
DALL-E
Intro.
이번 DALL-E 논문은 MultiModal task에 관심이 많아져서 읽고 싶었던 논문이다.
이미지 생성 모델답게 어려운 수식들이 있었지만 저걸 어떻게 하지?로 시작해서 어떤 아이디어로 이 모델이 학습되었구나를 알아가는 과정을 즐길 수 있었다.
이전에는 논문 형식을 지키면서 정리해온다는 느낌이었는데 이번에는 중요한 거 위주로 이해하기 쉽게 정리해보려고 한다.
paper : https://arxiv.org/pdf/2102.12092.pdf
DALL-E란?

DALL-E
- 120억 개 파라미터의 autoregressive transformer 모델(GPT-3 기반의 모델)을 2억 5천만 장의 이미지-텍스트 쌍으로 학습
- 데이터셋은 인터넷에서 수집하여 학습, 결과적으로 MS-COCO 데이터셋에서 추가 정보없이 zero-shot으로도 높은 성능을 보임
- Human Evaluation시 기존 모델보다 90% 더 높게 선호한다는 결과
- Image-To-Image translation에서도 기본적인 수행 능력을 가지는 것을 확인 가능(Image->Text->Image)
2 Stage 학습
문제점
DALL-E의 학습 목표는 텍스트와 이미지 토큰을 하나의 시퀀스로 입력받아 트랜스포머를 학습시키는 것이다.
이 과정에서 트랜스포머의 연산량은 시퀀스 길이의 제곱에 비례하기 때문에 이미지의 픽셀별로 입력을 넣는 것은 엄청난 자원을 소비하는 것이다.
이 문제점으로 인해 2Stage로 진행된다.
전반적인 프로세스
전체적인 학습 프로세스는 joint distribution에 대한 ELB(evidence lower bound)를 최대화 하는 과정이다.
아래와 같이 식을 분해할 수 있다.(이미지 x, 캡션 y, 토큰 z)
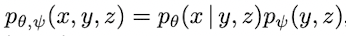
그리고 이 모델의 lower bound는 아래와 같다.(VAE의 ELB 식과 유사)

전반적인 진행과정은 텍스트와 이미지 토큰들이 들어가고 예측된 인덱스로 codebook에서 벡터를 꺼내 이미지 토큰에 추가시키고 이 과정이 결과 이미지를 생성할 때까지 계속 반복된다.

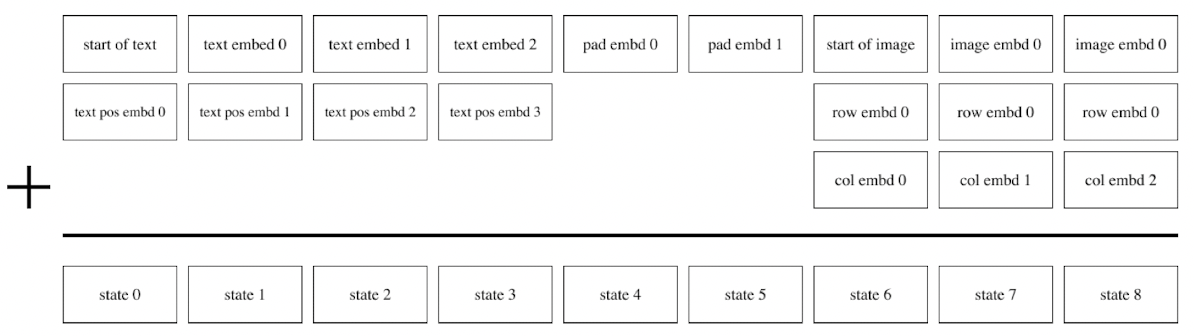
입력부분을 구체적으로 보면 아래처럼 start-of-text 스페셜 토큰으로 시작해서 text를 넣고 남은 부분은 padding으로 채운다.
이미지 입력 전에는 start-of-image 스페셜 토큰으로 시작해 임베딩된 이미지 토큰을 입력한다.
Stage 1: Learning the Visual Codebook
첫 번째 stage에서는 256x256 RGB 이미지를 32x32의 이미지 토큰으로 압축한다.
여기서 VQ-VAE에 대한 사전지식이 필요하다.
VQ-VAE에서는 위와 같이 이미지 토큰으로 자른 후 K개의 벡터가 들어있는 CodeBook에서 가장 가까운 하나로 대체하여 discrete한 이미지데이터에서 VAE를 이용한 학습을 보여준다.
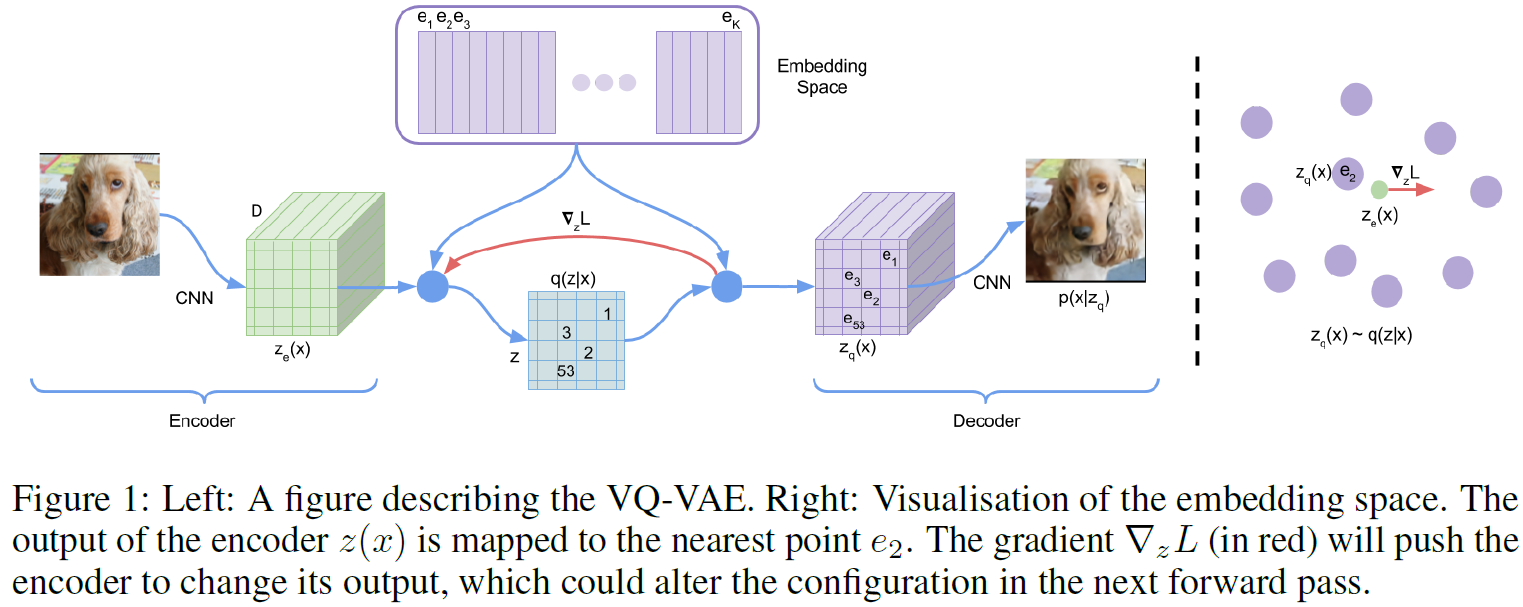
DALL-E에서도 K(codebook사이즈)는 8,192로 transformer를 고정한 상태로 discrete-VAE 인코더 와 디코더 를 학습한다.

위의 이미지가 original image이고 아래가 discrete VAE의 결과이다.
-> 디테일 손실은 보이지만 사물을 인식할 정도의 정보들은 남아있는 상태로 압축된다.
Discrete 데이터라서 발생하는 문제가 Back Propagation에서도 발생한다.
위에서 CodeBook에서 가장 가까운 값을 선택할 때, argmax를 이용해 인덱스를 선택하는 방식으로 진행하면 gradient를 구할 수 없다.
-> 그래서 gumble softmax relaxation을 이용하여 구해야한다. 여기서 temperature 는 0에 가까워질 수록 hard한 distribution을 만든다.
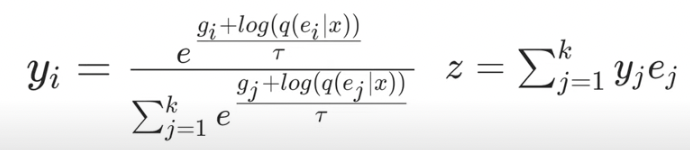
Stage 2
두 번째 stage에서는 256의 BPE-인코딩된 텍스트 토큰과 1,024(32x32)개의 이미지 토큰들을 concat하여 연속적으로 입력한다.
이번에는 discrete-VAE 인코더 와 디코더 를 고정한 상태로 트랜스포머 를 학습한다.
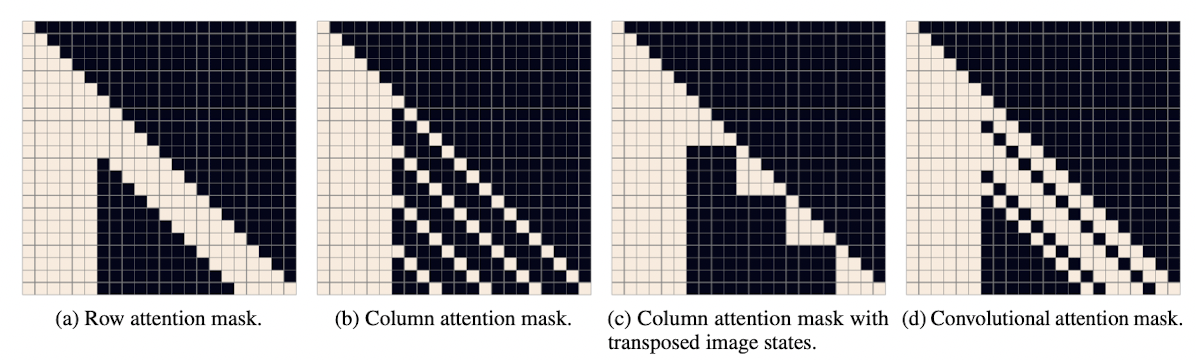
이 과정에서 아래와 같이 다양한 attention mask를 활용하며 모두 칸 6개는 모두 비워두어 text에 대해서는 항상 attention을 하고 이미지는 다양한 형태로 mask에 변형을 준다.
결과

N을 설정하여 N개의 다양한 이미지를 생성하고 CLIP사용해 k번째로 similarity가 높은 이미지를 선택한다.
이미지 출처 및 내용 참고
논문-https://arxiv.org/pdf/2102.12092.pdf
논문해설-https://youtu.be/CQoM0r2kMvI
