
📖 학습한 내용
- 나이브베이즈 분류를 이용한 감성분석
- 문장의 유사도 측정
📖 핵심내용
📌 나이브베이즈 분류를 이용한 감성분석 - 한글
한글을 토큰화 nltk
nltk에서 제공하는 word_tokenize 는 띄어쓰기 기준으로 토큰화를 진행한다. 왜냐하면 영어는 띄어쓰기로 토큰화가 되기 때문.
all_words = set(
word for sentence in train for word in word_tokenize(sentence[0])
)
all_words
-> 말뭉치 만들었는데 메리가 메리는 다 다른 단어로 인식
- 출력 과정 코드설명
- for sentence in train -> sentence에 ("메리가 좋아", 'pos') 할당됨
1.1) for word in word_tokenize(sentence[0]) -> sentence[0]->"메리가 좋아"를 word_tokenize
1.2) "메리가", "좋아"가 순서대로 word에 할당 -> 가장 앞에 word에 들어감 - for sentence in train -> sentence에 ("고양이도 좋아", 'pos') 할당됨
2.1) for word in word_tokenize(sentence[0]) -> sentence[0]->"고양이도 좋아"를 word_tokenize
2.2) "고양이도", "좋아"가 순서대로 word에 할당 -> 가장 앞에 word에 들어감
반복
- train 말뭉치들을 기준으로 나이브 베이즈 분류하기 위해, 5문장을 말뭉치로 나누고 pos/neg 구분
t = [({word : (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]- 나눠진 것으로 훈련, show_most_informative_features
clf = nltk.NaiveBayesClassifier.train(t)
clf.show_most_informative_features()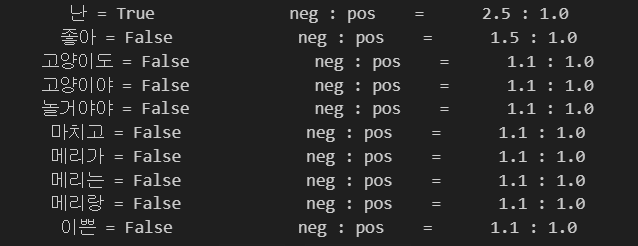
-> 뭔가 이상하다.
- 새로운 문장 넣어서 테스트
test_sentence = '난 수업이 마치면 메리랑 놀거야'
test_sen_feature = {
word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words
}
clf.classify(test_sen_feature)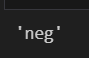
-> 긍정의 문장이였으나 부정의 결과가 나와버렸다. 이유는 형태소 분석을 안했기때문이다. 한글은 형태소에서 의미가 완전히 달라져서 토큰단위로 하면 안된다.
형태소에 따른 구분
- 품사별로 테그 달아주는 작업
조사 이 와 숫자 이 와 벌레 이 가 구분이 안가니깐 테그를 달아줌
def tokenize(doc):
return ['/'.join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]- train 데이터 함수에 넣어서 다시 생성
train_docs = [(tokenize(row[0]), row[1]) for row in train]
train_docs
-> 형태소별로 나눠져있는 것을 확인
다시 분류 후 테스트
-
각 문장 다시 새롭게 분류
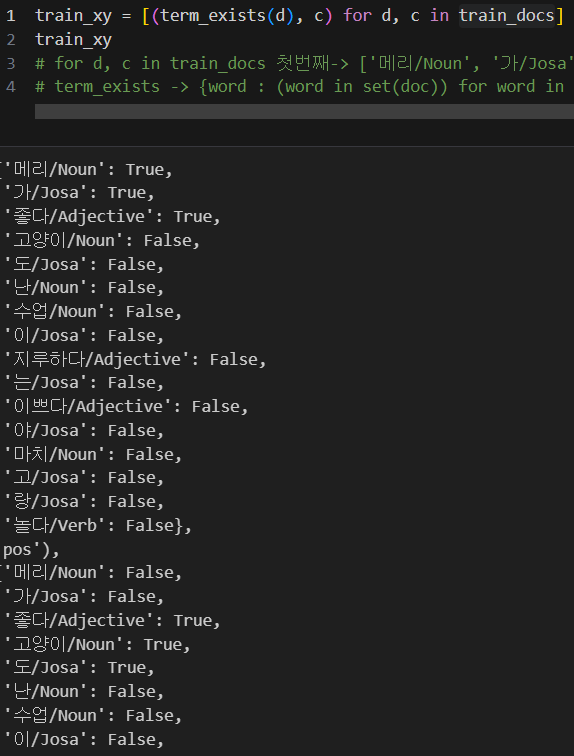
-
분류된 문장을 훈련
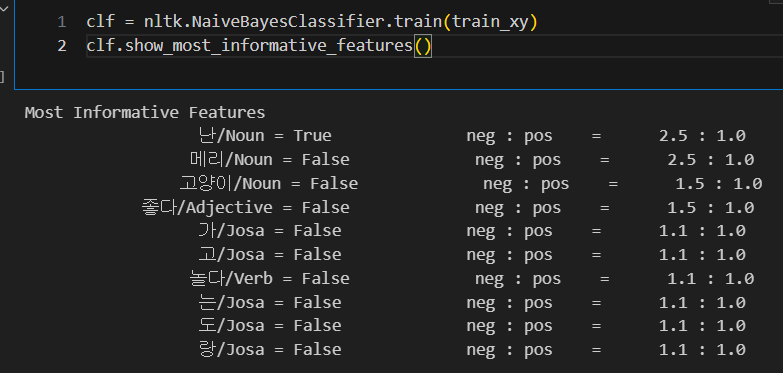
-
새로운 문장 테스트
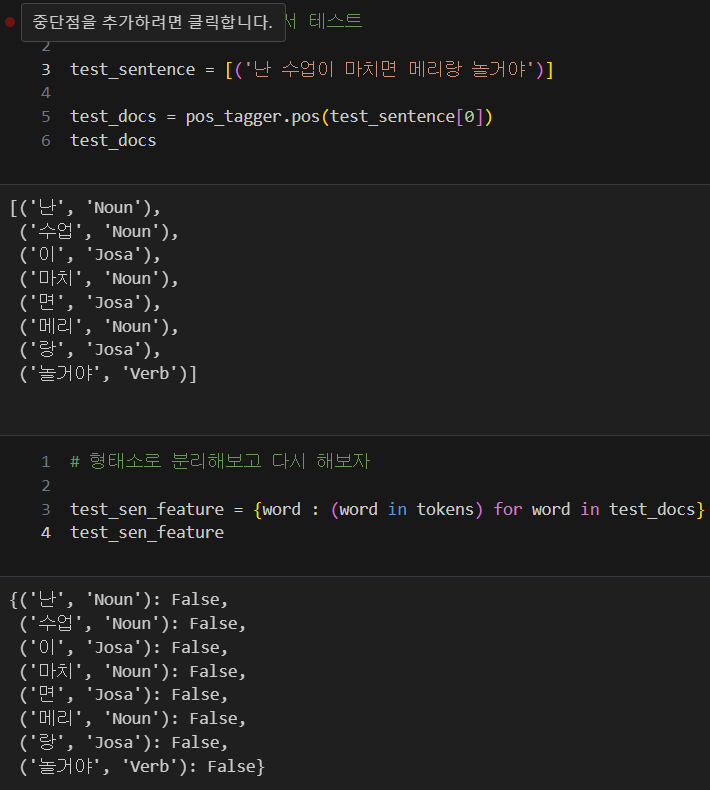
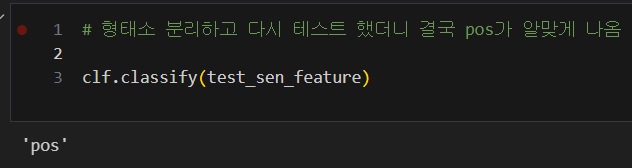
-> 매우 잘나오는 것을 확인 할 수 있다.
결론
한글은 형태소별로 분류하여서 나이브 베이즈 분류로 감성분석을 할 수 있다.
📌 문장의 유사도 측정
어떤 문장든, 음성이든, 무엇이든 벡터로 표시할 수 있으면 무엇이든 거리를 측정할 수 있다.
count vectorize 을 이용한 유사도 측정
어떤 방식으로 벡터화 할 수 있다면, 서로간에 거리를 재서 유사도를 측정할 수 있다.
형태소별 등장 횟수가 벡터의 요소가 되어서 벡터공간에 올릴 수 있다는 아이디어!
- CountVectorizer : 단순히 글자를 세는 함수
from sklearn.feature_extraction.text import CountVectorizer # 글자들을 세는 것
vectorizer = CountVectorizer()-
비교할 문장 설정 후 문장의 형태소 분석
한글이기때문에 형태소 분석 필수 -> Okt의 morphs를 사용한다.
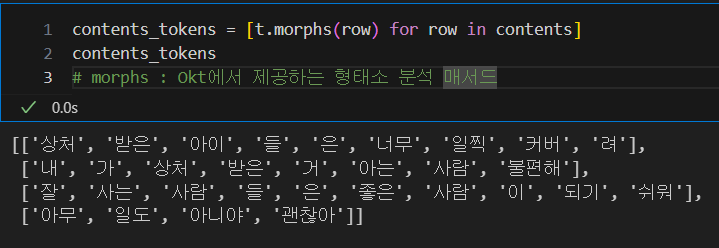
-
nltk 패키지를 사용하기 위해서 띄어쓰기로 구분된 문장으로 다시 만들기
nltk는 영어 기준이기에 띄어쓰기별로 형태소를 구분한다. 이것을 이용하기 위해, 한글도 형태소별로 띄어쓰기가 된 형태의 문장을 만들고, nltk에 넣고 분석!
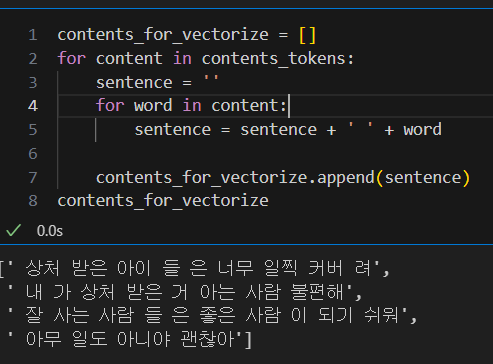
-> contents_for_vectorize 에 새롭게 문장을 만듬
-
CountVectorizer 에 새로운 문장을 훈련 및 변환
X = vectorizer.fit_transform(contents_for_vectorize)-
만들어진 것을 배열로 만들고 비교해보자

-> 형태소별 어느 문장에 몇번 등장했는지 확인 할 수 있다. -
테스트용 문장을 입력 후 벡터로 변환
새로운 문장 형태소로 분리하였다가 다시 문장으로 만들어준다.
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize 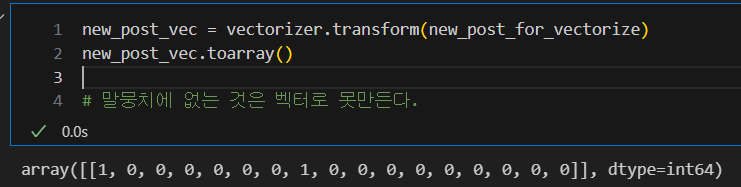
- 트레인의 4개 문장들과 새로운 테스트 문장의 벡터들의 거리 재기
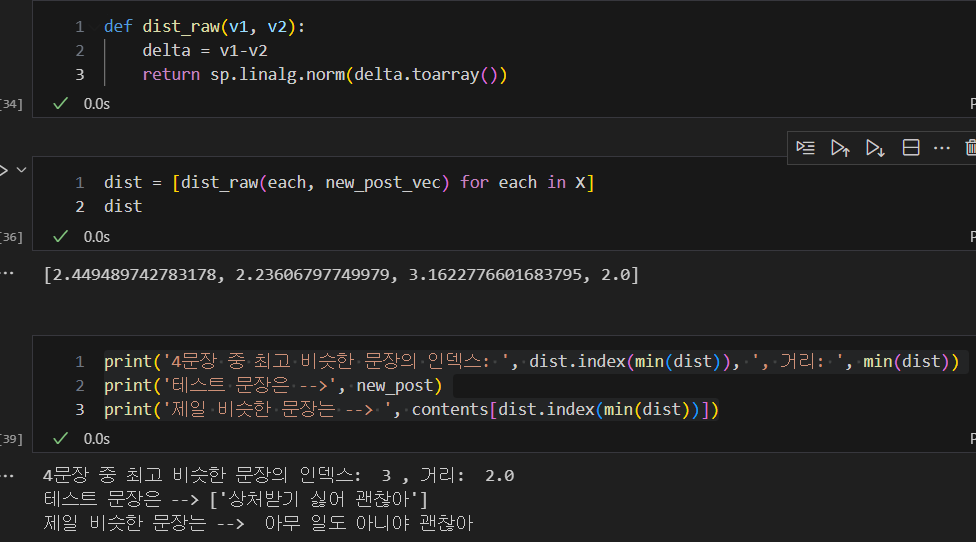
-> 4번째 문장이 새로운 테스트 문장과 벡터가 가장 가까운 것을 알 수 있다.
TF-IDF vectorize 를 이용한 유사도 측정
-
TF : 단어 빈도. 특정 단어가 한 문서 내에 얼마나 자주 등장하는지
-
DF : 문서 빈도. 특정 단어를 포함한 여러 문서가 몇개인지
- 그렇다면 골고루 등장하는 특정 단어는 흔다는 것
이런 요소들은 수치화가 되고 이것을 이용해서 벡터공간에 올리는 아이디어
- TfidfVectorizer 함수 사용
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')- 형태소 단위로 띄어쓰기 된 문장을 다시 이용
-> 사용 법은 CountVectorizer과 완전히 똑같다.X = vectorizer.fit_transform(contents_for_vectorize)
- 마찬가지로 배열화해서 각 문장별로 형태소가 어떻게 벡터화 되었는지 확인
X.toarray().transpose()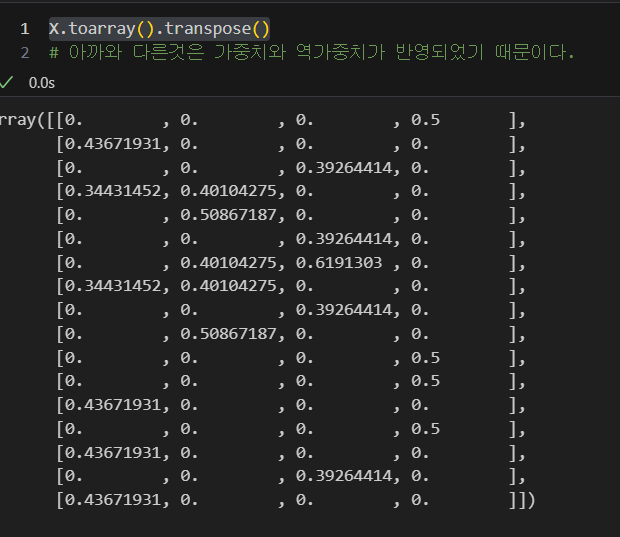
- 새로운 문장을 넣어서 벡터화
아까 만들어서 형태소 단위로 벡터화 한 문장 사용
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()-> 사용법은 CountVectorizer과 완전히 똑같다.
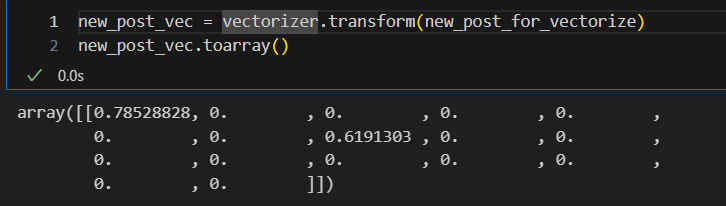
- 비교한 결과
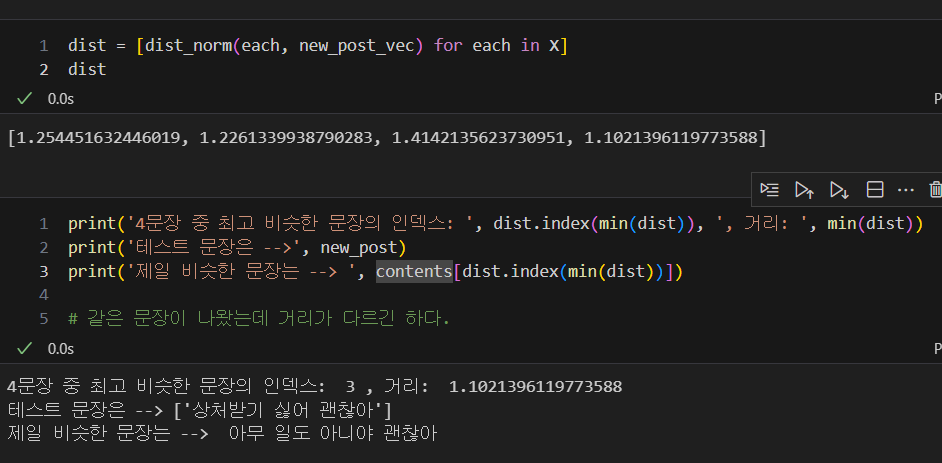
-> 당연히 결과는 같지만 거리의 차가 줄어들었다.
📖 흥미로운 점 / 새로 알게된 점
- 어떻게든지 수치화하면 벡터공간에 올릴 수 있고, 거리를 측정하여 상대적인 거리를 잰다는 아이디어가 흥미로웠다.
📖 어려운 부분
- 처음보는 함수들과 하나하나 펼치는 아이디어가 어려웠다.
📖 이후 학습 계획
- PCA 분석
