
📖 학습한 내용
- 경제적요인에 따른 조출생률 예측모델 생성 총정리
- EDA
📖 핵심내용
📌 경제적요인에 따른 조출생률 예측모델 생성
1. EDA
EDA 결론
-
피처들의 이상치가 너무 많고, 피처끼리의 상관관계가 매우 높으며, 종속변수가 정규분포를 따르지 않는다.
-
모델선택은 트리 기반 앙상블 모델인 Randomforest, XGboost 회귀모델을 사용한다. 이것들은 본질적으로 이상치에 덜 민감하며 일반적인 선형 회귀 모델보다 강건성을 가지기 때문이다.
또한 디시전 트리를 모델로 하여 사람들에게 어떤 방식으로 트리기반 앙상블 모델이 작동하는지 설명한다. -
피처선택은 첫번째로 상관계수에 의한 선택이다. 피처끼리의 상관관계가 높지 않은 피처 중 클래스와 상관관계가 너무 낮지 않은 모델을 선택한다.
두번째로는 PCA에 의한 피처선택을 한다. 이렇게 두개 중 하나의 방법으로 모델에 적용 후, 모델에서 출력되는 계수를 보고 다시 결정하는 방법을 사용한다.
트리 기반 앙상블 모델이 강건성을 가진 이유
-
데이터 분할 및 지역적 결정:
트리 기반 모델은 데이터 공간을 여러 작은 부분으로 분할하고 각 부분에서 별도로 예측을 수행합니다. 각 분할된 노드에서의 결정은 해당 노드에 속한 데이터 포인트만을 기반으로 하므로, 하나의 이상치가 전체 모델에 큰 영향을 미치지 않습니다. -
앙상블 효과:
랜덤 포레스트와 같은 앙상블 기법에서는 여러 개의 결정 트리를 생성하여 그 결과를 평균화하거나 투표를 통해 최종 예측을 만듭니다. 개별 트리에 이상치가 영향을 미치더라도, 다른 트리들이 이를 상쇄할 수 있어 모델의 전체적인 성능이 안정적입니다. -
무작위성 도입:
랜덤 포레스트는 각 트리를 생성할 때 데이터의 무작위 샘플링과 피처의 무작위 샘플링을 사용합니다. 이는 모델이 다양한 데이터 샘플을 학습하게 하여 특정 이상치의 영향을 줄이고, 모델의 일반화를 돕습니다.
XGBoost는 부스팅 방법을 사용하여 각 단계에서 이전 단계의 오류를 보정하는 방식으로 학습합니다. 이 과정에서 트리의 깊이를 제한하고, 학습률을 조정하며, 규제를 추가하여 과적합과 이상치의 영향을 줄입니다. -
비선형성과 유연성:
트리 기반 모델은 비선형적인 데이터 패턴을 잘 포착할 수 있습니다. 선형 회귀 모델은 데이터의 관계가 선형이라는 가정을 하지만, 트리 기반 모델은 이러한 가정이 필요 없으므로 데이터의 복잡한 패턴을 더 잘 학습할 수 있습니다.
이는 이상치가 데이터의 특정 영역에 집중되어 있을 때 해당 영역에서만 영향을 미치고, 전체 모델에 큰 영향을 주지 않도록 합니다.
A. 데이터 추가
- 조출생율 3분할 - 카테고리 데이터 생성
데이터의 특징을 알기 위해서, 클래스의 카태고리 컬럼 생성
def birth_categorize(birth):
one_third = np.percentile(df['조출생률(천명당)'], 33.33)
two_third = np.percentile(df['조출생률(천명당)'], 66.67)
if birth < one_third:
return 'low'
elif one_third <= birth < two_third:
return 'middle'
else:
return 'high'
df_cat = df.copy()
# 신규 피처생성(카테고리)
df_cat["조출생률_카테고리"] = df['조출생률(천명당)'].apply(birth_categorize).astype("category")
# 카테고리 순서 설정
df_cat["조출생률_카테고리"] = pd.Categorical(df_cat["조출생률_카테고리"], categories=['low', 'middle', 'high'], ordered=True)B. 종속변수 확인
- 조출생률 그래프
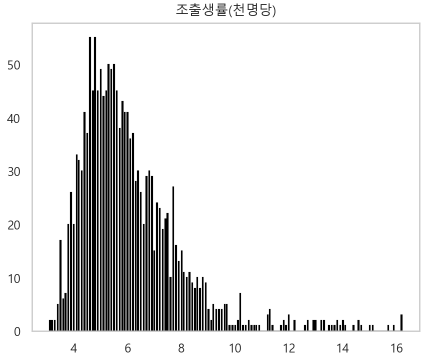
정규성 확인
- Shapiro-Wilk test를 사용한 정규성 검정
stat, p_value = shapiro(is_standard)
print(f'Statistic: {stat}, p-value: {p_value}')
alpha = 0.05
if p_value > alpha:
print('데이터가 정규 분포를 따릅니다 (귀무가설 기각하지 않음)')
else:
print('데이터가 정규 분포를 따르지 않습니다 (귀무가설 기각)')Statistic: 0.8591747879981995, p-value: 6.672026009687054e-36
데이터가 정규 분포를 따르지 않습니다 (귀무가설 기각)
- Q-Q plot
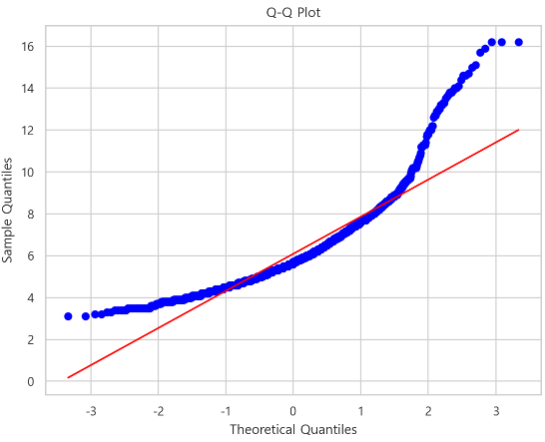
결론
결론적으로 종속변수가 정규성을 띄지 않는다.
따라서 일반적으로 선형회귀는 쓰기 어렵다.
C. 상관관계 분석
- 라벨과 강한 상관관계 피처 추출
- 거의 반드시 모델에 들어가야한다.
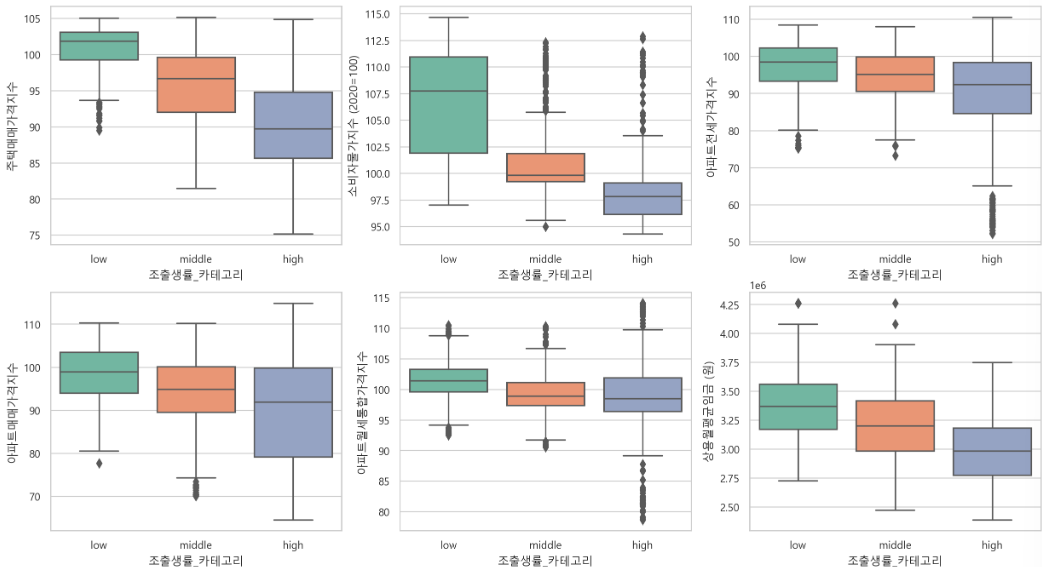
- 하지만 서로의 상관관계가 높다면 뺄지 고려해야한다.

- 라벨과 매우 약한 상관관계 피처 추출
- 너무 약한 것은 제거함 (-0.05~0.05)
- 라벨 제외한 피처들끼리의 상관관계
- 서로 영향을 많이 주면 다중공선성의 문제가 발생하므로 서로의 상관관계가 높은 피처는 제거한다.
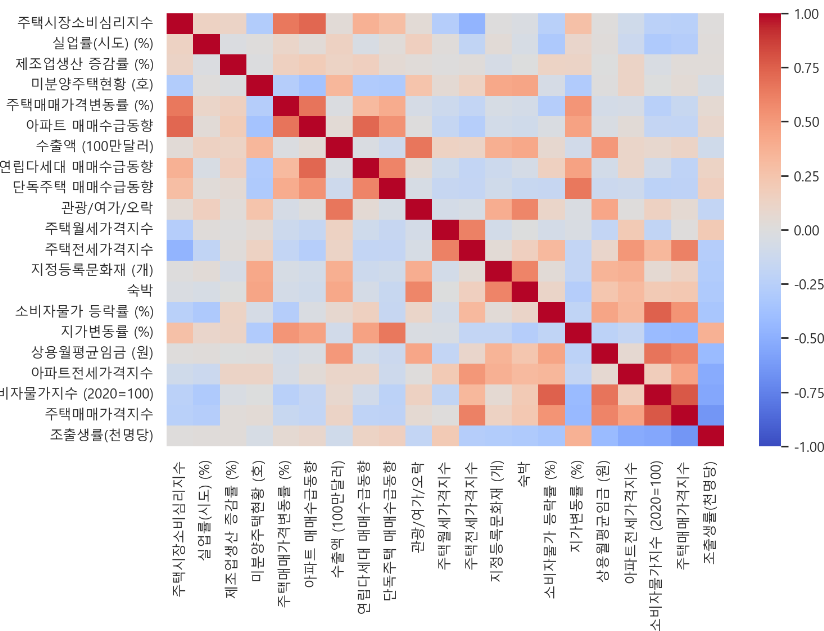
-> 상관관계 값을 보고 조정한 결과
D. PCA 분석
-
스케일링
PCA 분석할 때, 먼저 스케일링을 해야한다. -
적정한 차원 찾기
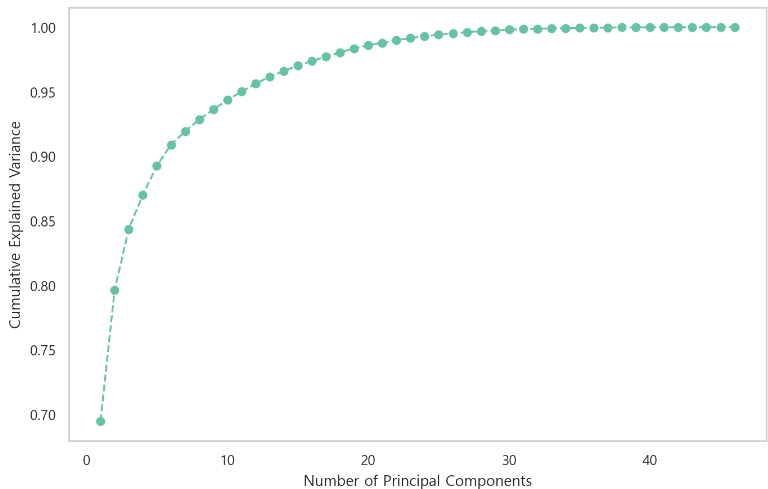
-> 주성분의 90% 첫번째는 6으로 설명된다. 따라서 피처의 개수를 6개로한다.
📖 어려운 부분
- PCA의 설명하는 첫번째 부분을 찾기
pca_n_search = PCA()
pca_n_search.fit(pca_scaling)
# 설명된 분산 비율
explained_variance_ratio = np.cumsum(pca_n_search.explained_variance_ratio_)
# 스크리 플롯
plt.figure(figsize=(8,5))
plt.plot(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio, marker='o', linestyle='--')
plt.xlabel('Number of Principal Components')
plt.ylabel('Cumulative Explained Variance')
plt.title('Scree Plot')
plt.grid()
plt.show()
best_n =0
# 몇 개의 주성분을 선택할지 출력
for i, var in enumerate(explained_variance_ratio):
if var >= 0.90: # 전체 분산의 90% 이상을 설명하는 주성분의 수
print(f'분산의 90%는 첫 번째 {i+1} 주성분으로 설명됩니다.')
best_n = i+1
break
pca = PCA(n_components = best_n).fit_transform(pca_scaling) 📖 이후 학습 계획
- 모델 생성 및 데이터 시트 작성
