
책의 마지막 챕터인 순환 신경망이다. 오예
이게 끝나면 양반식(?) 공부는 끝을 내가고 곧 실전이다...
 지금부터 진짜로 모델을 분석하고 적용시켜야한다. 물론 이 챕터 끝나고...(눙물)
지금부터 진짜로 모델을 분석하고 적용시켜야한다. 물론 이 챕터 끝나고...(눙물)
이제는 빅데이터처리 수업과 수업 자료로 알 수 없기 때문에 오직 책만 믿고 간다... 레고
아래 내용은 <혼자 공부하는 머신러닝 + 딥러닝> 책을 참고하여 작성한 내용입니다.
1. 순차 데이터와 순환 신경망
댓글을 분석하는 모델을 명받았다(?) 해보자.
순차 데이터
- 순차 데이터(Sequential Data) : 텍스트, 시계열 데이터(Time Series Data, 일정 시간 간격으로 기록된 데이터) 처럼 순서에 의미가 있는 데이터
이미지 한 장을 분류하는 것은 순서가 상관 없고 오히려 모델을 만들 때 골고루 있는 것이 General 한 모델이 되므로 더 좋다. 그러나 댓글과 같은 텍스트 데이터는 글의 순서가 중요한 순차 데이터이고 순서를 유지해주어야 한다.(ex : '별로지만 추천해요' 를 잘라서 다른 것들과 섞이게 하면 '추천해요' 와 '별로지만' 이 된다. 붙여서 분석해야 '긍정'이 아니라는 것을 알 수 있습니다.)
- 피드포워드 신경망(FeedForward Neural Network) 는 입력 데이터의 흐름이 앞쪽으로만 전달되는 신경망
챕터7의 완전신경망, 챕터8의 합성곱 신경망이 FFNN에 속한다. 신경망이 이전에 처리했던 샘플을 다음 샘플 처리를 위해 재사용하기 위해서는 다른 개념이 필요하다. 바로 '순환 신경망' 이다.
순환 신경망
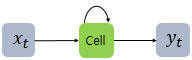
- 순환 신경망(Recurrent Neural Network, RNN) 은 완전 연결 신경망과 거의 비슷하지만 이전 데이터를 순환하도록 하는 고리를 붙인다.
 (출처 : 딥러닝을 이용한 자연어 처리 입문 08-1 순환신경망)
(출처 : 딥러닝을 이용한 자연어 처리 입문 08-1 순환신경망)
따라서 다음 입력을 처리하는 과정에서 이전의 데이터들을 어느정도 포함하고 있을 것입니다. '이전 샘플에 대한 기억을 가지고 있다' 라고 말한다고 합니다.
- 타임스텝(time step) : 샘플을 처리하는 한 단계
- 셀(cell) : 순환 신경망에서의 층. 한 셀에는 여러개 뉴런이 있으나 모두 표현X
- 은닉 상태(hidden state) : 셀의 출력
대체로 형태는 다음과 같습니다.
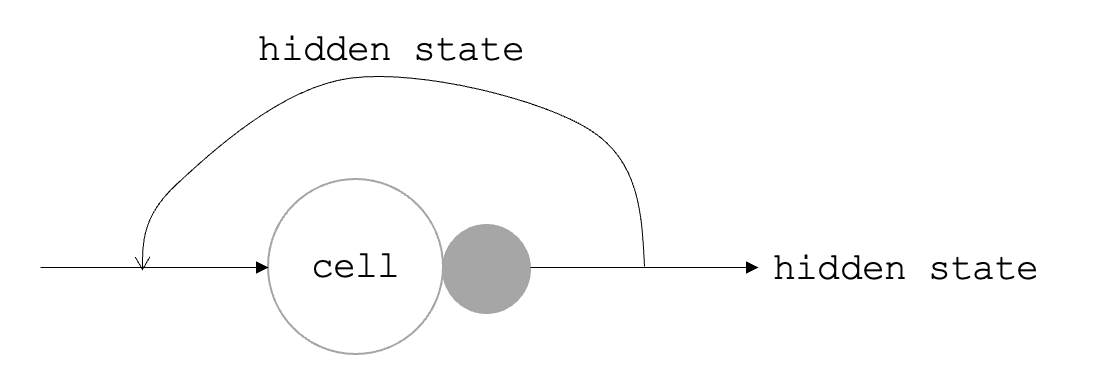 (참고 : 혼자 공부하는 머신러닝+딥러닝 490p)
(참고 : 혼자 공부하는 머신러닝+딥러닝 490p)
셀 뒤에 붙은 회색 작은 동그라미는 활성화함수 입니다. 일반적으로 활성화 함수는 하이퍼볼릭 탄젠트(hyperbolic tangent, tanh) 함수가 사용되며 s자 형태이기 때문에 종종 시그모이드 함수라고 부른다고 합니다. 다만 시그모이드의 치역은 0~1, 하이퍼볼릭 탄젠트는 -1~1 이기 때문에 구분해줘야한다고 생각한다.
순환 신경망의 활성화 함수는 입력, 이전 타임스텝의 은닉 상태 입력에 각각 가중치를 곱하여 결과를 도출해냅니다. 가중치가 여러개 라는 뜻이죠...
셀의 가중치와 입출력
CNN은 합성곱으로 데이터를 압축한 인공신경망이라고 정리했다. 순환신경망은 상당히 다르다. 각 입력층이 순환층으로 완전연결되어있고 순환층의 결과가 각 다른 셀에 영향을 끼친다. 다음처럼 그려보았다.
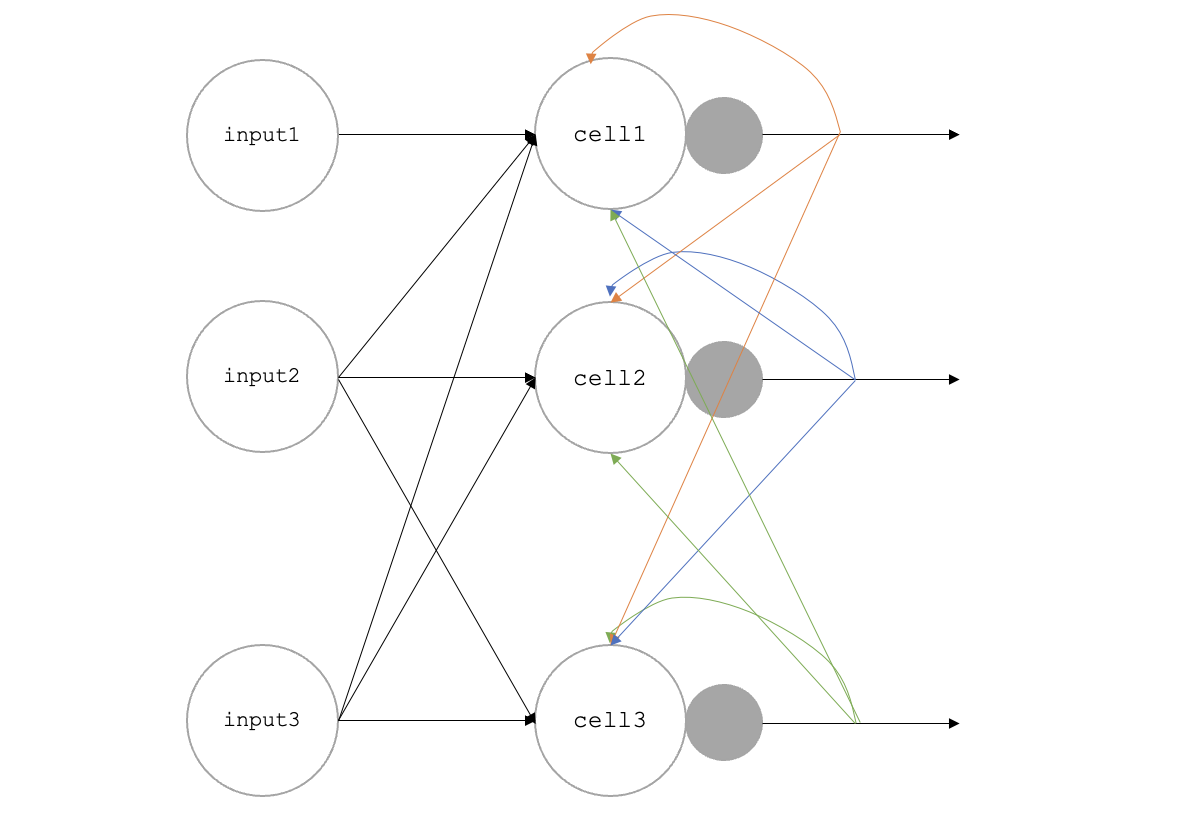 (참고 : 혼자 공부하는 머신러닝+딥러닝 493p)
(참고 : 혼자 공부하는 머신러닝+딥러닝 493p)
만약 샘플이 10개, 타임스텝이 20개, 각 벡터가 100인 입력을 나타낸다고 하면 (10, 20, 100) 으로 나타낼 수 있고 순환층을 연결해서 사용한다고 하면
(10, 20, 100) --> 순환층 --> (10, 20, 순환층의 뉴런 개수) --> 순환층 --> 마지막 타임스텝의 은닉상태
로 볼 수 있습니다.
2. 순환 신경망으로 IMDB 리뷰 분류하기
IMDB 리뷰 데이터셋을 사용해봅시다. 영화 사이트 리뷰 데이터셋으로 각각 훈련, 테스트 각각 25,000개씩 총 50,000 개 데이터셋이 있다. 0과 1로 라벨링이 되어있는데 이는 긍정, 부정을 뜻하며 각각 50%, 50%이다. 구체적인 내용은 여기에 IMDB(Keras)
- 토큰 : 분리된 단어 하나. 하나의 타임스텝을 의미
이 토큰들이 각각 정수에 매핑되어 있고, 0은 패딩, 1은 시작, 2는 어휘사전에 없는 토큰에 해당한다. 위의 keras.imdb 에 들어가보니, 사용 빈도로 인덱싱 되어있다고 한다. 우리는 상위 500개만 사용한다. 리뷰의 길이(토큰 개수)를 평균과 중간값으로 확인해봅시다.
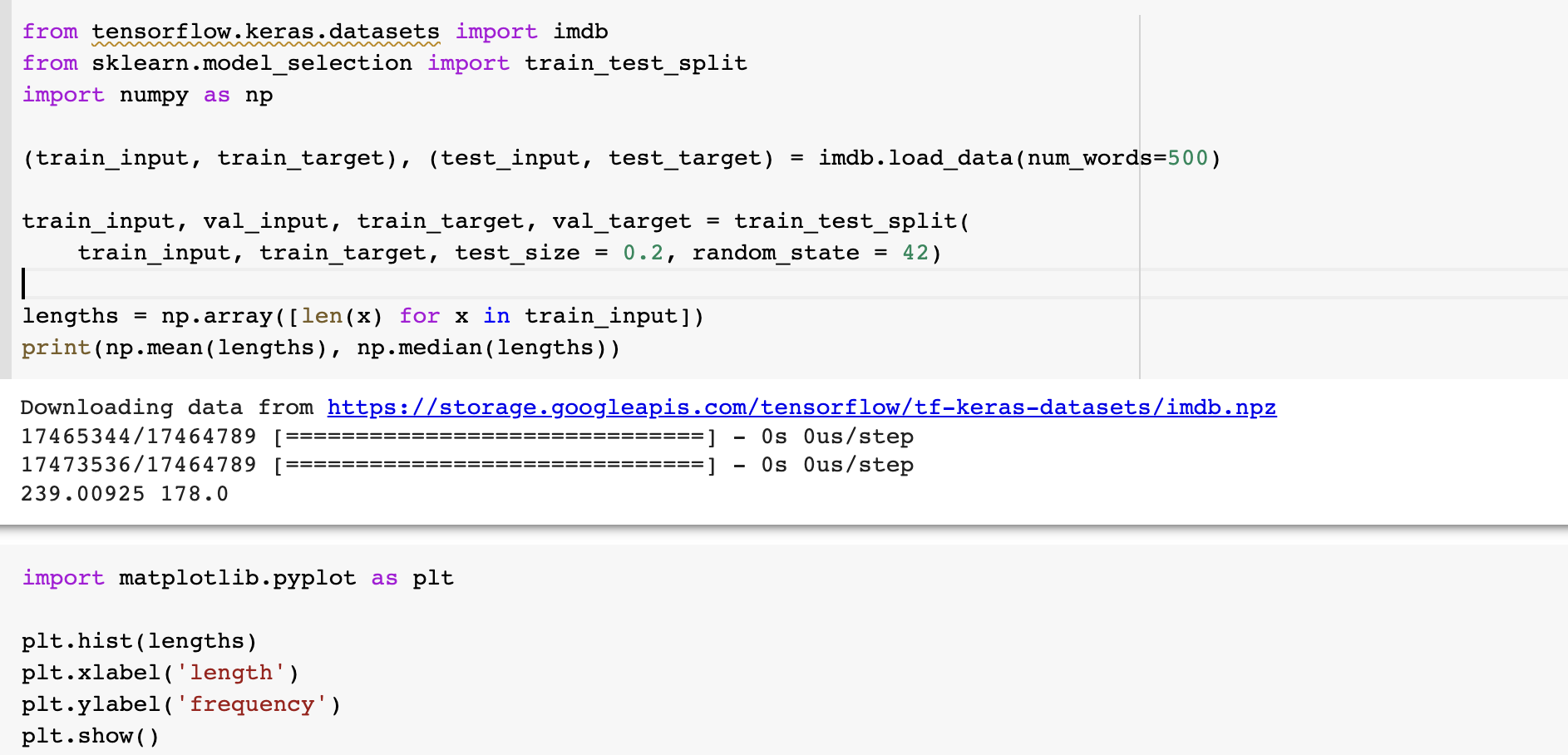
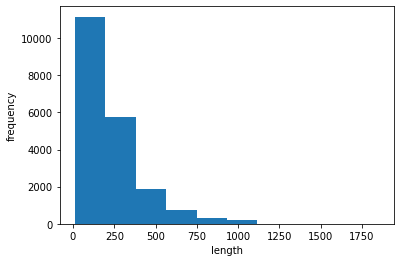
평균은 239, 중간값은 178 이고 전반적으로 토큰 500개 이하인 것이 많습니다. 물론 토큰 1만개짜리 엄청난 리뷰도 있지만 이정도면 리뷰가 아니라 분석 아닌감... 시퀀스 데이터 길이를 100으로 맞추도록 하겠습니다. maxlen 옵션을 지정하여 길면 자르고, 짧으면 0으로 패딩합니다.
모델을 만들어서 돌려봅시다.
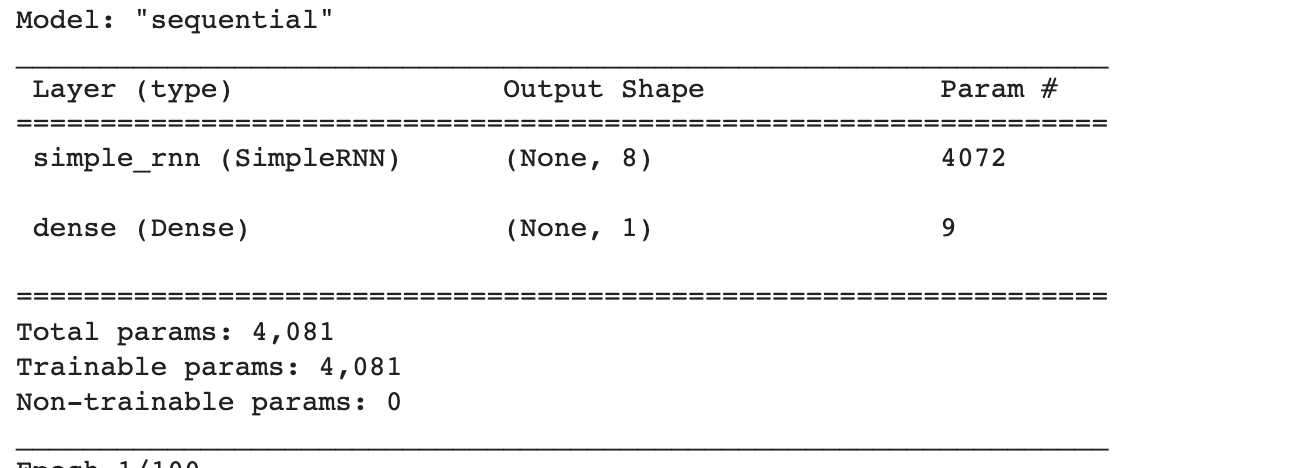 모델 구조입니다.
모델 구조입니다.
모델의 파라미터는 입력 토큰 500개 x 순환층 뉴런 8개 + 은닉상태 크기 8개 x 뉴런 8개 + 절편 8개 = 4072개 입니다. Dense층의 가중치 개수 9개까지 더해서 총 4081개가 됩니다.
RMSprop 가 default 이지만 학습률을 0.0001 로 바꾸었습니다.
patience 는 3 으로 설정하였고 조기종료하여 최적 모델을 저장하도록 설정하였습니다. 
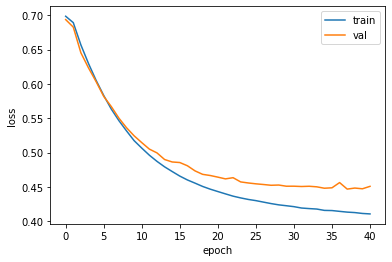 Epoch 38/100 의 정확도가 제일 높은 것을 볼 수 있습니다. validation loss loss가 대충 25부터는 거의 x=상수 에 수렴합니다. 삐까삐까하다는 뜻입니다... 그리고
Epoch 38/100 의 정확도가 제일 높은 것을 볼 수 있습니다. validation loss loss가 대충 25부터는 거의 x=상수 에 수렴합니다. 삐까삐까하다는 뜻입니다... 그리고 keras.utils.to_categorical() 을 사용하여 원-핫 인코딩을 사용해 500개 중 하나만 1이고 나머지를 0으로 만들어서 크기 속성을 없애주었습니다. 하지만 놀랍게도 토큰 1개를 500차원으로 늘렸기 때문에 데이터가 엄청 커집니다.
거 데이터 크기가 너무 심한거 아니요 실제로 원-핫 인코딩 방식은 단어의 의미나 단어 사이의 관계를 전혀 고려하지 않고 만약 단어를 2000개로 늘리면 더욱 크기가 늘어나게 된다... 더 좋은 방법을 찾아보도록 하자
더 좋은 방법을 찾아보도록 하자
단어 임베딩
RNN 에서 텍스트 처리를 할 때에는 '단어 임베딩(Word Embbeding)' 을 사용한다. 단어를 고정된 크기의 실수 벡터로 바꾸어주는 방법인데 단어의 의미를 고려하여 벡터로 표현한 것이다. 예를 들어, [고양이, 강아지, 개구리] 가 있다면 각각을 벡터로 표현하지만 고양이와 강아지 사이의 거리가 개구리와의 거리보다 가깝습니다. 고양이와 강아지는 포유류이고 개구리는 양서류이기 때문이죠. 실제로 그런지는 모르겠지만 예시라고 봐주세요
keras.layers.Embedding(input_dim, ooutput_dim) 을 사용하여 순환신경망을 만들어보겠습니다.
 500개 토큰을 크기 16 벡터로 변경하였기 때문에 500x16 크기의 모델 파라미터를 가진다. 뉴런이 8개 이기 때문에 16x8 개, 은닉상태의 가중치 8x8 + 8개 절편 -> 8200개 모델파라미터가 있고 Dense층 9개이므로 8209개 입니다.
500개 토큰을 크기 16 벡터로 변경하였기 때문에 500x16 크기의 모델 파라미터를 가진다. 뉴런이 8개 이기 때문에 16x8 개, 은닉상태의 가중치 8x8 + 8개 절편 -> 8200개 모델파라미터가 있고 Dense층 9개이므로 8209개 입니다.

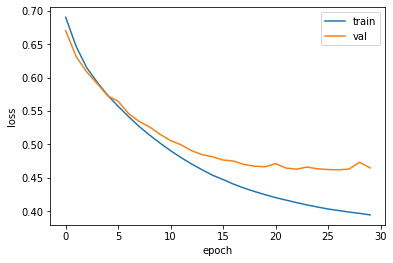 validation loss가 Epoch 27/100 에서 제일 낫기 때문에 조기종료 되었습니다. train loss 는 계속 줄어드는데 아쉽네요. 다른 방법을 3.LSTM&GRU cell 에서 공부해봅시다.
validation loss가 Epoch 27/100 에서 제일 낫기 때문에 조기종료 되었습니다. train loss 는 계속 줄어드는데 아쉽네요. 다른 방법을 3.LSTM&GRU cell 에서 공부해봅시다.
3. LSTM과 GRU 셀
simpleRNN 보다는 복잡하지만 훨씬 성능이 뛰어난 순환신경망 모델을 배워봅시다. 기본 순환층은 시퀀스가 길어질수록 순환되는 은닉 상태에 담긴 정보가 점차 희석되기 때문에 긴 시퀀스를 학습하기 어렵다. 그런 이유로 LSTM과 GRU셀이 제안되었다.
LSTM
- LSTM(Long Short-Term Memory) : 장단기 메모리
입력게이트, 삭제게이트, 출력게이트를 추가하여 불필요한 기억을 지우고 기억할 것들을 정하여 긴 시퀀스 입력을 잘 처리하도록 설계되었다.
구체적인 그림을 보자
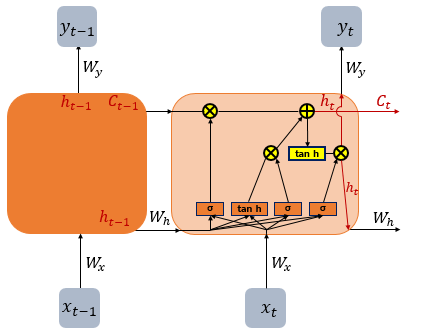 (출처 : 딥러닝을 이용한 자연어처리 입문 8.순환신경망 - 장단기 메모리, 이하 LSTM 단락의 사진은 같은 자료에서 따옴)
(출처 : 딥러닝을 이용한 자연어처리 입문 8.순환신경망 - 장단기 메모리, 이하 LSTM 단락의 사진은 같은 자료에서 따옴)
전반적인 LSTM의 내부 모습이다. 복잡해보이지만 어렵지는 않다.
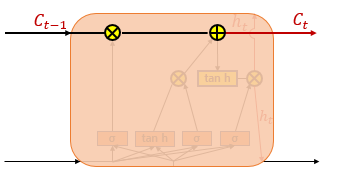 t시점의 셀 상태를 로 표현하고 있으며 이전 스텝은 로 표현하고 있다. 는 시그모이드 함수이다.
t시점의 셀 상태를 로 표현하고 있으며 이전 스텝은 로 표현하고 있다. 는 시그모이드 함수이다.
은 를 사용하는 각 게이트에서의 가중치이다. -자리에 알파벳이 들어가서 구분을 쉽게 할 예정
은 (은닉상태) 를 사용하는 각 게이트에서의 가중치이다. -자리에 알파벳이 들어가서 구분을 쉽게 할 예정
는 각 게이트에서 사용하는 bias 이다.
아래로 각각 입력, 삭제, 출력 게이트를 설명하겠다.
1) 입력 게이트
현재 정보를 기억하기 위한 게이트이다.
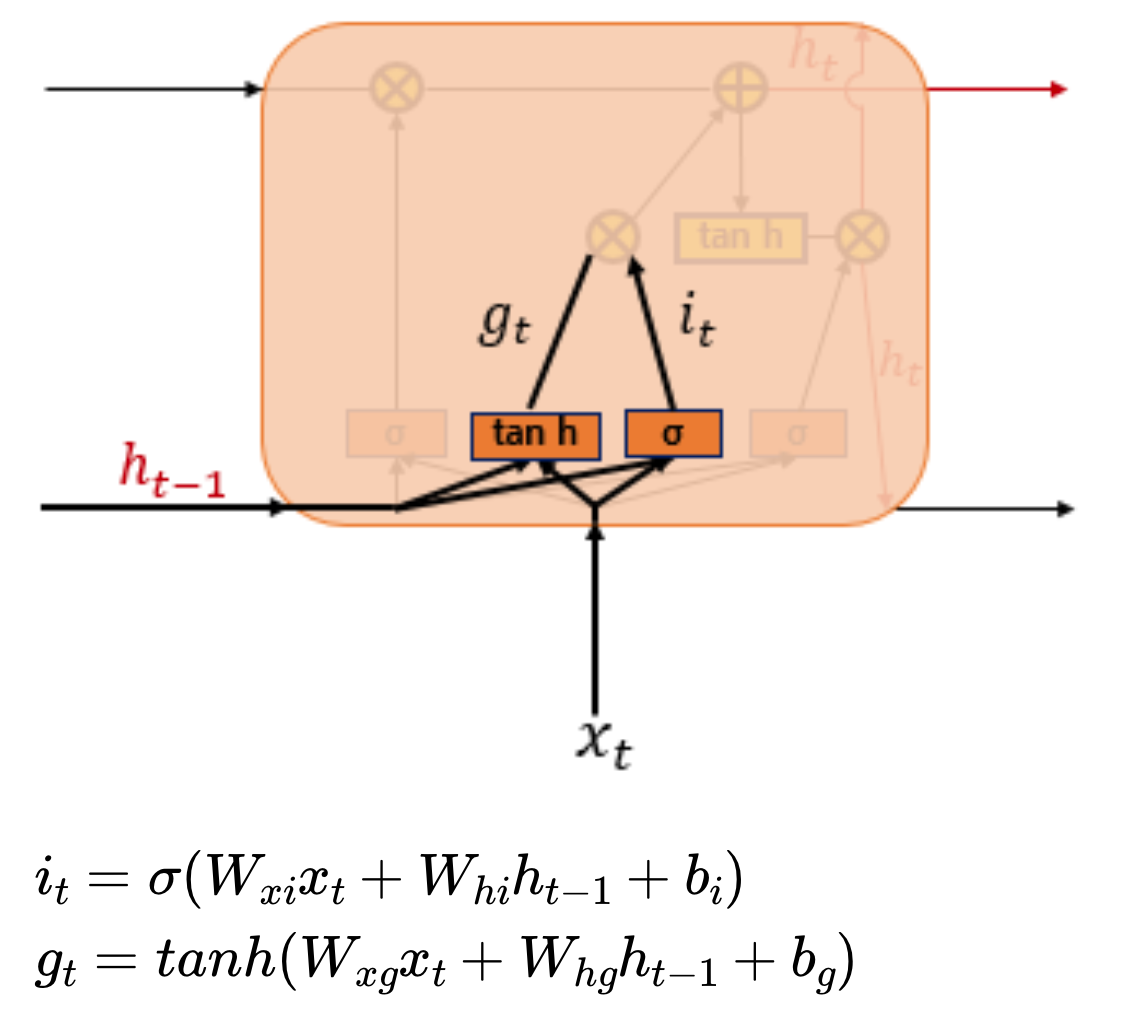 현 시점의 x값인 를 입력게이트로 이어지는 가중치 와 곱하고 이전 시전의 은닉상태에 가중치 를 곱하고 를 더해서 시그모이드 함수에 통과시킨다. 결과인 는 0~1 사이의 값을 갖는다.
현 시점의 x값인 를 입력게이트로 이어지는 가중치 와 곱하고 이전 시전의 은닉상태에 가중치 를 곱하고 를 더해서 시그모이드 함수에 통과시킨다. 결과인 는 0~1 사이의 값을 갖는다.
를 입력게이트로 이어지는 가중치 와 곱하고 이전 시전의 은닉상태에 가중치 를 곱하고 를 더해서 하이퍼볼리탄젠트함수에 통과시킨다. 결과인 는 -1~1 값을 갖는다. 이 두 값으로 기억할 정보의 양을 정한다.
2) 삭제 게이트
셀 상태에 있는 정보를 제거하는 역할을 한다.
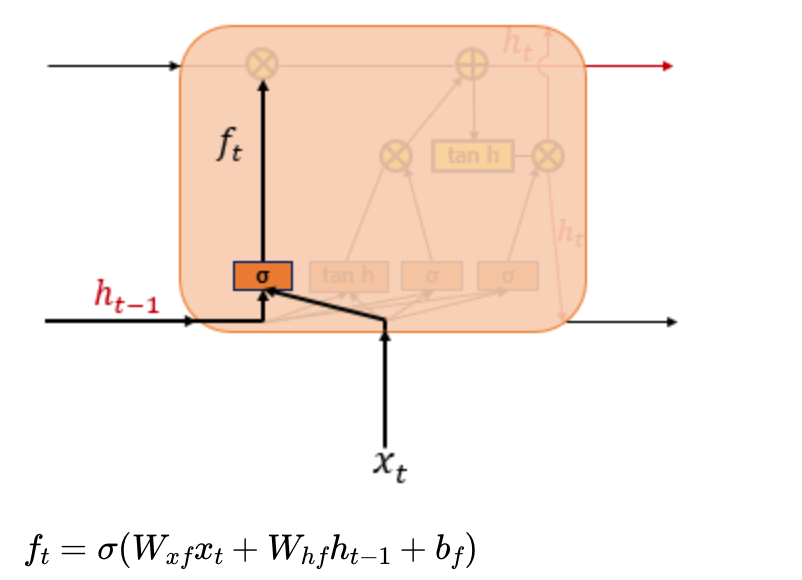 와 가 시그모이드 함수를 지나서 로 출력된다. 시그모이드 함수를 지났으므로 0~1 사이인데, 클수록 정보량을 많이 갖고 있다.
와 가 시그모이드 함수를 지나서 로 출력된다. 시그모이드 함수를 지났으므로 0~1 사이인데, 클수록 정보량을 많이 갖고 있다.
3) 셀상태
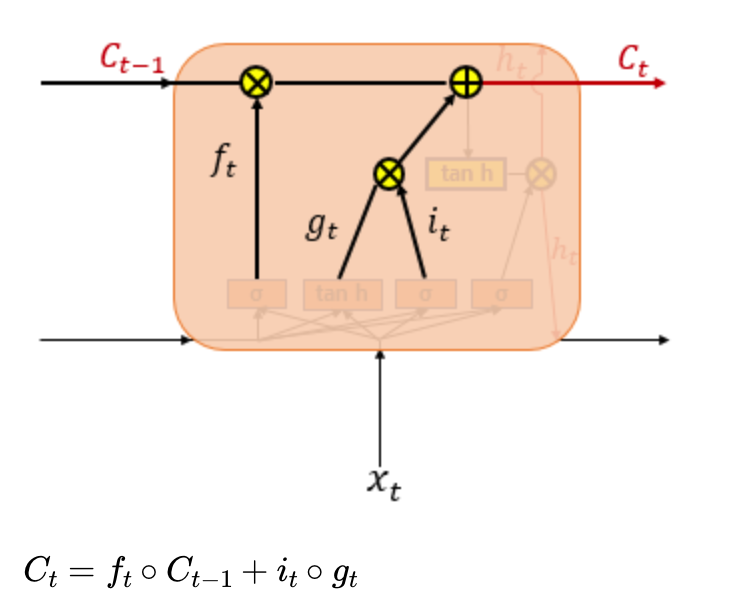
와 를 원소별 곱을 해주고 는 과 원소곱을 하여 둘을 더해줍니다. 만약에 삭제 게이트에서 0에 수렴하는 값을 내보냈다면 이전 셀의 정보는 거의 들어가지 않는다고 봐야합니다.
위 계산을 해줌으로써 t시점에서 셀 상태 계산은 끝납니다. 다음은 출력입니다.
4) 출력 게이트
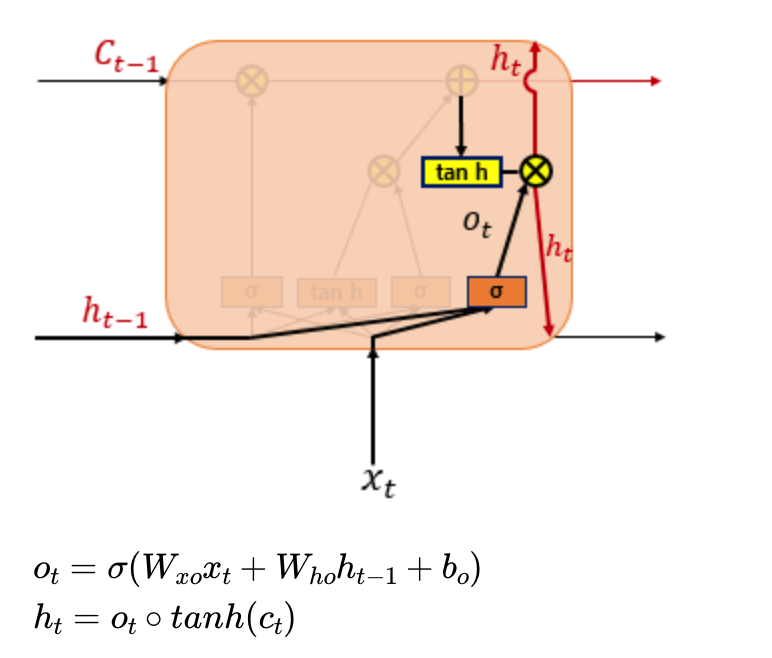
와 가 시그모이드 함수를 지난 결과와 셀 상태가 하이퍼볼릭탄젠트 함수를 지난 결과를 서로 원소별 곱해주어 결과를 낸다. 시그모이드 함수 결과인 는 현재 시점의 은닉 상태를 결정하고 하이퍼탄젠트 함수를 지난 결과값은 값이 걸러지는 효과가 발생하여 은닉상태가 된다고 한다.
처음엔 이걸 보고 삭제게이트와 같은 작업을 왜 두 번 해주는거지? 라고 생각했지만 각 가중치와 편향이 다르기 때문에 다른 작업이었다.
LSTM 신경망 훈련하기
LSTM을 배웠으니 훈련시킨다. 데이터를 준비하고 샘플 길이를 100으로 하여 패딩까지 해준다. lstm 클래스를 사용해준다. 모델 구조는 다음과 같다.

 단어임베딩을 했던 simpleRNN 과 같은 크기이지만 LSTM 덕분에(?) 모델 파라미터가 정확히 4배가 되었다. 컴파일하고 조기종료까지 만들어준다.
단어임베딩을 했던 simpleRNN 과 같은 크기이지만 LSTM 덕분에(?) 모델 파라미터가 정확히 4배가 되었다. 컴파일하고 조기종료까지 만들어준다.

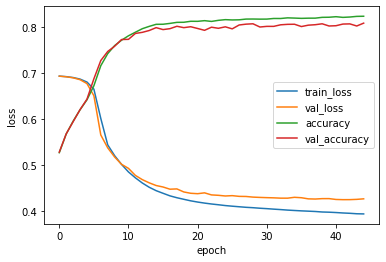 생각보다 잘됐다. 하지만 과대적합을 줄일 필요가 있다.
생각보다 잘됐다. 하지만 과대적합을 줄일 필요가 있다.
순환층에 드롭아웃
CNN에서 과대적합을 막기 위해 드롭아웃을 했는데 순환층에서는 자체적으로 드롭아웃 기능을 제공한다고 한다. 매개변수 recurrent_dropout 의 비율을 정해주면 된다. 하지만 이것을 사용하면 GPU 를 사용하여 훈련하지는 못한다고 한다. 30% 드롭아웃 시켜서 훈련시켜보자.

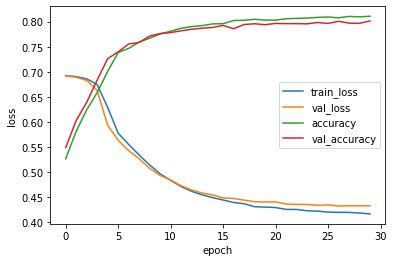 train, validation loss 와 accuracy 사이의 간격이 좁혀졌다. 이젠 순환층을 여러개 쌓아서 모델을 만들어보자
train, validation loss 와 accuracy 사이의 간격이 좁혀졌다. 이젠 순환층을 여러개 쌓아서 모델을 만들어보자
층 2개 연결하기
LSTM을 하나 더 쌓아준다. 모델을 다음과 같이 만들었다. 훈련도 시킨다.


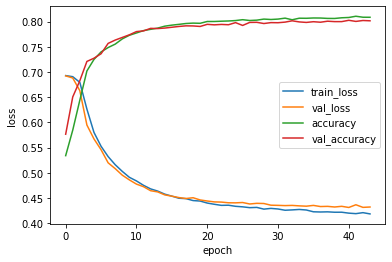 다음과 같은 결과가 나왔다. 매우 잘된 것 같다. 다만 드롭아웃한 것과 별 차이는 없다.
다음과 같은 결과가 나왔다. 매우 잘된 것 같다. 다만 드롭아웃한 것과 별 차이는 없다.
다른 방법도 사용해보자.
GRU
- GRU(Gated Recurrent Unit) : 게이트 순환 유닛이다. 2014년 뉴욕대학교 조경현 교수님이 낸 논문에서 제안되었다고 한다! GRU는 LSTM와 비슷한 역할을 하지만 구조를 간단하게 만든 모델이라고 생각하면 좋다.
LSTM은 입력, 삭제, 출력게이트가 존재했지만 GRU는 업데이트와 리셋 게이트만 사용한다.
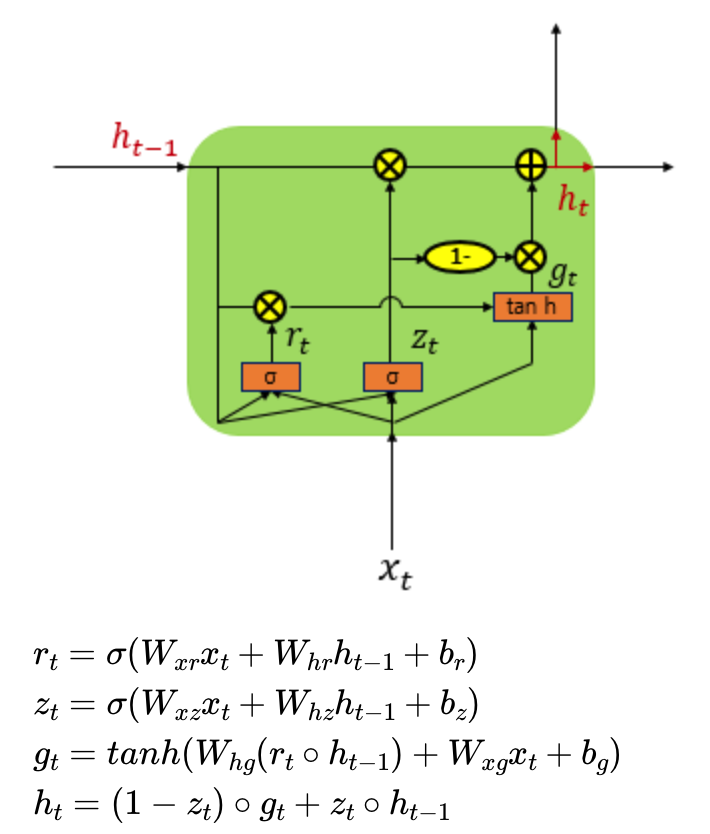 (출처 : 딥러닝을 이용한 자연어처리 입문 8.순환신경망 - 게이트 순환 유닛)
(출처 : 딥러닝을 이용한 자연어처리 입문 8.순환신경망 - 게이트 순환 유닛)
r은 리셋 게이트, z는 업데이트 게이트이다. LSTM과 다른 점은 셀 상태가 없다는 점이다.
입력과 이전의 은닉상태에 각각 가중치를 곱하고 bias를 더해서 시그모이드 함수를 통과시켜서 리셋게이트에서는 잊혀질 정보의 양을, 업데이트 게이트에서는 유지할 정보의 양을 계산합니다.
리셋게이트 결과를 하이퍼볼릭탄젠트 함수에 통과시키고 업데이트 게이트에는 1을 빼서 두 결과를 원소별로 곱해줍니다. 또 한 쪽에서는 업데이트 게이트와 이전의 은닉상태를 원소별로 곱해줍니다. 이 두 결과를 더해서 은닉상태의 정보를 정한다.
LSTM 클래스를 GRU로 바꿔주기만 하면 된다.

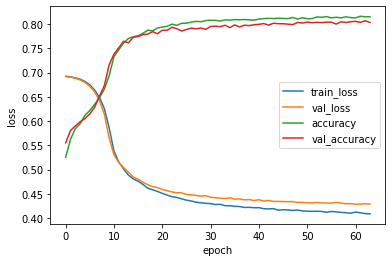 성능은 LSTM과 비슷한 것 같습니다. 층을 늘리거나 드롭아웃도 넣을 수 있지만 여기까지만 하겠습니다.
성능은 LSTM과 비슷한 것 같습니다. 층을 늘리거나 드롭아웃도 넣을 수 있지만 여기까지만 하겠습니다.
혼공머신 책을 끝냈다! 와우 어메이징 이것을 시작한 것이 1월인데 벌써 3월 중순이고 나는 휴학생이며 연구실을 정리하고 타대 대학원을 준비하고 있다. 짧은 시간에 많은 일이 있었고 다양한 것을 배울 수 있었다. 심지어 이 포스트를 거의 2주동안 작성하였는데 2주만에 연구실을 마무리하기로 결정하고 교수님과 상담도 여러번 하였다... 짧지만 진짜 바빴다...
공부를 하면서 선형대수를 다시 배우면 좋을 것 같아서 앞으로 네이버커넥트재단의 강의를 들을 예정이다. 코세라에서 자율주행 코스 수업도 듣고 코테도 준비할 것이라 연구실 다니는 것 못지않게 바쁠 것 같다.
책 배우면서 고생도(사실 걍 앉아서 코딩만...) 많이 했지만 책 한 권을 끝내서 매우 뿌듯하다. 이걸 배웠으니 그래도 base는 다졌다고 말할 수 있겠ㅈ...ㅣ? 다른 것들도 계속 도전해나가야겠다.

