
📖 학습한 내용
- 행정구역별 인구수 예측모델 생성 - 데이터 전처리, 모델 생성과 EDA
📖 핵심내용
📌 행정구역별 인구수 예측모델 생성
데이터 전처리
결측치 채우기
각각의 컬럼들을 지역별로 시간의 흐름에따라 변화를 그래프로 살펴보기

- '소비자물가 등락률 (%)'
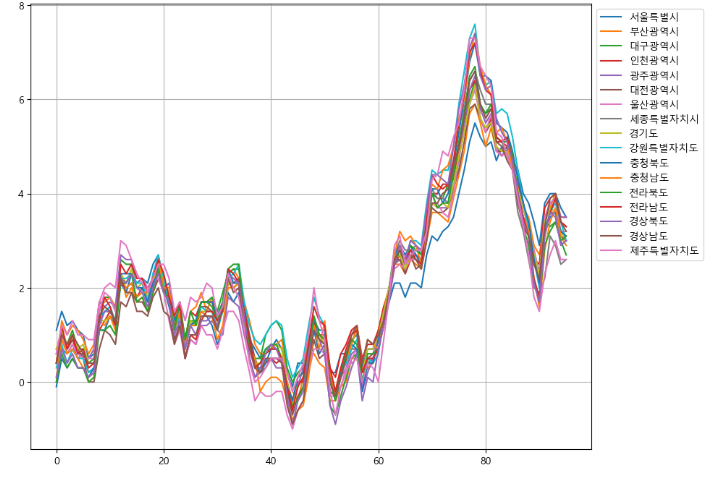
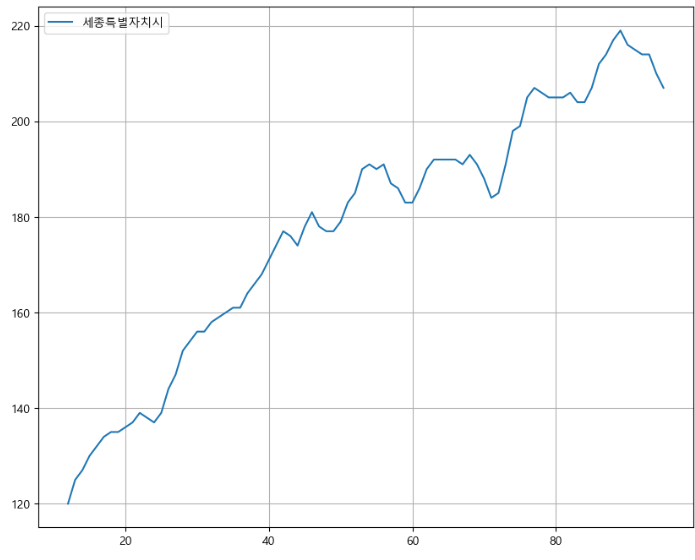
-> 세종시가 0~60까지 데이터가 없지만 전체적인 경향이 비슷하기에 선형회귀로 결측치를 채울 수 있다. - OLS 방식을 이용
# 인덱스 0~35까지 훈련 모델
X_train = df_nan.drop(['세종특별자치시'],axis=1).loc[:35]
y_train = df_nan.loc[:35,'세종특별자치시']
X = df_nan.drop(['세종특별자치시'],axis=1).loc[36:]
X_train = sm.add_constant(X_train)
X = sm.add_constant(X)
lm = sm.OLS(y_train, X_train).fit()
pred = lm.predict(X)
df.loc[708:767, '소비자물가 등락률 (%)'] = pred.values-
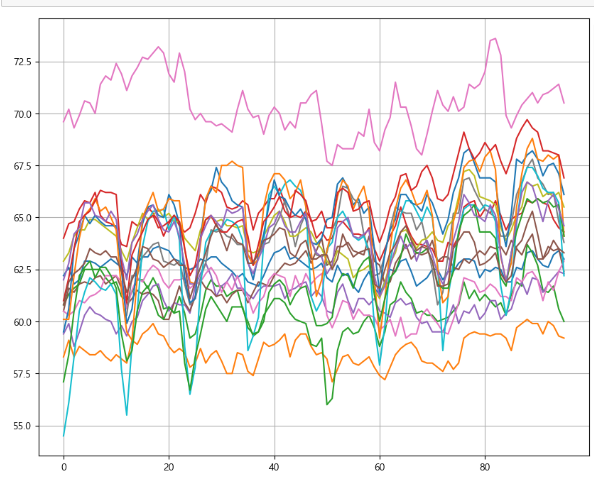
경제활동인구(시도) (천명)
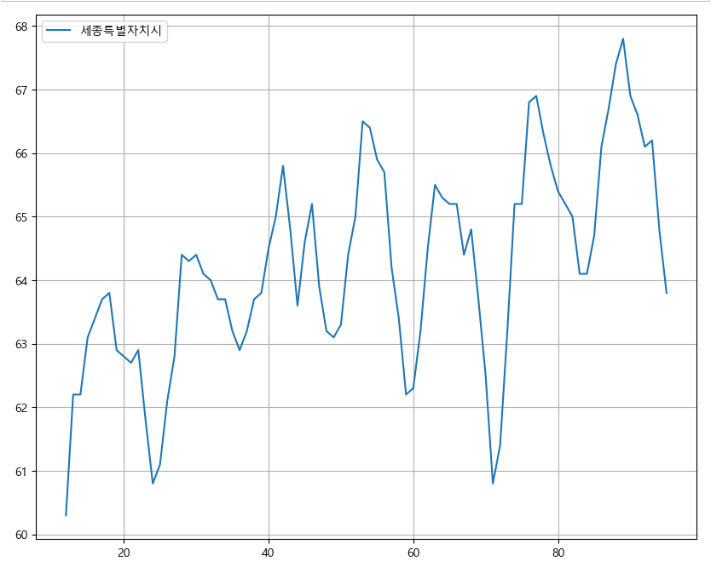
-> 선형적인 모양이 나오는 것을 알 수 있다. 따라서 적정한 값을 결측치에 채워넣기 -
경제활동참가율(시도) (%)
-> 어느정도 등락폭 관련이 있어보인다..
-> 이것도 선형회귀로 어느정 값 예측
- 고용률(시도) (%)
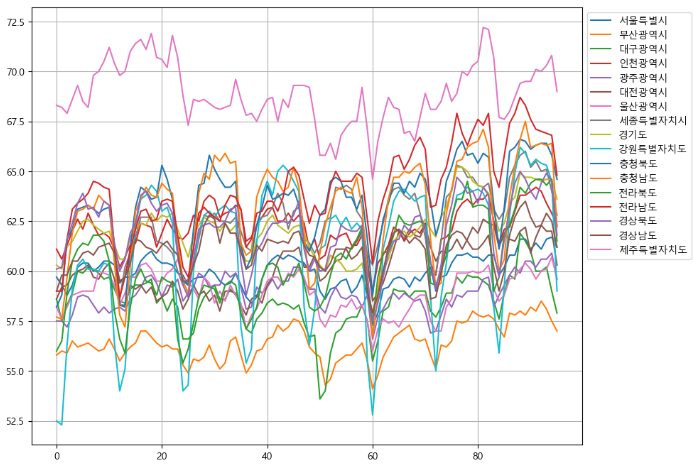
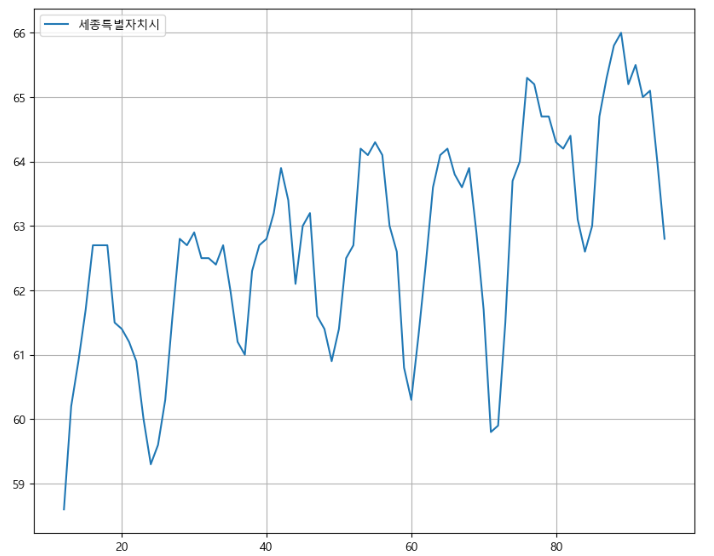
-> 마찬가지로 선형회귀로 어느정 값 예측
데이터 모델 생성
- DT
max_depth=5, random_state=1MSE : 3985836377.05
R^2 : 0.999649706121354
-> R 스퀘어값이 매우 크다.
- DNN
- 모델 설계
input_node = 72, output_node = 1, first_hidden_node = 64, second_hidden_node = 32, third_hidden_node = 16, Dropout(0.2), Adam(learning_rate=0.001), batch_size=5-> MSE 가 82627108864 이 나왔다.
결론 : 값이 정말 말도 안되게 크므로 데이터를 더 자세히 살펴봐야한다. EDA 분석 진행
- 기타 방법
-
feature_selection을 이용해서 상관관계가 높은 피처를 선정해주는데, 이것으로 랜덤포래스트 돌려서 기준 확립
-
랜덤포래스트와 XGBoost의 importance 를 보고, 피처를 선정
EDA
1. 상관관계 분석
-
인구수와 상관관계를 가진 컬럼 추출
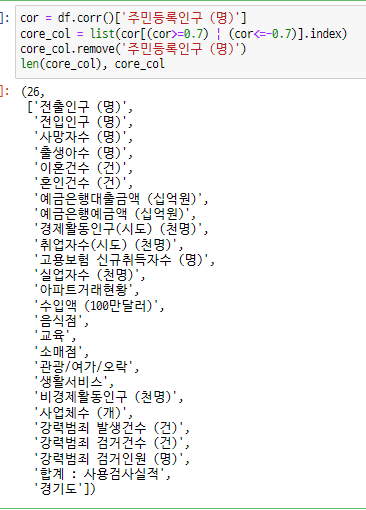
-
추출한 컬럼끼리의 상관관계를 확인
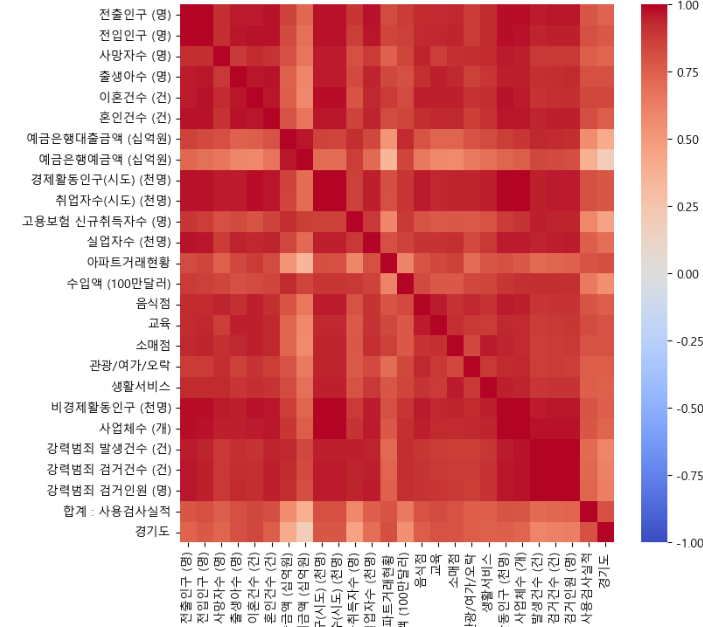
-> 서로 서로 매우 높은 상관관계인 것을 알 수 있다.
-> 그렇다면 반대로 인구수에 매우 영향을 받는 컬럼으로 추측할 수 있다. -
타겟과 상관관계는 높지만 서로의 상관관계는 0.7 이하인 컬럼
인구수에 크게 영향을 주는 독립변수인 것을 알 수 있다.
second_core_col = []
for col in core_col:
if (df[core_col].corr()[col].sum()-1)/(len(df[core_col].corr()['전출인구 (명)'])-1) > 0.75:
second_core_col.append(col)
first_core_col = []
for col in core_col:
if col not in second_core_col:
first_core_col.append(col)
first_core_col - 서로 상관관계가 매우 높은 컬럼을 최종 드랍 후보 선정
dum_list = df[second_core_col].corr()[df[second_core_col].corr() > 0.9].sum()
dum_list[dum_list>15]- 종속변수와 상관관계가 매우 낮은 피처 드랍 후보 선정
cor = df.corr()['주민등록인구 (명)']
dum_low = list(cor[(-0.1<cor) & (cor<0.1)].index)
len(dum_low), dum_low- 드랍 후보들 데이터프레임에서 드랍
thresh_col = dum_high + dum_low
thresh_col.remove('시점')
len(thresh_col), thresh_col2. 이상치 탐색
fig, axes = plt.subplots(8,3, figsize=(15,26))
for i, ax in zip(range(24),axes.flat):
sns.boxplot(data=df, x=df.columns[i], ax=ax)

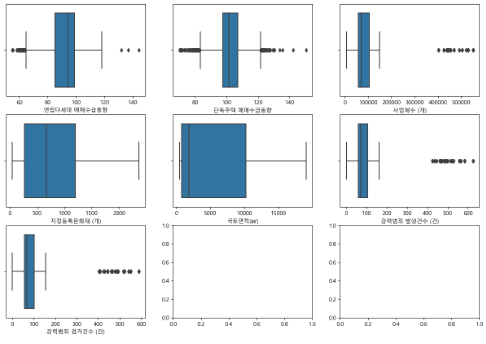
-> 박스플랏을 보면 대부분의 데이터에서 IQR 밖의 값이 매우 많다는 것을 확인 할 수 있다.
-> minmax scaler 와 standard scaler를 사용하기 어려워 보인다.
-> 이상치 밖의 데이터는 연속적이지 않은 경우가 매우 많다.
- 발견한 이상치
그래프상 많이 떨어진 이상치도 단위가 크지 않은 것을 보면 이상치가 아님을 알 수 있다.
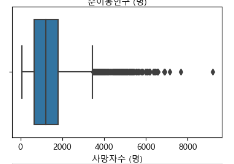
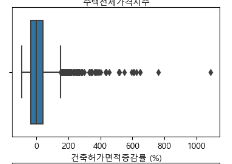
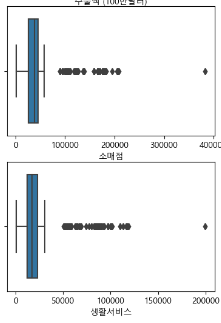
-> 위의 값들은 평균값과 매우 동떨어져있고, 단위도 꽤 큰 것을 알 수 있다. 이상치라고 생각하여 제거
# 이상치 제거
if od_col in list(df_ed.columns):
for i in od_col:
max_value = df_ed[i].max()
df_ed = df_ed[df_ed[i] != max_value]
fig, axes = plt.subplots(3,3, figsize=(15,12))
for i, ax in zip(od_col, axes.flat):
sns.boxplot(data=df_ed, x=df_ed[i], ax=ax)
ax.grid()-> 상관관계에서 드랍한 컬럼이 아니라면 이상치 행 삭제
- 히스토그램으로 데이터 살펴보기
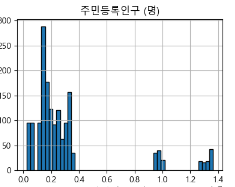
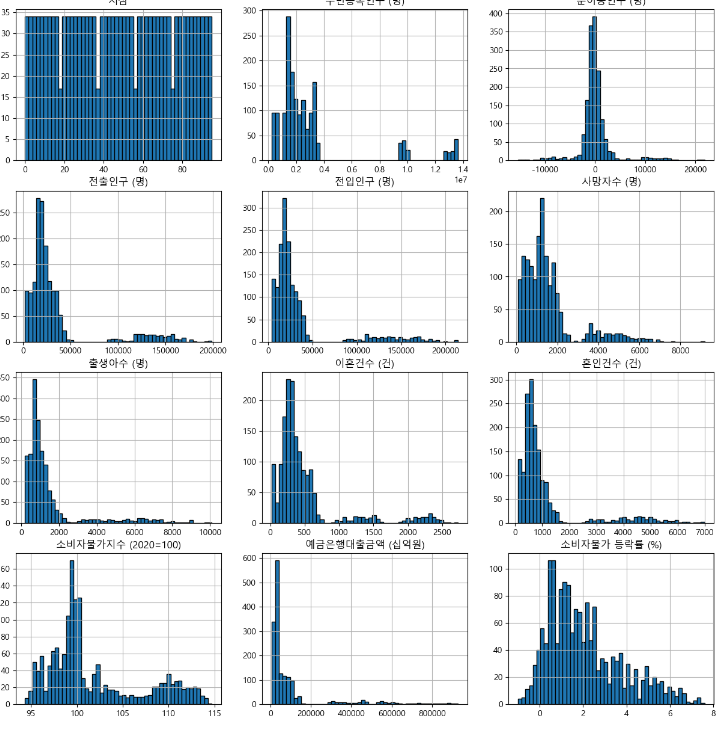
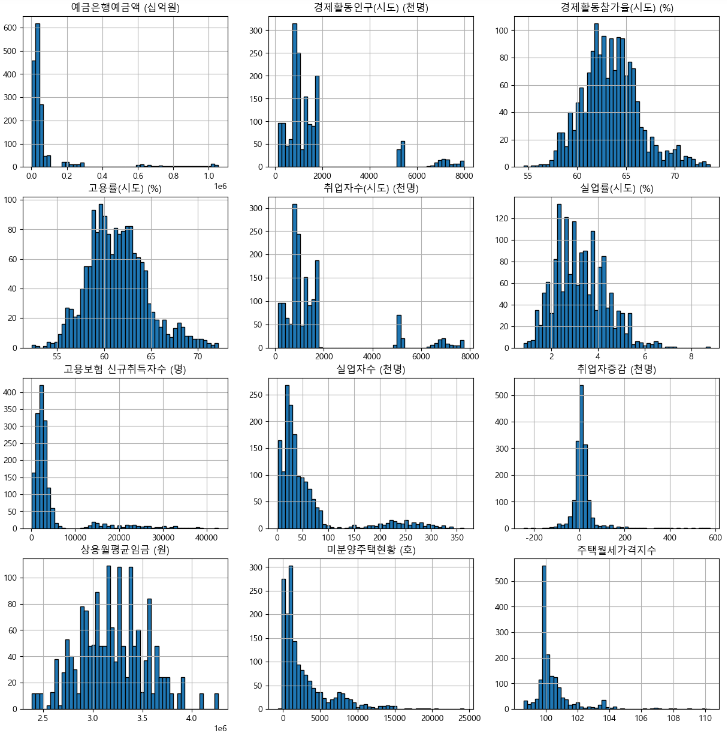
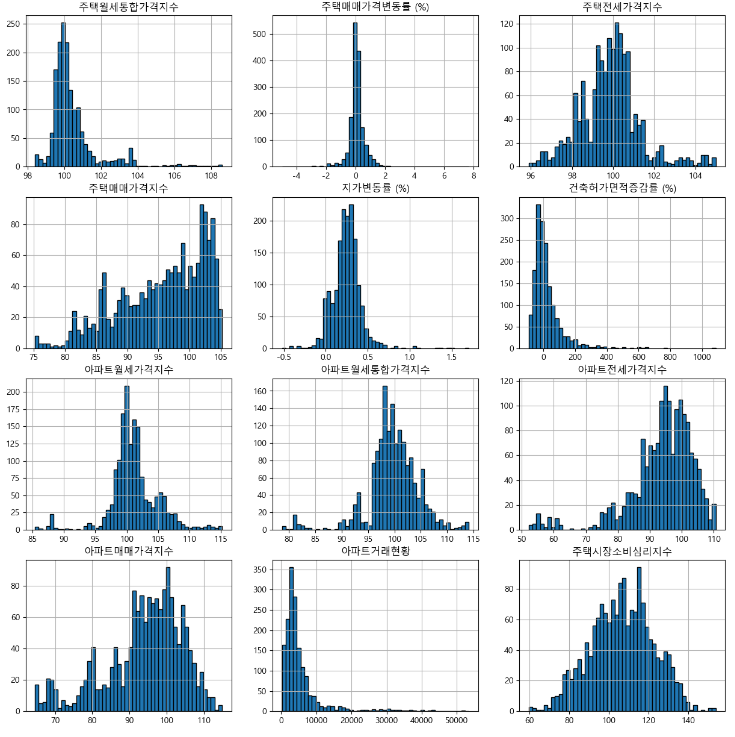
-> 주민등록인구수와 비슷한 모양을 가졌거나, 정규분포형식을 따르는 그래프임을 알 수 있다. 특별히 이상한 점은 알 수가 없었다.
다시 데이터 모델 생성
- 종속변수와 관계가 높은데 다른 컬럼과도 관계가 너무 높은 컬럼, 종속변수와의 관계가 너무 낮은 컬럼은 삭제, 이상치 삭제한 데이터프레임에서 다시 모델을 생성
RobustScaler
rs = RobustScaler()
x_train_sc = rs.fit_transform(x_train)
x_test_sc = rs.transform(x_test)박스플롯을 살펴봤을 때, IQR*3을 넘어가는 데이터들이 대다수 포진하여서, 삭제하지 못했다.
따라서 영향을 덜 받는 RobustScaler 사용
결론
하지만 이렇게 했음에도 R^2 값은 1에 매우 가깝게 나오는 반면에 MSE 값은 너무나도 크다.
왜 이러는 걸까..?
📖 이후 학습 계획
- EDA 및 원인 분석
