
📖 학습한 내용
- 집값 예측 모델 생성
- 모델평가
- 샘플링
- 마이닝 알고리즘
- Data Preparation
📖 핵심내용
📌 집값 예측모델 생성
-
스케일링
스케일링을 하지 않으면 설계자의 의도하지 않았는데, 어떤 특징피처가 가장 큰 비중을 차지하는 것.
각 값에 대한 편차가 크면 숫자가 큰 쪽으로 학습되기 때문이다.
따라서 차이가 큰것을 일정한 비율로 줄여주는 것이 스케일링이다. 예시) 피처가 키(cm), 연봉(천만원) -
Iteration: 하나의 batch를 사용하여 모델을 한 번 업데이트하는 과정
가중치 업데이트는 이터레이션 단위로한다.
전체/배치사이즈 -
정규화는 스케일링이다.
📌 모델평가
-
confusion matrix
accuracy만으로는 판단하기 어려운 것
베이스라인보다 좋아야한다. -> 확률보다 높아야한다.
정답라벨이 매우 불균형하면 그것보다 성능이 좋아야한다.
예시) 빨간공 2개 파란공 8개일때 파란공 뽑을확률 80%보다 모델 성능이 좋아야한다. -
문제에 따라서 프리시즌과 리콜을 중요하게 생각하는 것이 다르다.
-
f1score
F1 점수가 1에 가까운 경우: 모델이 양성을 예측하는 데 있어서 매우 정확, 실제 양성 사례 대부분을 정확히 감지해냈다는 의미
F1 점수가 낮은 경우: 모델이 양성을 예측하는 데 있어서 정확도가 떨어지거나, 실제 양성 사례들을 놓치고 있다는 의미
- 결국 accuracy, f1score, precision, recall 을 중요하게 봐야한다.
- 모델 성능평가 할때는 원래 데이터로 해야한다. 불균형해서 샘플링한 데이터를 기준으로 하면 안된다.
- 성능평가표
변수 - 모델링할때 인풋으로 입력된 피처. 변수 선택은 좋은 피처 소수로 잡는게 더 좋을 수 있다.
과정을 기록하면서 가야 편리하다.
📌 샘플링
샘플을 가지고 전체 모집단을 추론하는 것
무작위성이 매우 중요하다. 임의로 모델성능을 좋게하기 위해서 조작하면 안된다.
빅데이터 시대에서 통계..
슈퍼모집단 - 내가 취득한 표본이든 모집단???
벡데이터 시대에도 표본을 기본으로한 전통적인 방법들은 유효하다.
- 단순 임의 추출
임의성이 중요하다.
평향되지 않도록 해야한다.
- 계통샘플링(체계적 추출)
공장에서 샘플링할때 많이 사용한다.
모집단에 대한 데이터 목록이 정렬되어 있거나 데이터에 규칙적인 패턴이 있는 경우에 유용
-
층화 임의 추출
계층별로 임의 추출하는 것. 각클러스터 별로 비율도 맞춰야한다. -
군집추출
여러 군집으로 나누고 군집 통체로 하나 샘플링
군집이 전체를 잘 반영한다면 사용
- 비확률적 샘플링을 했다면, 샘플링을 어떻게 했는지 리포트에 반드시 명확히 밝혀야한다.
머신러닝 적용
데이터 분포 : 데이터 편향이 있는 경우 층화 샘플링 같은 방법을 사용하여 각범주의 데이터가 샘플에 균등하게 표현되도록해야한다.
샘플링 과정의 재현성: 실험의 재현성을 위해 샘플링 과정을 명확히 문서화하고, 고정된 시드값을 사용하여 샘플링을 수행
-> random seed 값을 고정하여 같은 결과가 나올 수 있게해야한다.
📌 마이닝 알고리즘 - 모델링
이진분류는 SVM이 가장 성능이 좋을때가 많다.
-
지도학습 (supervised learnig)
x->y 로 맵핑하는 모델을 훈련을 할 수 있다면, 예측할 수 있다.
어떤 문제가 있다면, labeled data로 만들 수 있을지 고민하고, 만들 수 있다면 딥러닝으로 해결 할 수 있다. -
이진분류로 여러 클래스 구분하기
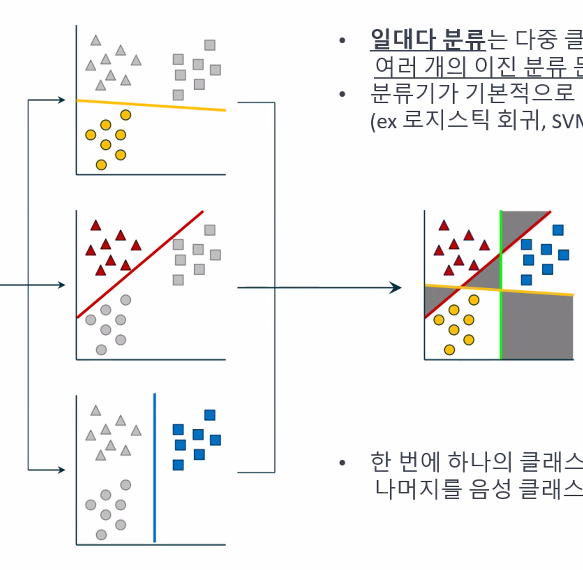
-> 분류기가 이진분류일 때 이용
-> 속도가 빠른 장점이 있다.
-
회귀모델은 베이스라인이란 최소 확률은 평균값과의 오차보다는 좋아야한다.
모델링 할때는 베이스 라인을 잘 생각해야한다. -
trade off
언더피팅과 오버피팅 사이의 지점을 적절히 잘 학습시켜야한다.
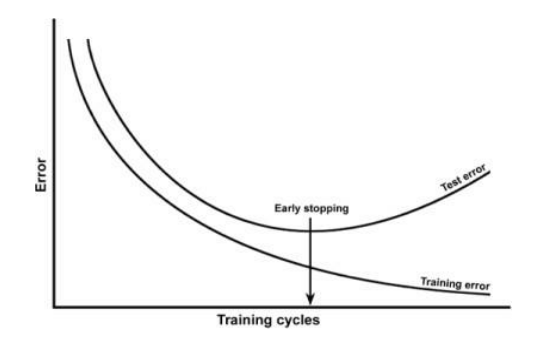
-> 학습데이터의 에러만 줄어들고, 검증데이터의 에러가 늘어나고 있다. 이것은 학습데이터만 너무 잘맞게 세팅이 되기 때문이다. -
clustering 군집화
비슷한 속성을 가진 군집을 하고, 그것을 해석해야하고 응용해야한다. -
클러스트링 의미
각 데이터 별로 클러스터 라벨을 붙인다. 그것이 해석의 시작이다.
타이타닉이면 생존예측에 어떻게 쓸 것인지, 회귀문제라면 얼마나 더 답을 맞추는데 도움이 될지 생각
마케팅이면 추천 시스템에 적용할 수 있다.
추천 시스템의 베이스 라인은, 모델링 안하고 베스트셀러 추천의 오차율 보다 적어야한다. 모델링 한게 무조건 베스트 셀러만 추천하는 것보다 더 오차가 적어야한다. -
수학적으로 비슷하다는 것이란?
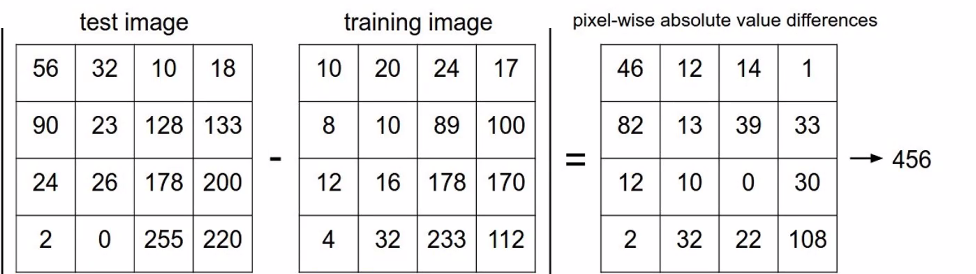
두 이미지 픽셀의 값의 차이의 합이 작을 수록 비슷하다. -
K-means 클러스트링 맛보기
k의 의미는 클러스트릐 개수를 의미한다. 설계자의 의도가 들어갈 수 있다. -
K-Nearest Neighbor
k의 의미는 가까운 데이터의 개수
k의 숫자에 따라서 계속 속하는 곳이 달라진다 -
맨하튼 거리와 유클리드 거리
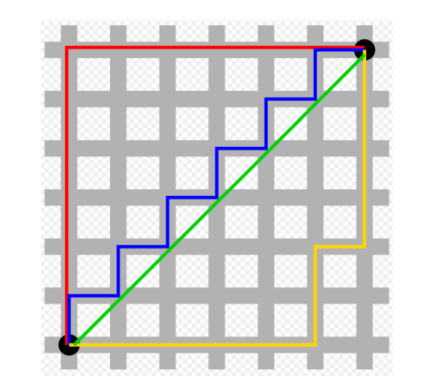
-> 맨하튼 거리는 빨간색, 파란색, 노란색
-> 유클리드 거리는 초록색 -
좌표 위의 점 의미
벡터공간, 좌표공간, 위상공간 위에 점은 각각의 특성을 나타낸다.
따라서 벡터 공간 위의 어떤 점과 점 사이의 거리는 유사도를 나타낸다.
키와 몸무게를 나타내는 2차원공간에서 모여있는 점은 비슷한 체형임을 알 수 있다.
마찬가지로 이미지를 벡터로 표현하여(픽셀값으로 정의) 서로 유사한 것 끼리 묶을 수 있다.
마찬가지로 텍스트 데이터도 단어별로 벡터공간에 올릴 수 있다.
방향의 거리 -> 코사인 각도를 이용해서 잴수 있다.
따라서 유클리드 거리가 멀어도 방향의 거리는 가까울 수 있다.
📌 Data Preparation
데이터 분석에서 가장 중요한 과정이다.

-
데이터마이닝 : 대규모 데이터 집합에서 유의미한 패턴, 규칙, 트렌드 및 관계를 발견하는 과정
-
데이터 전처리 예시

-
데이터 전처리에서는 독립변수 잘 준비해야한다.
-
전처리 프로세스
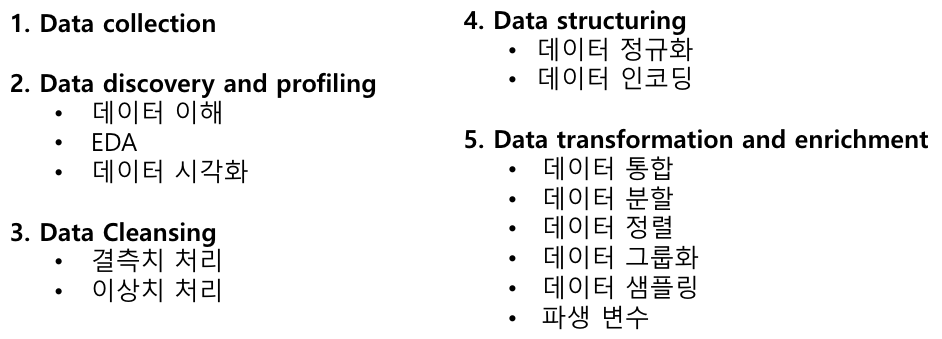
-
시각화를 잘해야한다. 분석과 발표할때 매우 유용하다.
-
파생변수란
원본 데이터의 기존 변수들을 사용하여 새로운 변수를 생성한 것
원-핫 인코딩 같은 카테고리형 변수를 변형하여 만들어진 변수도 포함 -
원핫인코딩의 장점
모델이 특정 범주에 편향되지 않도록 함
주형 변수를 이진 형태로 변환하여 모델이 데이터를 더 쉽게 처리 -
원핫인코딩의 단점
차원의 저주 -> 모델의 복잡성 증가, 과적합(overfitting)의 위험 up
메모리 및 계산 비용 측면에서 비효율 발생
📖 흥미로운 점 / 새로 알게된 점
- 모델을 바꿔가면서 돌릴때 고려해야하는 것

원핫 인코딩과 모델
- 원핫 인코딩은 범주형 데이터가 수치형으로 바뀌기 때문에 유용하다.
1) 로지스틱 회귀(Logistic Regression), 선형 회귀(Linear Regression)
-> 각 특성이 수치형 데이터로 표현되어야 하는 모델들(특성들의 가중치 학습 가능)
2) 서포트 벡터 머신(Support Vector Machines)
-> 범주형 변수 처리 불가
3) 신경망(Neural Networks)
-> 수치형 데이터만 입력 처리
3) 군집화(Clustering) 알고리즘
-> 수치형 데이터를 통해 변수 간의 유사도와 거리를 계산
📖 어려운 부분
-
딥러닝에서 이진분류에서 sigmoid 함수와 쓰레드 홀드를 이용해 0 또는 1로 구분할 수 있다. 따라서 풀력노드를 1개로 할 수 있다.
-
딥러닝에서 통상적인 출력노드 개수는 클래스 개수와 똑같다.
-
데이터프레임에서 카테고리컬 데이터로 변환해야하는지?
.astype('category')는 파이썬의 판다스(Pandas) 라이브러리에서 사용되는 방법으로, 특정 열을 범주형 데이터 타입으로 변환합니다.
범주형 데이터 변환
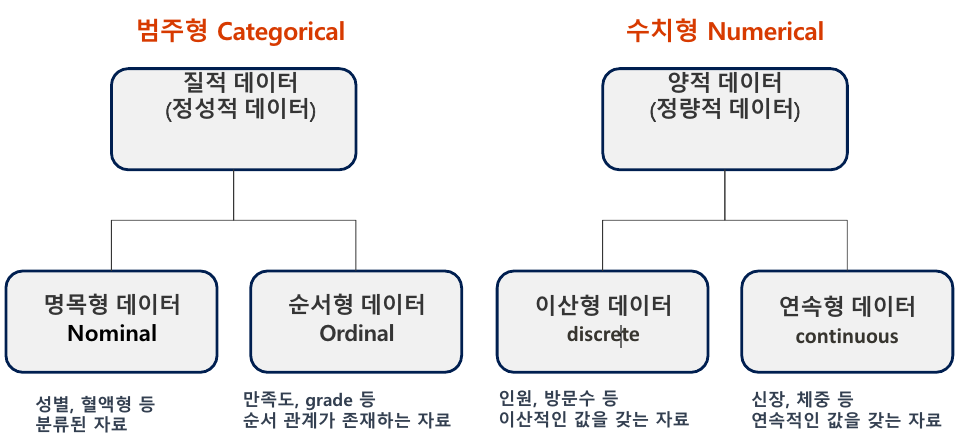
- 범주형-명목형데이터 변환
원핫인코딩
1) get_dummies 코드 사용법
df = pd.merge(df, new_embarked, left_index=True, right_index=True)-> 데이터프레임에서 사용
2) OneHotEncoder()
from sklearn.preprocessing import OneHotEncoder
# 샘플 데이터
data = pd.DataFrame({
'color': ['red', 'green', 'blue', 'green', 'red']
})
# 데이터의 타입을 범주형으로 지정
data['color'] = data['color'].astype('category')
# 원-핫 인코더 생성
one_hot_encoder = OneHotEncoder(sparse=False)
# 원-핫 인코딩 수행
encoded_data = one_hot_encoder.fit_transform(data[['color']])-> 배열에서 사용
- 범주형-순서형데이터 변환
1) maping 사용
import pandas as pd
# 샘플 데이터
data = pd.DataFrame({
'rating': ['Low', 'Medium', 'High', 'Medium', 'Low']
})
# 매핑 정의
mapping = {'Low': 0, 'Medium': 1, 'High': 2}
# 순서형 데이터 변환
data['rating_encoded'] = data['rating'].map(mapping)-> 데이터프레임에서 사용
2) OrdinalEncoder
from sklearn.preprocessing import OrdinalEncoder
# 샘플 데이터 (배열 형태)
data = np.array(['Low', 'Medium', 'High', 'Medium', 'Low']).reshape(-1, 1)
# 순서형 인코더 생성
ordinal_encoder = OrdinalEncoder(categories=[['Low', 'Medium', 'High']])
# 순서형 데이터 변환
encoded_data = ordinal_encoder.fit_transform(data)-> 배열에서 사용
📖 이후 학습 계획
-
모델 결과 분석(평가지표, 결과 시각화/모델 해석 도구, 적용)
-
결측치 채우는 방법 중 'SMOTE, KNN 같은 방법을 사용해서 근사한 instance의 값으로 대체'가 무슨말인지 알아볼 것
-
박스플랏 의미 다시 살펴보기
