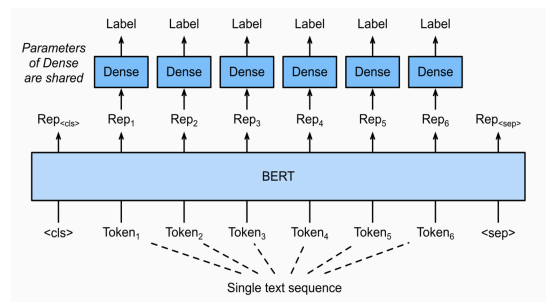
언어 모델 기반 문장 토큰 분류
문장 토큰 분류 task
주어진 문장의 각 token이 어떤 범주에 속하는지 분류하는 task
Named Entity Recognition (NER)
개체명 인식은 문맥을 파악해서 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고 있는 단어 또는 어구(개체) 등을 인식하는 과정을 의미한다.

texts = ["이수지가 저수지에 갔는데 이 수지가 저수지에 간 걸까 저 수지가 저수지에 간걸까 그 수지가 저수지에 간 걸까 하며",
"이수지는 고민했는데 고민 끝에 이수의 마이웨이를 부르며 불쾌지수가 올라가며 저수지를 떠나 경기도 수지구의 한 학원으로 달려가더니",
"지수함수를 배워서 잘 사용하여 주식 수지를 맞아 \"나 이수지, 바로 고단수지! 수지맞았다!\"하며 행복해했다."]
from pororo import Pororo
ner = Pororo(task="ner", lang="ko")
for text in texts:
for pred in ner(text):
if pred[1] != "O":
print("{}({})".format(pred[0],pred[1]), end="")
else:
print(pred[0], end="")
print()
# 이수지(PERSON)가 저수지에 갔는데 이 수지가 저수지에 간 걸까 저 수지가 저수지에 간걸까 그 수지가 저수지에 간 걸까 하며
# 이수지(PERSON)는 고민했는데 고민 끝에 이수(PERSON)의 마이웨이를 부르며 불쾌지수가 올라가며 저수지를 떠나 경기도(LOCATION) 수지구(LOCATION)의 한 학원으로 달려가더니
# 지수함수를 배워서 잘 사용하여 주식 수지를 맞아 "나 이수지(PERSON), 바로 고단수지! 수지맞았다!"하며 행복해했다.같은 단어라도 문맥에서 다양한 개체(Entity)로 사용 된다.
Part-of-speech tagging (POS TAGGING)
품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것이다.
품사 태깅은 주어진 문장의 각 성분에 대하여 가장 알맞는 품사를 태깅하는 것을 의미한다.
from pororo import Pororo
pos = Pororo(task="pos", lang="ko")
pos("이순신은 조선 중기의 무신이다.")
# [('이순신', 'NNP'),
# ('은', 'JX'),
# (' ', 'SPACE'),
# ('조선', 'NNP'),
# (' ', 'SPACE'),
# ('중기', 'NNG'),
# ('의', 'JKG'),
# (' ', 'SPACE'),
# ('무신', 'NNG'),
# ('이', 'VCP'),
# ('다', 'EF'),
# ('.', 'SF')]kor_ner
- 한국해양대학교 자연어 처리 연구실에서 공개한 한국어 NER 데이터셋
- 일반적으로, NER 데이터셋은 pos tagging 도 함께 존재

- Entity tag에서 B의 의미는 개체명의 시작(Begin)을 의미하고, I의 의미는 내부(Inside)를 의미하며, O는 다루지 않는 개체명(Outside)를 의미한다.
- 즉, B-PER은 인물명 개체명의 시작을 의미하며, I-PER는 인물명 개체명의 내부 부분을 뜻한다.
- kor_ner 데이터셋에서 다루는 개체명은 다음과 같다.

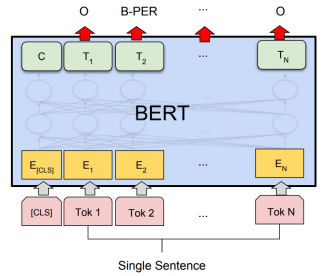
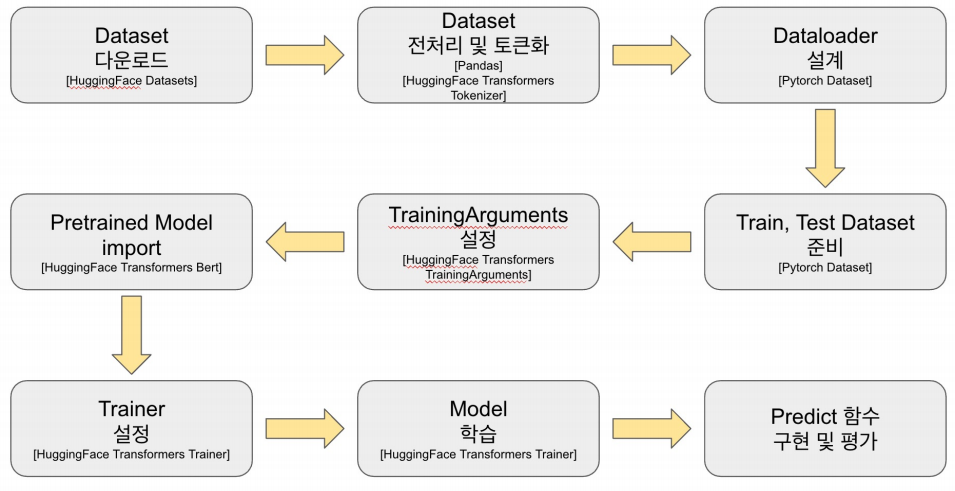
문장 토큰 분류 모델 학습
NER fine-tuning with BERT
주의점
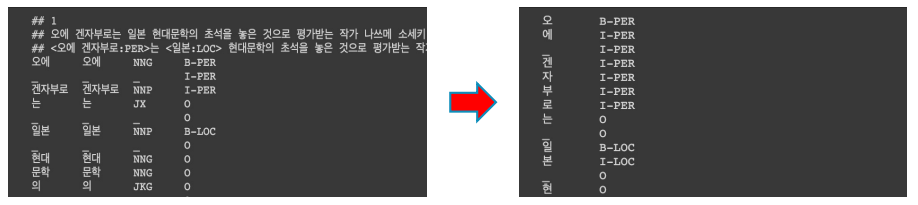
형태소 단위의 토큰을 음절 단위의 토큰으로 분해하고, Entity tag 역시 음절 단위로 매핑시켜 주어야 한다.
예를 들어, "이순신은 조선 중기의 무신이다."를 토크나이저가 이순 ##신 ##은 이라고 하면 ##신은 품사를 알기 힘들다.

초보 개발자입니다