Machine Learning lecture day-5
-
Information Gain Ratio
: because of limits "Information Gain" have, "Information Gain Ratio" is need. -
Intrinsic Value
<Deciding which "Descriptive Feature" should be used for the "Root Node" comparing "Information Gain Ratio" of each cases>
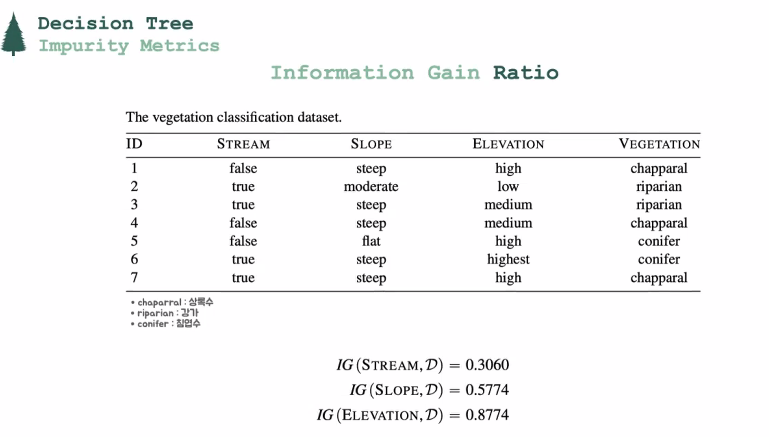
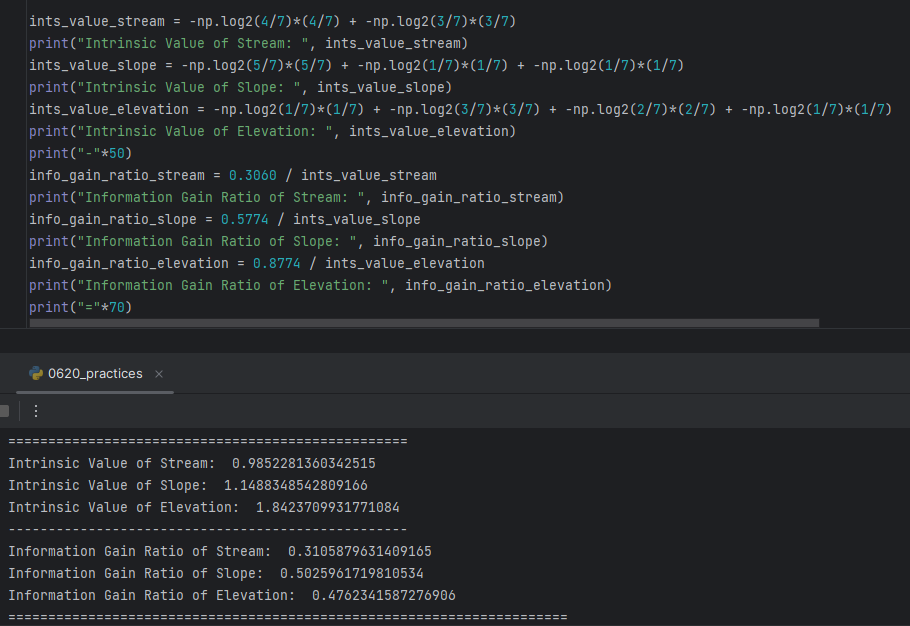
-> "Slope" has the biggest "Information Gain Ratio of 0.5025". Descriptive Feature for the Root Node has to be "Slope"
<Deciding which "Descriptive Feature" should be used for the "Internal Node" in the depth-2 between "Stream" and "Elevation" comparing "Information Gain Ratio" of each cases>
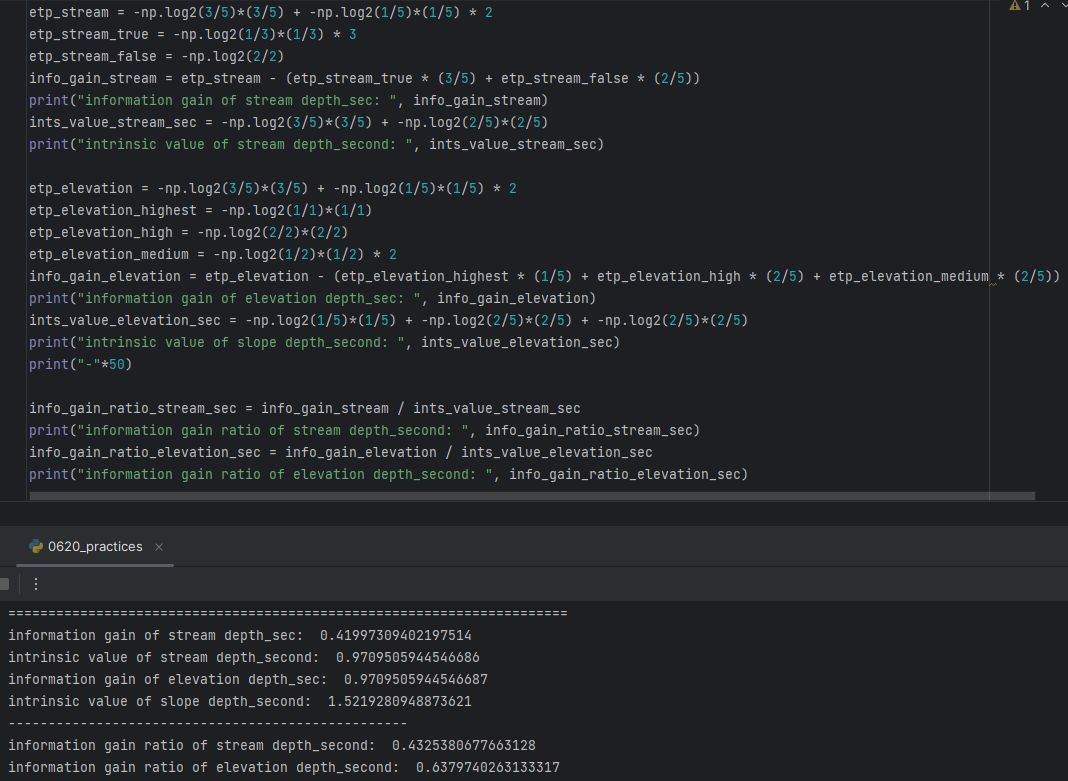
-> "Elevation" has bigger "Information Gain Ratio of 0.6379" than "Stream of 0.4325". Descriptive Feature for the Internal Node in the depth-2 has to be "Elevation"
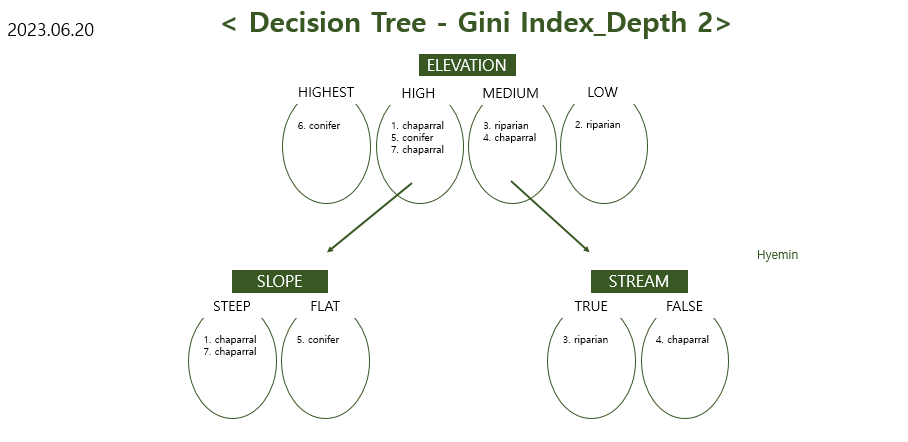
<Result (Final Decision Tree)>

-> Compare today's Decision Tree vs. yesterday's Decision Tree
-> Decision tree using Information Gain vs. Decision tree using Information Gain Ratio
= former one has two levels whereas later one has three levels
-> can't tell which dicision tree is better than the other by comparing depths of the trees.
-
Gini Index: used for mesuring impurity
-
Gini Index or Gini impurity: measures the degree or probability of a particular variable being wrongly classified when it is randomly chosen.
-
Impurity: If all the elements belong to a single class, then it can be called pure. The degree of Gini Index varies between 0 and 1,
-
Impurity 0 = all elements belong to a certain class or there exists only one class (pure).
Impurity 1 = the elements are randomly distributed across various classes (impure). -
A Gini Index of '0.5 'denotes equally distributed elements into some classes
-
CART (Classification And Regression Tree) algorithm: a type of classification algorithm that is required to build a decision tree on the basis of Gini's impurity index. It is a basic machine learning algorithm and provides a wide variety of use cases.
-
Gini Index Formula:
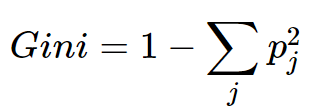
<Deciding which "Descriptive Feature" should be used for the "Root Node" comparing "Gini Index" of each cases>
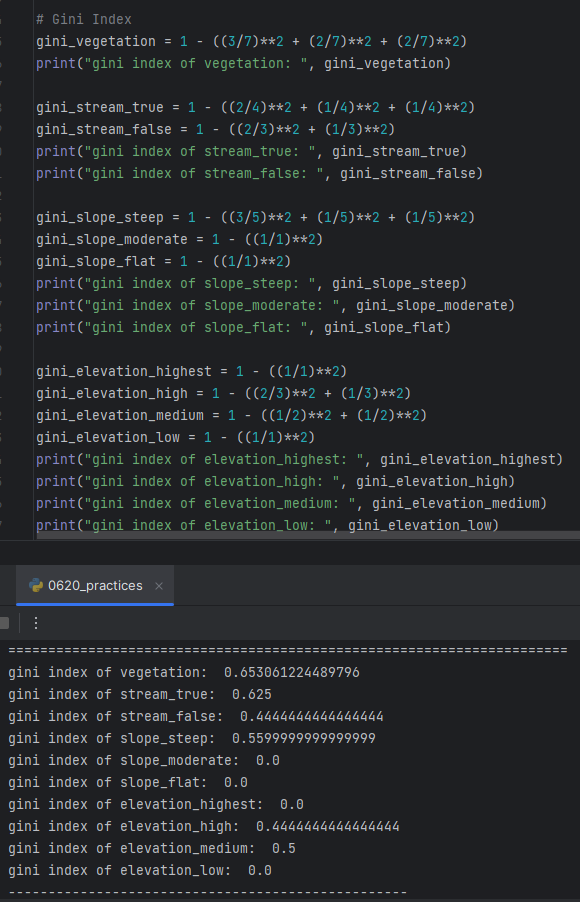
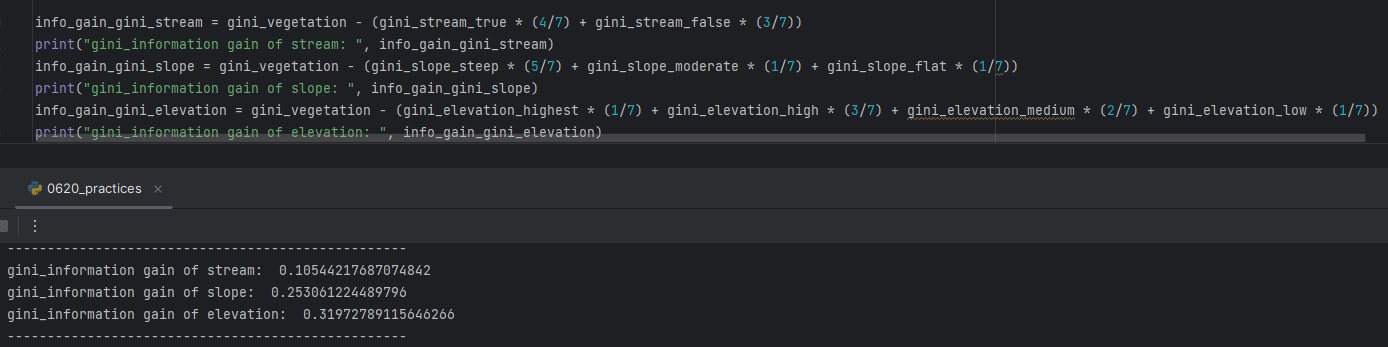
-> choosing "Elevation" as the "Root Node" since it has biggest value of 0.3197
**information gain = (upper gini index) - (lower gini index)**
**smaller (lower gini index)= bigger (information gain) = lower impurity**
**gini index and impurity are Proportional**
<Deciding which "Descriptive Feature" should be used for the "Internal Node" in the depth-2 between "Stream" and "Slope" comparing "Gini Index" of each cases>
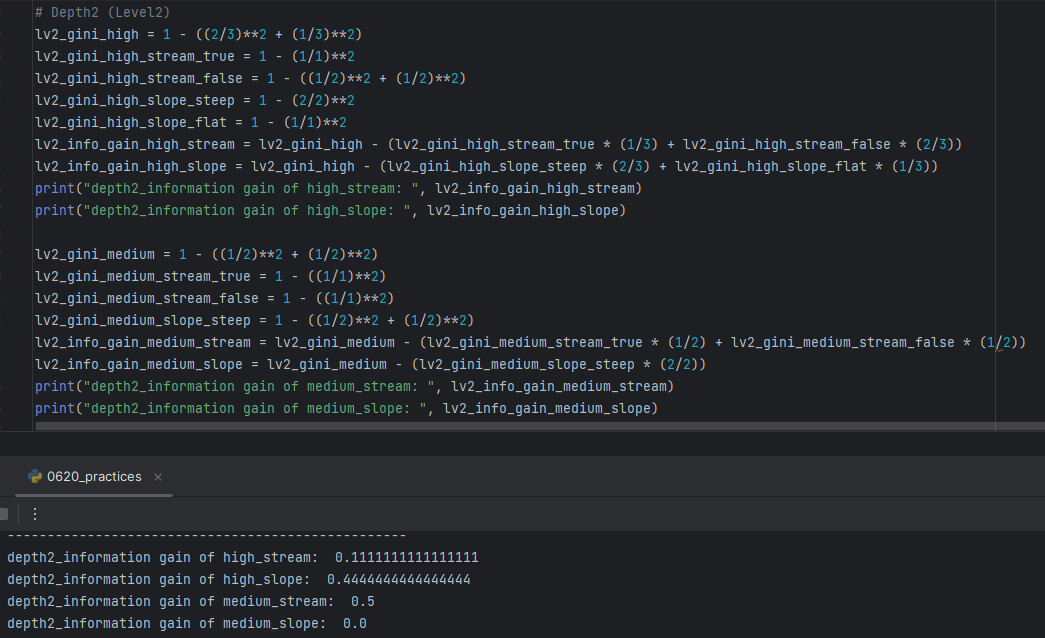
-> choosing "Slope(0.4444)" as the Internal Node of "Elevation-High", "Stream(0.5)" as the Internal Node of "Elevation-Medium"
<Result (Final Decision Tree)>