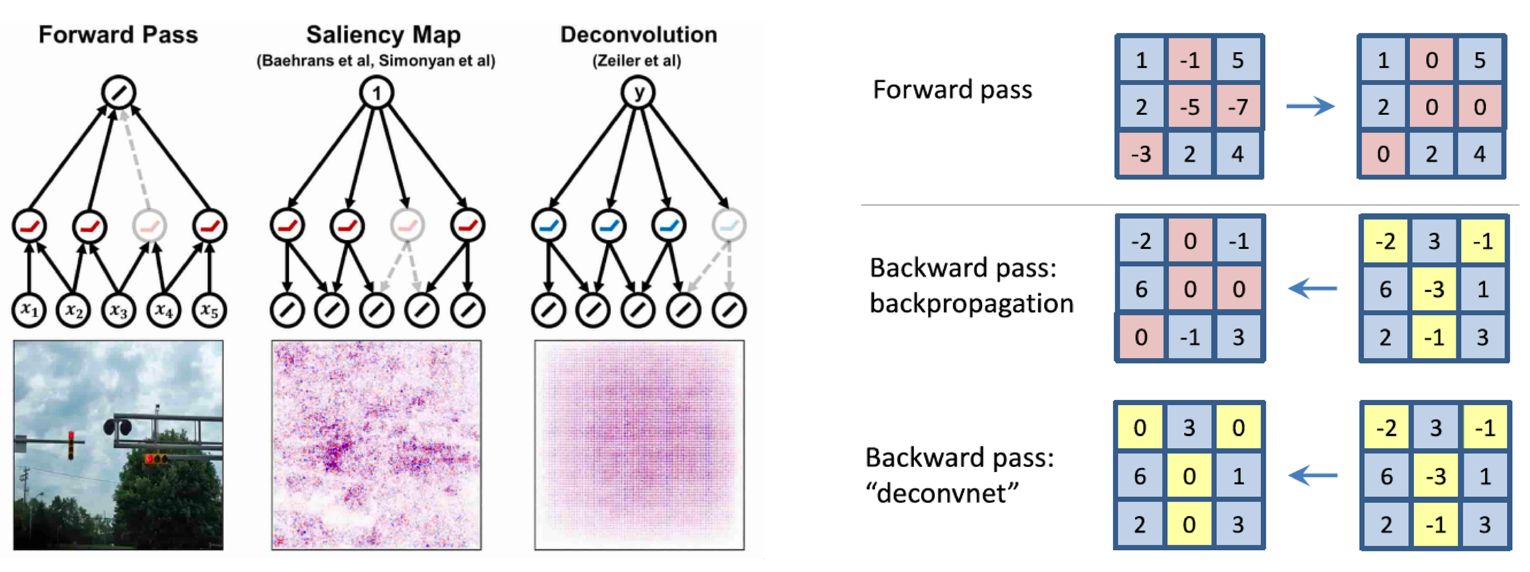
기존 ReLU의 back propagation은 ReLU를 통과해서 0이 된 부분은 그대로 0으로 masking을 시켜주고 나머지를 업데이트 해주는 방식이었다.
deconvnet에서 적용한 방식은 back propagation 되는 gradient들의 값 중에서 음수인 부분을 0으로 masking 해준다. 즉, backward가 될 때의 gradient에다가 ReLU를 적용시켜준 것이다.
그런데 이 방법은 사실 수학적으로 back propagation을 위한 방법도 아니고, gradient가 아니고 제 3의 어떤 것이다.

Guided backpropagation
이 두가지를 모두 합친 방법도 존재한다.
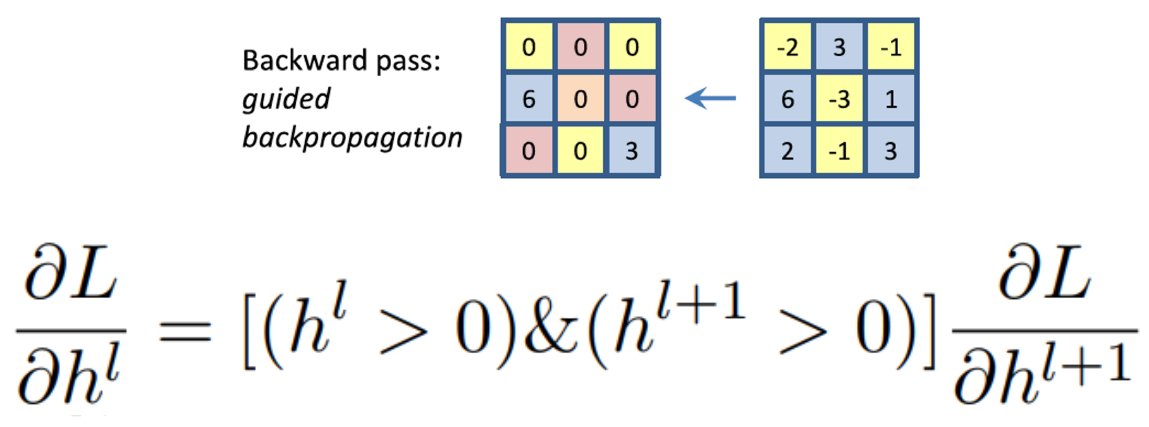
Comparison

수학적으로는 아무 의미가 없지만 위 그림을 봐보면 Guided backpropagation을 통해 나온 이미지는 사람이 해석하는 방식과 상당히 유사한 것을 볼 수 있다. 이 모델은 주로 귀쪽 부분과, 눈, 얼굴 쪽을 보고 해석하였다.
두 mask를 모두 사용한 것은 forward를 할 때도 결과에 영향을 미친 양수들을 참조를 하고, backward를 할 때도 gradient를 통해서 더 강화하는 activation들을 고른것이다. 즉, 양방향에서 class 결정에 모두 도움이 되는 부분만 추출한다.
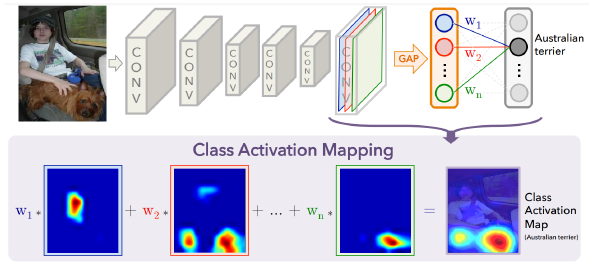
Class activation mapping
Class activation mapping (CAM) - Example
Visualize which part of image contributes to the final decision.

Global average pooling (GAP) layer instead of the FC layer.
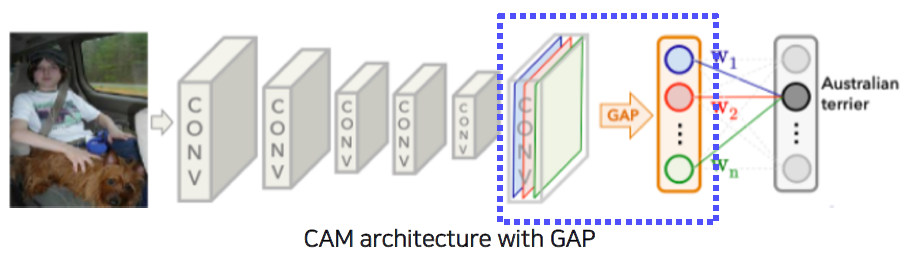
convolution에서 나온 feature를 GAP layer를 통과시키고 한 개의 Fully Connected layer만 통과시킨다.
이 구조를 사용해서 신경망을 다시 학습시킨다.
Derivation of CAM: Changing the order of the operations.

여기서 나온 CAM 부분을 시각화한다.
By visualizing CAM, we can interpret why the network classified the input to that class.
GAP layer enables localization without supervision.
어떤 물체의 위치정보를 주지 않고 단순한 이미지 인식만 학습했는데도 위치를 파악한다는 것이 확인된다. (제 3의 task까지 기능한다.)
object detection과 같이 정교한 task를 좀 더 rough한 영상인식 task 같은 것으로 데이터를 사용해서 간접 해결하는 것을 weakly supervised learning 이라고 부른다.
Requires a modification of the network architecture and re-training.
ResNet and GoogLeNet already have the GAP layer.
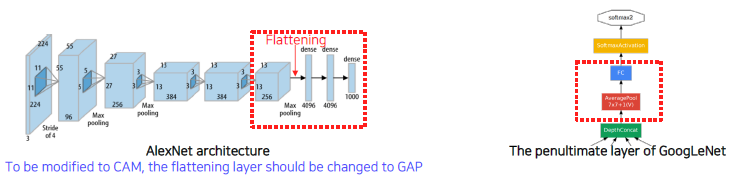
모델의 구조를 바꾸고 재학습 하기 때문에 tunning된 parameter들이 안 맞을 수 있어 성능이 떨어질 수 있다. 그러나 ResNet과 GoogLeNet은 이미 이 구조를 갖고 있어 CAM을 활용하기 좋다. 즉, 모델을 수정하지 않고도 바로 추출할 수 있다.
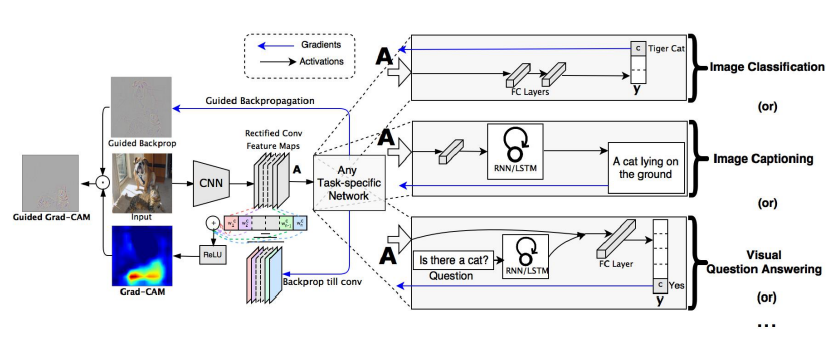
Grad-CAM - Example

Get the CAM result without modifying and re-training the original network.
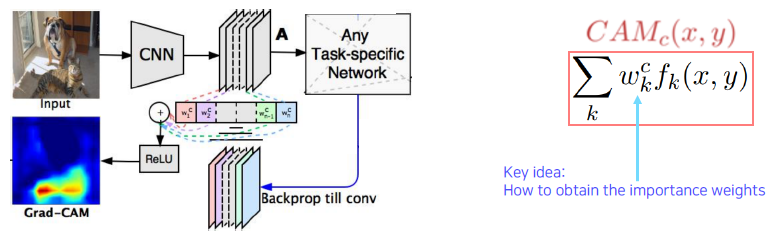
Measure magnitudes of gradients as neuron importance weights.
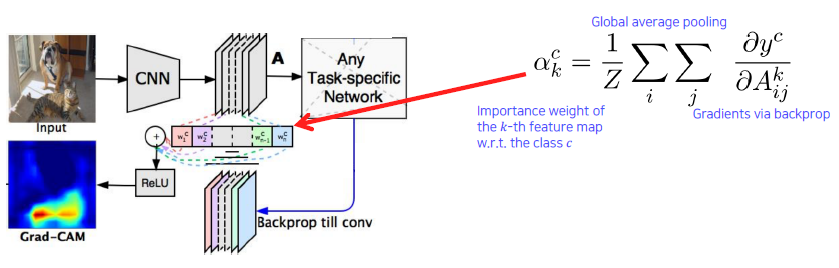
With ReLU, we focus on the positive effect only.
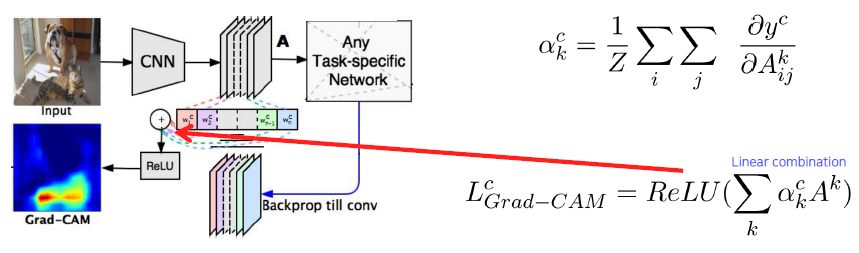
Grad-CAM works with any task head.
SCOUTER - Example

GAN dissection
- Spontaneously emerging interpretable representation during training.
- Not only for analysis but also for manipulation applications.

