
📖 학습한 내용
- 경제적요인에 따른 조출생률 예측모델 생성 총정리
- 데이터 유형파악
- 데이터 전처리
📖 핵심내용
📌 경제적요인에 따른 조출생률 예측모델 생성
1. 컬럼 유형 파악
숫자형 데이터
- 연속형 데이터 컬럼
'소비자물가지수 (2020=100)'
'소비자물가 등락률 (%)'
'경제활동참가율(시도) (%)'
'고용률(시도) (%)'
'실업률(시도) (%)'
'상용월평균임금 (원)'
'주택월세가격지수'
'주택월세통합가격지수'
'주택매매가격변동률 (%)'
'주택전세가격지수'
'주택매매가격지수'
'지가변동률 (%)'
'건축허가면적증감률 (%)'
'아파트월세가격지수'
'아파트월세통합가격지수'
'아파트전세가격지수'
'아파트매매가격지수'
'주택시장소비심리지수'
'제조업생산 증감률 (%)'
'백화점판매액 (백만원)'
'대형소매점판매액 (백만원)'
'어음부도율'
'수입액 (100만달러)'
'수출액 (100만달러)'
- 이산형 데이터 컬럼
'주민등록인구 (명)'
'순이동인구 (명)'
'전출인구 (명)'
'전입인구 (명)'
'사망자수 (명)'
'출생아수 (명)'
'이혼건수 (건)'
'혼인건수 (건)'
'예금은행대출금액 (십억원)'
'예금은행예금액 (십억원)'
'경제활동인구(시도) (천명)'
'취업자수(시도) (천명)'
'고용보험 신규취득자수 (명)'
'실업자수 (천명)'
'취업자증감 (천명)'
'미분양주택현황 (호)'
'아파트거래현황'
'민간아파트신규분양대수'
'비경제활동인구 (천명)'
'사업체수 (개)'
'지정등록문화재 (개)'
'강력범죄 발생건수 (건)'
'강력범죄 검거건수 (건)'
'강력범죄 검거인원 (명)'
'합계 : 사용검사실적'
'국토면적(㎢)'
범주형 데이터
-
명목형 데이터 컬럼
'지역별' -
순서형 데이터 컬럼
'시점'
2. 데이터 전처리
A. 유형에 따른 데이터 변환
범주형 데이터 : 순서형 데이터 변환 - Ordinal Encoding
- 시점
년.달 형식으로 되어있는 데이터를 0~95의 숫자로 변경
for i in range(17):
for j in range(96):
df_final.loc[j+96*(i),'시점']=95-j
df_final['시점']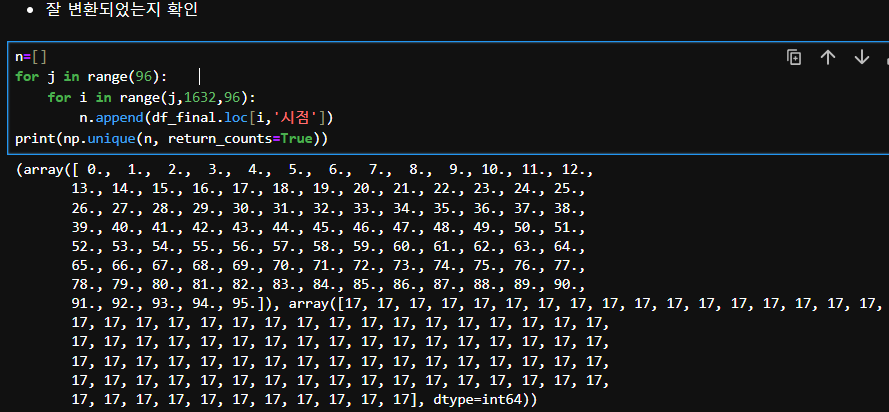
-> 시의 데이터가 17개라서 정확히 다 잘 들어갔다.
범주형 데이터 : 명목형 데이터 변환 - 원핫인코딩
- 지역별(행정구역)
차원의 저주를 피하기 위해서 drop_first=True 를 사용
# 원핫인코딩
df_final_onehoted = pd.get_dummies(df_final, columns=['지역별'], drop_first=True)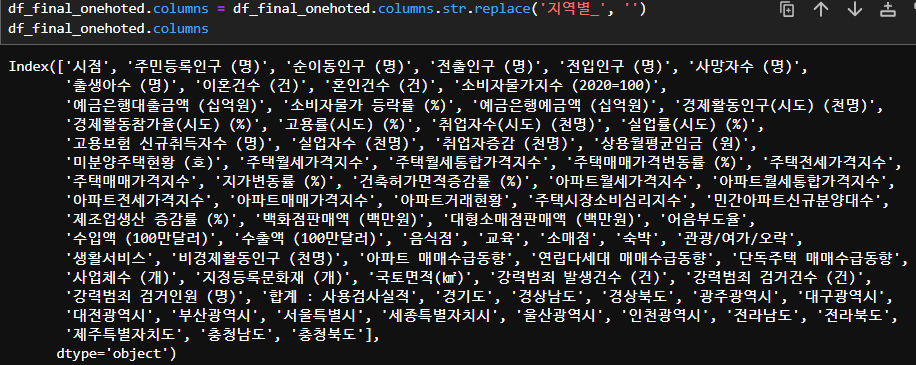
-> 각 행정구역이 하나의 컬럼으로 생성되었다. 강원도는 제외. 모두 0일때 강원도임을 알 수 있다.
숫자형 데이터 자료형 변환
- 오브젝트인 자료들 확인
# object 데이터형인 컬럼 확인
object_col = df_final_onehoted.select_dtypes('object').columns
len(object_col), object_col- 컴마 제거 후 플롯타입으로 변경
for col in mi_col:
df_final_onehoted[col] = df_final_onehoted[col].str.replace(',','').astype(float)B. 필요없는 데이터 드랍
회의에서 필요없다고 판단되거나, 결측치가 많은 데이터 버림
C. 결측치 처리
1. 소비자물가지수 결측치
- 경향 파악
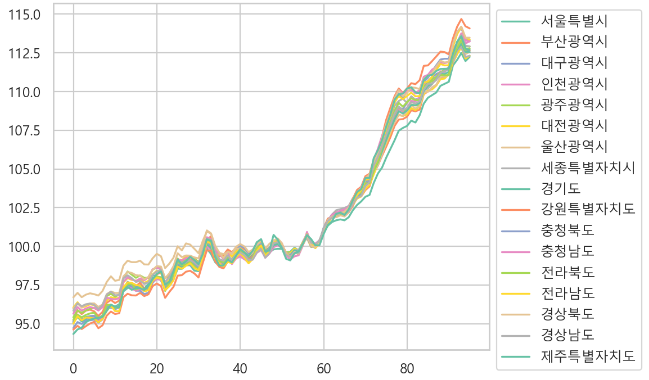
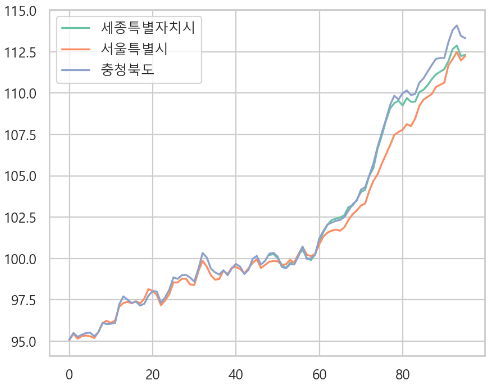
-> 세종특별시도 경향을 따라간다.
-> 세종시는 다른 지역과 비슷하게 따라가다가 20년부터 비는 것을 확인
- 세종시 결측 예측을 위해 도시별 소비자물가로 데이터프레임 생성
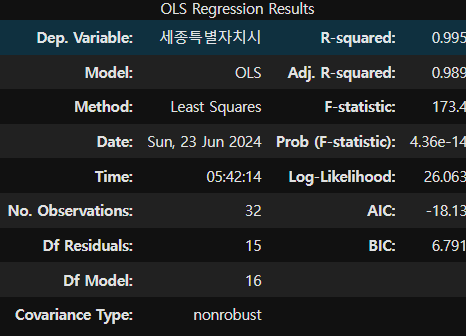
- OLS 회귀 모델 생성
# 인덱스 0~47까지 훈련 모델
x_sejong = df_mulga.iloc[0:48,:].drop(['세종특별자치시','월'], axis = 1)
y_sejong= df_mulga.iloc[0:48,:]['세종특별자치시']
x_train_mul, x_val_mul, y_train_mul, y_val_mul = train_test_split(x_sejong,
y_sejong,
test_size=0.1,
random_state=42,
)
x_train_mul = sm.add_constant(x_train_mul)
x_val_mul = sm.add_constant(x_val_mul)
lm = sm.OLS(y_train_mul, x_train_mul).fit()
pred_mul = lm.predict(x_val_mul)
fig, ax = plt.subplots(figsize=(5,4))
sns.scatterplot(x=y_val_mul, y=pred_mul , ax=ax)
plt.plot([min(y_val_mul), max(y_val_mul)], [min(y_val_mul), max(y_val_mul)], 'r', ls='--', lw=1)
plt.show()
lm.summary()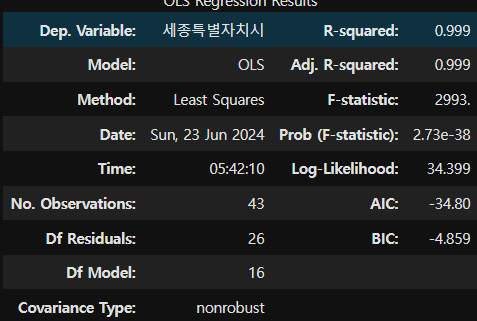
-> 지표가 매우 좋으므로 결측치에 채워넣는다
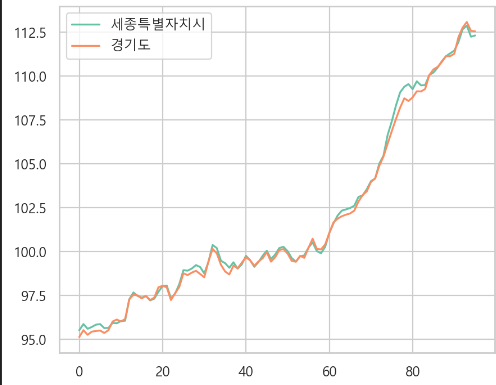
-> 잘 채워진 것을 확인
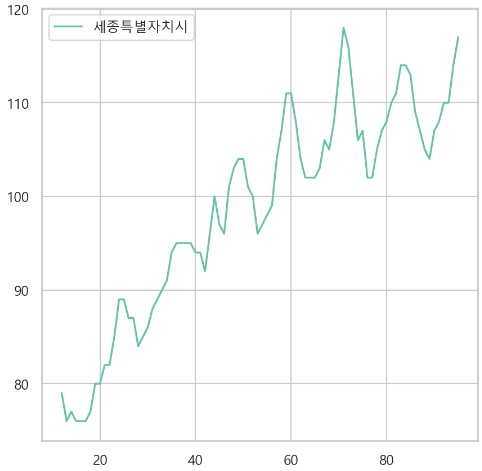
2. 비경제활동인구 (천명) 결측치
-
전체 경향 확인
-> 어떤 흐름을 따르지 않는다. -
피처의 그래프
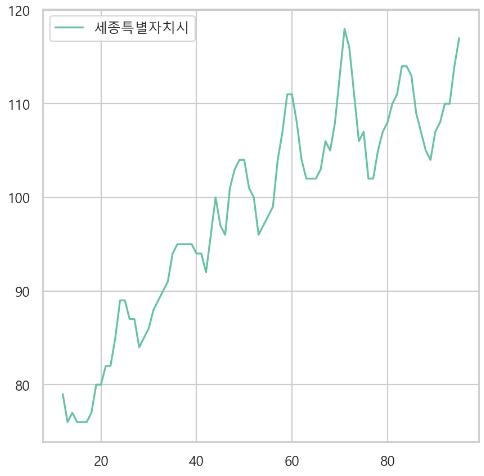
-> 선형회귀로 결측치를 채울 수 있을 것 같다.
model_sejong = LinearRegression()
model_sejong.fit(x_train_sejong, y_train_sejong)
pred_sejong = model_sejong.predict(x_test_sejong)
sejong[nan_index] = pred_sejong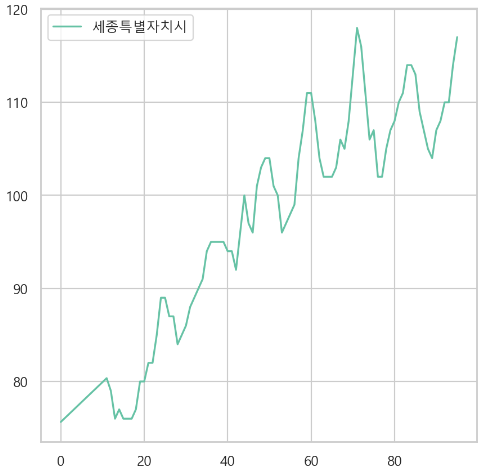
-> 잘 채워진 것을 확인
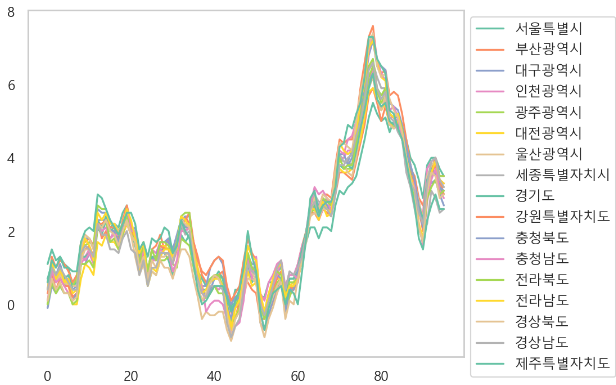
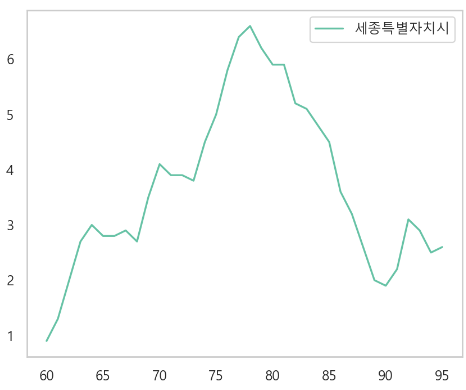
3. 소비자물가 등락률 (%)
-
전체 경향 확인
-> 경향을 따라가므로 OLS 로 결측치 채우기 -
결측있는 컬럼만 확인
-> 0~60까지 결측이라 그래프에 나오지 않음 -
OLS 로 결측치 채우기
-> 꽤 유효한 값이 나오므로 결측치를 채운다.
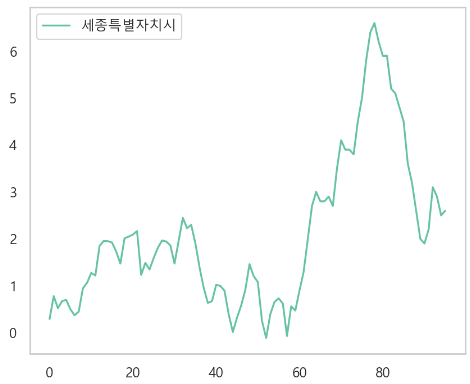
-> 매우 잘 채워진 것을 알 수 있다.
4. 경제활동인구(시도) (천명)
- 전체 경향 확인
- 결측있는 컬럼만 확인
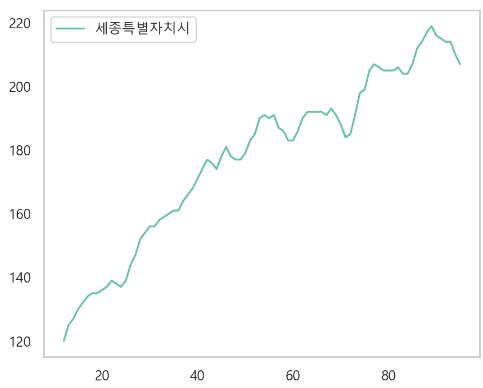
- 회귀로 결측치 채우기
model_sejong = LinearRegression()
model_sejong.fit(x_train_sejong, y_train_sejong)
pred_sejong = model_sejong.predict(x_test_sejong)
sejong[nan_index] = pred_sejong- 잘 채워졌는지 확인
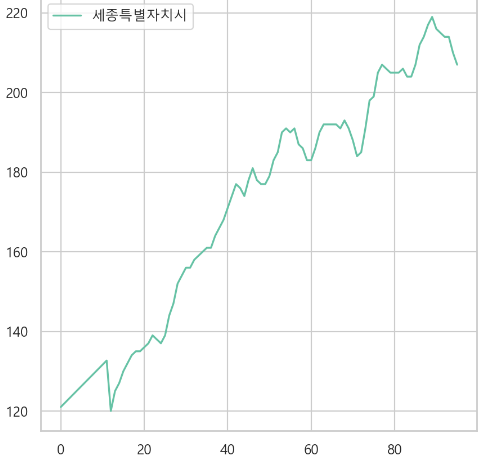
5. 경제활동참가율(시도) (%)
- 전체 경향 확인
- 결측있는 컬럼만 확인
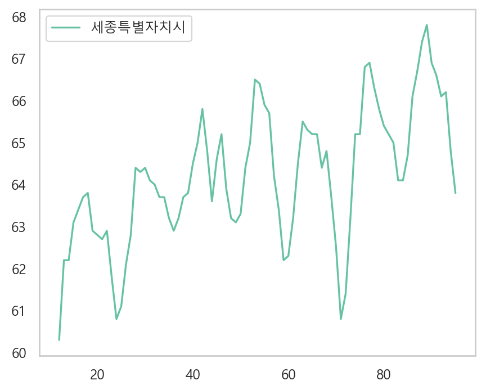
- 회귀로 결측치 채우기
model_sejong = LinearRegression()
model_sejong.fit(x_train_sejong, y_train_sejong)
pred_sejong = model_sejong.predict(x_test_sejong)
sejong[nan_index] = pred_sejong- 잘 채워졌는지 확인
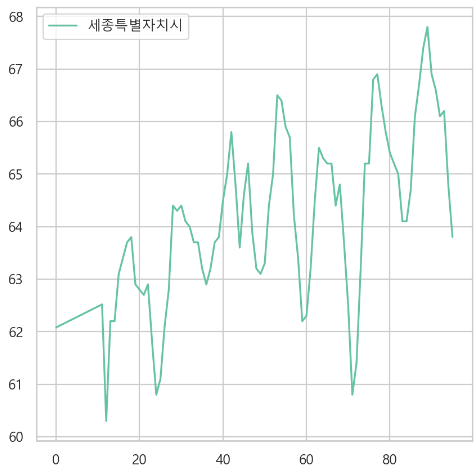
6. 고용률(시도) (%)
- 전체 경향 확인
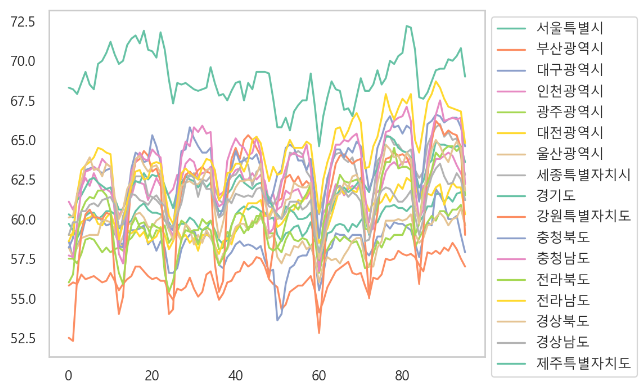
- 결측있는 컬럼만 확인
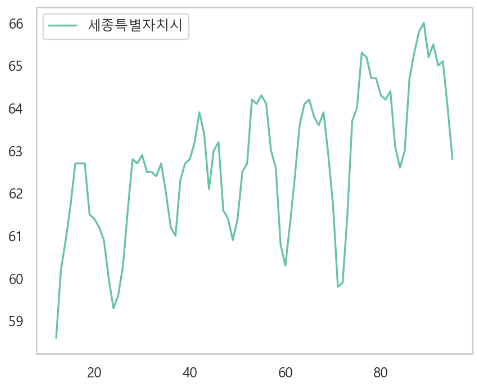
- 회귀로 결측치 채우기
model_sejong = LinearRegression()
model_sejong.fit(x_train_sejong, y_train_sejong)
pred_sejong = model_sejong.predict(x_test_sejong)
sejong[nan_index] = pred_sejong- 잘 채워졌는지 확인
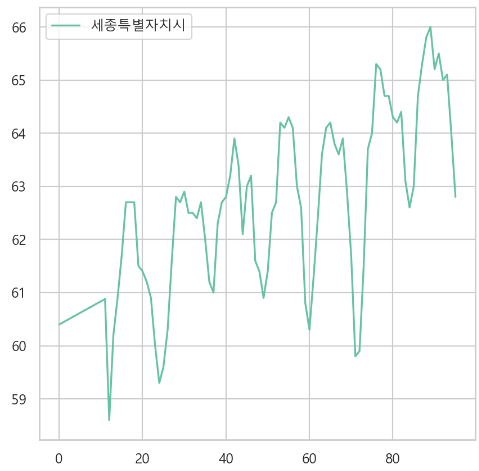
D. 이상치 처리
1. 박스플랏으로 이상치 탐색 및 처리
-
데이터 확인
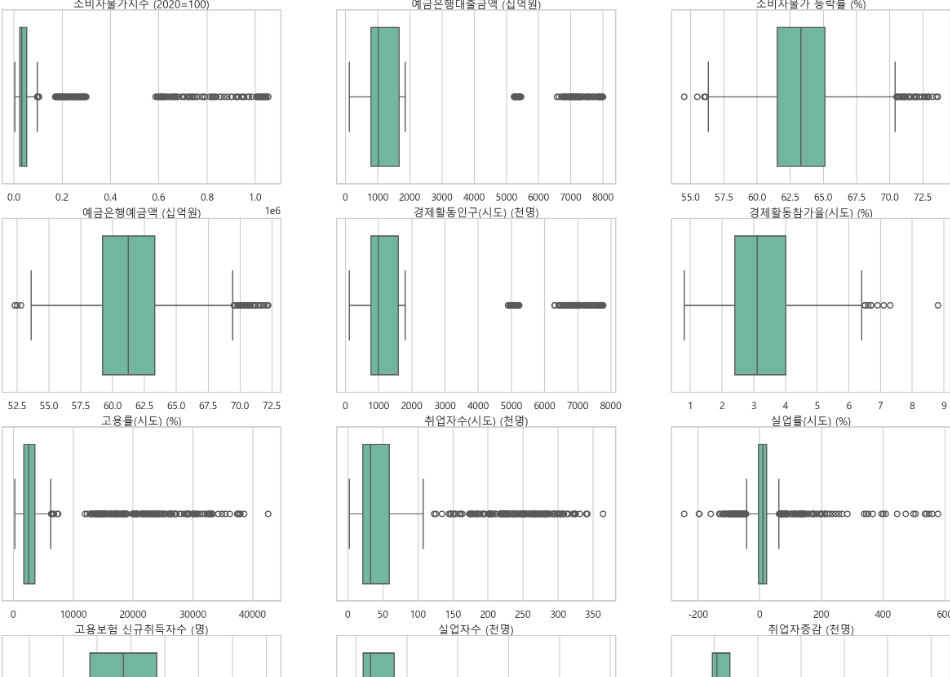
-> IQR로 이상치 제거하면 다 없어질 것 같다. 따라서 너무 심하게 떨어진 값만 제거 -
제거 기준
중앙값 ~ 상한경계 길이의 5배가 넘으면 제거한다.
많은 값들이 뭉처있는 경우 제거하지 않는다.
연속적인 경향을 보이는 경우 제거하지 않는다. -
제거한 데이터
고용보험 신규취득자수 (명) - 1개
실업자수 (천명) - 1개
주택매매가격변동률 (%) - 2개
건축허가면적증감률 (%) - 1개
민간아파트신규분양대수 - 3개
소매점, 생활서비스 - 3개
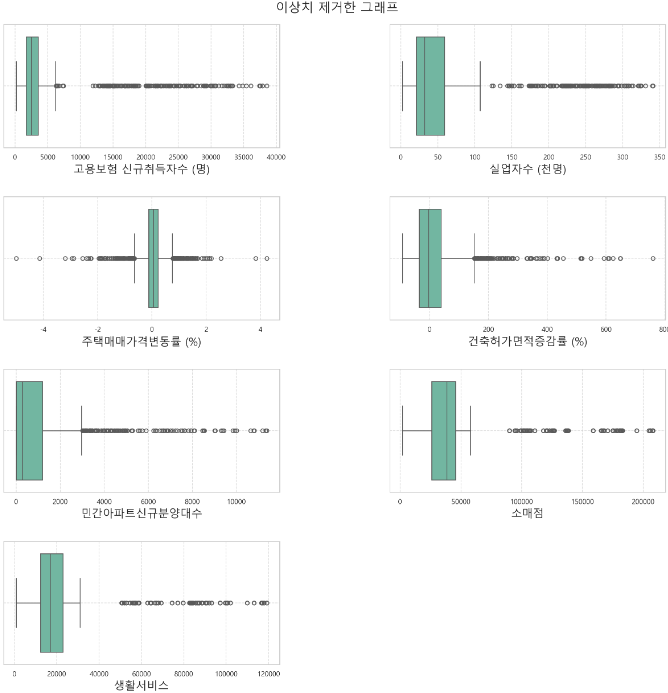
-> 여전히 극단적인 값이 많지만 전보다 안정된거 같다.
2. 히스토그램으로 이상치 탐색 및 처리
-
클래스의 히스토그램
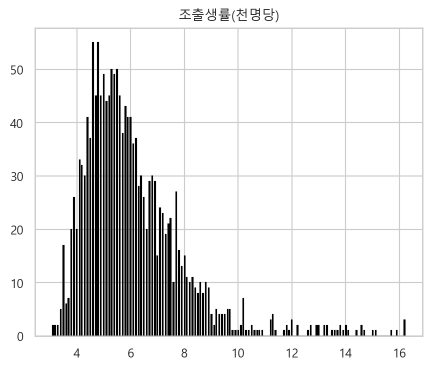
-
피처의 히스토그램
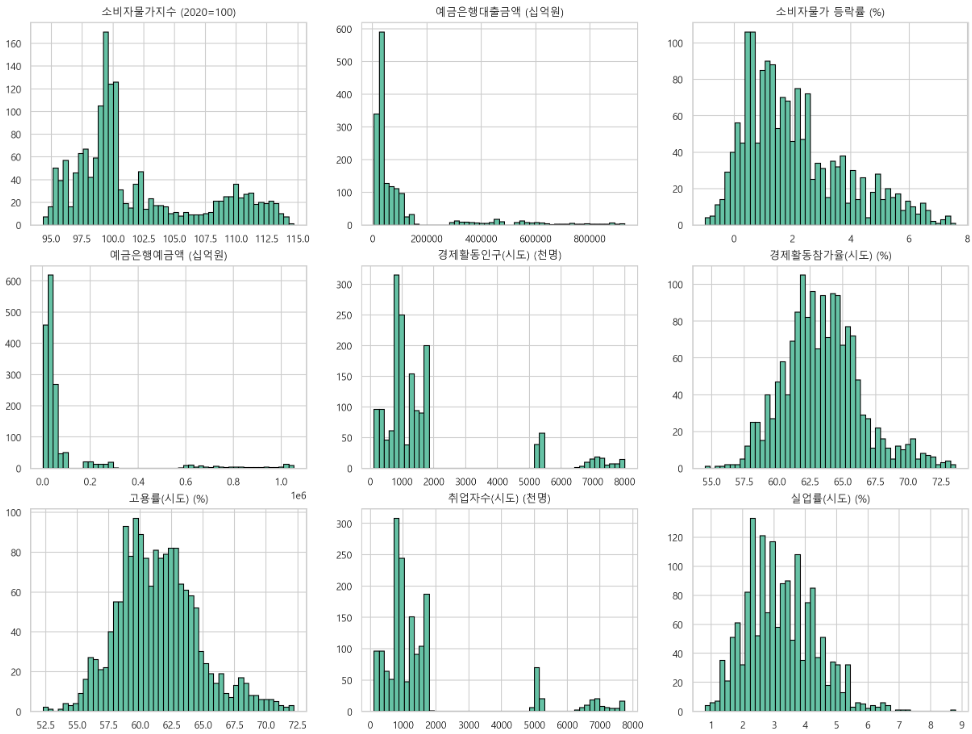
-> 정규분포를 따르는 것도 있고 아닌 것도 있다. 함부로 판단하기가 어려었다.
3. 0 인 데이터 살펴보기
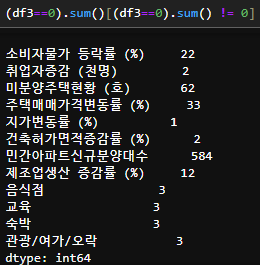
-> 모두 0이 나올 수 있는 피처들이여서 이상함을 느끼지 못했다.
📖 어려운 부분
자료형 변환 중 이상치 발견
- 자료 변환 도중 자꾸 에러가 발생함
- 데이터를 살피다 보니, '-' 로 표기된 결측치 발견함. 그래서 .astype(float)에서 에러 발생한 것을 파악
- '-' 로 표기된 문자열을 제거하려했으나, 음수가 함께 포함되어서 불가능함
- '-'만 있는 데이터와 그렇지 않은 데이터로 구분
mi_col = []
nan_col = []
for col in minus_col:
if df_final_onehoted[col].isin(['-']).sum() == 0 :
mi_col.append(col)
else:
nan_col.append(col)
print('마이너스 가진 문자형 컬럼 : ',mi_col)
print()
print('결측치가 -로 표기된 컬럼 : ',nan_col)- 이상치를 결측치로 변경 후 결측치 처리때 한번에 해결
for col in nan_col:
df_final_onehoted[col] = df_final_onehoted[col].str.replace(',','').replace('-', np.nan).astype(float)결측치 채워넣기
-
결측값을 채워 넣는 단계에서만 시간이 오래 결렸다.
shape 도 같고, 에러도 발생하지 않는데, 왜 채워지지 않는 건지 정말 화가 났다. -
해결 - 아래의 모든 조건이 맞아야 데이터프레임의 값이 바뀐다
1.데이터프레임에 값을 변경하기 위해서 접근항때는 iloc를 사용하면 안된다. 무조건 loc로 접근해야한다.
- 쉐길이가 맞아야한다. 들어가는게 데이터프레임보다 길면 오류가 발생해서 인지할 수 있지만, 짧으면 아무도 모르게 안들어가진다.
- 배열형태이여야 한다. 시리즈형태에 들어갈때는 같은 시리즈 형태라도 들어가지지 않는다.
📖 이후 학습 계획
- EDA, 모델 생성 추가
📖 기타
- 행정구역별 인구수 예측모델에서 경제적요인에 주제 변경
데이터셋을 가지고 모델을 학습시키던 중, R2, MSE, MAE 값 이상하리만큼 높다는 것을 발견했다.
R2 값이 높은 이유는 데이터베이스가 너무 라벨과 비례하게 올라가는 피처들로 구성되어있어 일어난 일이라는 것을 알 수 있었다.
MSE, MAE 오차 값이 너무 큰 이유는, 행정구역별 인구수 자체 크기가 매우 컸기 때문이다. 따라서 값이 클 수 밖에 없었다. 단위을 좀 더 줄이는 방법을 사용하면 된다.
피처의 구성이 잘못되어서 새로운 주제를 할것인지, 새로운 데이터를 찾을 것인지 고민이 있었다.
모은 데이터를 살펴보니, 대부분 경제와 부동산에 관련된 피처였다. 따라서 요즘 사회적인 이슈인 출산률에 대한 주제로 변경하였다.
데이터를 잘 살펴보지 않았기 때문에 생긴 문제였다. 데이터를 잘 살펴보고 특징을 잘 파악했다면, 당연히 라벨이나 다름없는 피처는 수집하지 않았을 것이다.
상관관계를 확인하고 높은 것들이 없는 것을 확인했다. 또한 피처끼리 상관관계가 너무 높은 컬럼은 제거하여 다중공선성을 제거하였다.
