01. 데이터 리터러시
1) 정의
- 데이터를 읽는 능력
- 데이터를 이해하는 능력
- 데이터를 비판적으로 분석하는 능력
- 결과를 의사소통에 활용할 수 있는 능력
데이터 리터러시란?
- 데이터 수집과 데이터 원천을 이해하고
- 주어진 데이터에 대한 다양한 활용법을 이해하고
- 데이터를 통한 핵심지표를 이해하는 것
- 데이터 리터러시는 올바른 질문을 던질 수 있도록 만들어 줌
2) 데이터 분석에 대한 착각
- 보통 데이터 분석을 배운다고 한다면, SQL, Python, Tableau 등을 학습
- 막상 데이터 분석을 하려고 보면 잘 되지 않음
☑️ 데이터 분석에 대한 착각
- 데이터를 잘 분석하면 문제, 목적, 결론이 나올 것이라고 생각
- 데이터를 잘 가공하면 유용한 정보를 얻을 수 있다고 생각
- 분석에 실패하면 방법론, 스킬이 부족한 것이라고 생각
3) 데이터 해석 오류 사례
☑️ 심슨의 역설 (Simpson’s Paradox)
- 심슨의 패러독스란 '부분'에서 성립한 대소 관계가 그 부분들을 종합한 '전체'에 대해서는 성립하지 않는 모순적인 경우를 말한다.
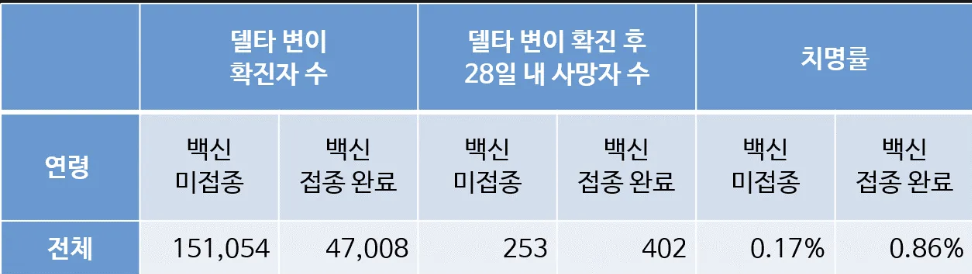
- 위 표는 영국 공공보건국에서 2021년 8월 발표한 코로나 변이 바이러스에 대한 브리핑 자료
- 백신 미접종자의 치명률 0.17%, 백신 2차 접종 완료 치명률 0.86%
- 백신 접종 완료자의 치명률이 미접종자에 비해 5배 이상 더 높게 나타난 의문스러운 결과
- 하지만 나누어 생각한다면?
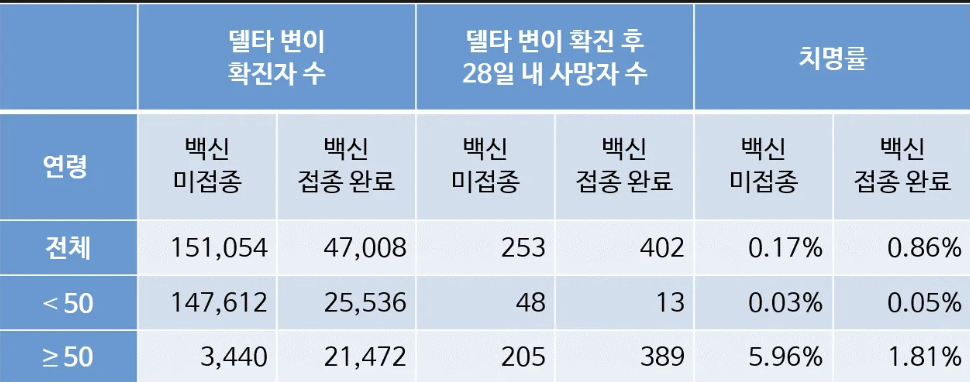
- 데이터를 50세 미만과 50세 이상으로 나누어 살펴보면 다른 결과를 확인할 수 있음
- 50세 미만 집단에서는 백신 미접종자의 치명률이 0.03%, 접종 완료자의 치명률이 0.05%
- 접종 완료자의 치명률이 더 높기는 했으나, 양쪽 모두 낮은 수준의 치명률을 나타냄
- 50세 이상 집단에서는 백신 미접종자의 치명률이 5.96%, 접종 완료자의 치명률이 1.81%
- 미접종자의 치명률이 접종 완료자에 비해 3배 이상 높게 나타남
- 즉, 개별 연령 집단 내에서 살펴보면, 50세 미만은 백신 접종 여부에 관계없이 치명률이 매우 낮았고, 50세 이상의 위험군에서는 백신이 치명률을 낮추는 효과가 있음
- 전체에 대한 결론이 언제나 개별 집단에 그대로 적용되는 것은 아님
- 데이터에 기반한 결론이라고 해서 이를 맹목적으로 받아들여서는 안됨
☑️ 시각화를 활용한 왜곡
- 자료의 표현 방법에 따라서 해석의 오류 여지가 존재
- 매해 노동자와 자본가가 버는 시간당 액수의 증가를 세 가지 방식으로 나타낸 사례
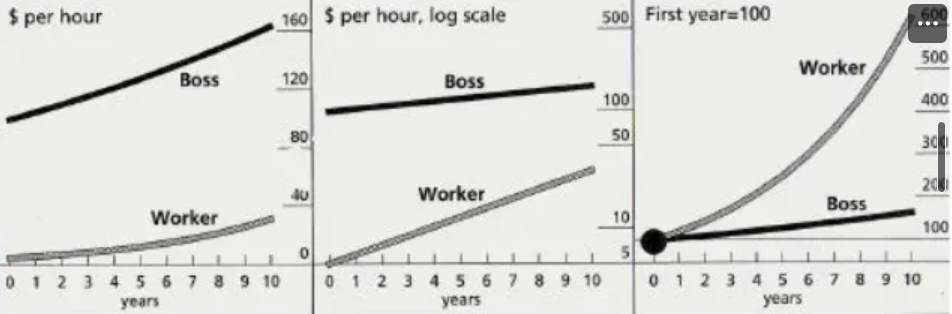
(《The Economist》의 자료)
- 왼쪽은 있는 그대로의 자료
- 중간은 증가량에 로그를 취한 자료
- 오른쪽은 노동자와 자본가의 최초 수입을 100%로 놓고 이후의 증가율에 대한 자료
- 왼쪽 그래프에서는 노동자의 임금이 현저히 낮은 것을 확인 할 수 있음
- 중간 그래프에서는 노동자들의 임금 증가가 급격하게 이루어져 왔다고 해석될 여지 존재
- 오른쪽 그래프에서는 노동자들의 임금 증가가 자본가의 수입 증가를 훨씬 능가한다고 해석할 여지 존재
☑️ 샘플링 편향 (Sampling Bias)
- 전체를 대표하지 못하는 편향된 샘플 선정으로 인해 오류가 발생
- 1936년 미국 대통령 선거에서 Literary Digest 잡지사가 천만 명에게 우편물을 보내 수행한 대규모 여론조사 사례
- 240만 명의 응답을 받았고 랜던이 선거에서 57% 득표를 얻을 것이라고 높은 신뢰도로 예측했지만, 루즈벨트가 62% 득표로 당선
- 문제는 Literary Digest의 샘플링 방법
- 첫째, 여론조사용 주소를 얻기 위해 전화번호부, 자사의 구독자 명부, 클럽 회원 명부 등을 사용. 이런 명부는 모두 공화당(따라서 랜던)에 투표할 가능성이 높은 부유한 계층에 편중된 경향이 존재
- 둘째, 우편물 수신자 중 25% 미만의 사람이 응답. 이는 정치에 관심 없는 사람, Literary Digest를 싫어하는 사람과 다른 중요한 그룹을 제외시킴으로써 역시 표본을 편향되게 만듦
- 표본이 편향되면서 실제와는 다르게 해석하게 될 수 있음
☑️ 상관관계와 인과관계
- 상관관계
- 두 변수가 얼마나 상호 의존적인지를 파악하는 것을 의미
- 파악 방법은 한 변수가 증가하면 다른 변수도 따라서 증가/감소하되 그 추이를 따름
- 인과관계
- 실질적으로 하나의 요인으로 인해 다른 요인의 수치가 변하는 형태를 의미
- 원인과 결과가 명확한 것
- 사례
- 1940년대 보건 전문가의 소아마비와 아이스크림 섭취 간의 연구 결과
- 당시 보건 전문가는 소아마비와 아이스크림 섭취량의 상관관계가 있는 것을 발견, 전국에 소아마비 예방을 위해 아이스크림 섭취량을 줄일 것을 권고
- 소아마비는 여름에 많이 발생
- 아이스크림은 여름에 판매량이 급증
- 즉 소아마비와 아이스크림 섭취 간에는 어떤 인과관계도 존재하지 않음
- 단순히 날씨라는 변수로 인해 공통으로 영향을 주게 됨
- 상관관계는 인과관계가 아닌 것을 항상 유의해야 함
- 상관관계만으로 섣불리 의사결정 하지 않기
- 양쪽을 모두 활용하여 합리적인 의사판단 하기
4) 데이터 리터러시가 필요한 이유
- 크게 3가지 단계로 구분
- 문제 및 가설정의
- 데이터 분석
- 결과 해석 및 액션 도출
- 위 단계 중 ‘생각’이 주요한 단계에서 데이터 리터러시가 필요
- 데이터 분석이 목적이 되지 않도록 ‘왜?’를 항상 생각해야 함
02. 문제 정의
1) 문제 정의란?

☑️ 데이터 분석에 실패하는 이유
- 데이터 리터러시 단원에서 정리했던 것처럼, 풀고자 하는 문제를 명확하게 정의하지 않음
☑️ 문제 정의란?
- 데이터 분석 프로젝트의 성공을 위한 초석
- 분석하려는 특정 상황이나 현상에 대한 명확하고 구체적인 진술
- 프로젝트의 목표를 설정하고 분석 방향을 설정
☑️ 문제 정의 사례
- 상황: 매출 증가가 목표인 패션 플랫폼 A
- 문제 정의: 매출을 어떻게 늘릴 수 있을까?
- 문제 정의는 했지만, 모호하고 구체적이지 않음
- 어떤 고객층, 제품에 초점을 맞출지에 대한 명확한 지침이 부재
- 데이터 분석할 시 방향성을 잡기가 어려움
- 문제 정의를 다음과 같이 수정해볼 수 있습니다.
- 지난 6개월 동안 25 - 35세 여성 고객층의 구매 전환율이 급격히 감소했다. 이 고객층의 전환율을 2%에서 5%로 끌어올리기 위해 어떤 마케팅 전략을 적용할 수 있을까?
- 구매 전환율: 고객이 방문한 후 구매까지 전환됐는지의 여부
- 구매고객수/방문고객수*100 = 구매 전환율(%)
- 지난 6개월 동안 25 - 35세 여성 고객층의 구매 전환율이 급격히 감소했다. 이 고객층의 전환율을 2%에서 5%로 끌어올리기 위해 어떤 마케팅 전략을 적용할 수 있을까?
2) 문제 정의 방법론
☑️ MECE (Mutually Exclusive, Collectively Exhaustive)
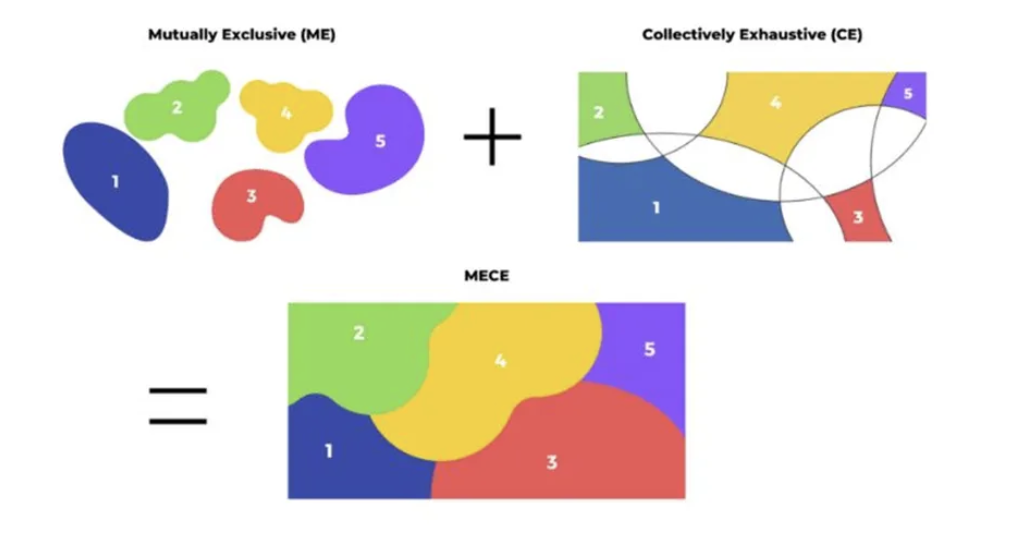
- 문제 해결과 분석에서 널리 사용되는 접근 방식
- 문제를 상호 배타적(mutually exclusive)이면서, 전체적으로 포괄적(collectively exhaustive)인 구성요소로 나누는 것
- MECE를 통해 복잡한 문제를 체계적으로 분해하고, 구조화된 방식으로 분석할 수 있음
- 잘못된 MECE 예시
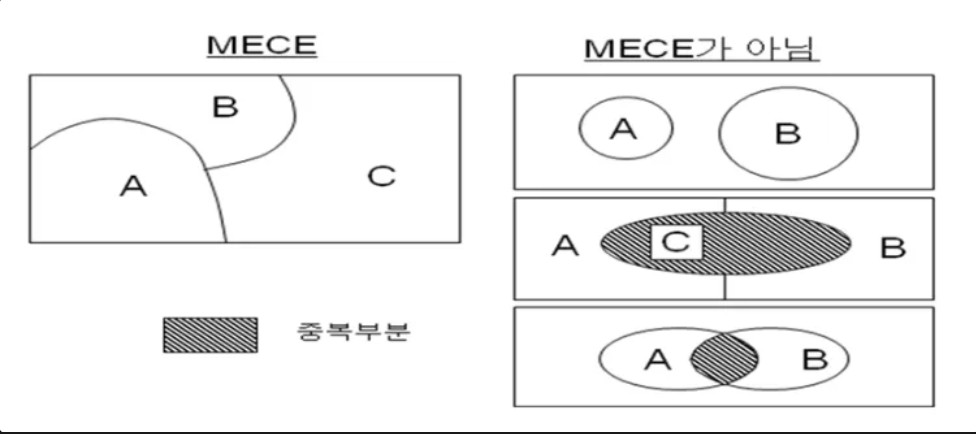
- 사람 - 남성, 여성, 아저씨로 나눔: 남성과 아저씨가 중복
- 영화 장르 - 액션, 스릴러, 공포로 나눔: 멜로 코메디 등 누락 장르 존재
- 자동차 - SUV, 세단, 쿠페, 현기차로 나눔: 분류 기준이 다름. 자동차 종류 VS 브랜드
- 3학년 3반 학급원 - 영어 우수 학생, 수학 우수 학생으로 나눔: 분류 기준이 불명확, 서로 중복되고 누락된 정보가 존재
☑️ 로직 트리(Logic Tree)
- MECE 원칙을 기반으로 복잡한 문제를 더 작고 관리하기 쉬운 하위 문제로 분해하는데 사용
- 상위 문제로부터 시작하여 하위 문제로 계층적 접근
- 일반적으로 도표 형식으로 표현되어 쉽게 파악할 수 있음
- 로직트리를 활용하여 문제정의 해보기
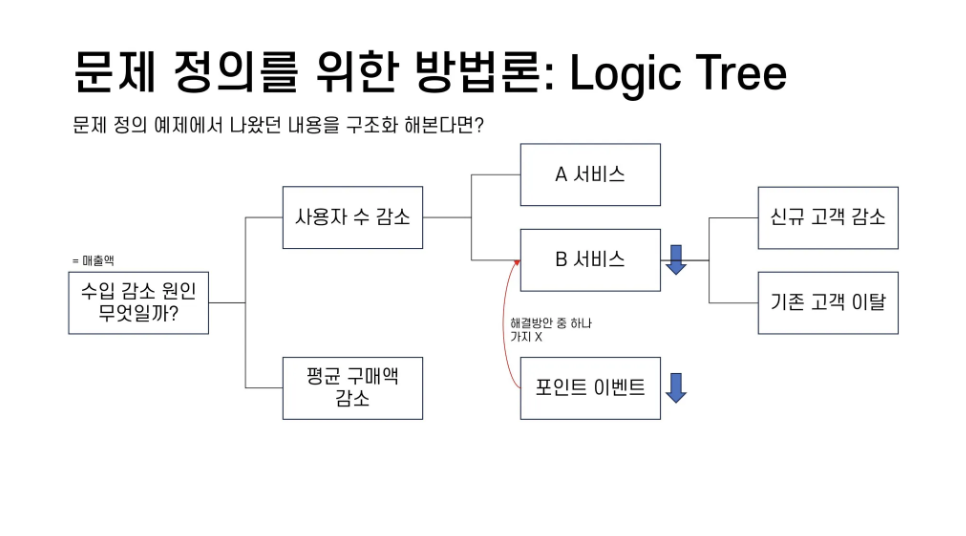
- 문제 정의 예제에서 나왔던 내용을 구조화 한다면?
- 수입 = 매출액으로 정의하고 구조화
- 사용자 수 감소에서 A, B 서비스를 나누어 생각
- 포인트 이벤트는 해결 방안 중 하나이고, 문제가 되는 것은 아님
- B서비스를 더 세분화해서 A서비스와 비교해서 다른 점이 무엇인지 찾아볼 수 있도록 구조화
- 로직트리는 정해진 답이 없으며, 사용자가 어떤 기준으로 나누냐에 따라 그 깊이와 넓이가 달라짐
- 인과 관계의 순서는 작은가지 → 큰 가지
- 위 예시에서도 ‘브랜드 선호도 감소’와 같은 원인을 큰 가지에 삽입할 수도 있고, 고객 수 감소의 작은 가지로 넣어볼 수도 있음
3) 로직트리 Cheet Sheet
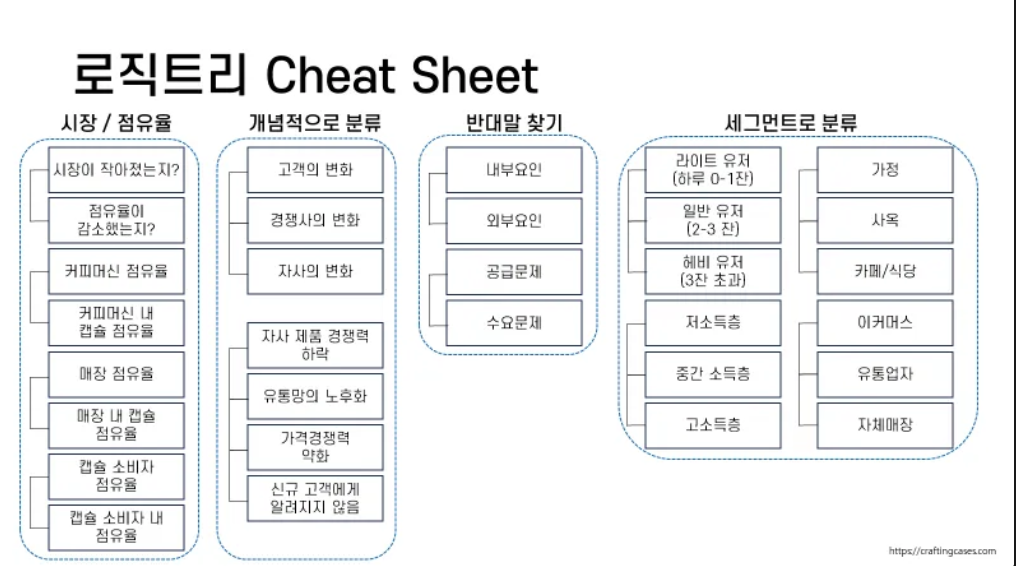
- 시장 / 점유율에 따라 분류
- 개념적으로 분류
- 반대되는 말로 분류
- 세그먼트에 기반하여 분류
- 앱 서비스에 적용하기 위해 변경해 본다면? (비즈니스에 따라서 정의가 달라짐!)
- 세그먼트 분류
- 라이트유저, 일반유저, 헤비유저 > 구매 전 고객, 재구매 고객, VIP 고객
ex) 배달의 민족 고마운분, 귀한분, 더귀한분, 천생연분
- 라이트유저, 일반유저, 헤비유저 > 구매 전 고객, 재구매 고객, VIP 고객
- 캡슐 점유율
- 해당 서비스 시장 점유율로 변화
- 세그먼트 분류
4) 문제 정의 정리와 관련된 팁
- 결과를 공유하고자 하는 사람이 누구인지 정의하기
- 결과를 통해 원하는 변화를 생각하기
- 회사 소속이라면, 경영자의 입장에서 보려고 노력
- 많은 사람들과 의견을 나눠보는 것도 방법
- 반드시 혼자서 오래 고민해보는 시간을 가질 것
문제 정의 시 체크리스트 보러가기 : 링크

문과생의 sql 배우기 많은 관심 부탁드립니다