이 논문은 2021년에 나온 Transformer를 action segmentation task에 맞게 변형시킨 모델에 대해 나와있다.
NLP의 Transformer가 CV에서도 활용되어 여러 논문들이 나왔다고 들었는데 action segmentation task에도 나온 걸 보니 신기하다.
내 개인적인 생각으로는 action segmentation도 NLP 기계번역 분야처럼 순서나 위치, 이웃간의 상관관계 같은 것들이 중요하기 때문에 Transformer와 잘 맞을 것 같다는 생각이 들었다.
ASFormer: Transformer for Action Segmentation
Author: Hangqiu Yi, Hongyu Wen, Tingting Jiang
Submitted dat: August 16, 2021
Abstract
NLP에서 유명한 Transformer를 변형하여 만든 모델이다.
모델의 3가지 특징
- feature들의 high locality로 인해 local connectivity inductive bias를 가져올 수 있다. 이는 action segmentation taks에서 적은 학습 데이터를 가지고 적절한 target function을 학습시킬 수 있다.
- pre-defined hierarchical representation pattern을 적용할 수 있다. → 이는 긴 input sequences를 효율적으로 다룰 수 있다.
- 인코더로부터 initial predictions를 수정할 수 있는 디코더를 디자인했다.
Introduction
기존 vanilla transformer를 action segmentation task에 적용했을 때, 주요 문제점과 해결
-
training set의 작은 사이즈로 인해 inductive biases 부족은 병목현상을 초래한다.
→ action segmentation의 특징 중 하나는 높은 locality 피처들이다. 그래서 local connectivity inductive bias가 굉장히 중요하다. 그래서 모델은 hypothesis space를 reliable 범위안으로 제한해서
-
긴 비디오에 대한 self-attention 적용은 transformer가 효과적으로 표현하기 힘들다. 이는 비디오의 길이로 인해 의미있는 locations에 집중하도록 하는 적절한 weigths 학습이 힘들다는 것이다.
→ pre-defined hierarchical representation pattern을 각 self-attention layer들에 적용한다. 이는 low-level self-attention layer들을 local relation에 먼저 집중하도록 한 후, 점진적으로 high-level layer들 쪽으로 넓히는 것이다.
이 결과 수렴 시간과 성능을 높일 수 있다. 그리고 이러한 계층적으로 표현하는 패턴은 time complexity와 total space도 줄일 수 있다.
-
기존의 인코더-디코더 구조는 action segmentation task의 refinement 부분과 맞지 않다. 원래 action segmentation 모델들은 initial prediction 이후 다시 refine하는 과정을 반복하는데 트랜스포머는 이와 맞지 않다.
→ 디코더에 cross-attention 구조를 넣는다. 이는 인코더의 모든 포지션이 refinement 과정에 들어가도록 한다. 동시에 학습된 피처 space에 대한 인코더의 방해도 막는다.
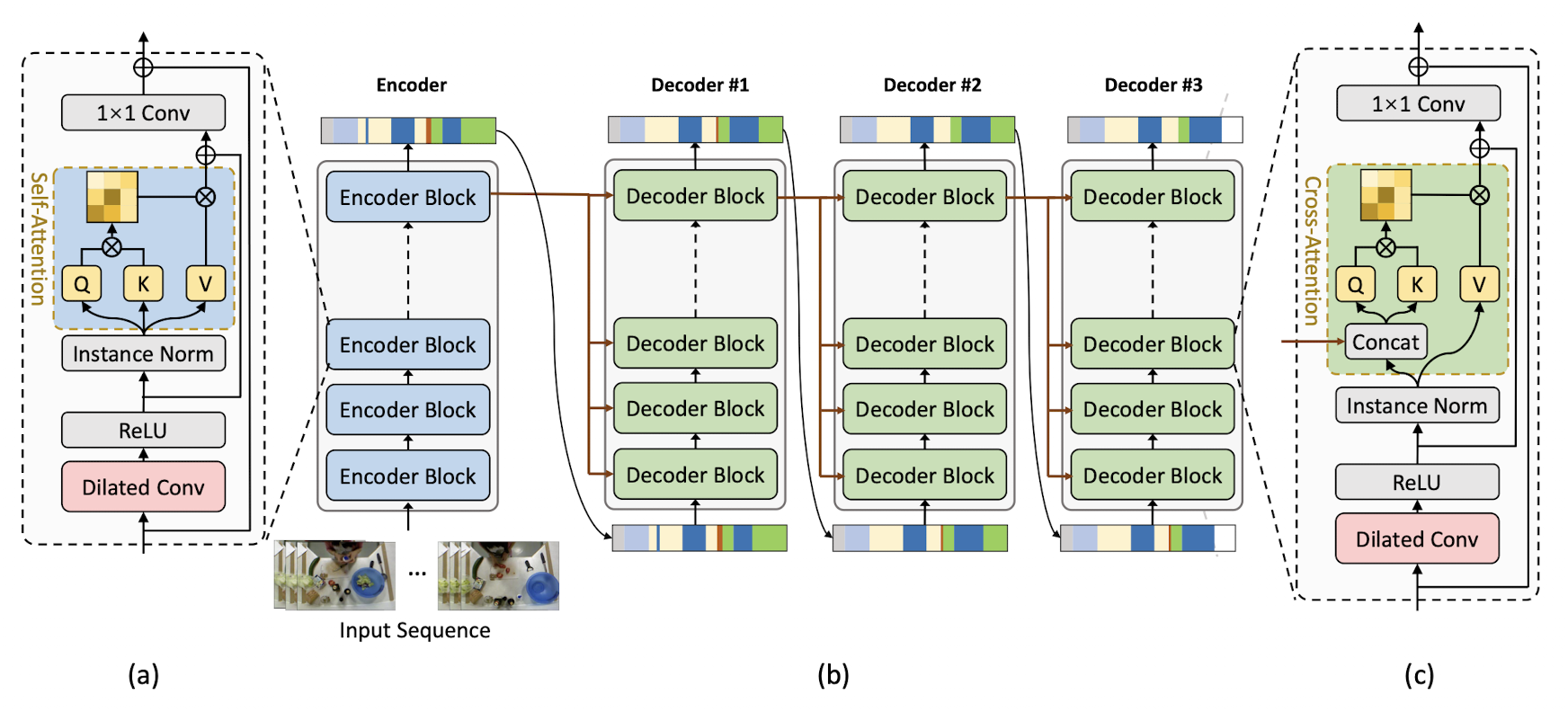
(b)는 반복적인 refinement를 위한 구조
인코더에서 video sequences를 받고 intial predictions를 내보낸다. 인코더안에는 pre-defined hierachical representation patterns가 들어잇다.
디코더에는 predictions를 input으로 받고 인코더와 비슷한 구조를 갖고 있다.
(a)에서 인코더 블록은 dilated conv를 가진 feed-forward layer와 self-attention layer, residual connections를 가지고 있다.
(c)에서 디코더 블록을 보면 인코더에서 정보를 가져오기 위해 cross-attention 구조를 갖고 있다.
Methods
Transformer 구조로 된 인코더 디코더 구조를 가진다.
인코더가 미리 추출된 frame-wise 비디오 feature sequence를 인풋으로 받고 첫 predictions를 내보낸다. 그러면 디코더가 이를 인풋으로 받아 refinement 하는 과정을 반복한다.
인코더에서 적은 학습데이터셋과 긴 비디오 시퀀스를 어떻게 다루는 지 보여주고
디코더에서 여러 action segments 사이의 temporal relation의 이점을 다룬다.
Encoder
미리 추출된 입력 sequence의 크기는 TxD
T: video 길이, D: feature dimension
인코더의 첫 레이어는 fully connected layer로 입력 피처를 받아 predicitions 를 아웃풋으로 내보낸다.
C: action class 수
각 인코더 layer는 2개의 sub-layers를 가진다. → feed-forward layer와 single-head self-attention layer. 추가로 각 sub-layers 사이에 residual connection도 있다.(위의 그림 참고)
기존 Transformer와 다르게 dilated temporal convolution을 feed-forward layer로 넣었다.(원래는 point-wise fully connected layer)
→ training set의 부족과 high locality of features를 고려한 변형
self-attention layersms 의미있는 location을 찾기 힘들고 서로 모여서 효과적인 representation을 형성하기 힘들다.
→ 이 문제를 해결하기 위해 pre-defined hierachical representation pattern을 적용한다.
그리고 w사이즈의 local window 로 self-attention layer의 receptive fields를 제한한다. 이 사이즈는 레이어마다 2배씩 증가한다.
인코딩 depth가 증가할수록, temporal conv 레이어의 dilation rate도 2배씩 증가시킨다.self-attention 레이어에서는 그대로 유지한다.
이런 계층적인 패턴은 우선 local feature에 집중하도록 하고 점진적으로 receptive field를 넓혀 global information을 볼 수 있게 한다.
추가로 기존 transformer의 메모리 사용량은 대략 JTT이다.
이를 계층적 표현 패턴으로 로 줄일 수 있다.
Decoders
take bottle, pour water 다음은 drink water와 같이 multiple action segments간에는 temporal relations가 존재한다. 이는 action segmentation task에서 매우 중요한 역할을 한다.
디코더에서는 temporal relations를 잘 찾아서 인코더가 전달한 initial predictions를 refinement 과정을 통해 성능을 높인다.
A Single Decoder
먼저 설명을 위해 하나의 디코더를 살펴보자면,
디코더의 첫번째 레이어는 차원을 맞추기 위해 fully-connected layer로 구성되어있다. 그 뒤에 디코더 블럭들이 차례로 붙는다.
구조는 인코더와 비슷하게 feed-forward layer와 hierarchical pattern이 있으며, cross-attention layer가 적용되는 점이 다르다.
self-attention과 다르게 cross-attention은 우선 Q(query), K(key)를 인코더와 이전 레이어의 output의 concat에서 얻는 반면에 V(value)는 concat전 이전 레이어의 output에서 얻는다는 점이 다르다.
→ 이러한 구조로 refinement 과정에서도 모든 포지션의 인코더가 관여할 수 있도록 하였다. V는 인코더의 방해없이 오로지 input predictions으로부터 만들어진다.
이전 연구들에서도 보여줬듯이 refinement 과정은 학습된 feature space의 방해에 매우 민감하다.
Multiple Decoders
iteratice refinement를 위해 위의 single decoder를 확장시킨다.
cross-attention은 외부 정보를 가져오는데, error accumulation 문제를 피하기 위해서 외부에서 가져오는 정보의 weight를 줄인다.
첫번째 디코더는 로 설정하고 점차 감소한다.
Loss Function & Implementation details
loss function은 classification loss()와 smooth loss()의 합으로 이루어져있다.
classification은 cross-entropy loss, smooth loss는 frame-wise probabilities의 mean squared error로 계산한다.
: predicted probability for the groung truth label at time
: 논문에서는 0.25로 설정
final ASFormer는 1개의 인코더와 3개의 디코더로 구성되어있으며,
인코더와 디코더는 각각 9개의 블럭을 갖고있다.
차원 셋팅을 위한 각 첫번째 fc layer는 64 dimension으로 설정한다
그리고 논문에서는 dropout rate을 0.3으로 인코더의 input feature에 dropout을 적용했다. 120epoch를 adam optimizer로 lr 0.0005로 훈련시켰다.
Experiments
Impact of position encoding and multi-head self-attention
구현에서 vanilla transformer와 다른 점이 2가지 있다.
- position encoding X
- multi-head attention X, 각 인코더 디코더 블럭에 single-head attention 사용
실험1 : position encoding이 ASFormer에 필요한가 아닌가
아래 표는 50Salads dataset의 결과이다. 확실히 성능이 떨어지는 것을 볼 수 있다.
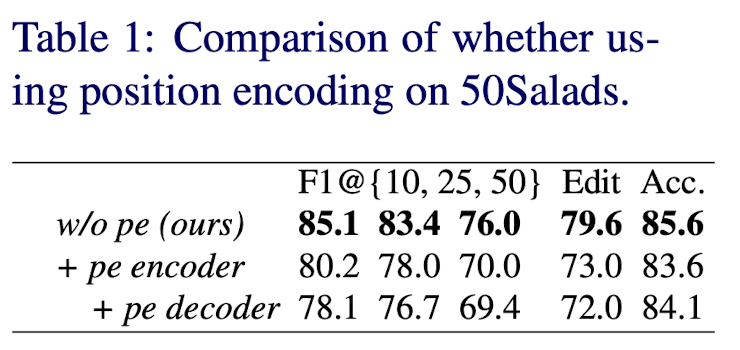
→ 가능성있는 근거로는 temporal conv에서 이미 모델의 상대적인 relationships을 가질 수 있기 때문이다. 그러므로 absolute한 position encoding은 필요없으며 오히려 방해가 된다.
실험2 : multi-head self-attention의 영향력
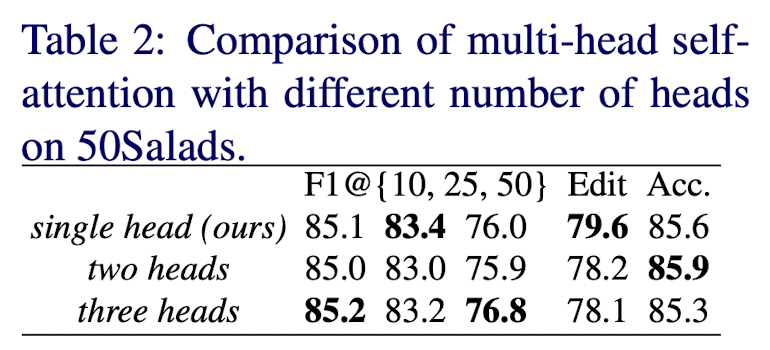
single head와 다른 multi heads와 성능차이가 거의 없다.
→ convolution operation은 multi-head self-attention operation과 비슷하기 때문이다.
결론적으로 computation, memory budgets를 고려하여 single-head self-attention을 default로 사용한다.
Effect of the local connective inductive bias
이번에는 local connective inductive bias의 효과에 대해 살펴본다.
vanilla transformer와 같이 feed-forward layer로 사용되는 MLP와 비교하였다.
temporal conv를 없애려면 vanilla transformer처럼 position encoding이 필요하다.
먼저 refinement 과정의 영향력을 제외하기 위해 인코더 부분에서만 사용해보았다.

성능이 크게 줄어드는 것을 확인할 수 있다. 특히 F1 score와 edit이 많이 떨어지는데 이는 모델이 frame들 사이에서 temporal relationship을 알아내지 못한 것을 의미한다.
Effect of the hierarchical representation pattern
ASFormer의 hierarchical representation pattern은 중요한 역할을 한다. 이를 보여주기 위해 계층구조가 아닌 모든 attention layer의 local window사이즈를 512로 맞춘 모델을 준비했다. 여기서 512는 마지막 인코더, 디코더 블록에서 메모리 용량을 고려한 가장 큰 window size이다.

확실한 성능 저하가 보인다.
→ 왜 이러한 성능 차이가 나는 지 더 잘 이해하기 위해 아래 그림을 첨부하였다. 아래 그림은 각 인코더의 self-attnetion 레이어의 attention weights를 그린 것이다.
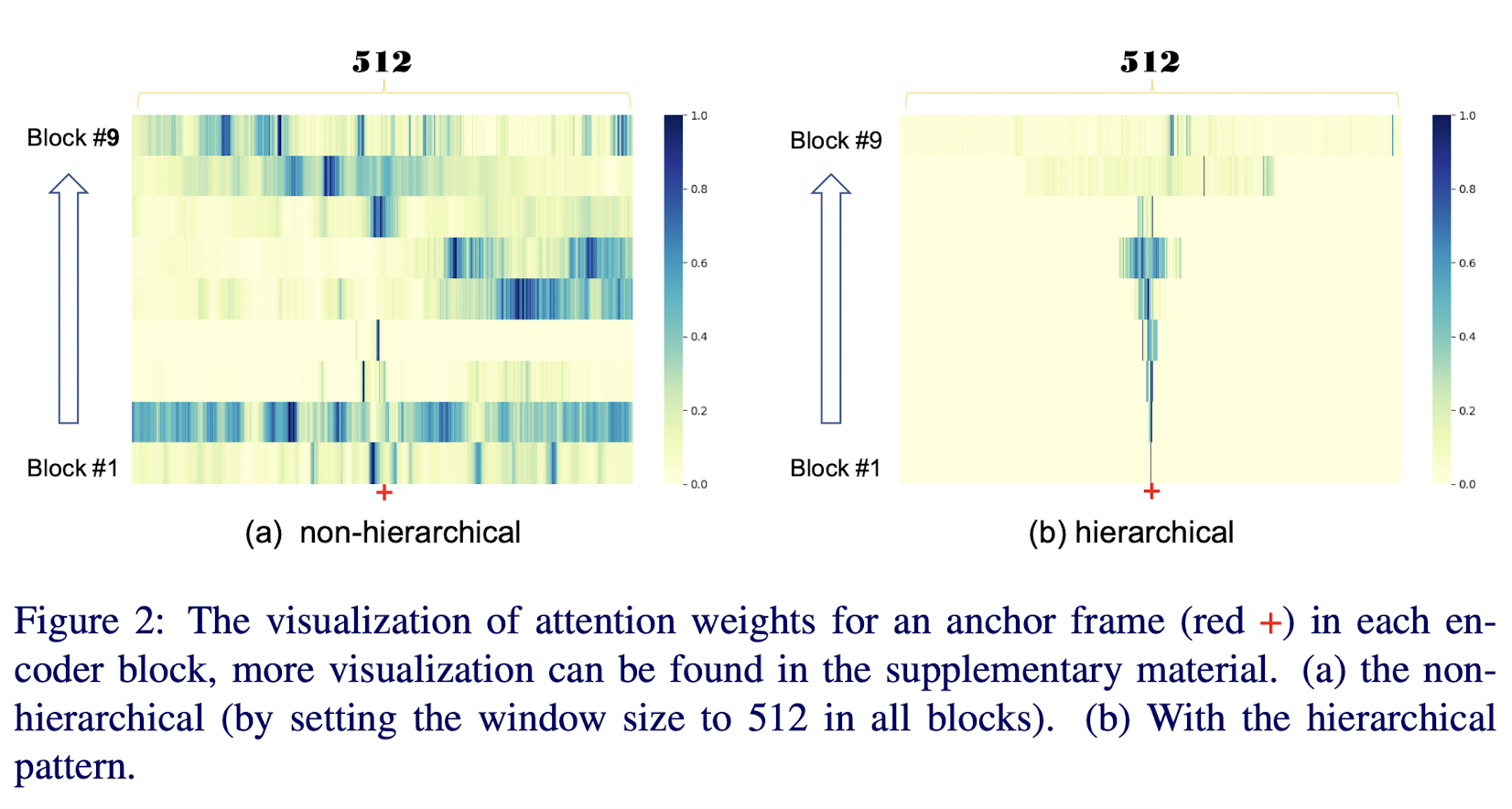
- 비계층 버전이 high-level 블럭에서 더 많은 활동이 있다. 이것은 attention weights가 더 많은 위치에서 더 가까운 값과 더 비슷한 사소한 균일 분포를 가진다는 것을 의미한다. 반대로 계층 버전에서는 몇몇 의미있는 위치에 집중한다.
- ‘freely’ attention 은 스스로 계층적인 패턴을 데이터에서 학습하지 못한다는 것을 볼 수 있다. self-attention layer가 자유로울때 low-level 블럭들은 주위 이웃들에게 집중을 하지 않는다는 것을 위의 이미지에서 볼 수 있다.
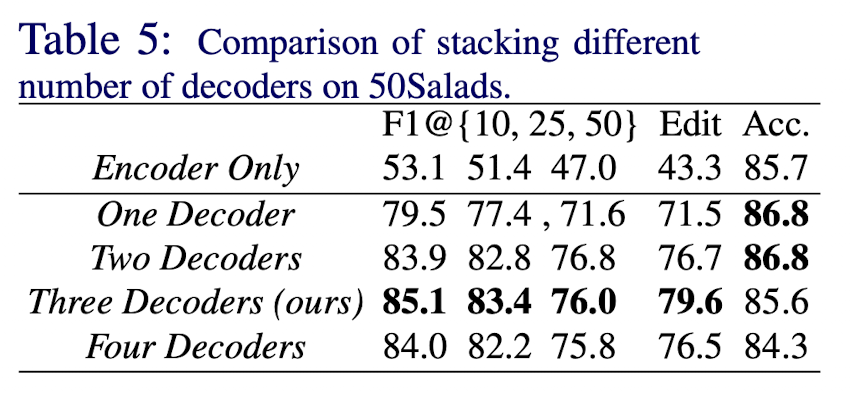
Effect of the multiple decoders
이번에는 디코더가 가져오는 이점을 보여주기 위해 디코더 개수를 다르게 하여 연구하였다. 인코더와 비교하여 디코더가 성능이 크게 변하였다.
논문에서는 3개의 디코더를 쌓았을 때 성능이 가장 좋았다.
Ablations of the number of blocks
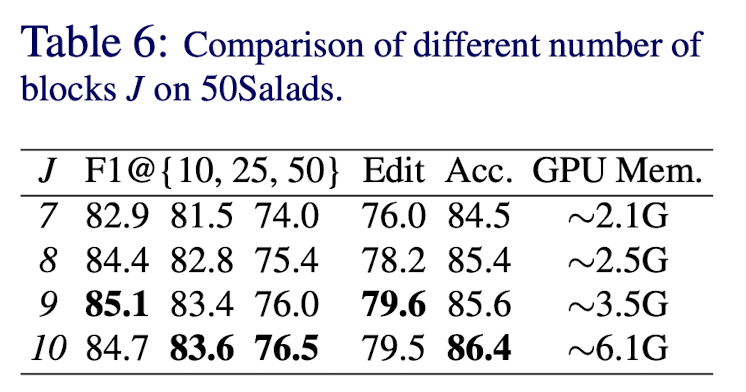
블럭 개수를 정하는 하이퍼파라미터는 더 넣은 receptive fields와 더 높은 메모리 비용을 발생시키기 때문에 중요하다.
그래서 블럭 개수를 다르게 하여 실험을 진행하였다.
블럭(J)가 9일때 가장 성능이 좋았다.
Comparison with SOTA


논문 읽는 멋진 여자! 오랜만에 논문을 만나니 재미있네요~^^ NLP 모델은 잘 몰라서 더 공부해야 완전히 이해하겠지만 CV에서도 쓰일 수 있게 변형시킨 게 신기하고 잘 읽었습니다~~