PyGAD를 활용해서 NN을 훈련 후, regression 문제를 해결하는 두번째 포스팅입니다.
우리가 양식장을 운영한다고 가정합니다. 물고기를 마켓에 판매하기 위해, 우리는 양식장의 물고기 무게정보를 마켓에 전달해주어야 합니다. 양식장의 물고기는 여러가지 길이를 가지고 있을 것입니다. 예를 들면, 머리부터 지느러미까지의 길이, 머리부터 꼬리까지의 길이, 몸통 길이 등 다양한 기준으로 물고기의 길이를 체크할 수 있습니다. 이 물고기 신체 데이터를 가지고, 우리는 물고기의 weight를 예측하고자 합니다. 물론 한마리 물고기 가지고는 예측이 힘들겠지만, 수백마리, 수만마리의 물고기 데이터를 이용해서는 어느정도 표준화 가능하게 될 것입니다.
이 예시를 통해, 이번 포스팅에서는 물고기 길이 (inputs)을 가지고 물고기의 weight(output)를 예측하는 예시입니다. 물고기의 무게는 물고기의 길이정보, 몸통 길이, 너비 길이를 통해 결정된다는 사실을 가정합니다.
우선 라이브러리를 준비해줍니다.
!pip install pygad==2.17.0
import numpy
import pygad
import pygad.nn
import pygad.gann
import pandas
from sklearn.preprocessing import MinMaxScalerTraining Dataset 준비
물고기 데이터정보는 csv 파일로 준비 되어있습니다. 데이터 구성은 다음과 같습니다.
데이터를 확인해보면, 데이터가 normalization 처리가 되어있지 않아 범위들이 들쑥날쑥하기 때문에, 데이터에 normalization처리 해줍니다. Normalization 방법은 여러가지가 있지만, 이번 포스팅에서는 Min-Max Normalization 메소드로 진행했습니다.
data_not_norm = pandas.read_csv("Fish_v1.csv")
data=data_not_norm.copy()
for column in data_not_norm.columns[1:]:
data[column] = (data_not_norm[column] - data_not_norm[column].min()) / (data_not_norm[column].max() - data_not_norm[column].min())
# view normalized data
data_norm = numpy.array(data)
data=data_norm.copy()표준화 전:
Species Weight Length1 Length2 Length3 Height Width
0 Bream 242.0 23.2 25.4 30.0 11.5200 4.0200
1 Bream 290.0 24.0 26.3 31.2 12.4800 4.3056
2 Bream 340.0 23.9 26.5 31.1 12.3778 4.6961
3 Bream 363.0 26.3 29.0 33.5 12.7300 4.4555
4 Bream 430.0 26.5 29.0 34.0 12.4440 5.1340
5 Bream 450.0 26.8 29.7 34.7 13.6024 4.9274
6 Bream 500.0 26.8 29.7 34.5 14.1795 5.2785
7 Bream 390.0 27.6 30.0 35.0 12.6700 4.6900
8 Bream 450.0 27.6 30.0 35.1 14.0049 4.8438
9 Bream 500.0 28.5 30.7 36.2 14.2266 4.9594표준화 후:
Species Weight Length1 Length2 Length3 Height Width
0 Bream 0.143604 0.304854 0.309091 0.358108 0.568334 0.418978
1 Bream 0.1728 0.320388 0.325455 0.378378 0.624055 0.459235
2 Bream 0.203211 0.318447 0.329091 0.376689 0.618123 0.514279
3 Bream 0.217201 0.365049 0.374545 0.41723 0.638566 0.480365
4 Bream 0.257953 0.368932 0.374545 0.425676 0.621966 0.576004
5 Bream 0.270117 0.374757 0.387273 0.4375 0.689203 0.546882
6 Bream 0.300529 0.374757 0.387273 0.434122 0.722699 0.596372
7 Bream 0.233623 0.390291 0.392727 0.442568 0.635084 0.513419
8 Bream 0.270117 0.390291 0.392727 0.444257 0.712565 0.535098
9 Bream 0.300529 0.407767 0.405455 0.462838 0.725433 0.551393# Preparing the NumPy array of the inputs.
data_inputs = numpy.asarray(data[:35, 2:], dtype=numpy.float32)
# Preparing the NumPy array of the outputs.
data_outputs = numpy.asarray(data[:35, 1], dtype=numpy.float32)num_inputs = data_inputs.shape[1] #5pygad.gann.GANN class의 인스턴스 생성
num_solutions = 100 # A solution or a network can be used interchangeably.
GANN_instance = pygad.gann.GANN(num_solutions=num_solutions,
num_neurons_input=num_inputs,
num_neurons_hidden_layers=[10],
num_neurons_output=1,
#hidden_activations=["sigmoid"],
hidden_activations=["relu"],
output_activation='relu')Population Weights를 벡터화
population_vectors = pygad.gann.population_as_vectors(population_networks=GANN_instance.population_networks)
initial_population = population_vectors.copy()Fitness Function 정의
Fitness Function을 Mean Absolute Error (MAE)로 정의합니다 (MAE: real data - prediction data).
def fitness_func(solution, sol_idx):
global GANN_instance, data_inputs, data_outputs
predictions = pygad.nn.predict(last_layer=GANN_instance.population_networks[sol_idx],
data_inputs=data_inputs, problem_type="regression")
solution_fitness = 10-numpy.mean(numpy.abs(predictions - data_outputs))
#solution_fitness = 1/numpy.mean(numpy.abs(predictions - data_outputs))
return solution_fitnessGeneration Callback Function 정의
last_fitness = 0
def callback_generation(ga_instance):
global GANN_instance, last_fitness
population_matrices = pygad.gann.population_as_matrices(population_networks=GANN_instance.population_networks,
population_vectors=ga_instance.population)
GANN_instance.update_population_trained_weights(population_trained_weights=population_matrices)
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
print("Change = {change}".format(change=ga_instance.best_solution()[1] - last_fitness))
last_fitness = ga_instance.best_solution()[1].copy()pygad.GA class를 활용하여 인스턴스 생성
num_parents_mating = 80 # Number of solutions to be selected as parents in the mating pool.
num_generations = 100 # Number of generations.
mutation_percent_genes = 0.05 # Percentage of genes to mutate. This parameter has no action if the parameter mutation_num_genes exists.
parent_selection_type = "sss" # Type of parent selection.
crossover_type = "scattered" # Type of the crossover operator.
mutation_type = "random" # Type of the mutation operator.
keep_parents = -1 # Number of parents to keep in the next population. -1 means keep all parents and 0 means keep nothing.
sol_per_pop=num_solutions
init_range_low = -4
init_range_high = 4ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
mutation_percent_genes=mutation_percent_genes,
init_range_low=init_range_low,
init_range_high=init_range_high,
parent_selection_type=parent_selection_type,
crossover_type=crossover_type,
mutation_type=mutation_type,
keep_parents=keep_parents,
sol_per_pop=sol_per_pop,
callback_generation=callback_generation)GA 실행
ga_instance.run()output:
Generation = 1
Fitness = 9.686440101422606
Change = 9.686440101422606
Generation = 2
Fitness = 9.680182672179413
Change = -0.006257429243193613
Generation = 3
Fitness = 9.799329752325686
Change = 0.11914708014627351
...
Generation = 100
Fitness = 9.88982629805265
Change = 0.0Plot results 확인
ga_instance.plot_result()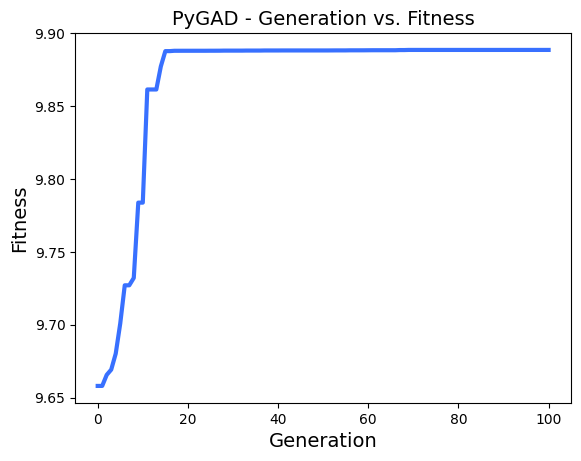
Best Solution 정보
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))output:
Fitness value of the best solution = 9.888717427132542
Index of the best solution : 0if ga_instance.best_solution_generation != -1:
print("Best fitness value reached after {best_solution_generation} generations.".format(best_solution_generation=ga_instance.best_solution_generation))output:
Best fitness value reached after 90 generations.Trained Weights를 사용해서 분류 예측
NN을 훈련할 때 데이터의 일관성을 위해서 데이터 전처리 과정인 표준화처리를 해서 데이터 범위를 0~1사이로 조정했었습니다. 하지만 실제 예측하고자 하는 weight 값은 표준화처리를 제거해주어야 합니다. Normalization을 없애서 실제 예측값을 얻습니다.
##Min and max of the weights
min_weight=data_not_norm[data_not_norm.columns[1]].min()
max_weight=data_not_norm[data_not_norm.columns[1]].max()
# Predicting the outputs of the data using the best solution.
predictions_before = pygad.nn.predict(last_layer=GANN_instance.population_networks[solution_idx],data_inputs=data_inputs,problem_type="regression")
#predictions=predictions_before*(max_weight-min_weight)
predictions = [element * (max_weight-min_weight) for element in predictions_before]
print("Predictions of the trained network : {predictions}".format(predictions=predictions))output:
Predictions of the trained network : [array([410.93740273]), array([448.35813349]), array([471.02756228]), array([461.1890567]), array([516.10915732]), array([511.50102095]), array([544.16529798]), array([488.84226813]), array([518.49023402]), array([537.77022318]), ...통계 계산
data_outputs_real=data_outputs*(max_weight-min_weight)
abs_error_percent = numpy.mean(numpy.abs(predictions - data_outputs_real))
print("Prediction error : {abs_error}.".format(abs_error=abs_error_percent))
print("data_outputs",data_outputs_real)output:
Prediction error : 182.9596703358191.
data_outputs [236.09999 284.1 334.1 357.1 424.1 444.1 494.09998
384.1 444.1 494.09998 469.1 494.09998 494.09998 334.1
594.1 594.1 694.1 694.1 604.1 644.1 569.1
679.1 614.1 674.1 694.1 719.1 714.1 708.1
844.1 994.1 914.1 949.10004 919.10004 969.10004 944.1 ]이렇게 PyGAD를 활용해서 Classification과 Regression 문제를 다뤄봤습니다.

이전 Regression(1)도 그렇고 여기에서도 callback_generation 인수를 못 불러온다는데 어떻게 해결하는 건가요...? 아래와 같이 뜹니다 ㅠ
TypeError: GA.init() got an unexpected keyword argument 'callback_generation'