Bag-of-words
단어 등을 숫자형태로 나타내는 기법
Step 1. Vocabulary 구축
- 유니크한 단어들을 모아서 사전에 등록한다.
예시로 "John really really loves this movie","Jane really likes this song." 문장이 있다면
사전 Vocabulary에는 {"John","really","loves","this","movie","Jane","likes","song"}이 등록된다.
Step 2. Encoding
Categorical 데이터를 모델에 적용하기 위해 one-hot vector로 바꿔준다.
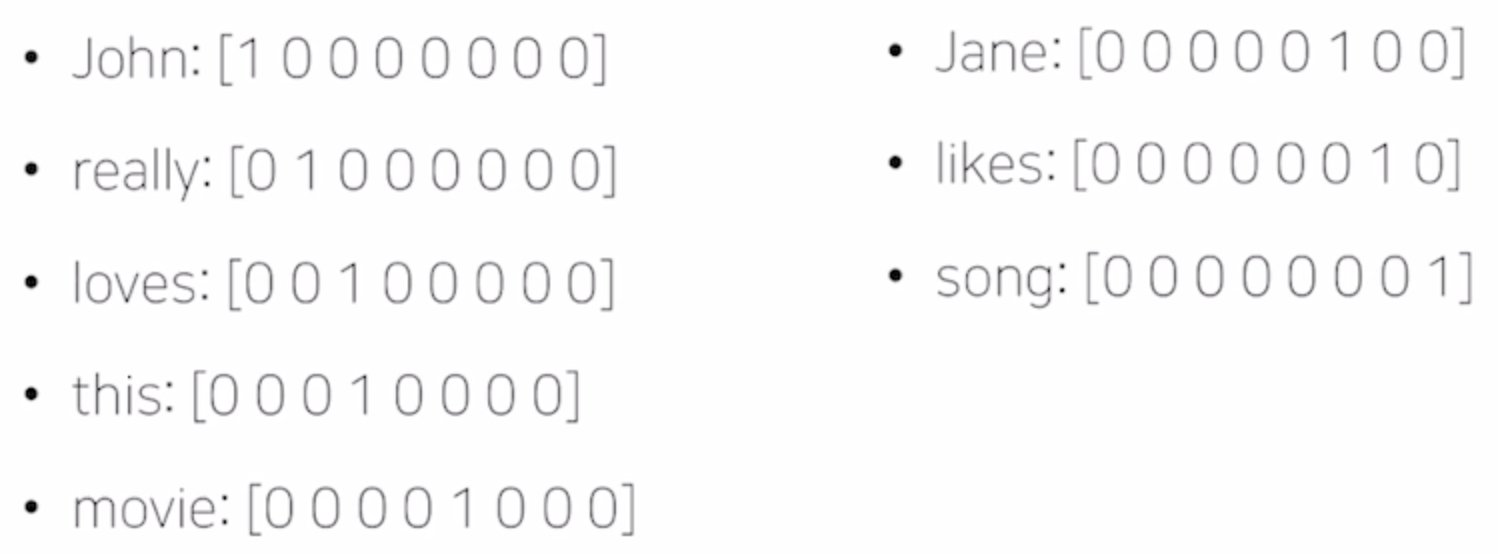
-> 어떤 단어쌍이든 유클리드 distance :
-> cosine 유사도 : 0
=> 의미에 상관없이 모두가 동일한 관계
Step 3. 확장
각 문장에 포함된 워드 벡터들을 합한다. -> Bag-of-Words

NaiveBayes Classifier
이제 위에서 표현한 벡터들을 이용해서 분류기를 생성한다.
Class : C
documet : d 이면
1) MAP : Maximum a posteriori
2) P(d)를 상수값으로 보고 무시한다.

여기서 P(C_cv) = P(C_nlp) = 1/2 이다
그리고 각 P(d|c)를 구하면 아래와 같다.
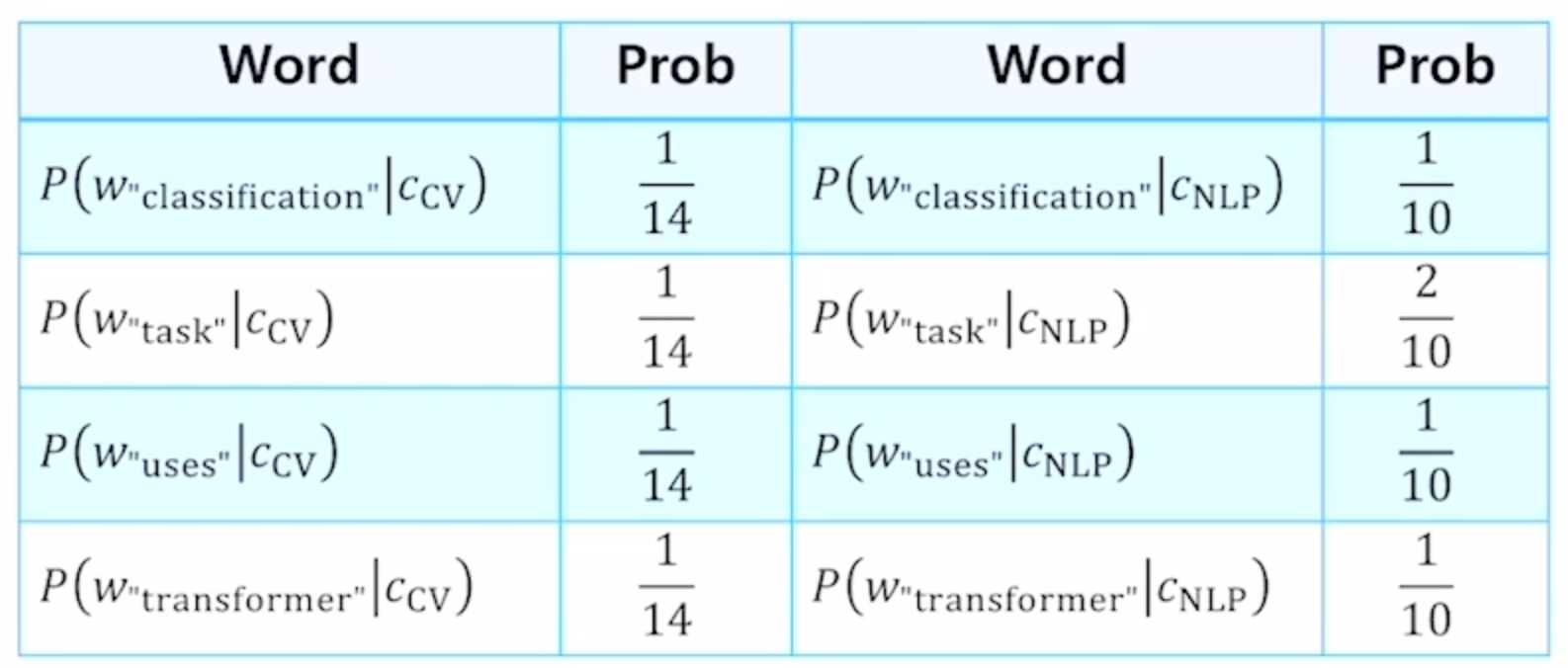
그래서 마지막 test 문장을 구하려면 아래와 같은 식을 세운다.
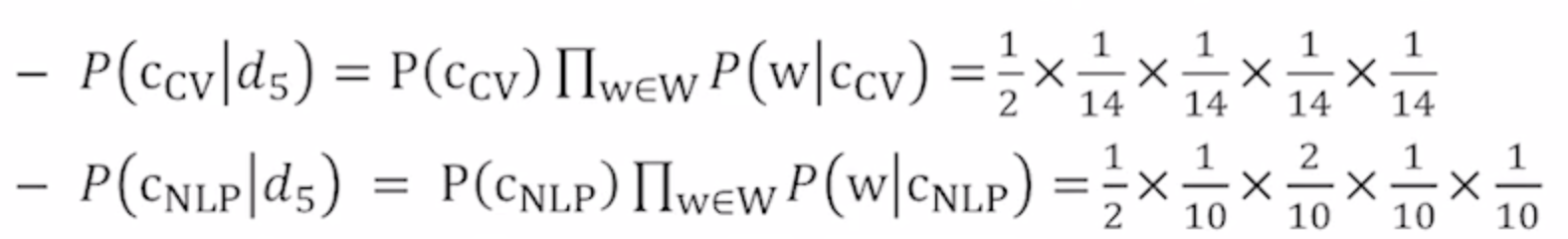
- 문제점 : 학습 데이터 안에서 특정 클래스 내에서 특정 단어가 나오지 않았을 경우 그 단어가 해당 클래스로 분류될 가능성이 0이 된다.

나는야 호기심 많은 느림보🤖
나이브 베이즈는 고전적인 text 분류기로 사용 됩니다.
나이브 베이즈의 가정 중 조건부 독립 때문에 두 사건이 발생할 때의 교집합을 신경쓰지 않고 바로 곱해도 됩니다.
그래서 순진하게(나이브) 확률을 믿는다고 해서 나이브 베이즈라고 불립니다!
나이브 베이즈의 좀 더 자세한 원리를 알아두시면 좋을 것 같습니다! (키워드: 조건부 독립)