Training & Inference
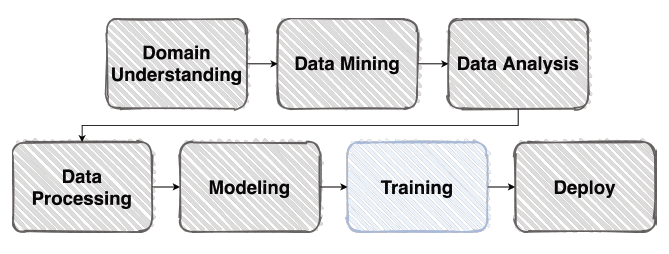
학습 프로세스에 필요한 요소를 크게 아래와 같이 나눌 수 있습니다.

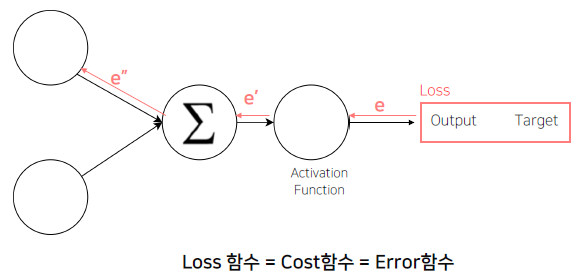
Loss
(오차) 역전파
Error Backpropagation
Loss도 사실은 nn.Module Family이라서 nn 패키지에서 찾을 수 있다.
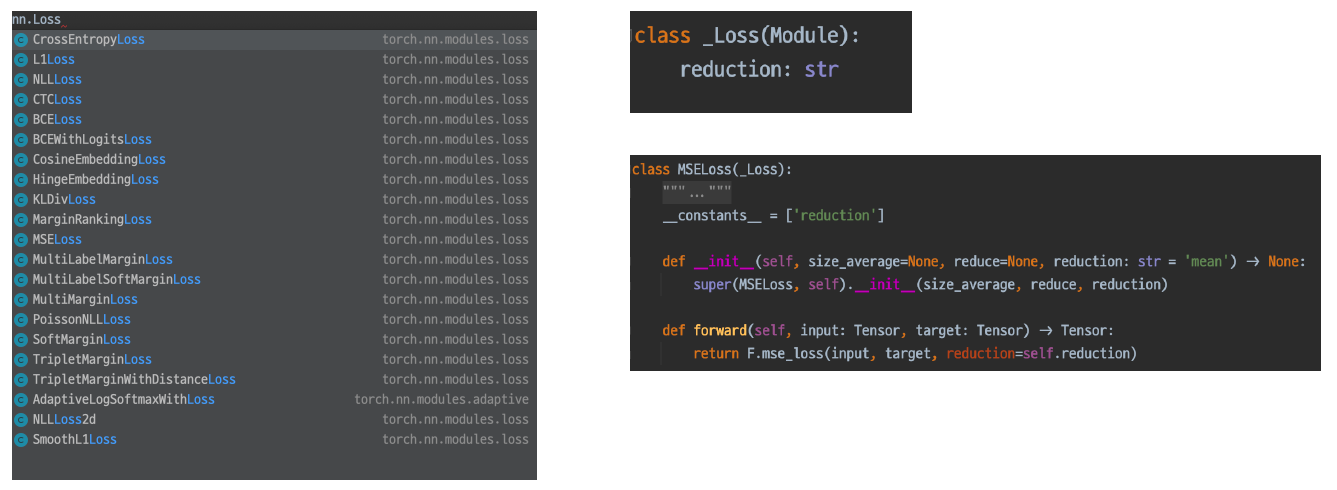
Loss에도 forward 함수가 정의되어 있는 것이 확인 된다.
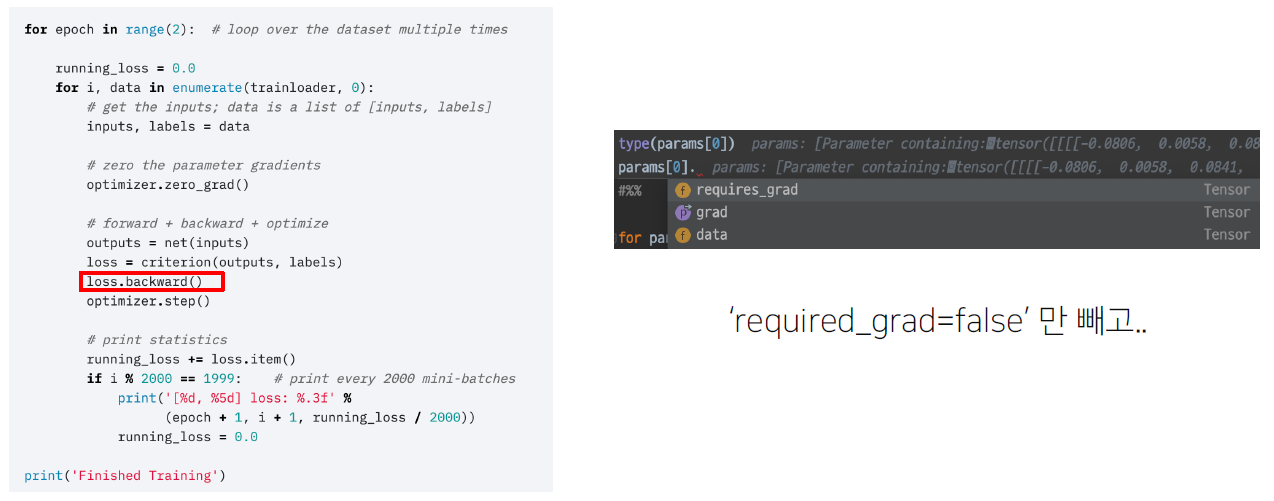
loss.backward()
이 함수가 실행되면 모델의 파라미터의 grad 값이 업데이트 됩니다.
조금 특별한 loss
Focal Loss
Class Imbalance 문제가 있는 경우, 맞춘 확률이 높은 Class는 조금의 loss를 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여.
Label Smoothing Loss
Class target0label을 Onehot 표현으로 사용하기 보다는
ex) [0,01,00,00,00,0…]
조금 Soft 하게 표현해서 일반화 성능을 높이기 위함
ex) [0.025,00.9,00.025,00.025,0…]
현실에서 생각해보면 차량을 구분하는 모델을 학습시킬 때 정말 차만 있는 사진은 있지 않다. 그 주변에 사물들도 존재할 수 있고, 차에도 번호판 같은게 있어 차량만 있는 것은 아니기에 one hot label이 아닌 값으로 smoothing 시키는 것이다.
Optimizer
영리하게 움직일 수록 수렴은 빨라집니다.

LR scheduler
학습 시에 LearningJrate를 동적으로 조절할 수는 없을까?
StepLR
특정 Step 마다 LR 감소
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)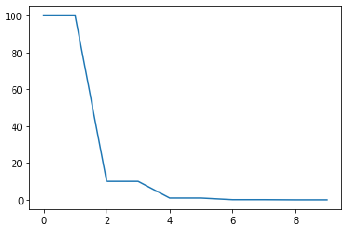
CosineAnnealingLR
Cosine 함수 형태처럼 LR을 급격히 변경
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)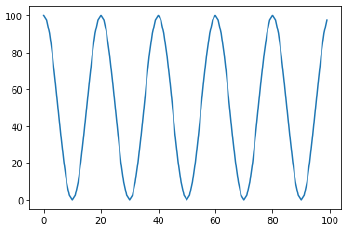
Learning Rate가 작아졌다가 줄어졌다가 하는게 효과가 없어보일 수 있지만, local minimum에 있을 때 갑자기 LR이 커진다면 그 영역을 벗어날 수 있다.
ReduceLROnPlateau
더 이상 성능 향상이 없을 때 LRJ감소
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')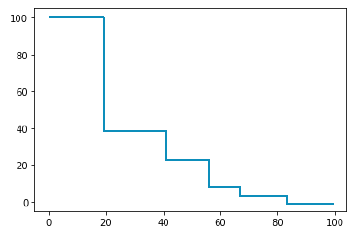
Metric
모델의 평가
학습에 직접적으로 사용되는 것은 아니지만 학습된 모델을 객관적으로 평가할 수 있는 지표가 필요하다.

Metric의 허와 실
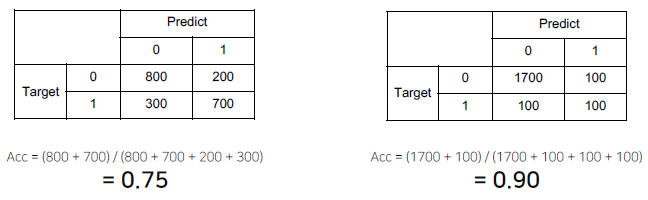
위 모델의 결과를 봐보자. 왼쪽 모델은 0.75의 정확도를, 오른쪽 모델은 0.90의 정확도를 갖는다. 이 때 이 수치만 보고 0.90이 더 정확하다고 판단할 수 있을까?
오른쪽 표를 봐보면 0에 대해서는 잘 맞추지만 1에 해서는 단순히 찍기 정도의 수준으로 모델이 예측하는 것을 확인할 수 있다.
균형이 맞지 않는 데이터를 학습하게 되어 단순히 0으로 예측하는 경우가 많아진 것이다.
극단적으로 만약 0이 학습 데이터의 95%를 차지한다고 가정할 경우 모델은 1이 아닌 0만 출력하더라도 95%의 정확도를 보여준다. 이 경우 이렇게 예측한 모델이 더 정확하다고, 더 좋은 모델이라고 할 수 있을까?
위 같은 경우에도 오른쪽 모델은 1에 대한 평가를 할 수 없기에 왼쪽 모델이 결과적으로 더 좋은 모델이라고 할 수 있다.
올바른 Metric의 선택

이처럼 정확도만 갖고 모델을 판단하는 것은 위험하다. 그래서 데이터의 특성을 잘 파악하고, 데이터 상태에 따라 적절한 Metric을 선택하는 것이 필요하다.
Training & Inference Process
Training Process
Training 준비
학습 한번 하기 위해 지금 까지 만든 결과물
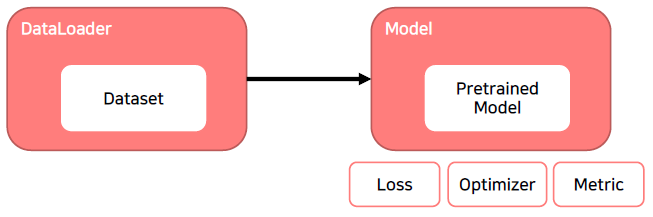
Training 프로세스의 이해
model.train()

model을 train하는 상태로 변경해준다. train 상태로 변경해주는 이유는 보통 모듈 안에는 Dropout이나 BatchNorm이 존재하는데 train 과정과 evalutation 과정에서 동작되는 방식이 다르기 때문이다.
optimzer.zero_grad()

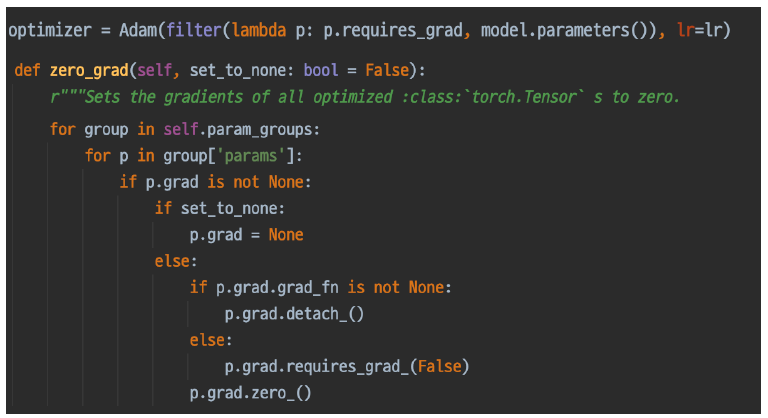
loss = criterion(outputs, labels)

loss 함수 내부 구조는 위와 같은데, 매번 배치가 반복될 때 마다 grad가 갱신되는 것이 아닌 쌓이는 구조이다. 그래서 일반적으로는 매 배치별로 이전 과거의 배치의 grad를 초기화 하고 이번 배치에 관해서만 grad를 갱신해주려고 optimizer.zero_grad() 를 사용하는 것이다.
loss는 마지막에 생성되며 이로써 backward 될 수 있는 chain이 완성된다.
loss의 grad_fn chain → loss.backward()
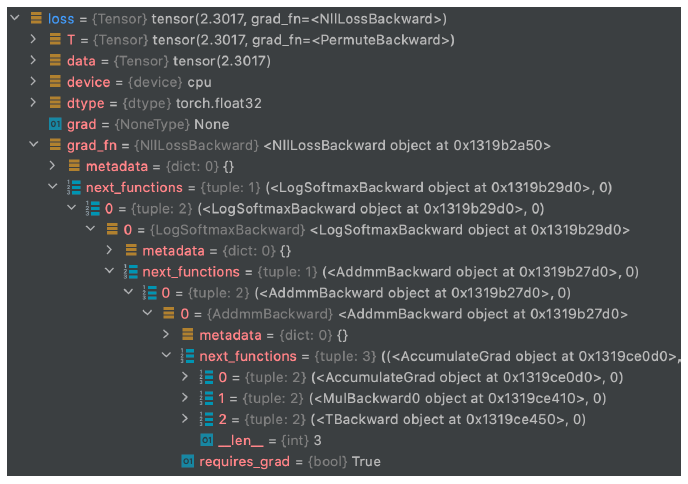
디버깅을 진행해보면 위와 같이 backward가 트리 구조로 계속 형성되는 것을 볼 수 있다.
optimizer.step()
grad가 저장이 됐으면 이제 각 parameter를 업데이트 시켜줘야 한다. 이 역할을 optimizer.step()이 한다.
More: Gradient Accumulation
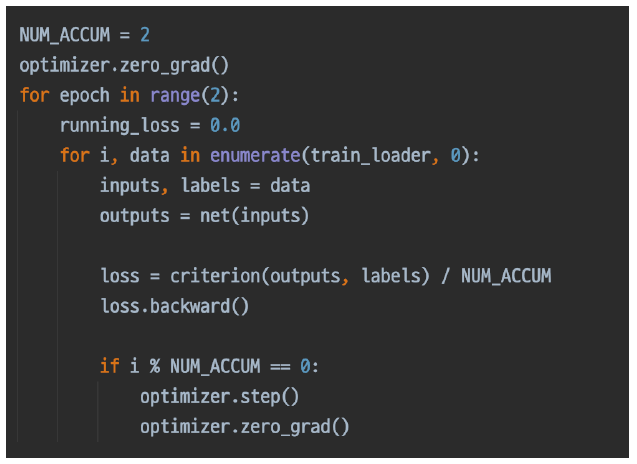
일반적으로 매 배치별로 optimizer.zero_grad를 실행하여 grad를 초기화 해주지만 GPU 자원은 한정적이라 모델이 커서 어쩔 수 없이 작은 배치 사이즈만 학습 가능한 경우가 존재한다. 이 때 Gradient를 Accumulation 시켜 원하는 배치 사이즈가 됐을 때 optimizer.step()로 gradient를 업데이트하여 배치를 크게 한 만큼의 효과를 줄 수 있다.
Inference Process
model.eval()
model을 evalutation 모드로 만들어, Dropout과 BatchNorm을 평가에 맞게 사용한다.
with torch.no_grad():

모델이 예측을 진행할 때는 학습이 필요없어 gradient를 저장할 필요가 없다. 하지만 모든 파라미터의 requires_grad를 False로 하는 것은 비효율적일 수 있는데, pytorch는 한번에 모든 parameter의 requires_grad를 False로 하는 기능을 제공한다.
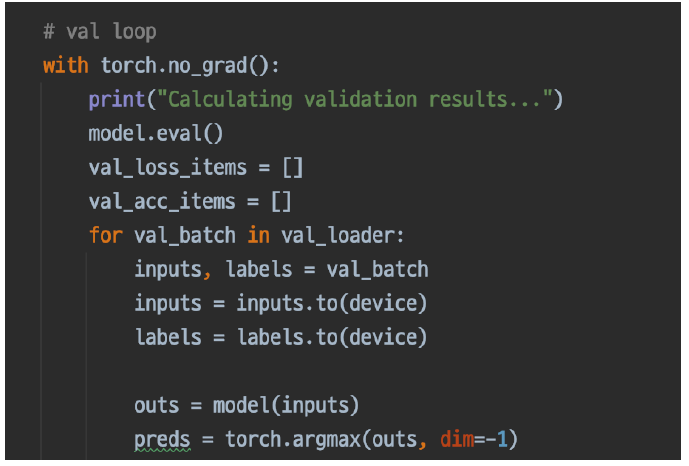
Validation 확인
추론 과정에 Validation 셋이 들어가면 그게 검증입니다.
Checkpoint
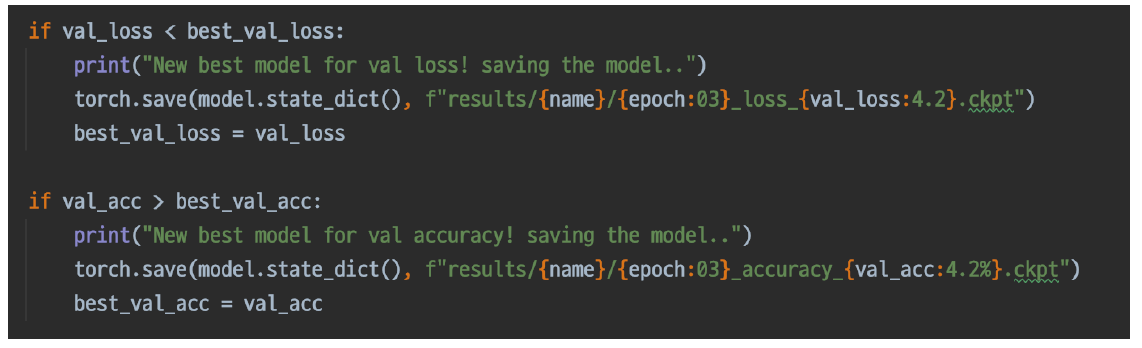
valid_loss나 valid_acc로 가장 성능이 잘 나오는 모델을 저장한다.
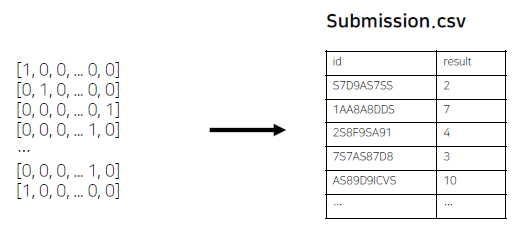
최종 Output, Submission 형태로 변환
최종 Submission 스펙을 확인한 후 변환하여 제출한다.
Pytorch Lightning
Pytorch도 Keras 처럼 간단하게 모델의 train과 inference를 할 수 있도록 라이브러리가 존재한다.
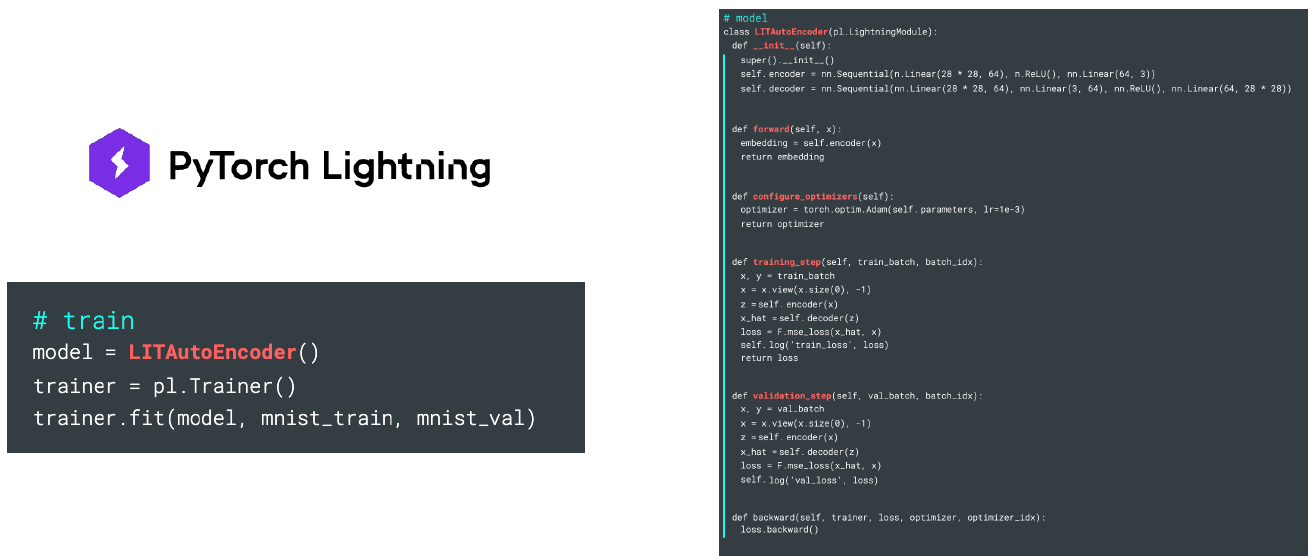
그래도 머신러닝을 공부하는 동안에는 Pytorch 라이브러리로 직접 하는 것을 권장한다. 깊은 이해가 쌓이고, 기초가 튼튼해질 때 이 라이브러리를 사용하는 것을 추천한다.
