
오늘의 목표
- 범죄파트 끝내기
오늘의 달성목표
- 범죄파트 3 끝내기
오늘을 마치며
- 요즘 수업에 대한 집중도와 열의가 점점 떨어지고 있는거 같다.
그래서 진도가 점점 밀리고 있는데, 마음을 다잡아야 할거 같다. 나 스스로 극복하는거 말고는 방법이 없으니 말이다. 화이팅하자!!! 거북이처럼 느리지만 결승전까지 지치지 않고 달려가야지.
4/17일 월요일
8. 범죄 데이터 정렬을 위한 데이터 정리
8-1) 평균화 : 최고값은 1, 최소값은 0
crime_anal_gu['강도'] / crime_anal_gu['강도'].max()
np.mean()
- numpy의 나눗셈값이다.
- numpy에서는 axis=1 행, axis=0 열 pandas와 반대이다.
8-2) 검거율 추가
8-3) 구별 CCTV 자료에서 인구수와 CCTV수 추가
8-4) 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
8-5) 검거율 평균을 구해서 검거 컬럼의 대표값으로 사용
Seaborn
예제1 : seaborn 기초
- sns.set_style()
- white', 'whitegrid', 'dark', 'darkgrid', 'ticks'
예제2: seaborn tips data
- boxplot
- swarmplot
- lmplot
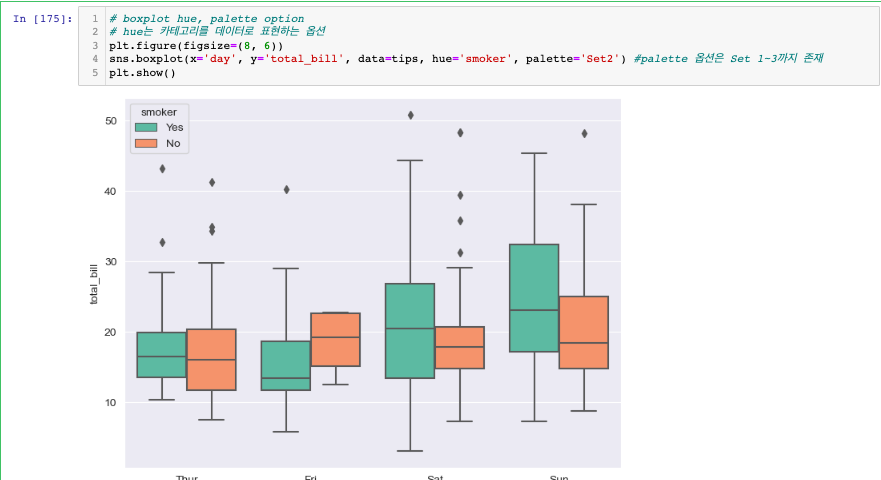
boxplot
- hue, palette 옵션 사용 가능
- hue는 카테고리를 데이터로 표현하는 옵션
- palette 옵션은 Set 1~3까지 존재
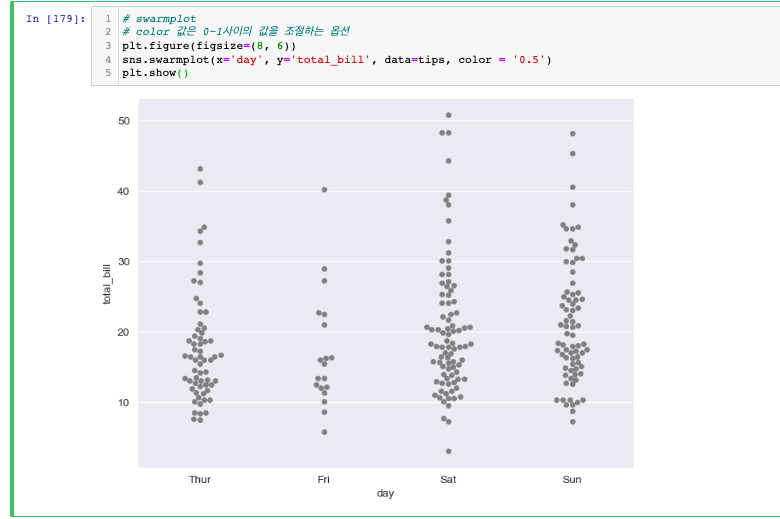
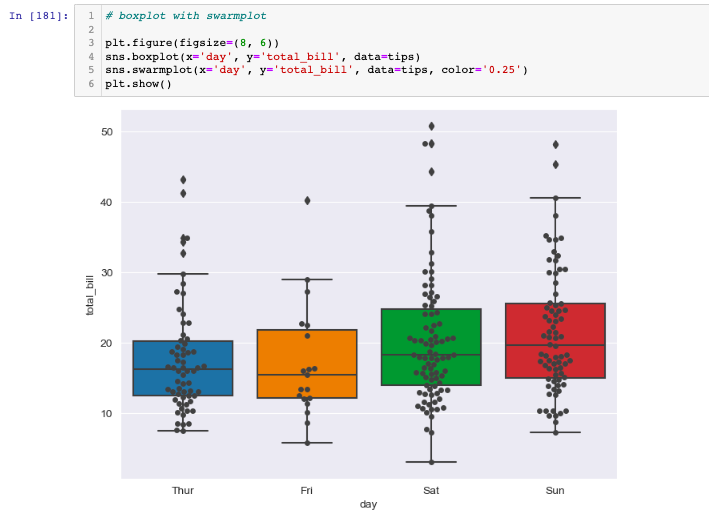
swarmplot
- color 값은 0~1사이의 값을 조절하는 옵션
lmplot
- total_bill과 tip 사이 관계 파악
- hue 옵션을 통해 카테고리를 나눌 수 있음(ex: 남자/여자)
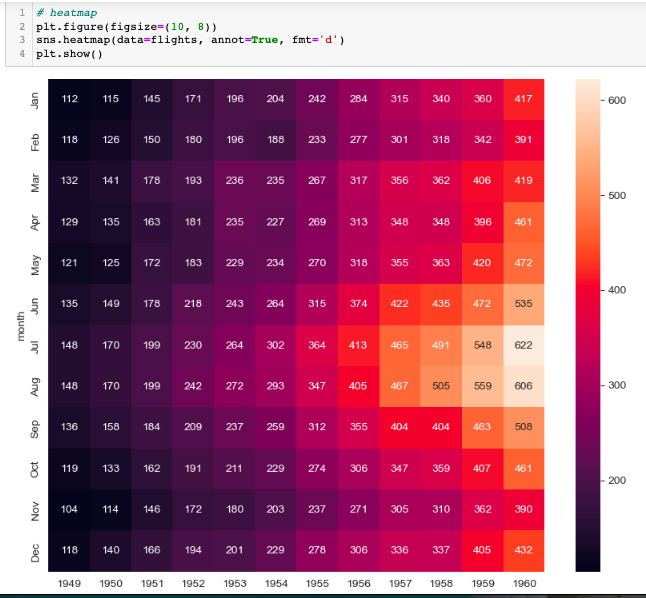
예제3: flights data
- heatmap으로 표시
- pivot으로 데이터 정리(index, columns, values)
- annot=True는 데이터 값을 표시, fmt='d'는 정수형을 표시
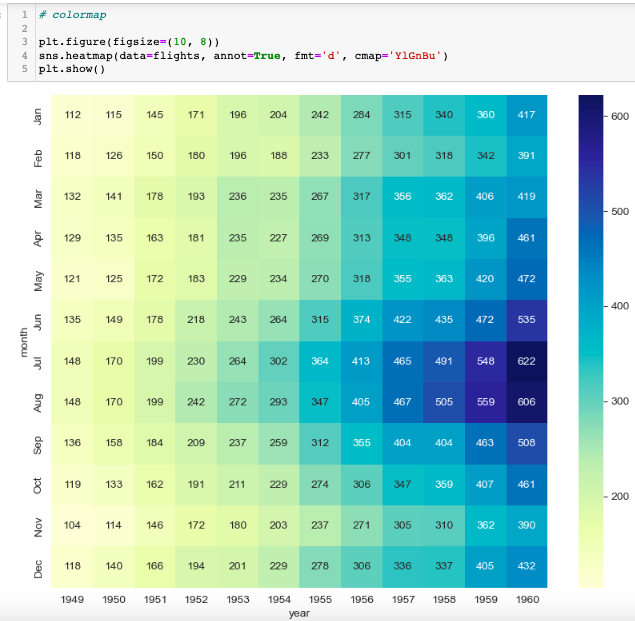
- colormap을 이용하여 히트맵 색상을 변경할 수 있음
예제4: iris data
- pairplot
- sns.set_style('ticks')
sns.pairplot(iris)
plt.show() 를 통하여 모든 데이터의 차트를 나타낼 수 있음
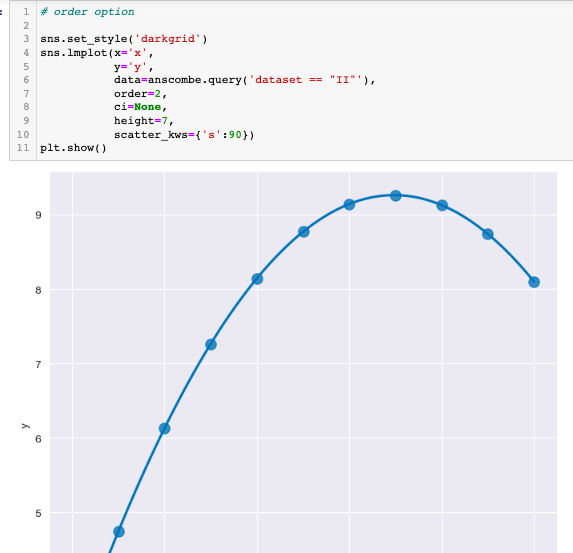
예제5: anscombe data
- lmplot
- data=anscombe.query('dataset == "I"'를 통해 원하는 데이터만 출력 가능
- order를 통해 데이터 값에 맞는 출력가능
- robust=True를 통해 outlier데이터 무시 가능
[본 내용의 글 중 일부는 제로베이스 데이터스쿨 강의 자료 중 일부에서 발췌한 내용이 포함되어 있습니다. ]

또 다른 나를 찾아서