
📖 학습한 내용
- 자연어처리 - 육아휴직관련법안 분석
- 나이브베이즈 분류를 이용한 감성분석
📖 핵심내용
📌 자연어처리
육아휴직관련법안 분석
- 육아휴직관련법안
konlpy 에서 아예 가지고 있다
doc_ko = kobill.open('1809890.txt').read() - nltk.Text()
텍스트 데이터를 처리하고 분석하기 위한 유용한 기능들을 제공
-> 텍스트 데이터를 분석하고 탐색하는 데 사용
vocab(): 메서드를 사용하여 단어의 빈도를 계산
plot(보고싶은 단어 개수): 단어 빈도 그래프를 그릴 수 있다.
count: 개수 세기
dispersion_plot(): 단어가 어디쯤 위치하는지
concordance(): 좌우의 글자들을 보여줘서 문맥을 알 수 있게함
collocations(): 특정 단어와 함께 가장 많이 쓰인 단어를 보여줌
📌 나이브베이즈 분류를 이용한 감성분석
전처리
- 라벨달기
train = [
('i like you', 'pos'),
('i hate you', 'neg'),
('you like me', 'neg'),
('i like her', 'pos'),
]- 문장에서 말뭉치 생성
# 텍스트 데이터를 전처리하고 단어들을 소문자로 변환하여 모두 모은 뒤, 중복을 제거한 집합(set)을 생성하는 코드
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0]) # lower : 소문자만
)
# train이라는 데이터셋에서 각각의 sentence를 가져와서 그 문장의 첫 번째 요소 (sentence[0])를 토큰화한 단어들을 순회하면서 처리
all_words
-> 말뭉치가 있다면 어떤 문장들을 만들 수 있다.
나이브 베이즈 분류
-
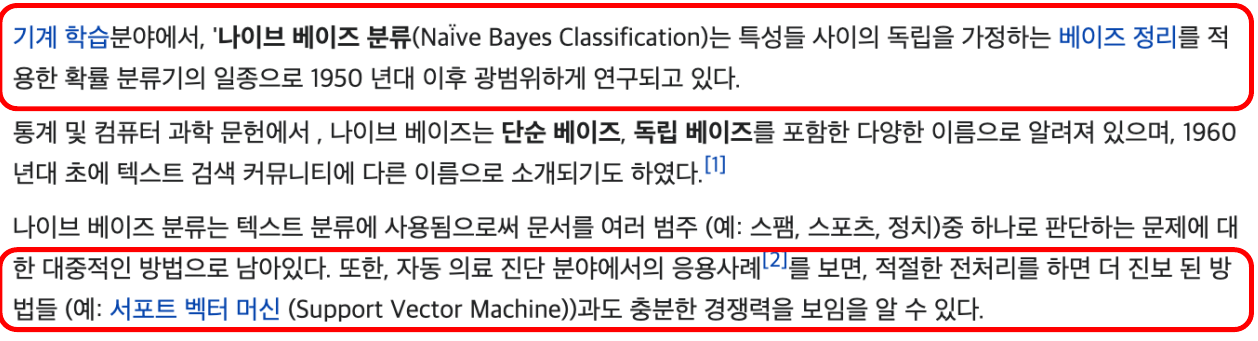
각 문장들에 위에서 만든 각각의 말뭉치들이 있는지 없는지 표기하고, 라벨(긍/부정)을 달아줌
t = [({word : (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]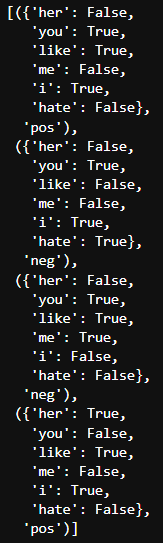
-
나이브 베이즈 분류
clf = nltk.NaiveBayesClassifier.train(t)-> sklearn 에서는 fit(), nltk 에서는 train()
clf.show_most_informative_features()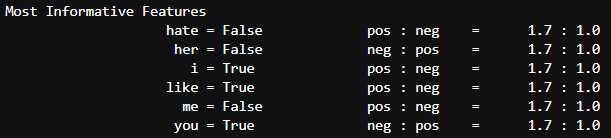
-> like가 있을 때, Positive할 확률이 1.7:1.0이다… 뭐 이런식으로 분류가 되었음 -
각단어별로 독립적으로 확률을 계산하기 때문에 나이브하다고 한다.
-
새로운 문장 넣어서 테스트
test_sentence = 'i like merry' # 트레인에는 메리가 없으므로 i like 로 문장 긍부정 판단 test_sen_feature = { word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words } test_sen_feature
-> 하나하나 단어별로 긍부정을 나타내고 확률로 그것이 긍정인지 부정인지 나타낸다.
📖 흥미로운 점 / 새로 알게된 점
- 문장의 긍부정을 알아내는 방식이 각 단어별로 긍정인지 부정인지 구분해서 나중에 최종 합하여 알아내는 아이디어
📖 어려운 부분
글꼴 문제가 해결이 안된다. 왜 안되는지 도저히 모르겠다. 디렉토리 들어가서 확인하고 경로복사해봐도 안된다.
📖 이후 학습 계획
- 나이브베이즈 감성분석 한글
- 문장의 유사도 측정

설계엔지니어의 변신