[CS231N] Introduction to Convolutional Neural Networks for Visual Recognition
Study Memo - CS231N

1강. Introduction to Convolutional Neural Networks for Visual Recognition
Computer Vision의 역사와 CS231N 강의의 전반적인 내용을 가볍게 흝어보는 내용이었습니다.
CS231N - 1강
- History of Computer Vision
- CS231N Overview
History of Computer Vision
Computer Vision은 Camera Obscura부터 서서히 발전해왔고, 2000년대 초반 ML(Machine Learning)의 재조명, 이미지 품질 향상 등으로 인해 그 기술 수준이 나날이 높아지고 있습니다.
16~20세기
Camera Obscura(16세기)
좁은 구멍에 빛을 투사해 그 반대편에 목표 사물과 반대 방향으로 상이 맺히도록 하는 Pinhole의 원리를 이용한 방법론으로 동물의 눈이 사물을 인식하는 것과 유사합니다.
Stage of Visual Representation(19세기)
David Marr이 그의 저서 "Vision"에서 언급한 내용으로 사물의 인식 과정과 Computer Visualizing의 과정을 4단계로 나누어서 제시한 것입니다.
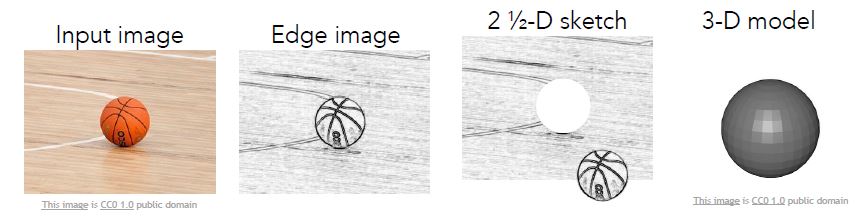
Step 1. Input Image
인식하고자 하는 사물 등의 이미지를 카메라 등으로 입력받습니다.
Step 2. Primal Sketch
Edge(경계), Curve(곡선), Boundaries(범위) 등 입력받은 이미지에서 2D 요소들을 인식합니다.
Step 3. 2-1/2-D Sketch
해당 목표물이 Surface(표면)과 어느 정도의 거리를 가지고 있는지 인식하고, 표면에서 분리합니다.
Step 4. 3D Model Representation
해당 목표물의 Surface(표면)과 Volumetric(용적)에 따라 계층적으로 3D 모델링합니다.
Generalized Cylinder & Pictoral Structure(20세기)
목표 대상을 여러 개의 원통으로 표현하거나, 피사체의 관절부나 경계 부분을 이어서 스켈레톤처럼 표현하는 방법론입니다.
Normalized Cut(20세기)
피사체를 있는 그대로 인식하는 것이 아니라 같은 대상을 가리키는 이미지 상 범위에 대해 표면 형태, 질감 등을 배제하고 같은 색으로 표시해 서로 다른 대상을 분리하는 방법론입니다. (Semantic Segementation과 유사합니다)
21세기~현재
Face Detection(21세기)
Machine Learning 기반으로 서로 다른 인물의 얼굴 범위를 인식하고 각 범위 내의 얼굴을 다르게 인식하는 기술입니다.
SIFT Object Recognition(21세기)

기준 피사체의 각 부분이 비교 피사체의 어떤 부분에 해당하는 지를 판단하는 SIFT를 통해 서로 다른 각도와 위치의 대상이라도 비교할 수 있는 기술입니다.
Pascal Visual Object Challenge(21세기)
보다 다양한 이미지에 대해 Classifiacation을 수행할 수 있도록 기차, 비행기 등 20개의 Class의 이미지 데이터에 대해 정확도를 높히는 프로젝트였습니다.
Imagenet Challenge(21세기)
Overfit
: Classification이 학습 데이터에 지나치게 적합해 일반적인 데이터에 대해서 범용적으로 사용이 어려운 딜레마
Overfit 문제가 발생해 다량의 Class에 대해 다량의 데이터를 확보하도록 14M개의 이미지 데이터를 모은 프로젝트로 2010~2015년까지의 분류 성능 개선으로 일반적인 인간의 정확도를 뛰어넘는 데 성공했습니다.
CS231N Overview
CNN 기반 Image Classification을 중심으로 다루돼, Object Detection, Image Caption 등에 대해서도 다룰 예정입니다.
CNN?
CNN은 Convolution(합성곱)을 통해 input Image에서 원하는 Feature를 추출하고 Pooling으로 해당 이미지를 구체화시키는 과정으로 이루어집니다.
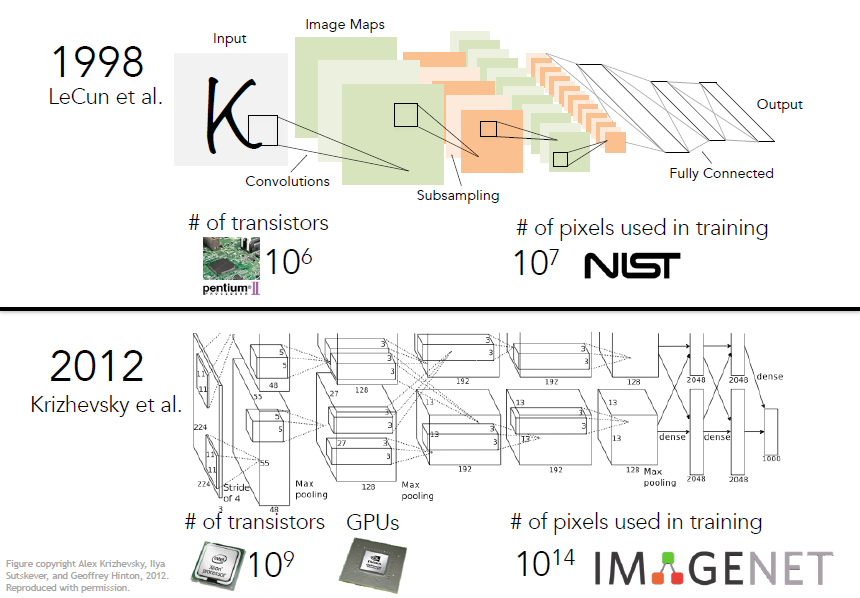
하지만 CNN은 21세기에 새롭게 등장한 개념은 아닙니다
20세기에 유사한 구조를 가진 digital data 처리 방법론이 있었으나, GPU 등 연산 보조 장치의 부재, Training에 필요한 데이터의 부족으로 21세기가 되어서야 조명받게 된 것입니다.
오역, 내용 오류 등에 대한 지적은 언제나 환영입니다
