
📖 학습한 내용
- 행정구역별 인구수 예측모델 생성
- 경제적요인에 따른 조출생률 전처리와 모델 생성
📖 핵심내용
📌 행정구역별 인구수 예측모델 생성
모델 생성 및 모델평가
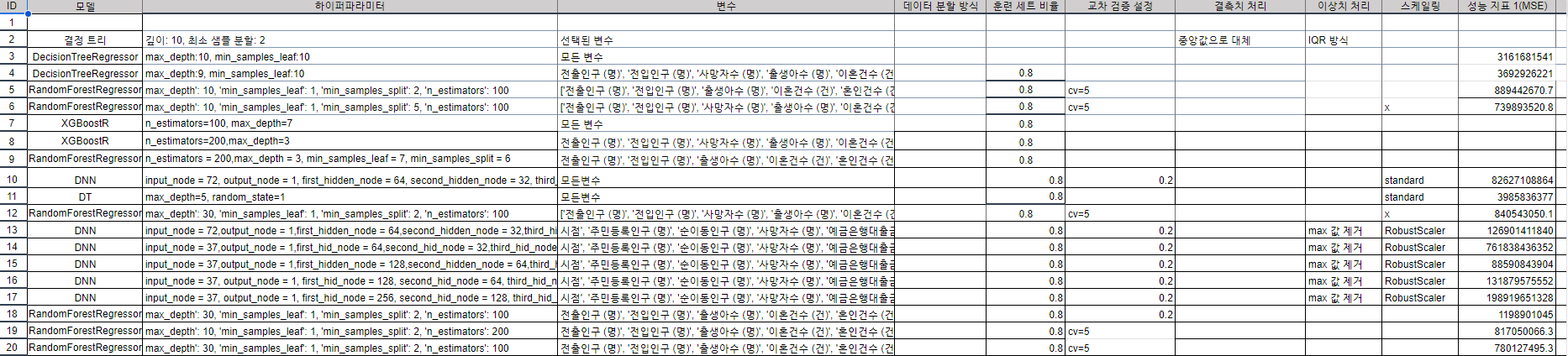
문제점
-
MSE, R^2 이상치
조원들 모두 어제와 마찬가지로 MSE 값이 크게 좋아지지 않는다. 처음부터 워낙 큰수이여서 성능을 개선한다해도 큰 변화는 없다. -
원인과 이유
예측해야하는 데이터가 시단위의 인구수이므로 값이 크다. 따라서 오차의 크기가 클 수 밖에 없다. MSE 의 값이 그래서 크다.
또한 피처들이 너무 인구수와 관련된 데이터이다. 순이동 인구수 같은 경우는 인구수나 다름 없는 독립변수이므로 당연히 제거해야한다. 이런 독립변수 때문에 R^2가 매우 크게 나올 수 밖에 없다.
- 해결 방안
- 컬럼에서 인구수와 관련된 자료는 모두 삭제한다.
- 모은 자료에서 연관지어 새로운 주제 생성
-> 새로운주제 - 경제적요인에 따른 조출생률
-> 출산률에 대한 사회적인 관심이 많고 많은 사람들이 흥미로워할 것이라고 생각하고, 경제와 관련된 지표 데이터가 많기 때문에 선정
📌 경제적요인에 따른 조출생률
데이터 베이스 생성
행정구역별 인구수 예측모델 데이터베이스에 조출생률 추가 및 관련 없는 몇몇 피처 삭제.
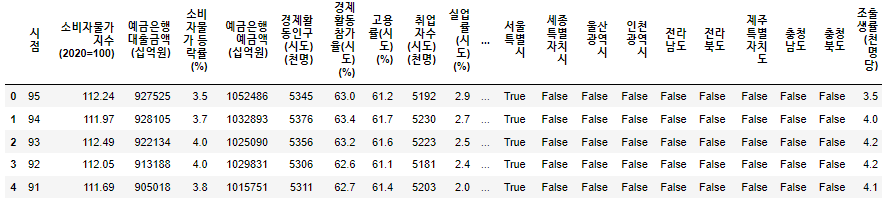

EDA
- 상관관계 분석
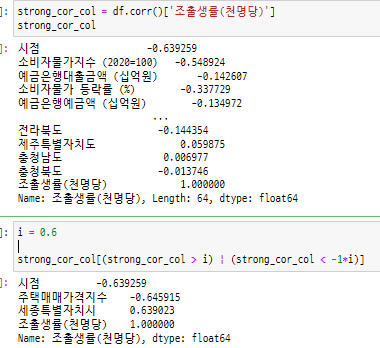
-
데이터이해 - 그래프 생성
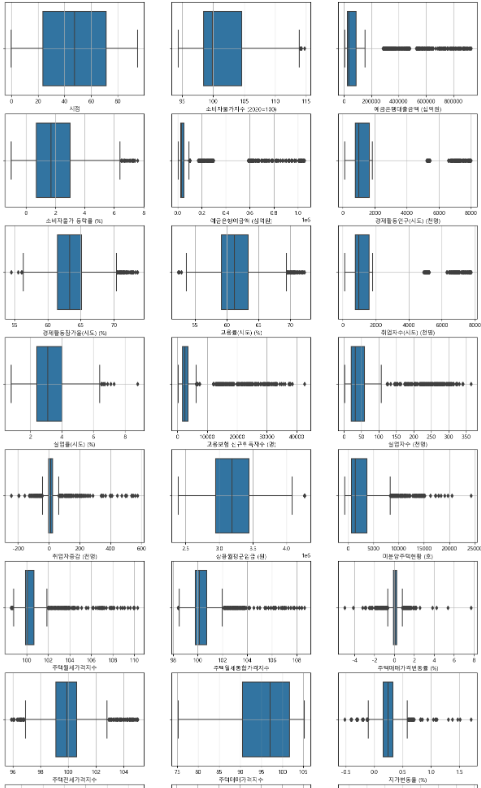
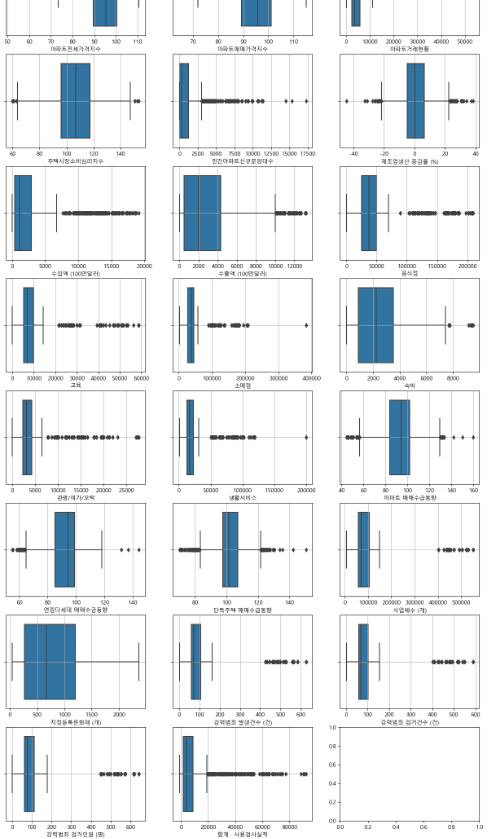
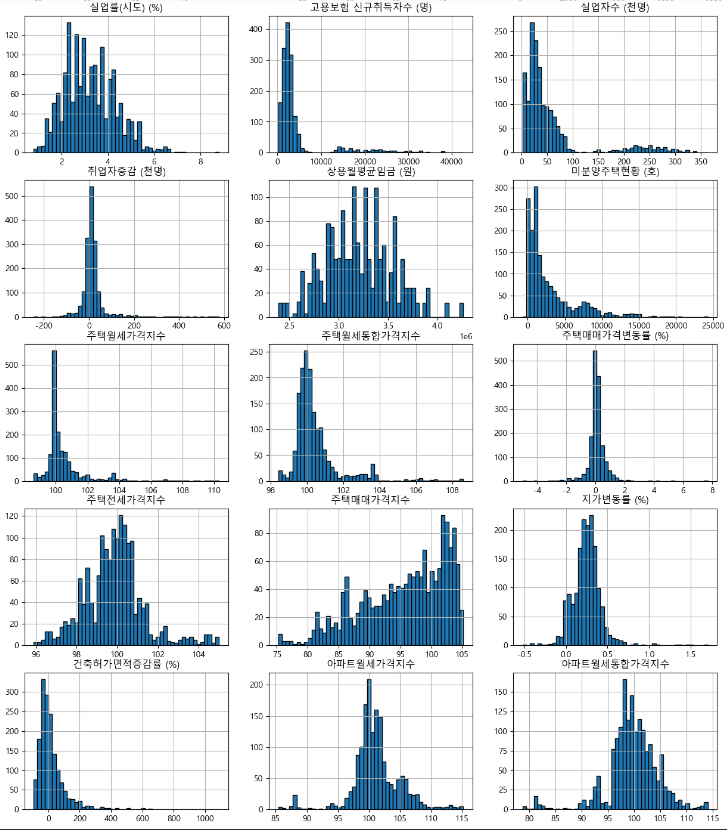
-
행정구역별 인구수 예측모델과 다른 데이터가 없으므로 이상치 제거방법은 동일하게 진행
모델 생성 및 모델평가
- DNN 에서 히든픙의 노드수와 깊이를 변경해가며 평가
np.random.seed(42)
input_node = 63
output_node = 1
first_hid_node = 16
second_hid_node = 32
df = Sequential(name="regression_model")
df.add(Dense(first_hid_node, activation="relu", kernel_initializer='he_normal', input_shape=(input_node,)))
df.add(Dropout(0.2))
df.add(Dense(second_hid_node, activation="relu", kernel_initializer='he_normal'))
df.add(Dropout(0.2))
df.add(Dense(output_node, activation="linear", kernel_initializer='he_normal'))
adam = Adam(learning_rate=0.001)
df.compile(loss='mean_squared_error', optimizer=adam, metrics=['mse', MeanAbsoluteError()])
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=2,
patience=2,
restore_best_weights=True
)
df_hist = df.fit(x_train_sc, y_train,
epochs=150,
batch_size=2,
validation_split=0.2
)
📖 흥미로운 점 / 새로 알게된 점
-
어제 상관관계분석을 통해서 라벨에 강한 영향을 주는 피처를 뽑았다. 뽑힌 피처들끼리의 상관관계를 보니 모두 매우 매우 높았다. 그래서 생각한 점이 라벨 자체가 피처에 영향을 끼치는 것이였다. 그리고 그런 피처들이 라벨인 인구수와 너무 비슷한 데이터라고 생각했다. 그래서 드랍을 했었던게 정말 알맞은 분석이였다.
역시 무엇보다, 데이터 자체에 집중을 하는 것이 맞았다. 많은 모델을 만들어서 성능을 올리려는 시도보다 이렇게 데이터를 이해하는 것이 효율적이고 중요하다는 것을 또 느꼈다. -
주제 변경을 고민할때 컬럼들을 보다보니, 인구수와 경제에 관한 지표가 많았다. 이를 이용해서 인구수와 경제의 연관성에 대한 주제를 선택한게 흥미로웠다. 더 나아가서 출산률과 경제지표를 연관지을 수 있어서 더욱 흥미로웠다.
📖 이후 학습 계획
- 데이터 분석 및 모델 성능 평가하여 최적화 모델 생성
