조미정 강사님(데이터 수집)
DataCollecting_Crawling_Selenium
어제 마쳤던 곳에서 이어서. jupyter notebook에서 코드 작성
-
네이버 쇼핑상품 정보
-
페이징 처리하기
- 검색결과 페이지 스크롤해서 밑으로 내려가게 하기. -
GMarket 상품데이터 수집
-
이미지크롤링(네이버이미지)
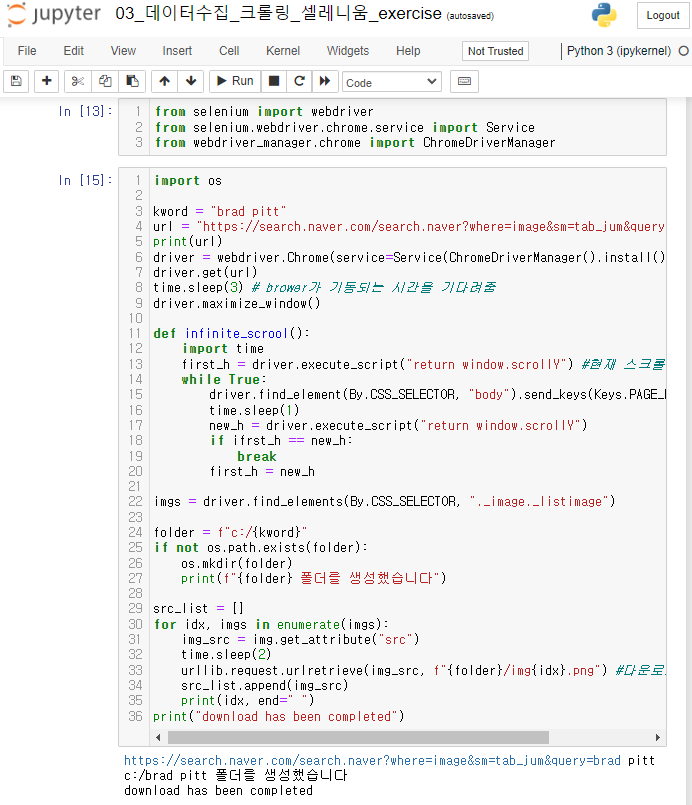
폴더까지는 생성이 되어있는데 도대체 왜 다운로드가 안되어있는지 모르겠다.. -
bing 활용해 이미지 다운받기
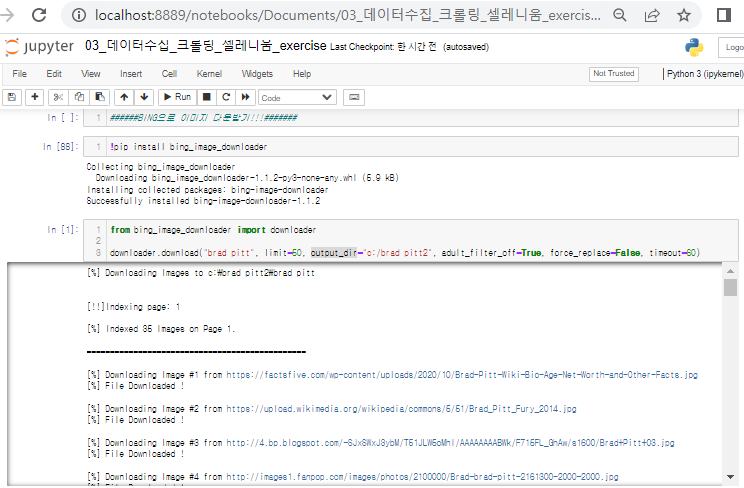 실행하면
실행하면
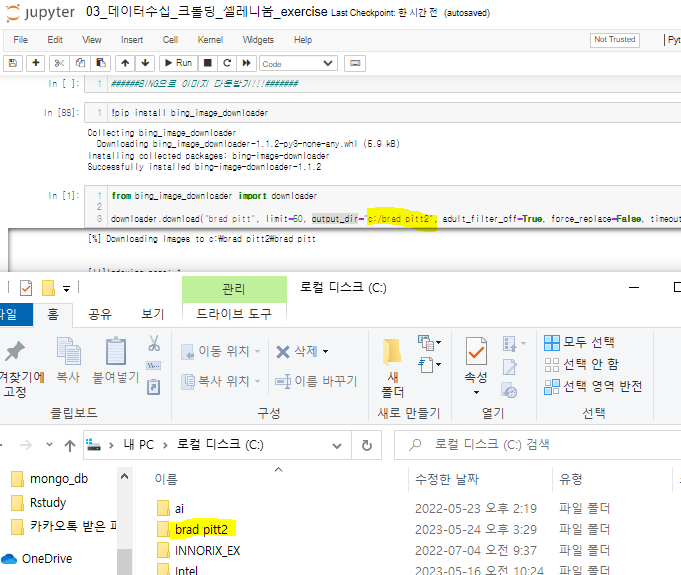 로컬 디스크(C:)에 brad pitt2 폴더가 생성되어 있고
로컬 디스크(C:)에 brad pitt2 폴더가 생성되어 있고
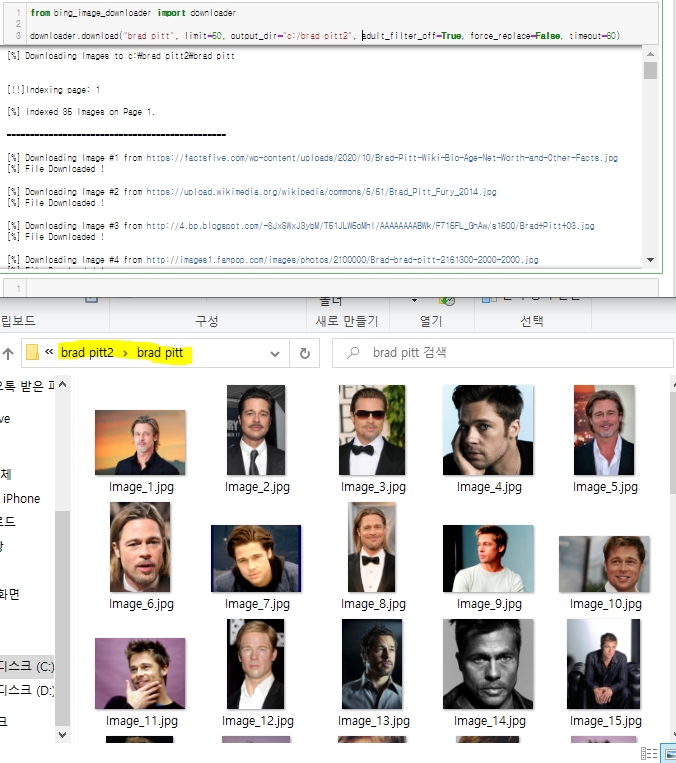 폴더를 열어보면 brad pitt로 검색된 image 50장이 저장되어있다.
폴더를 열어보면 brad pitt로 검색된 image 50장이 저장되어있다.
03_분석라이브러리활용
- Kaggle에서 titanic 엑셀 파일 가져와 분석라이브러리활용 실습해보기.
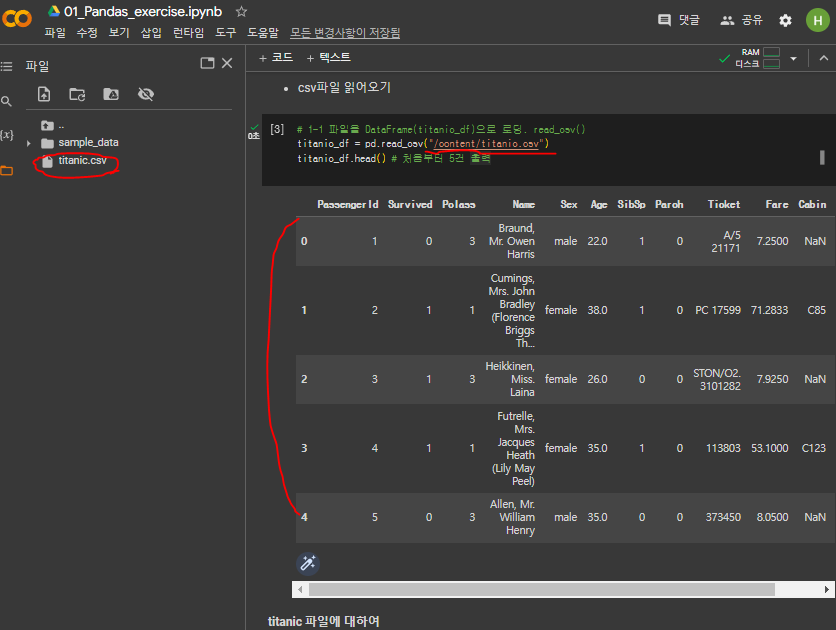 다운받은 엑셀 파일을 colab 파일 폴더 안에 drop해주면 파일이 들어와있는 것을 확인할 수 있다.
다운받은 엑셀 파일을 colab 파일 폴더 안에 drop해주면 파일이 들어와있는 것을 확인할 수 있다.
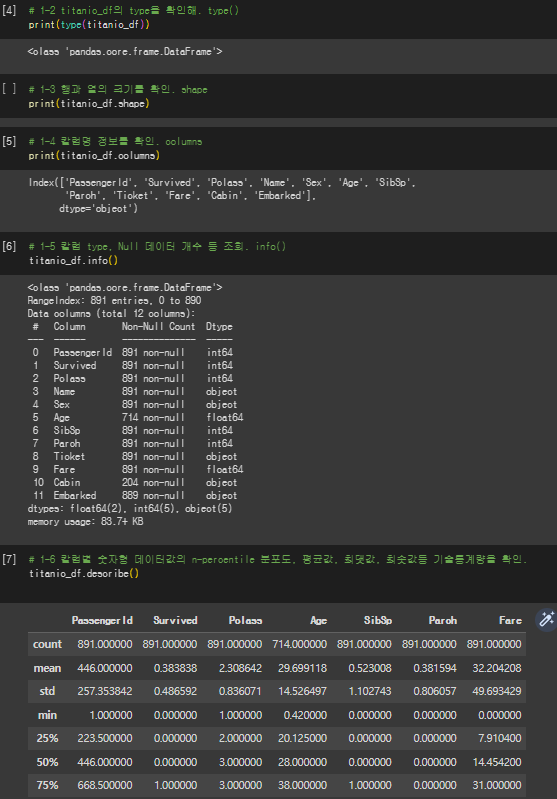
titanic 데이터로 각종 정보를 분석하여 확인해볼 수 있다.
오늘 수업에선 여기까지.
comment of the day
web crawling에서 스크롤하여 제일 하단까지 내려 나열되어있는 상품 이미지를 하나하나씩 클릭해 새 창을 열어보는 실습을 마저 해보고 image download를 실습해봤다.
다음 챕터로 넘어가 엑셀 파일로 받은 데이터를 python에서 이렇게 저렇게 어떻게 분석해볼 수 있는지 data analysis 실습을 살짝 해보고 수업이 끝났다.
위에 해결안된 오류들, 왜 다운로드 안됐는지 꼭 다시 확인해보기:)
