
📖 학습한 내용
- 마이닝 알고리즘
- Neural Network
📖 핵심내용
📌 마이닝 알고리즘
-
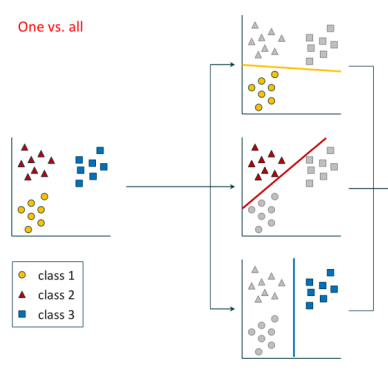
디바이드 앤 퀀커
-
과적합 방지
k-fold cross validation

-
클러스트링 활용
클러스터별로 라벨을 설정한다.
이때 클러스트링 했을 때 만들어진 그룹을 파생변수로 활용할 수 잇다. 이때 특정 피처에 너무 가중치가 쏠리는 것을 조심해야한다.
각 클러스터별로 어떻게 해석할 수 있는지, 어떤 그룹의 특성이 있는지 분석해야한다. -
거리
L1 norm : 멘하튼 거리
L2 norm : 유클리드 거리 -
이미지 간에 유사성을 어떻게 찾을 것인지
픽셀 값으로 벡터 공간에 매칭한다.
이미지를 수치화(벡터화)한다.
이미지 데잍터는 해상도에 따른 각 픽셀별 값이 정해져있다. 너무 데이터량이 많기 때문에 압축한다. -
텍스트 데이터 간에 유사성
텍스트를 벡터로 임베딩해야한다.
좌표공간에서 두데이터간의 거리 -
비지도 학습 : 클러스터링
데이터의 유사성을 기반으로, 2차원에 군집하여 나타내는것
K-NearestNeighbor
가까운 점이 과반수인쪽으로 결정된다.
-
n_neighbors=k
동점이 되지 않게 k 값을 홀수로 정해준다.
k 값이 너무 작으면 모델은 너무 복잡 -> 오버피팅(과적합)
k 값이 너무 크면 모델은 너무 단순 -> 언더피팅(과소적합)
cross_val_score()을 이용해서 최적의 k값을 찾는다.
일반적으로 데이터 샘플의 수가 n일 때, k 값을 설정하는 경험적 규칙 중 하나는 sqrt(n) (즉, n의 제곱근)이다. -
weights='distance'
가까울 수록 가중치를 많이 줘서 동점을 피하는 방법이 있다.
Decision-tree
선을 하나씩 그어서 영역을 나누며 혼잡도를 떨어뜨린다.
트리수를 제한(max_depth)하여서 트레이드 오프 지점을 찾아야한다.
구조에 대한 이해도 좋고, 일반화 성능도 괜찮다.
디시전트리는 기준이 되어줄 수 있어서 다른 분야에 적용하기 좋다. 해석력이 좋기 때문이다. 타인에게 설명하기 좋다.
랜덤포레스트
결정트리의 단점인 오버피팅을 극복하는 장점이 있다.
-
프로세스
1) 인풋된 데이터의 피처 중 랜덤하게 n 개의 피처를 선택(max_features) -> 하나의트리
2) 또 랜덤하게 n개의 피처를 선택..반복 -> m 개의 트리(\n_estimators)
3) 하나의 트리에서 랜덤하게 데이터를 뽑는다(max_samples)
4) 트리(Decision-tree)마다 최대 가지수를 제한한다.(max_depth) -
부트스트랩 샘플링
n개의 샘플을 복원추출로 n번 추출하는 것. 스스로, 외부 도움없이라는 의미. 외부의 도움 없이 (추가적인 데이터 수집 없이) 주어진 샘플의 데이터만을 이용해 스스로 무엇인가를 해내는 말이다. -
배깅
부트스트랩(Bootstrap) + 집계(Aggregating). 부트스트랩을 통해 여러 분류기를 만들고 그 결과를 통합하는 어그리게이팅 과정을 포함한다. 의사결정나무의 경우 분산이 높다는 단점이 있는데, 배깅을 의사결정나무에 적용한다면 여러 개의 의사결정나무의 예측을 투표함으로서 분산을 낮추고 성능을 향상시킬 수 있다. -
max_features
디폴트는 sqrt -> 경험적 규칙으로 모든 피처 개수의 제곱근 개수 (총 피처 4개면 2개 선택). 피처선택은 딱히 도메인 지식이 중요하지 않다. 정수로 적을시 개수, 0~1 사이로 적을시 퍼센트 Decision-tree. -
featureimportances
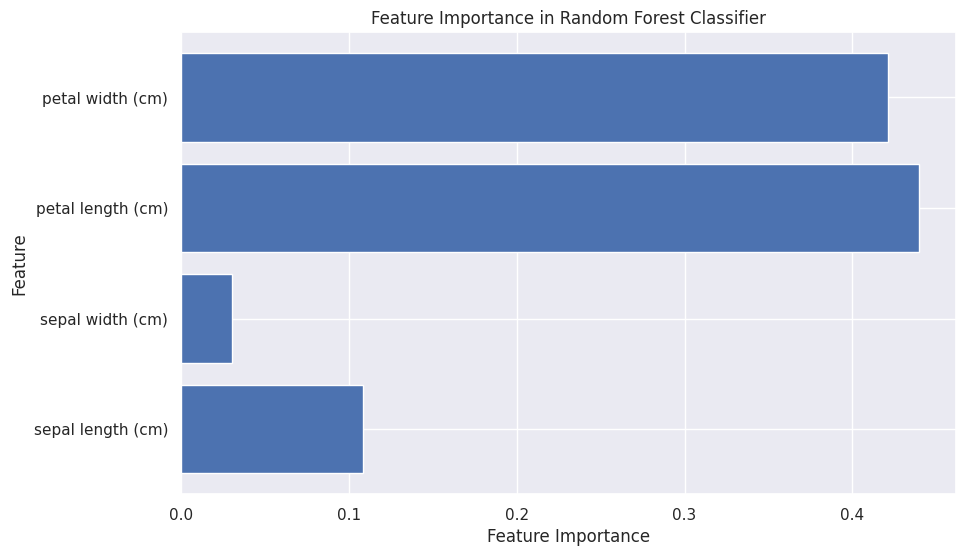
모델이 어떤 것을 위주로 해석 하였는지 판단할 수 있다.
📌 Neural Network
딥러닝은 비선형적 구조이다.
머신러닝은 선형적인 구조
-
선형 함수는 아무리 쌓아도 선형합수이다. 아무리 결합해도 또 다른 선형함수가 나온다.
따라서 활성함수는 비선형 함수를 준다. -
비선형변환 - 활성활함수
딥러닝에서 가장 중요한 것
신경망의 각 노드에 적용되어 입력 데이터를 비선형으로 변환
머신러닝에서는 이러한 비선형 변환을 통해 특성 공간을 확장하고, 모델의 예측 성능 향상 -
편향 노드(bias node)
출력되는 값은 1이다.
모델의 표현성과 유연성이 좋아진다. -
출력 노드 개수
노드가 sigmiod() 는 노드가 1개이고 쓰레드 홀드 값을 줘야한다.
softmax() 는 노드가 2개 -
비용함수
문제의 종류에 따라서 쓰임이 달라진다.
회귀문제 - MSE
분류문제 - 교차엔트로피 -
신경망에서의 파라미터
학습 : 비용함수를 최소화하는 모형의 파라미터값을 탐색
따라서 가중치와 바이어스가 파라미터이다. -
일반적인 작동방식
입력노드 : 입력된 값을 그대로 출력
은닉노드 : 입력받은 값을 활성화함수로 변환하여 출력 relu
출력노드 : 회귀문제 함수사용 x, 다중분류문제 : 소프트맥스함수 사용, 이중분류문제 : 시그모이드함수 사용
📖 흥미로운 점 / 새로 알게된 점
-
help() 를 사용해서 머신러닝의 파라미터를 볼 수 있다.
-
랜덤포레스트 random_state
랜덤포레스트에서 여러 트리가 만들어질때 선택되어지는 피처는 랜덤하다. 이것을 특정하게 고정하는 것이다. -
랜덤포래스트 트리 규칙을 보기 (아이리스 데이터)
from sklearn.tree import plot_tree
plt.figure(figsize=(20,10))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()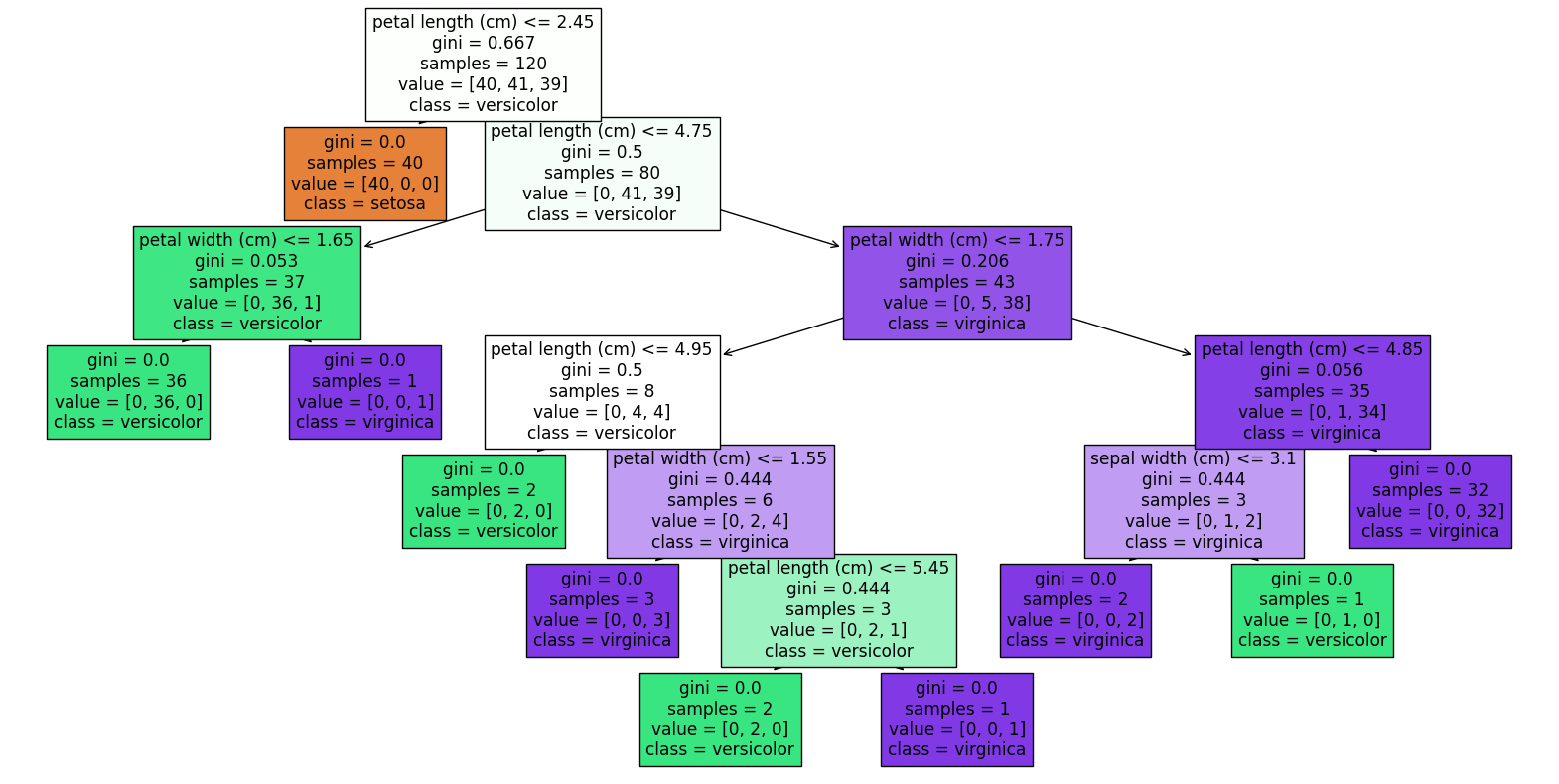
-> 전문지식이 없는 사람에게도 의사결정의 이유를 설명하기 유리하다.
- 랜덤포래스트 트리 규칙을 텍스트로 보기
from sklearn.tree import DecisionTreeClassifier, export_text
tree_rules = export_text(clf, feature_names=iris.feature_names)
print(tree_rules)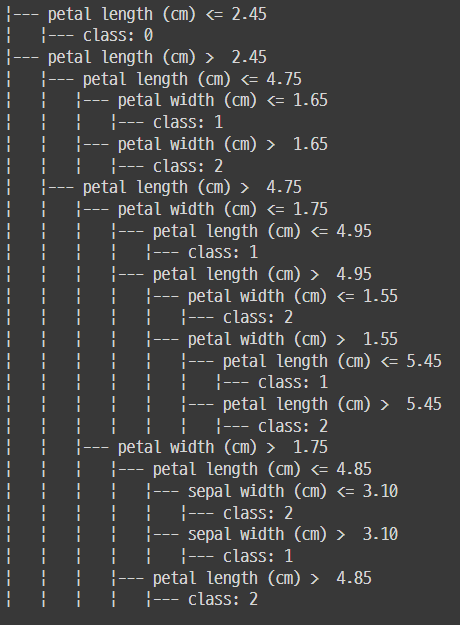
-> 전문지식이 없는 사람에게도 의사결정의 이유를 설명하기 유리하다.
📖 어려운 부분
-
어떤 랜덤니스가 있냐 -> 피처의 개수가 뽑히는 알 수 없다 random_state로 고정-> 우리의 의지대로만 돌아가고 싶다.
-
부트스트랩 : 복원 추출, 보통 원본과 동일한 크기의 샘플 추출
📖 이후 학습 계획
- 공공데이터 활용 프로젝트 - 주제선정
