
📖 학습한 내용
- 행정구역별 인구수 예측모델 생성 3일차
데이터 조사 및 취합
📖 핵심내용
📌 행정구역별 인구수 예측모델 생성
데이터 조사 및 취합
기존 데이터에 조사한 내용 취합
월단위로 있는 데이터와 년단위로 있는 데이터 파일 2개로 구분
월단위 파일
소비자물가지수, 비경제활동인구 (천명), 실업률 (%), 아파트 매매수급동향, 연립다세대 매매수급동향, 단독주택 매매수급동향
- 결측치 확인
소비자 물자지수
경향을 확인
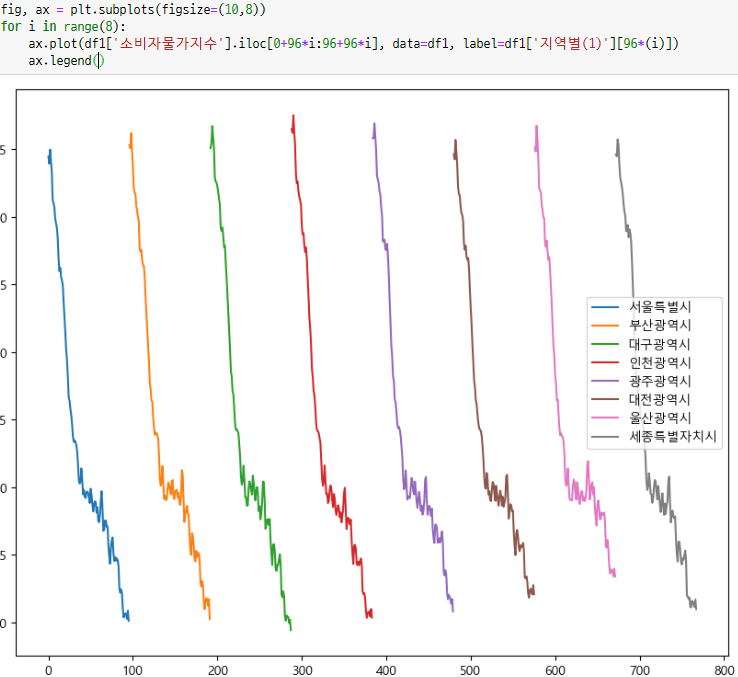
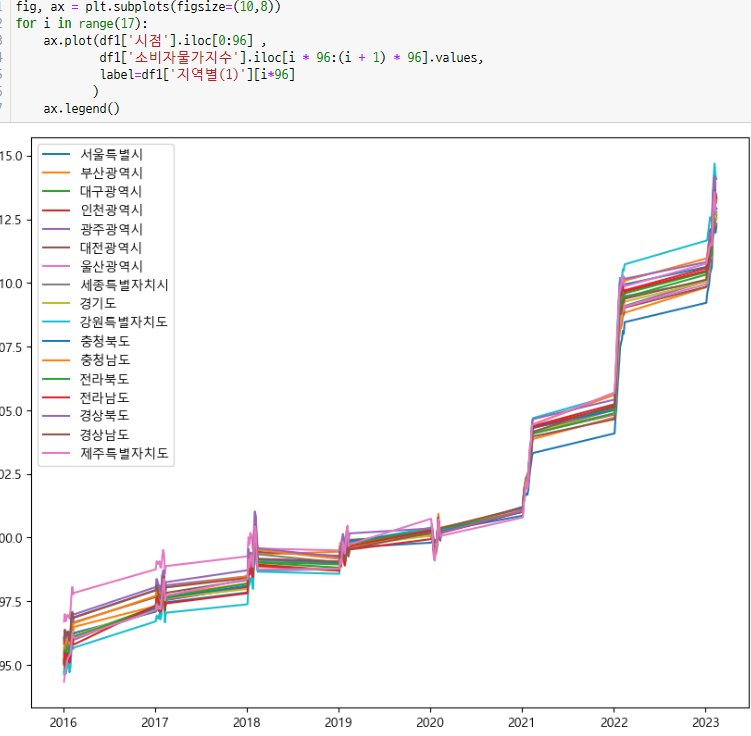
-> 전국이 비슷하게 가는 것을 알 수 있다. 이를 이용해서 회귀모델로 결측치를 채울 수 있다고 생각
- 지역 - 소비자 물가지수 데이터프레임 이용
지역-소비자물가지수 데이터프레임 생성
data = {}
for i in range(17):
data[df['지역별(1)'][i*96]] = df1['소비자물가지수'].iloc[i * 96:(i + 1) * 96].values세종시 인덱스 48~95가 결측값인 것을 알고 있으므로 0~48 인덱스 데이터로 훈련
- OLS 회귀 모델 생성
X_train = sm.add_constant(X_train)
X_test = sm.add_constant(X_test)
lm = sm.OLS(y_train, X_train).fit()
pred = lm.predict(X_test)
fig, ax = plt.subplots(figsize=(10,6))
sns.scatterplot(x=y_test, y=pred , ax=ax)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'r', ls='--', lw=1)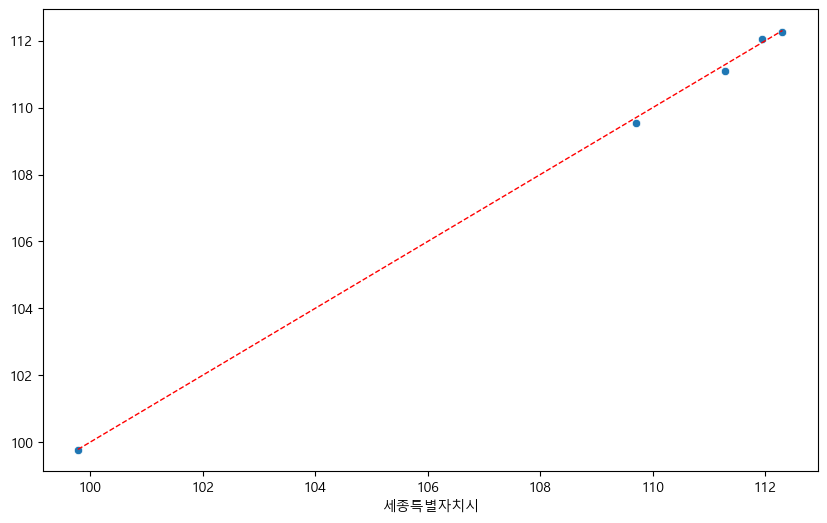
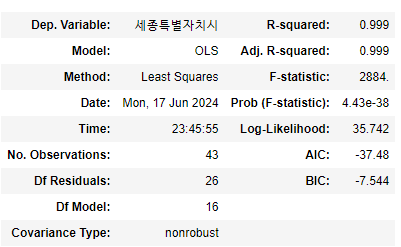
-> 결정 계수 (R-squared): 0.999 로 매우 높아 변동성을 잘 반영하고 있고,
-> F-statistic: 2884 이 매우 높으므로 통계적으로 유의미하다고 해석 할 수 있다.
- 모델로 결측치 채우기
df1.loc[720:767, '소비자물가지수'] = pred.values-> iloc로는 데이터 프레임의 값을 변결할 수 없다는 것을 알았다.
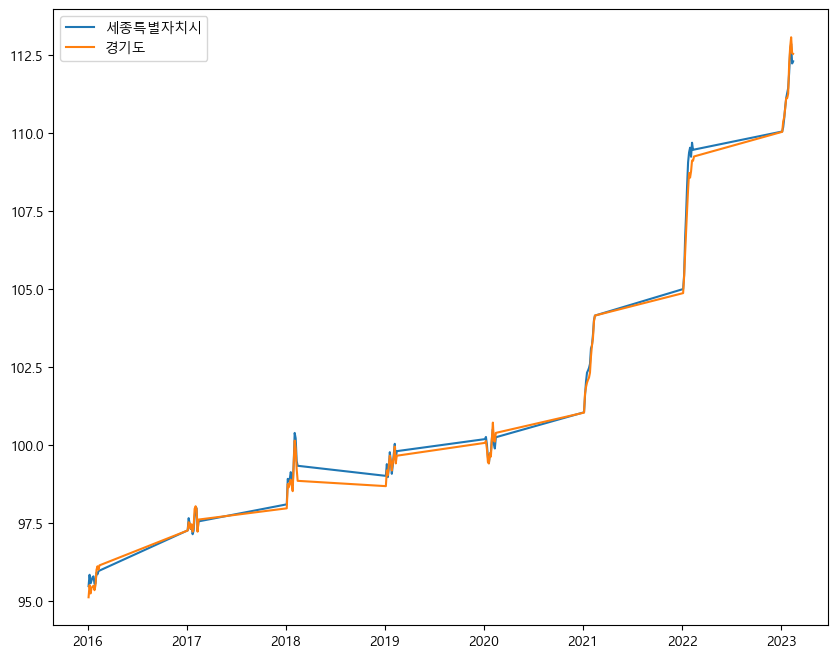
-> 잘 반영된 것을 알 수 있다.
비경제활동인구
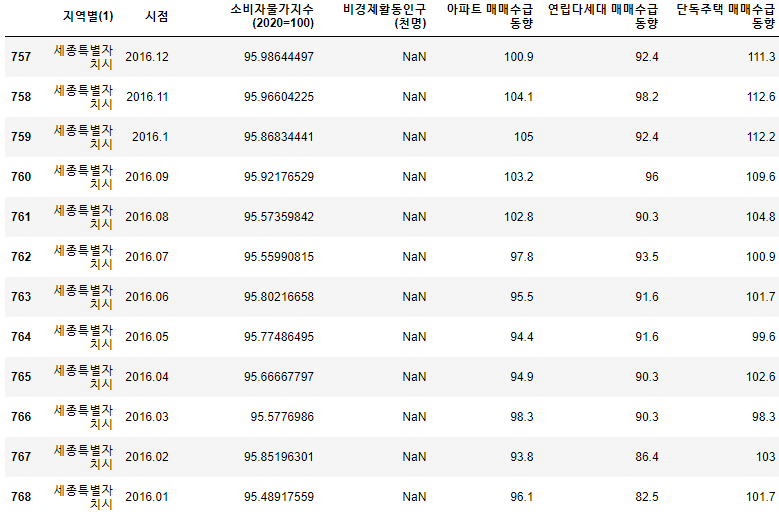
-> 세종특별자치시 2016년 데이터가 결측임을 확인. 인터넷 검색을 했지만 나오지 않음.
따라서 임의로 채우기로 함
-
EDA 경향 확인하기
전국적인 경향 확인
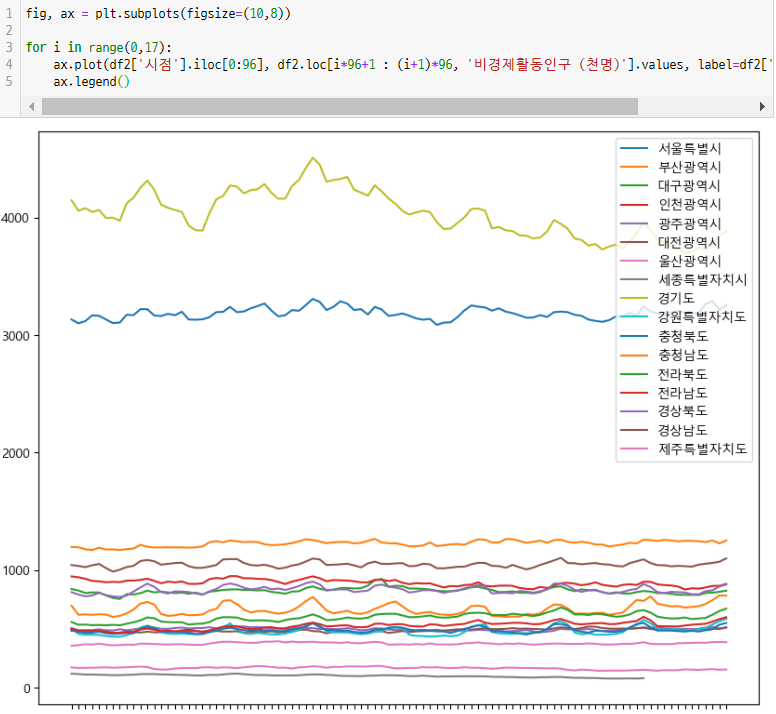
-> 딱히 시도 로 나눴을때 뭔가 보이지 않는다.세종시의 경향 확인
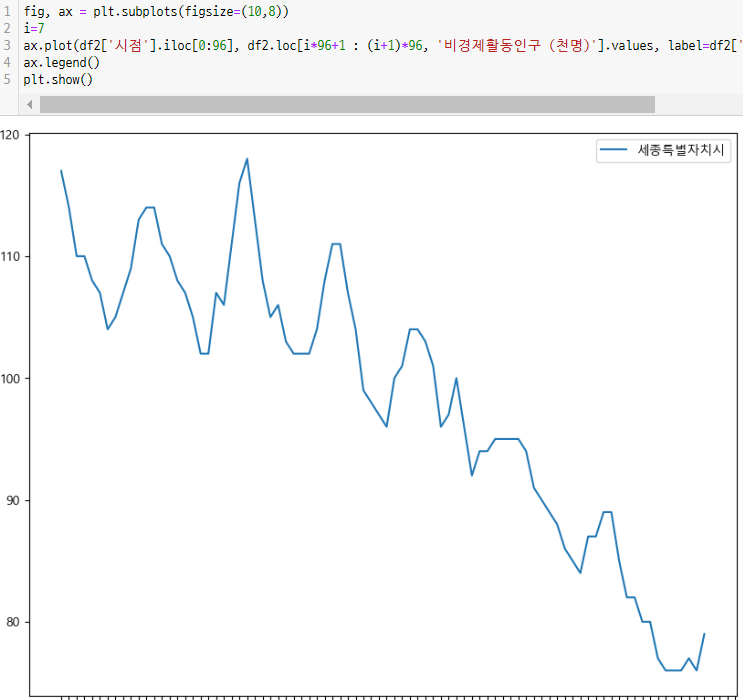
-> 그래프의 모양을 보니선형회귀로 해결할 수 있다는 생각이 들었다. -
linear regression 이용
이번에는 데이터 프레임을 만들지 않고 배열로 바로 풀이nan인 인덱스와 아닌 인덱스로 배열을 나눈다
idx = ~np.isnan(data[0]) nan_idx = np.isnan(data[0])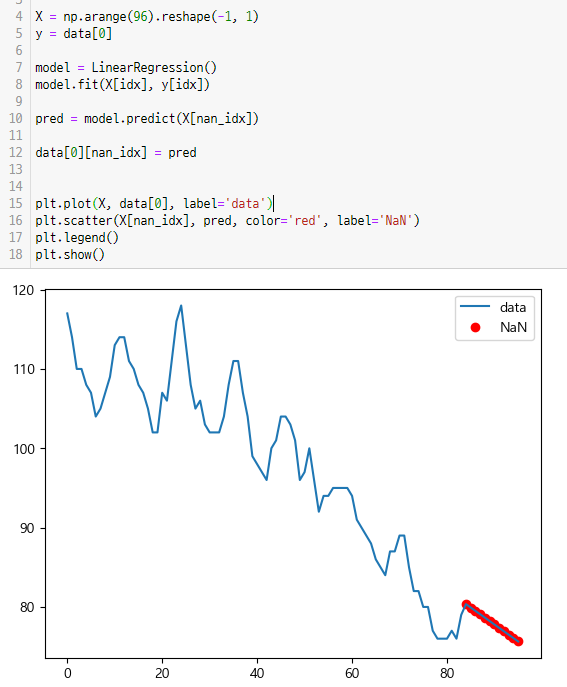
-
결측치 채우고 확인
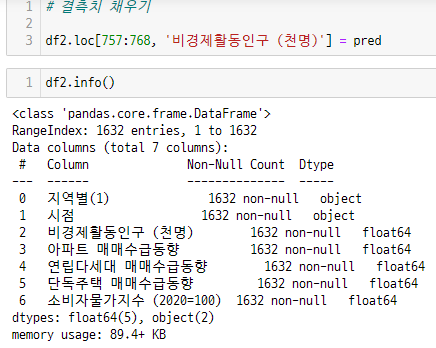
기타
실업률 (%), 아파트 매매수급동향, 연립다세대 매매수급동향, 단독주택 매매수급동향
실업률은 다른 조원이 해서 드랍
매매수급동향은 결측이 없어서 형식을 float으로 변경
년단위 파일
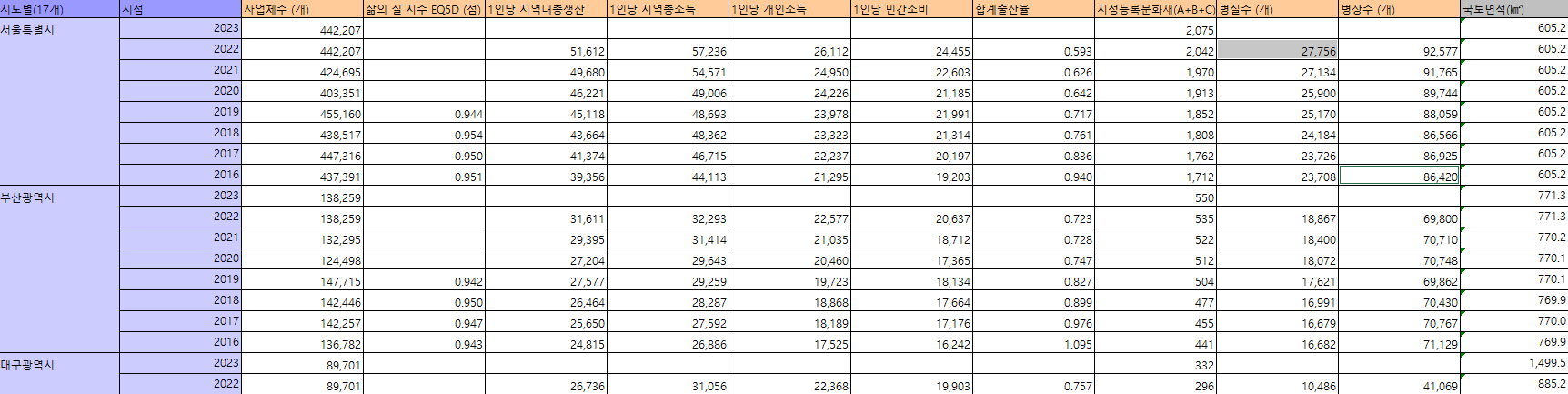
사업체수 (개), 삶의 질 지수 EQ5D (점), 1인당 지역내총생산, 1인당 지역총소득, 1인당 개인소득, 1인당 민간소비, 합계출산율, 지정등록문화재(A+B+C), 병실수 (개), 병상수 (개), 국토면적(㎢)
-
피처 선택
모두 사용하면 좋은 파일이지만, 년단위로 있기에 월단위로 하면 결측이 없을 사업체수, 지정등록문화재, 국토 면적 선택 -
데이터 개수 늘리기
-
데이터 타입 수정
중간에 ',' 이 있어서 문자형이므로 변환 시켜주고 float 타입으로 변경
df3['국토면적(㎢)'] = df3['국토면적(㎢)'].str.replace(',', '').astype(float)
df3[['사업체수 (개)','지정등록문화재(A+B+C)']] = df3[['사업체수 (개)','지정등록문화재(A+B+C)']].astype(float)
최종
엑셀에서 디테일 수정하고, 형식을 맞춰서 다른 파일과 병합할 수 있는 형태로 변경
📖 흥미로운 점 / 새로 알게된 점
- 숫자의 3자리 분리 기호 ',' 제거
df3['국토면적(㎢)'] = df3['국토면적(㎢)'].str.replace(',', '').astype(float)-> 문자형으로 변경하고 ','을 공백으로 대체한다. 그 뒤 실수형으로 변경
- 데이터프레임 데이터 전체 반복
tmp = pd.DataFrame(data)
# 각 행의 데이터를 12번 반복
repeated_data = np.repeat(tmp.values, 12, axis=0)
df3 = pd.DataFrame(repeated_data, columns=df.columns)-> np.repeat 함수는 배열을 정해진 횟수만큼 통채로 반복한다. 이를 이용해서 values와 함께 사용
- 결측, 결측이 아닌 배열 인덱스 받기
idx = ~np.isnan(data[0])
nan_idx = np.isnan(data[0])-> T/F 를 반환하기에 배열에서 인덱스처럼 쓸 수 있는 점을 이용하는 아이디어!
📖 어려운 부분
- 데이터 자체에 집중해야하는 부분이 어려웠다. 물론 아직 코딩이 원하는데로 되지 않아서 답답하고 힘들지만, 시간이 있으면 결국 해결이된다. 하지만, 데이터는 아무리 찾아봐도 나오지 않는다면, 이를 해결할 수 있는 다른 데이터를 찾아봐야하고, 연관 있는지 확인해야하고, 그래프를 이렇게 저렇게 그려가면서 살펴봐야하는 점이 시간이 많이 걸렸다.
📖 이후 학습 계획
- 팀원과 함께 모은 피처들을 취합 했으니, 본격적인 EDA를 시작하겠다.
