Mathematics for Artificial Intelligence
미분
미분(differentiation)은 변수의 움직임에 따른 함수값의 변화를 측정하기 위한도구
- 최적화에서 제일 많이 사용하는 기법
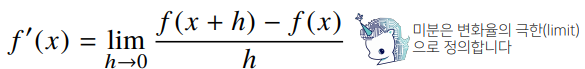
- 최근엔 미분을 손으로 직접 계산하는 대신 컴퓨터가 계산해줄 수 있습니다.
import sympy as sym
from sympy.abc import x
sym.diff(sym.poly(x**2 + 2*x + 3), x)
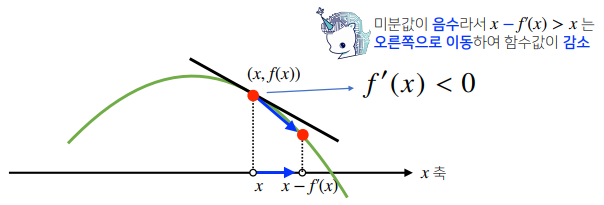
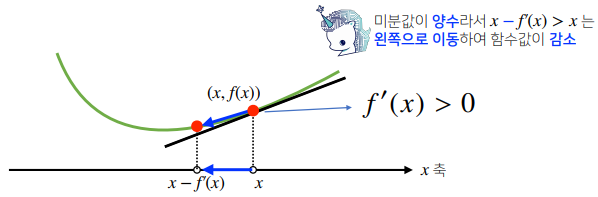
# Poly(2𝑥+2,𝑥,𝑑𝑜𝑚𝑎𝑖𝑛=ℤ)- 미분은 함수 f의 주어진 점 (x, f(x))에서의 접선의 기울기를 구한다.
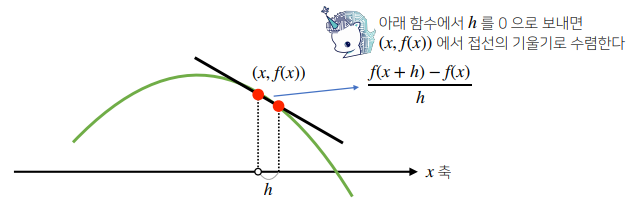
- 한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수 값이 증가하는지 / 감소하는지 알 수 있다.
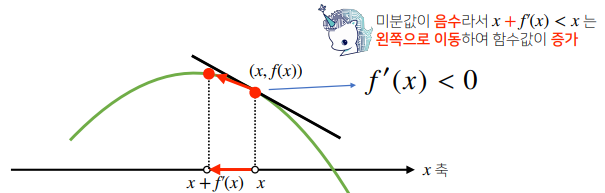
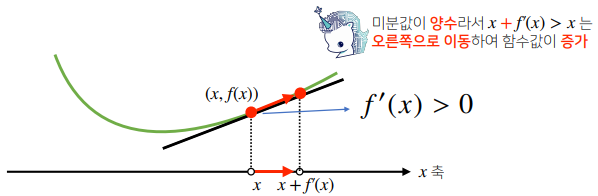
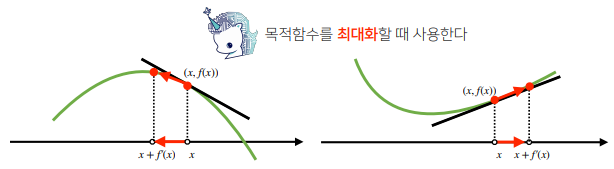
- 미분 값을 더하면 경사상승법(gradientascent)이라 하며 함수의 극대값의 위치를 구할 때 사용한다.
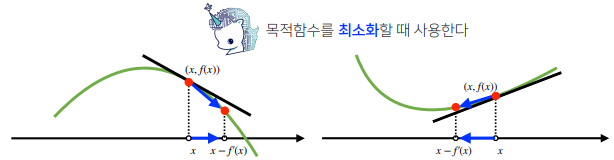
- 미분값을 빼면 경사하강법(gradientdescent)이라 하며 함수의 극소값의 위치를 구할 때 사용한다.
- 경사상승/경사하강 방법은 극값에 도달하면 움직임을 멈춘다.
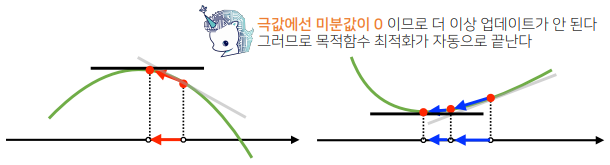
- 컴퓨터로 계산할 때 미분이 정확히 0이 되는 것은 불가능하므로 eps 보다 작을 때 종료하는 조건이 필요하다.
var = init
grad = gradient(var)
while(abs(grad > eps):
var = var - lr * grad # lr은 학습률로서 미분을 통해 업데이트하는 속도를 조절한다
grad = gradient(var) # 종료 조건이 성립하기 전까지 미분 값을 계속 업데이트한다def func(val):
fun = sym.poly(x**2 + 2*x + 3)
return fun.subs(x, val), fun
def func_gradient(fun, val):
_, function = fun(val)
diff = sym.diff(function, x)
return diff.subs(x, val), diff
def gradient_descent(fun, init_point, lr_rate = 1e-2, epsilon = 1e-5):
cnt = 0
val = init_point
diff, _ = func_gradient(fun, init_point)
while np.abs(diff) > epsilon:
val = val - lr_rate * diff
diff, _ = func_gradient(fun, val)
cnt += 1
print(f"함수: {fun(val)[1]}, 연산횟수: {cnt}, 최소점: ({val}, {fun(val)[0]})")
gradient_descent(fun = func, init_point = np.random.uniform(-2, 2))
# 함수: Poly(x**2 + 2*x + 3, x, domain='ZZ'), 연산횟수: 624, 최소점: (-0.999995082008834, 2.00000000002419)벡터의 미분
벡터가 입력인 다변수 함수의 경우 편미분(partialdifferentiation)을 사용한다.

import sympy as sym
from sympy.abc import x, y
sym.diff(sym.poly(x**2 + 2 * x * y + 3) + sym.cos(x + 2 * y) , x)
# 2𝑥+2𝑦−sin(𝑥+2𝑦)- 각 변수 별로 편미분 을계산한 그레디언트(gradient) 벡터를 이용하여 경사하강/경사상승법에 사용할 수 있다.
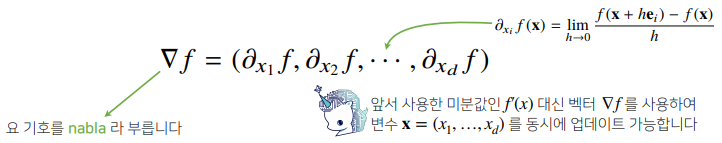
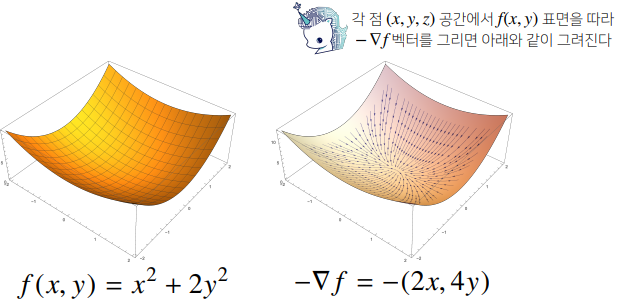

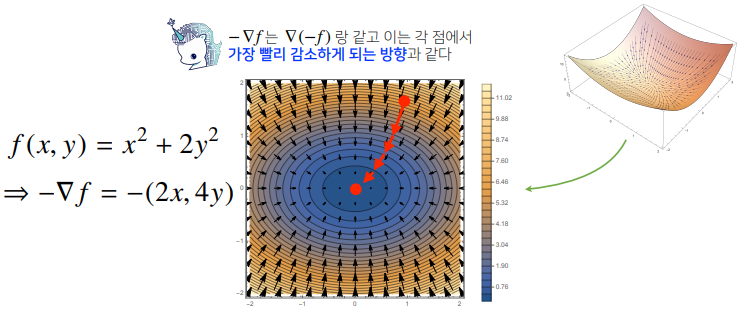
def eval_(fun, val):
val_x, val_y = val
fun_eval = fun.subs(x, val_x).subs(y, val_y)
return fun_eval
def func_multi(val):
x_, y_ = val
func = sym.poly(x ** 2 + 2 * y ** 2)
return eval_(func, [x_, y_]), func
def func_gradient(fun, val):
x_, y_ =val
_, function = fun(val)
diff_x = sym.diff(function, x)
diff_y = sym.diff(function, y)
grad_vec = np.array([eval_(diff_x, [x_, y_]), eval_(diff_y, [x_, y_])], dtype = float)
return grad_vec, [diff_x, diff_y]
def gradient_descent(fun, init_point, lr_rate = 1e-2, epsilon = 1e-5):
cnt = 0
val = init_point
diff, _ = func_gradient(fun, init_point)
while np.linalg.norm(diff) > epsilon:
val = val - lr_rate * diff
diff, _ = func_gradient(fun, val)
cnt += 1
print(f"함수: {fun(val)[1]}, 연산횟수: {cnt}, 최소점: ({val}, {fun(val)[0]})")
pt = [np.random.uniform(-2, 2), np.random.uniform(-2, 2)]
gradient_descent(fun = func_multi, init_point = pt)
# 함수: Poly(x**2 + 2*y**2, x, y, domain='ZZ'), 연산횟수: 529, 최소점: ([ 4.96374105e-06 -5.33676420e-10], 2.46387257323552E-11)선형회귀 분석
선형회귀의 목적식은 이고 이를 최소화하는 를 찾아야 하므로 다음과 같은 그레디언트 벡터를 구해야 한다.
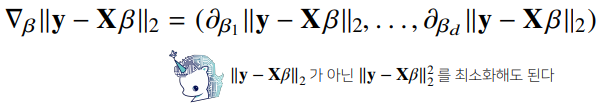
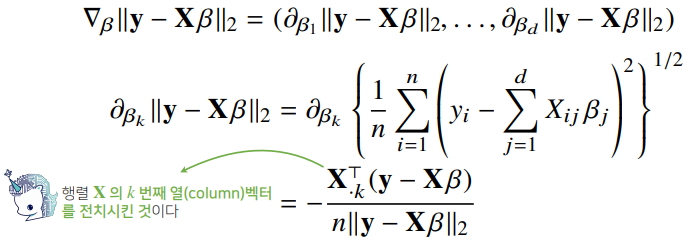
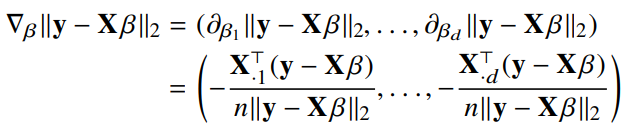
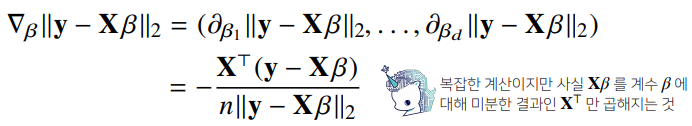
- 이제 목적식을 최소화하는 를 구하는 경사하강법 알고리즘은 다음과 같다.
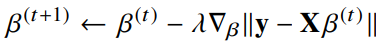
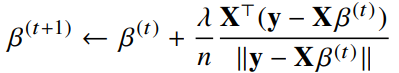
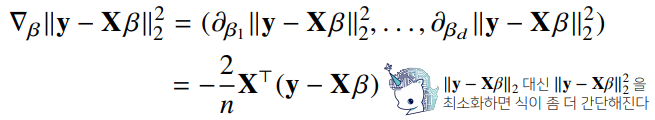
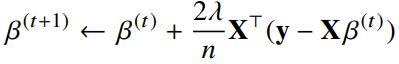
- 경사하강법 알고리즘에서 학습률과 학습횟수가 중요한 hyperparameter가 된다.
for t in range(T): # 학습 횟수가 너무 적으면 경사하강법이 수렴하지 못할 수 있다
error = y - X @ beta
grad = - transpose(X) @ error
beta = beta - lr * gradX = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
beta_gd = [10.1, 15.1, -6.5] # [1, 2, 3] 이 정답
X_ = np.array([np.append(x, [1]) for x in X]) # intercept 항 추가
for t in range(5000):
error = y - X_ @ beta_gd
# error = error / np.linalg.norm(error)
grad = - np.transpose(X_) @ error
beta_gd = beta_gd - 0.01 * grad
print(beta_gd)
# [1.00000367 1.99999949 2.99999516]경사하강법
이론적으로 경사하강법은 미분 가능하고 볼록(convex)한 함수에 대해선 적절한 학습률과 학습 횟수를 선택했을 때 수렴이 보장되어 있습니다.
특히 선형 회귀의 경우 목적식 은 회귀계수 에 대해 볼록함수이기 때문에 알고리즘을 충분히 돌리면 수렴이 보장됩니다.
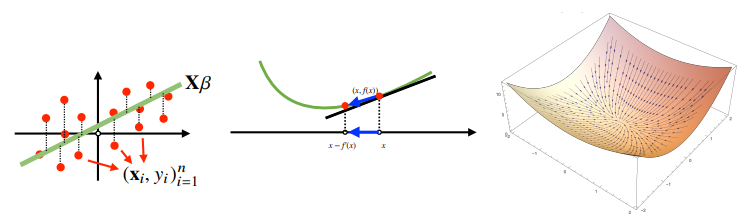
하지만 비선형 회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지는 않습니다.
확률적 경사하강법
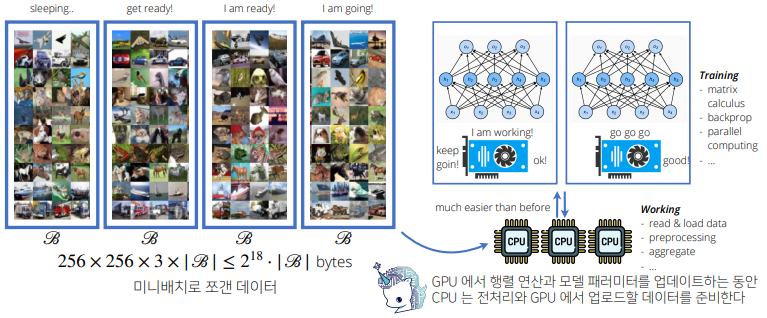
확률적 경사하강법(stochasticgradientdescent)은 모든 데이터를 사용해서 업데이트하는 대신 데이터를 한 개 또는 일부 활용하여 업데이트 합니다.

- SGD는 데이터의 일부를 가지고 패러미터를 업데이트하기 때문에 연산 자원을 좀 더 효율적으로 활용하는데 도움이 됩니다.

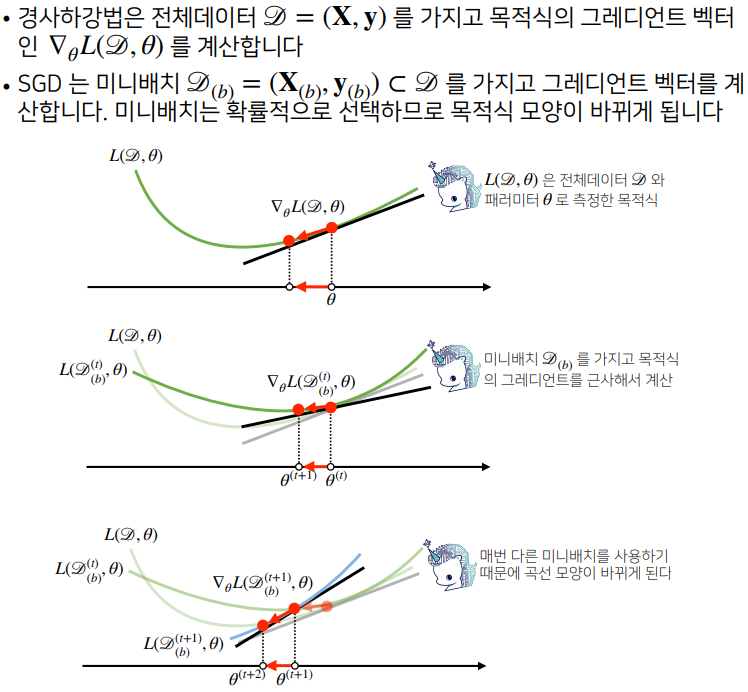
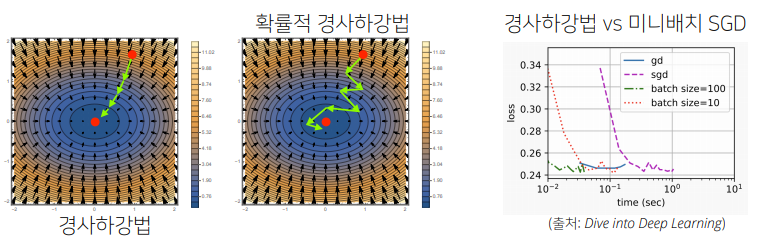
- SGD는 볼록이 아닌 목적식에서도 사용 가능하므로 경사하강법보다 머신러닝 학습에 더 효율적입니다.
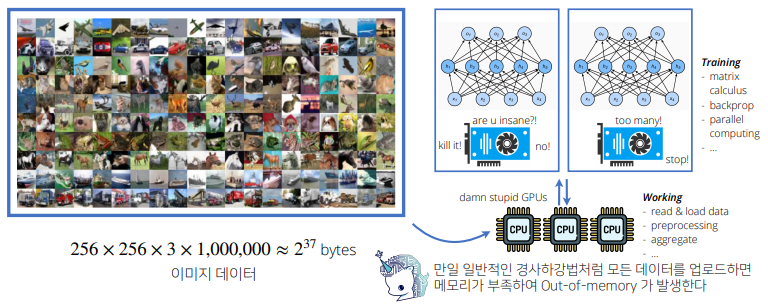

초보 개발자입니다