GPT-1
최근 NLP 블로그들이나 커뮤니티에서 GPT-3에 대한 많은 언급들을 보게되었다. 우리 팀원들과 무슨 논문을 읽을까에 대한 얘기가 나왔을 때 강력 추천해서 읽게 되었다ㅎㅎㅎ
Author: Alec Radford, OpenAI
Reading date: March 20, 2022
Summary: GPT-1
Improving Language Understanding by Generative Pre-training
Abstract
unlabeled 텍스트 corpus들은 많은 반면에 특정 task들에 맞는 labelded된 데이터는 희귀하다.
unlabeled 텍스트로 language model의 generative pre-training을 하고
각 task별로 다른 fine-tuning을 하면 많은 이득이 있다.
이전 접근들과 다르게, fine-tuning에서 task-aware 입력 transformation을 사용하여 효과적으로 전달할 수 있다. (+ 약간의 모델구조 변형)
이러한 방식으로 Natural Language Understanding 분야에서 다방면으로 높은 성능을 보여준다.
Introduction
raw text를 얼마나 효과적으로 학습할 수 있는 지는 supervised learning에 대한 의존도를 완화시키는데 중요하다.
대부분의 딥러닝 모델은 어느정도 충분한 labeled 데이터가 필요한데 이러한 데이터는 많은 도메인에서 적용하기 힘들다. 그래서 이러한 데이터를 이용해 가치있는 representation을 만든다. 이는 확실히 성능을 높여준다.
그러나 unlabeled text에서 단어단위를 넘는 효과를 얻기는 힘들다.
- 각기 다른 task마다 다양한 objectives를 가지기 때문에 효과적인 transfer를 위한 text representation을 최적화하려는 목표가 명확하지 않기 때문이다.
- 학습된 representation을 transfer하는 가장 효과적인 방법이 task마다 달라서 일치하지 않는다.
- 목표 : 다양한 task에 transfer 가능한 보편적인 representation을 학습
-
논문에서는 semi-supervised 접근을 보여준다 → (unsupervised pre-training + supervised fine-tuning)
-
unlabeled text + target task에 맞는 몇몇 datasets ( unlabeled corpus와 같은 도메인이라면 target task의 dataset 필요없음)
2-stage의 학습과정이 있다.
- unlabeled 데이터로 파라미터 초기화를 학습
- target task의 supervised objective에 맞게 파라미터 학습
-
모델 안에서 Transformer를 사용한다.
- 구조적인 메모리로 long-term dependencies를 효과적으로 다루기 위해 사용한다. rnn계열 모델에 비해 다양한 task에 대해 robust한 결과를 얻는다.
본 모델은
- natural language inference
- question answering
- semantic similarity
- text classification
이 4가지 타입의 NLU task를 평가하였다.
당시 12 task 중 9개에 SOTA를 달성하였다.
Related Work
Semi-supervised learning for NLP
본 논문의 모델은 semi-supervised learning에 속하며 이 분야는 sequence labeling이나 text classification과 같은 task에 잘 적용된다.
가장 먼저 supervised 모델 안에서 unlabeled data의 word-level 또는 phrase-level에 대해 연구하였다.
몇 년 후, 워드 임베딩의 이점들로 다양한 task의 성능이 올라갔다.
저자는 단어 이상의 전달을 하고자 했다. 당시 최근 연구들도 unlabeled 데이터에서 Phrase-level, sentence-level에 대한 연구가 되고 있었다.
Unsupervised pre-training
컴퓨터 비전 연구부터 pre-training에 대한 대한 연구를 보여줬었다. NLP분야에서도 언어적인 정보를 잡아내는 데 도움이 되는 pre-training LSTM 모델을 보여주었으나 RNN 계열 모델이기에 비교적 짧은 범위에서만 가능했다.
그래서 본 논문의 모델은 transformer를 선택하여 긴 범위에도 가능하게 하였으며, 뿐만 아니라 다양한 task도 가능하게 하였다.
Auxiliary training objectives
보조적인 unsupervised training objectives를 더하는 것은 semi-supervised learning의 변형 중 하나이다.
이전 연구에서 POS tagging과 같은 보조적인 language 모델링 objective를 추가하여 sequence labeling에서 성능 향상을 보여줬다.
본 논문의 모델도 보조적인 objective를 추가하는데, unsupervised pre-training은 이미 target task와 연관된 언어적 특성을 학습한다.
Framework
2-stage로 학습과정이 구성된다.
- Unsupervised pre-training
- Supervised fine-tuning
Unsupervised pre-training
unlabeled된 많은 corpus를 가진 Text로 높은 수용력을 가진 모델을 학습하는 과정이다.
→ likelihood를 maximize하기 위한 modeling objective
U = {u_1,...,u_n} : unsipervised corpus of tokens ( unlabeled 데이터 )
k : window size, P : conditional probability(파라미터 에 의해 만들어진다.)
→ 이 식은 이전 토큰들을
파라미터들은 확률적 경사하강법으로 학습된다.
- transformer를 변형한 multi-layer Transformer decoder를 사용한다.
- multi-headed self-attention 을 적용하였다.
- U = (u-k, ..., u-1) : context vector of tokens,
- n : 레이어 개수,
- W_e : 토큰 임베딩 matirx,
- W_p : position 임베딩 matrix
Supervised fine-tuning
실제 target task에 맞게 labeled 데이터를 가지고 fine-tuning하는 과정이다.
- → maximize하는 objective
- C : labeled 데이터, : 마지막 transformer 블럭을 얻기위해 pre-trained 모델을 지나온 이 과정에서의 입력 데이터, W_y : 추가된 output 레이어의 파라미터
위의 2개의 objective를 아래 식으로 하나로 합친다.
fine-tuning동안 추가되는 파라미터는 W_y와 토큰 구분을 위한 임베딩에서 뿐이다.
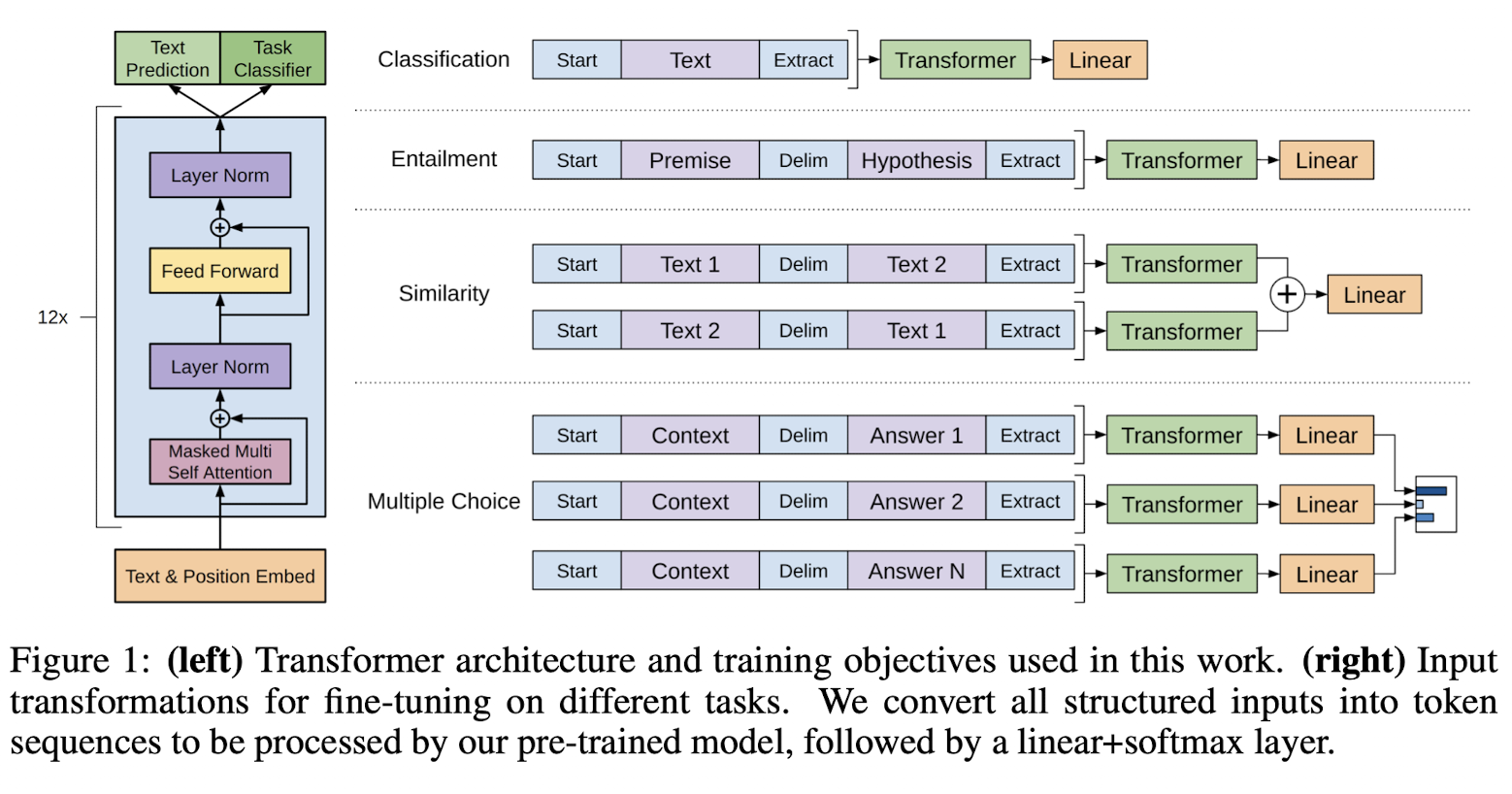
Task-specific input transformations
text 분류 task 같은 경우에는 앞 뒤에 start와 end token만 붙여 넣어주면 된다.
반면에 다른 task같은 경우에는 변형을 주고 넣어야 된다.
이전 연구에서는 task specific한 구조에 맞춰 넘겼기에 상관없지만 본 논문 모델에서는 pre-training 과정에서는 task를 고려하지 않기에 변형을 주어야한다.
structed input → ordered sequence로 pre-trained 모델이 바꿔준다. 이러한 변형으로 나중에 task에 맞게 fine-tuning하는 과정에서 많은 변화를 주지 않아도 된다.
Experiments
Setup
- Unsupervised pre-training
- BookCorpus dataset 이용
- 어드벤처, 판타지 로맨스를 포함한 다양한 장르의 7000 서로 다른 출판되지 않은 책이 있는 데이터 셋 → long-range 구조
- 1B Word Benchmark
- 대략 같은 사이즈지만 문장단위로 섞여있다. → long-range 구조 파괴
- 이 corpus에 대해 매우 낮은 perplexity ( 18.4 )
- Model specifications
- position-wise feed-forward 네트워크에서 3072차원의 inner states
- Adam optimizer ( max lr : 2.5e-4, 2000 iter까지는 선형적으로 0부터 증가하다가 consine 스케줄러로 0까지 그래프를 따라 바뀐다. )
- 64 mini-batch로 랜덤하게 샘플링하여 100 epoch 학습
- Layernorm에서는 가중치 초기화 N(0,0.2)
- 40000dml BPE vocabulary
- 드롭아웃 0.1
- 변형된 L2 regulariation
- Gaussian Error Linear Unit(GELU) - activation function
- Fine-tuning
- unsupervised learing의 하이퍼 파라미터 재사용
- classifier의 드롭아웃 0.1
- 3 epoch정도 학습
- 배치사이즈 32, lr : 6.25e-5
- learning rate decay 스케줄 ( warmup 0.2%, lambda : 0.5 )
Supervised fine-tuning
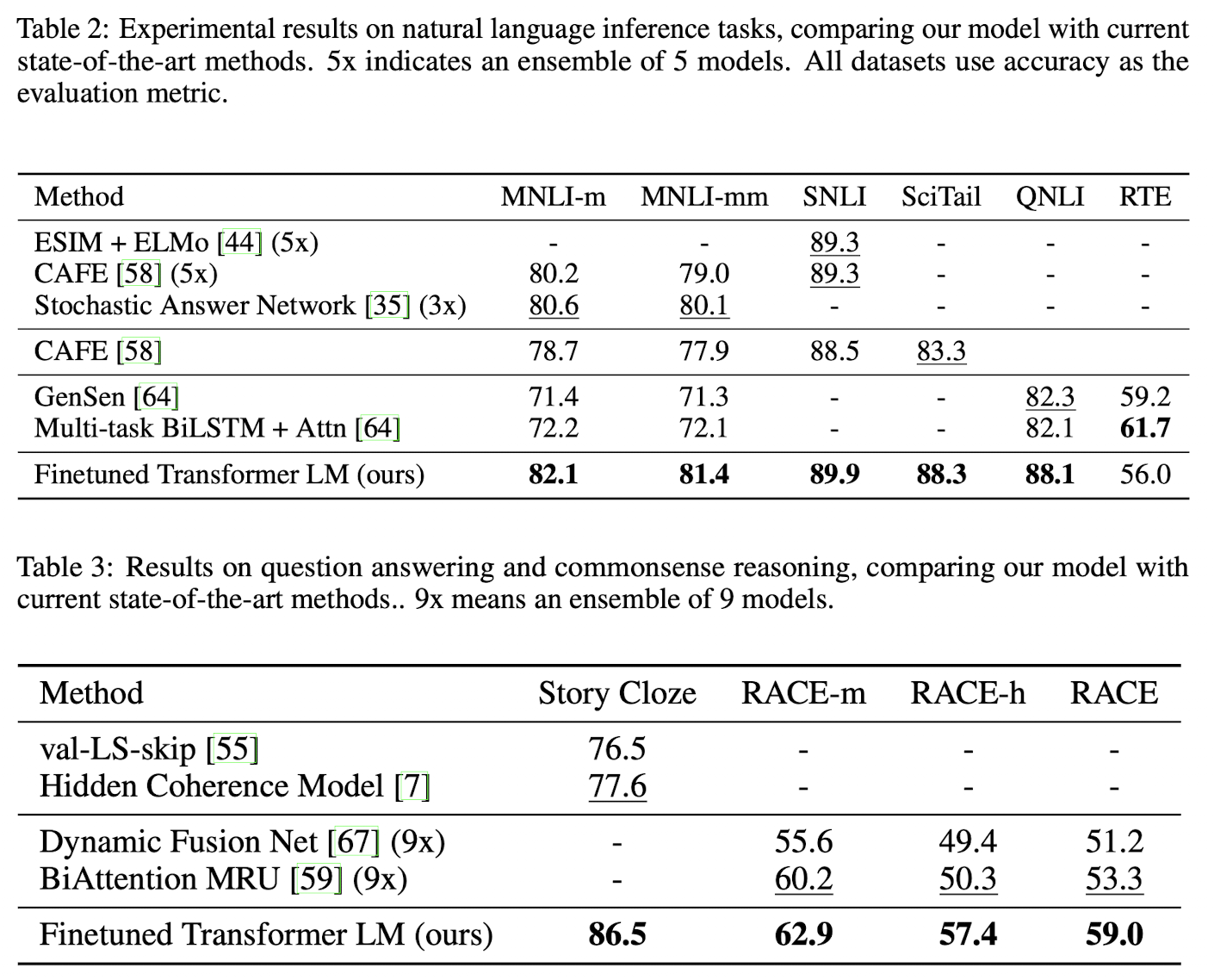
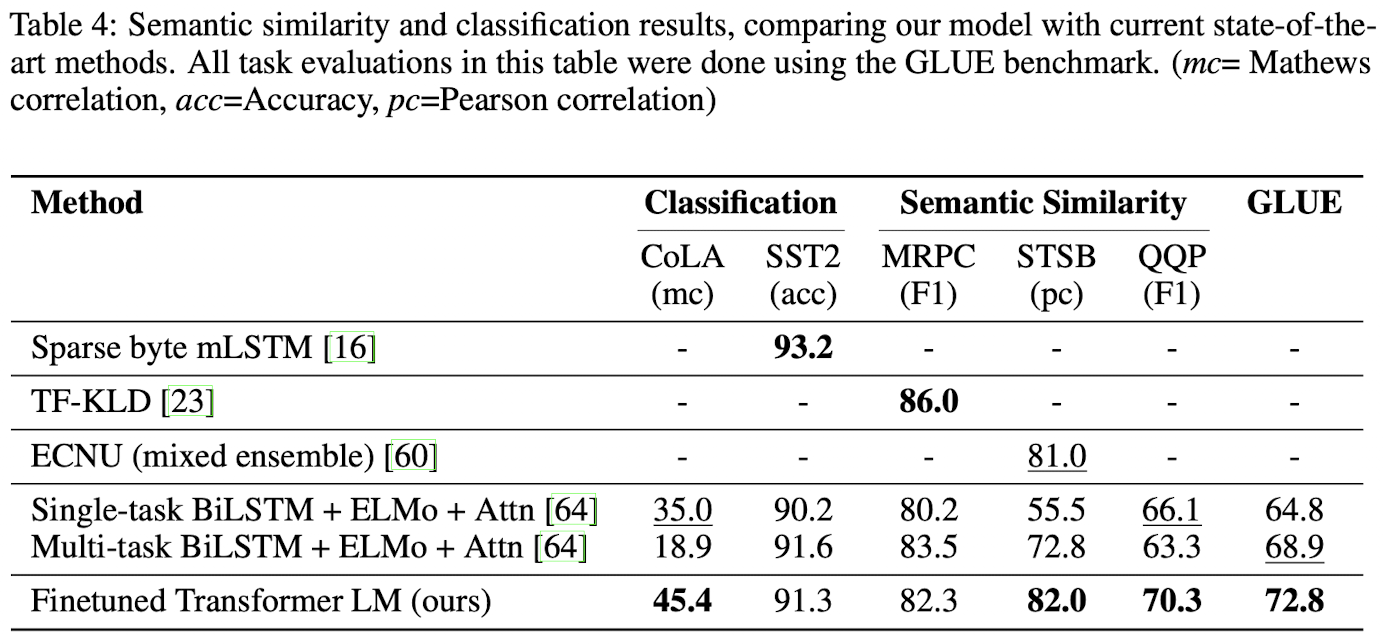
- NLI, QA & commonsense reasoning, Semantic Similarity, Classification 많은 dataset에서 SOTA 달성
Analysis
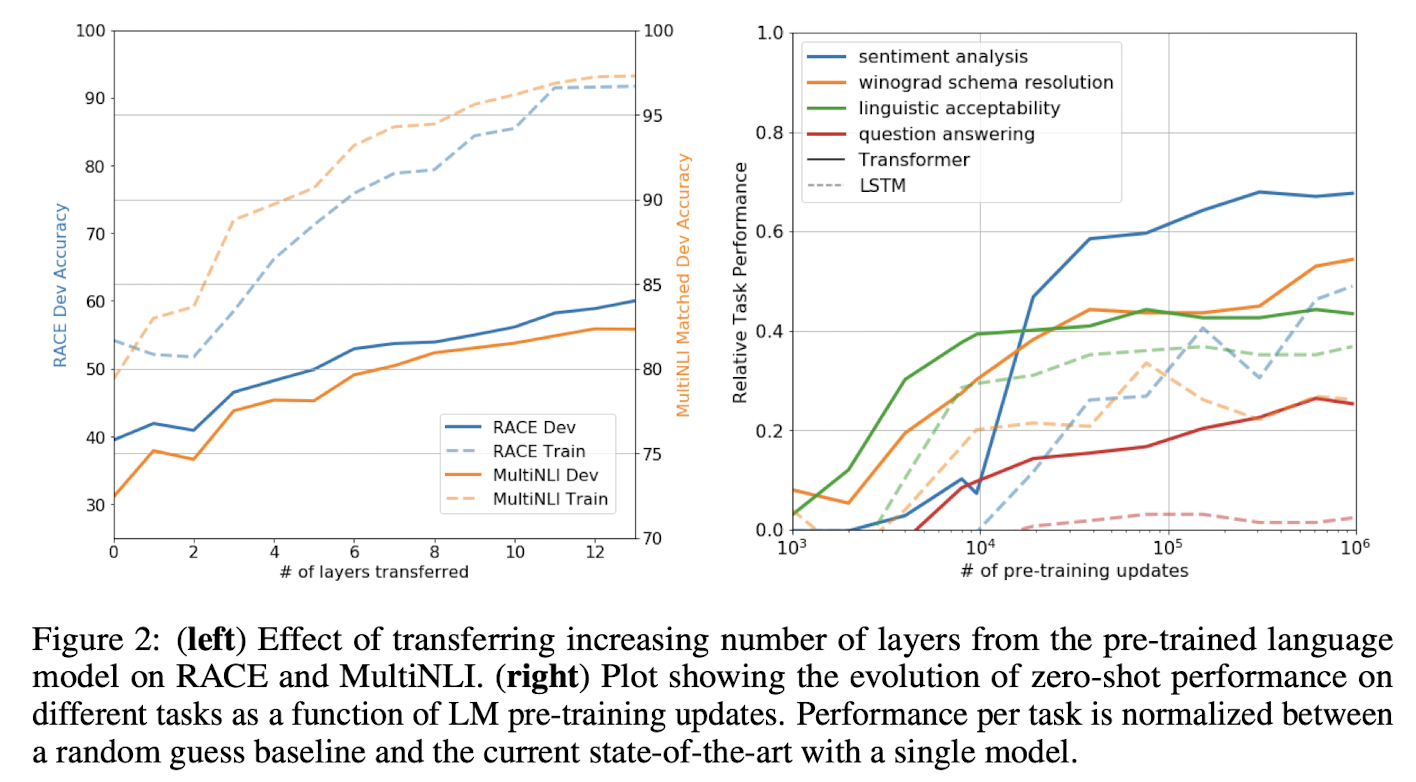
- transfer할 때의 layer 개수에 따른 성능을 그래프로 보여준다. → 층의 개수가 많아질수록 성능이 좋아지는 것을 볼 수 있다. → update를 많이 할 수록 전체적으로 성능이 좋아지는 것을 볼 수 있다. ( 다양한 NLP task를 위한 다양한 특성 학습 )
Ablation studies
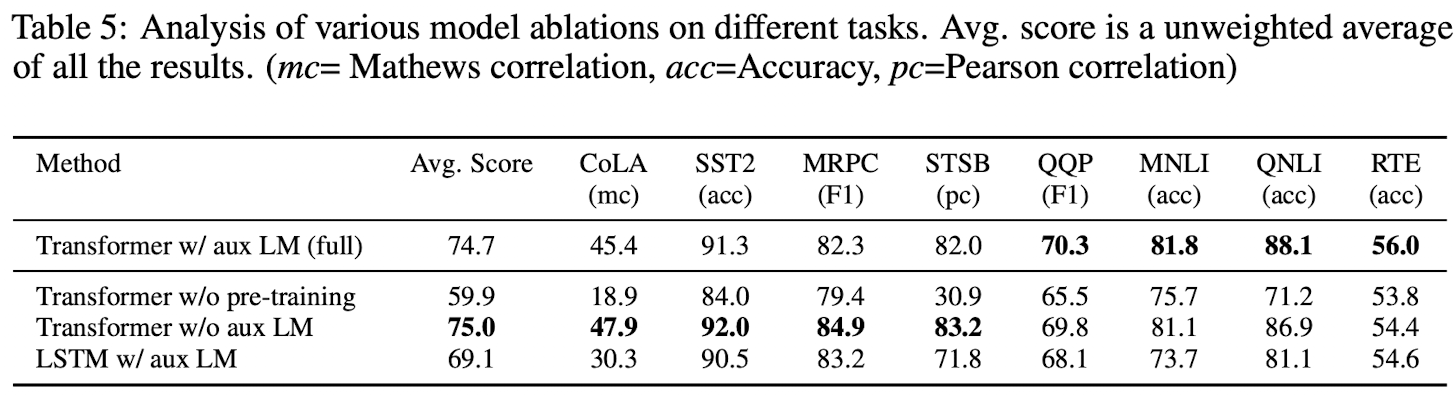
3가지 다른 연구 진행
- w/o 보조적인 LM
- 보조적인 objective는 NLI task와 QQP에 도움을 준다.
- 큰 데이터셋에 좋다.
- LSTM과 Transformer 비교
- LSTM에서 평균 5.6의 성능이 더 떨어진다.
- pre-training하지 않았을 때도 비교해 보았을 때, 논문의 모델 성능이 더 좋았다.
마무리
내가 이번 논문으로 Transformer의 대단함과 비교적 NLP에서 더 Input transformation처럼 실제 학습이 진행되기 전까지의 전처리 과정이 중요한 것 같다는 생각이 들었다.
생각보다 모델 안의 구조가 단순해서 놀랐으며 마지막 output layer를 조금 더 복잡한 형태나 task specific하게 바꾸면 성능이 더 오를 수도 있지 않을까....?하는 작은 의문이 들었다.
이후 GPT-2,3도 읽을 예정인데, 앞으로 어떠한 단점을 가지고 변화하였을 지 궁금하다.
