NLP
1.Bag-of-Words & NaiveBayes Classifier | NLP
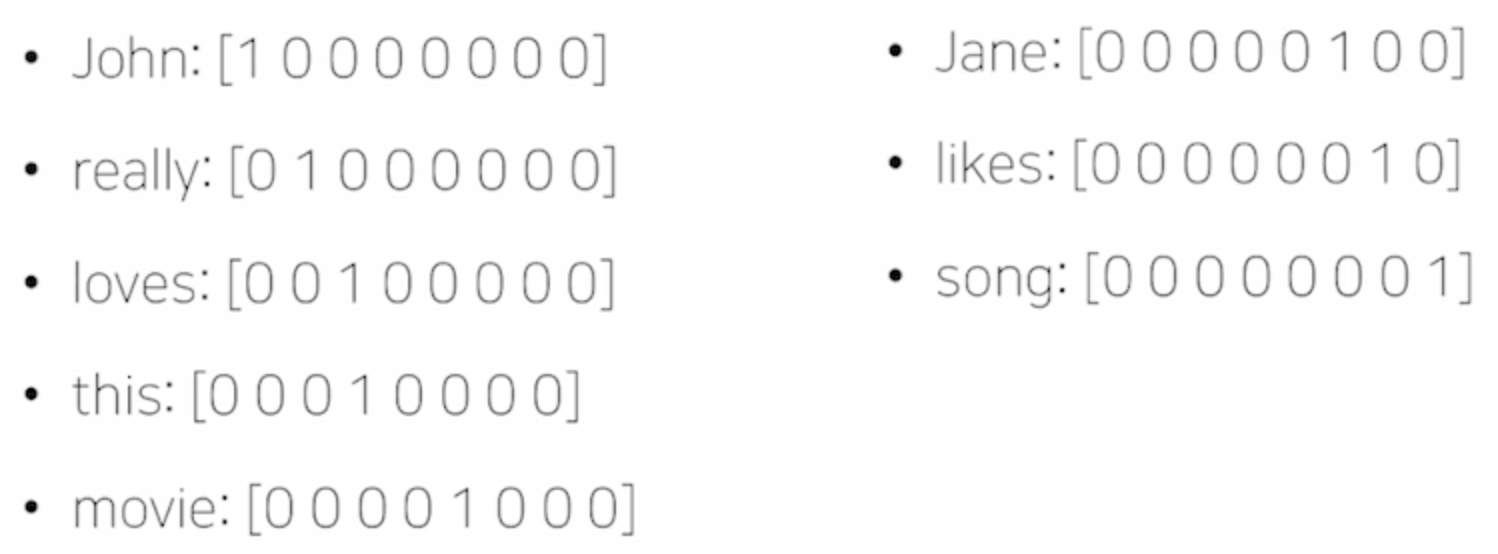
단어 등을 숫자형태로 나타내는 기법유니크한 단어들을 모아서 사전에 등록한다.예시로 "John really really loves this movie","Jane really likes this song." 문장이 있다면사전 Vocabulary에는 {"John","rea
2.Word Embedding | Word2Vec, GloVe
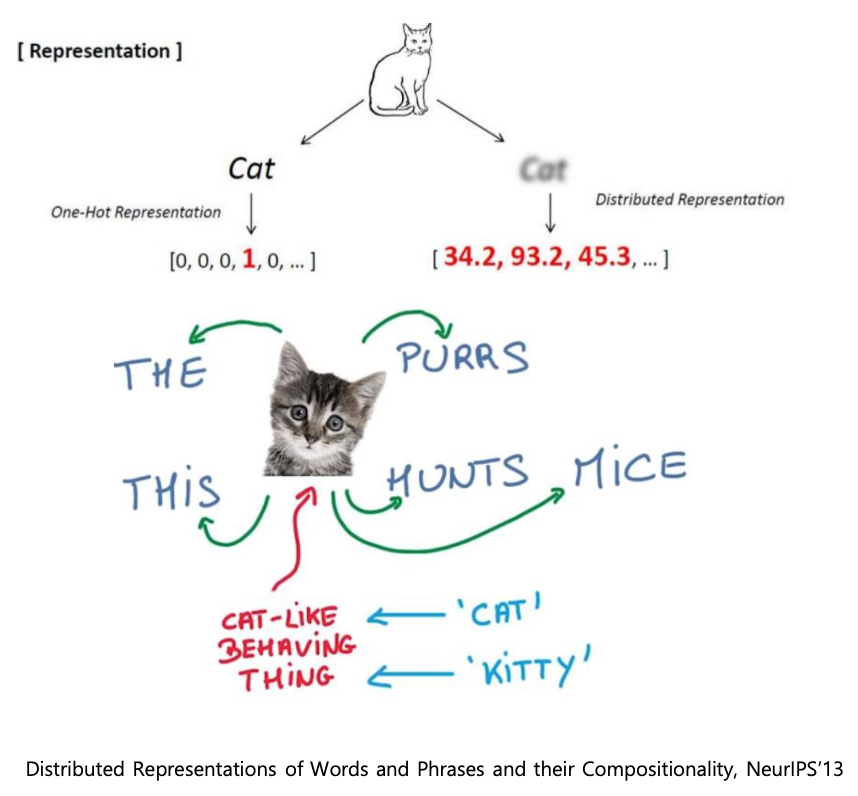
단어들을 특정한 차원으로 이루어진 공간 상의 한 점, 좌표로 변환해주는 기법text dataset을 학습 데이터로 제공하고dimension수를 사전에 정하여 알고리즘에 전달하면결과 값으로 각각의 단어의 최적의 벡터 표현형이 나온다.비슷한 단어는 가까운 공간에 표현되도록
3.Sequence-to-Sequence | Attention
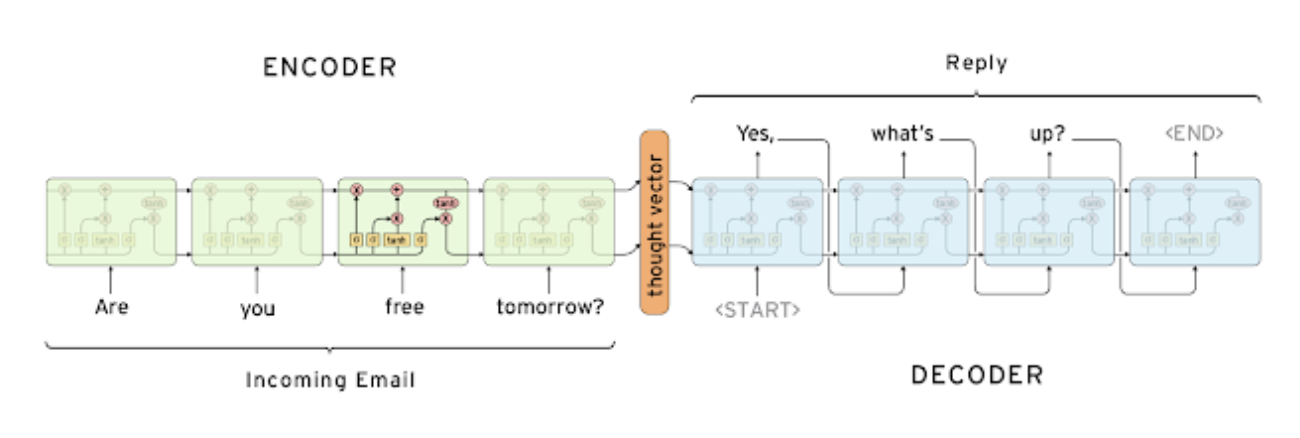
Sequence to Sequence 모델은 NLP 중 many-to-many 타입에 해당되는 모델이다인코더와 디코더로 구성되어 인코더는 input을 받고 디코더는 output을 낸다.서로 share하지 않는다.세부구조를 보면 여기서는 lstm을 선택한 것을 볼 수 있
4.Beam Search 알아보기
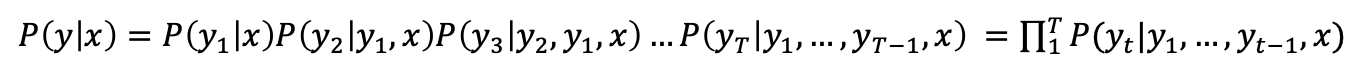
매 타임 스텝마다 높은 확률을 가지는 단어 하나만을 선택해서 진행한다.이를 Greedy decoding이라고 한다.알고리즘 공부했을 때 배운, 그리디 알고리즘처럼 당시 상황에서의 최선의 선택을 하기 때문에 앞에 Greedy가 붙은 것 같다.이 단점중 하나는 뒤로 못 돌
5.BLEU Score 알아보기
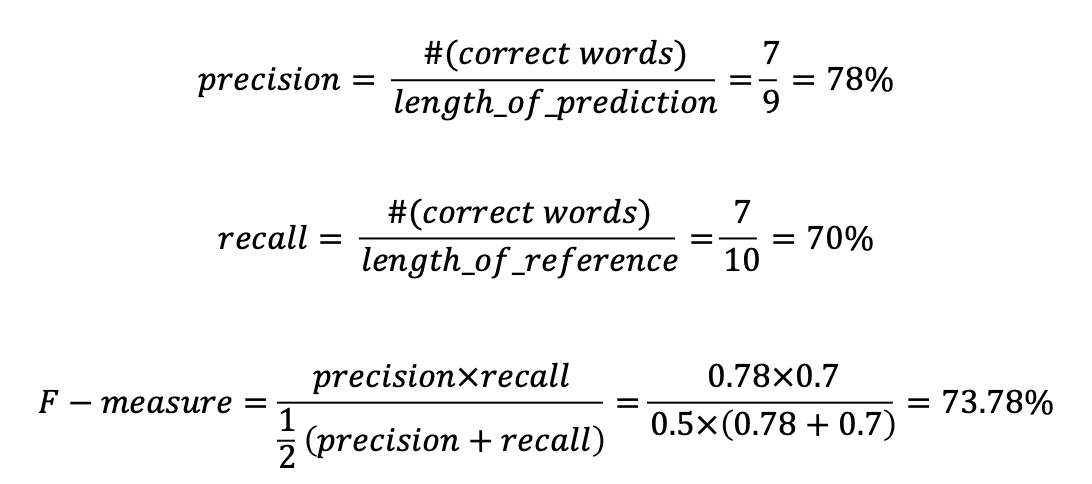
NLP 논문을 읽다보면 정말 자주 나오는 것 같다.우선 precision과 recall을 먼저 알고 넘어가야한다.이미지 분류 모델처럼 cross-entropy loss와 같이 일반적인 loss 방법들을 사용하면 NLP에서 맞지 않을 수 있다.가령 문장 생성 task에서
6.GPT-1 간단하게 알아보기
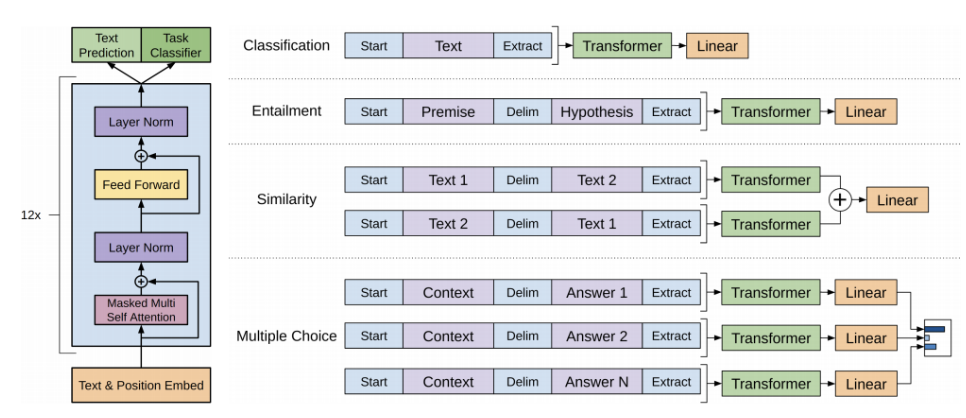
Open AI에서 개발한 모델로 다양한 자연어처리 task를 처리할 수 있는 통합된 모델이 중요한 특징이다.우선 Text를 position 임베딩을 더한다.self-attention 블럭을 12개 쌓는다.Text Prediction : 첫 단어부터 다음 단어까지 순차적
7.논문 속 RE Task 관련 데이터셋 이해하기 | TAC Relation Extraction Dataset | KLUE

RE 데이터셋을 구축하기 위해 RE 관련 논문 2개를 데이터셋 구축 위주로 보았다.Position-aware Attention Supervised Data Improve Slot filling 논문 안에 있는 내용이다.Slot filling 과제는 Subject 엔티티