Python Data Analysis Library
pandas
구조화된 데이터의 처리를 지원하는 Python 라이브러리
- panel data → pandas
- 고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 “스프레드시트” 처리 기능을 제공
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공
- 데이터 처리 및 통계 분석을 위해 사용 (Deep Learning, Image, Text, Sound)
- Tabular형 데이터 처리에 적합하다.
conda create -n ml python=3.8 # 가상환경생성
activate ml # 가상환경실행
conda install pandas # pandas 설치
jupyternotebook # 주피터 실행하기pandas 구성
import pandas as pd
# 기존 데이터를 불러와서 DataFrame을 생성
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' #Data URL
df_data = pd.read_csv(data_url, sep = "\s+", header = None) # csv 타입 데이터 로드, separate는 빈공간으로 지정하고, Column은 없음
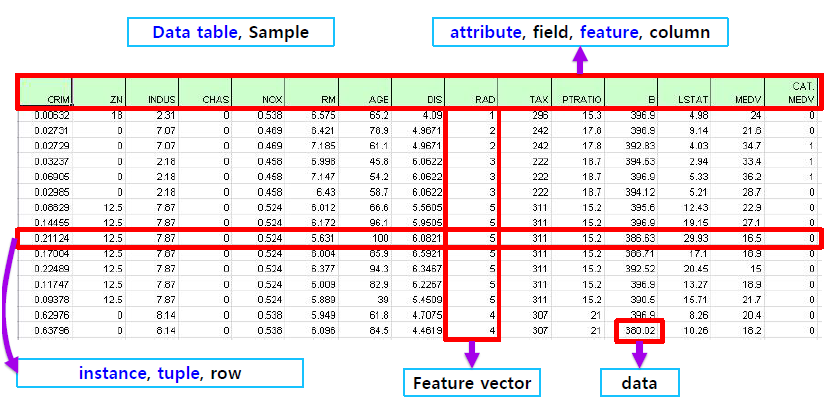
df_data.head() # 처음 다섯줄 출력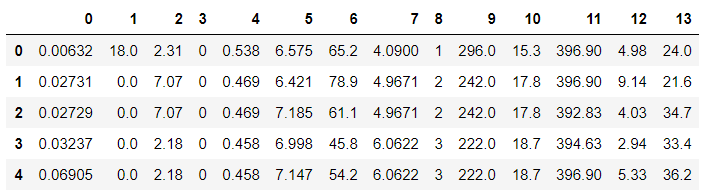
df_data.columns = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT", "MEDV"]
# Column Header 이름 지정
df_data.head()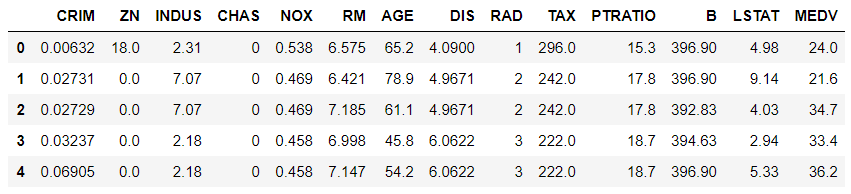
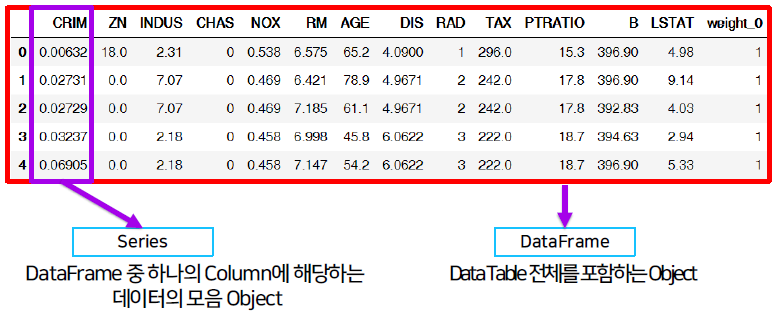
Series
column vector를 표현하는 object
list_data = [1, 2, 3, 4, 5]
example_obj = Series(data = list_data)
example_obj
# index data
# ↓ ↓
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# dtype: int64
# ↑
# Data type
list_data = [1, 2, 3, 4, 5]
list_name = ['a', 'b', 'c', 'd', 'e']
example_obj = Series(data = list_data, index = list_name) # index 이름을 지정
example_obj
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64dict_data = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
example_obj = Series(data = list_data, index = list_name) # data type 설정, series 이름 설정
example_obj
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64
example_obj['a'] # data index에 접근하기
# 1
example_obj = example_obj.astype(float)
example_obj
# a 1.0
# b 2.0
# c 3.0
# d 4.0
# e 5.0
# dtype: float64
example_obj['a'] = 3.2
example_obj
# a 3.2
# b 2.0
# c 3.0
# d 4.0
# e 5.0
# dtype: float64
example_obj.values # 값 리스트만
# array([3.2, 2. , 3. , 4. , 5. ])
type(example_obj.values)
# numpy.ndarray
example_obj.index # Index 리스트만
# Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
# 데이터에 대한 정보를 저장
example_obj.name = 'number'
example_obj.index.name = 'alphabet' # index 이름
example_obj
# alphabet
# a 3.2
# b 2.0
# c 3.0
# d 4.0
# e 5.0
# Name: number, dtype: float64
dict_data_1 = {"a": 1, "b": 2, "c": 3, "d": 4, "e": 5}
indexes = ["a", "b", "c", "d", "e", "f", "g", "h"]
series_obj_1 = Series(dict_data_1, index=indexes) # index 값을 기준으로 series 생성
series_obj_1
# a 1.0
# b 2.0
# c 3.0
# d 4.0
# e 5.0
# f NaN
# g NaN
# h NaN
# dtype: float64Dataframe
Series를 모아서 만든 Data Table (기본 2차원)
- Dataframe 생성
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {"first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"],
"last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"],
"age": [42, 52, 36, 24, 73],
"city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"]}
df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city"])
df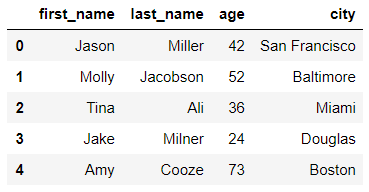
DataFrame(raw_data, columns=["age", "city"]) # column 선택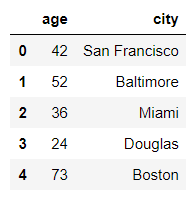
# 새로운 column 추가
df = DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "debt"])
df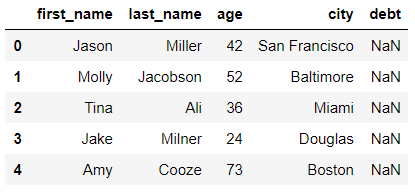
# column 선택 - Series 추출
df.first_name
# 0 Jason
# 1 Molly
# 2 Tina
# 3 Jake
# 4 Amy
# Name: first_name, dtype: object
df["first_name"]
# 0 Jason
# 1 Molly
# 2 Tina
# 3 Jake
# 4 Amy
# Name: first_name, dtype: object- Dataframe indexing
loc은 index 이름, iloc은 index number
# Example from - https://stackoverflow.com/questions/31593201/pandas-iloc-vs-ix-vs-loc-explanation
s = pd.Series(np.nan, index=[49, 48, 47, 46, 45, 1, 2, 3, 4, 5])
s.loc[:3]
'''
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
dtype: float64
'''
s.iloc[:3]
'''
49 NaN
48 NaN
47 NaN
dtype: float64
'''- Dataframe handling
# column에 새로운 데이터 할당
df.debt = df.age > 40
df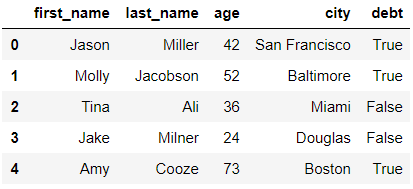
df.T # transpose
df.values # 값 출력
'''
array([['Jason', 'Miller', 42, 'San Francisco', nan],
['Molly', 'Jacobson', 52, 'Baltimore', nan],
['Tina', 'Ali', 36, 'Miami', nan],
['Jake', 'Milner', 24, 'Douglas', nan],
['Amy', 'Cooze', 73, 'Boston', nan]], dtype=object)
'''
df.to_csv() # csv 변환
# ',first_name,last_name,age,city,debt\r\n0,Jason,Miller,42,San Francisco,\r\n1,Molly,Jacobson,52,Baltimore,\r\n2,Tina,Ali,36,Miami,\r\n3,Jake,Milner,24,Douglas,\r\n4,Amy,Cooze,73,Boston,\r\n'# column을 삭제함
del df["debt"]
df
Selection & Drop
- Selection with column names
import numpy as np
df = pd.read_excel("./data/excel-comp-data.xlsx")
df.head()
# 한 개의 column 선택 시
df["account"].head(3)
'''
0 211829
1 320563
2 648336
Name: account, dtype: int64
'''
# 1개 이상의 column 선택
df[["account", "street", "state"]].head(3)
- Selection with index number
# column 이름없이 사용하는 index number는 row 기준 표시
df[:3]
# column 이름과 함께 row index 사용시, 해당 column만
df["account"][:3]
'''
0 211829
1 320563
2 648336
Name: account, dtype: int64
'''
account_serires = df["account"]
account_serires[:3]
'''
0 211829
1 320563
2 648336
Name: account, dtype: int64
'''
account_serires[[0, 1, 2]] # 1개 이상의 index
'''
0 211829
1 320563
2 648336
Name: account, dtype: int64
'''
account_serires[account_serires < 250000] # Boolean index
'''
0 211829
3 109996
4 121213
5 132971
6 145068
7 205217
8 209744
9 212303
10 214098
11 231907
12 242368
Name: account, dtype: int64
'''- index 변경
df.index = df["account"]
del df["account"]
df.head()
- basic, loc, iloc selection
# column과 index number
df[["name", "street"]][:2]
# column 과 index name
df.loc[[211829, 320563], ["name", "street"]]
# column number와 index number
df.iloc[:2, :2]
- index 재설정
df.index = list(range(0, 15))
df.head()
- Data drop
# index number로 drop
df.drop(1)
# 한 개 이상의 index number로 drop
df.drop([0, 1, 2, 3])
# axis가 지정된 축을 기준으로 drop → column 중에 “city”
df.drop("city", axis=1)
Dataframe operations
- Series operation
index 기준으로 연산 수행, 겹치는 index가 없을 경우 NaN값으로 반환
s1 = Series(range(1, 6), index=list("abced"))
s1
'''
a 1
b 2
c 3
e 4
d 5
dtype: int64
'''
s2 = Series(range(5, 11), index = list('bcedef'))
s2
'''
b 5
c 6
e 7
d 8
e 9
f 10
dtype: int64
'''
s1 + s2
'''
a NaN
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f NaN
dtype: float64
'''
s1.add(s2)
'''
a NaN
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f NaN
dtype: float64
'''
초보 개발자입니다