
📖 학습한 내용
- 프로젝트 : Dacon 재정정보 검색 알고리즘 경진대회
📖 핵심내용
📌 데이터 준비
Llama3로 LLM서비스 구현
- 프로세스
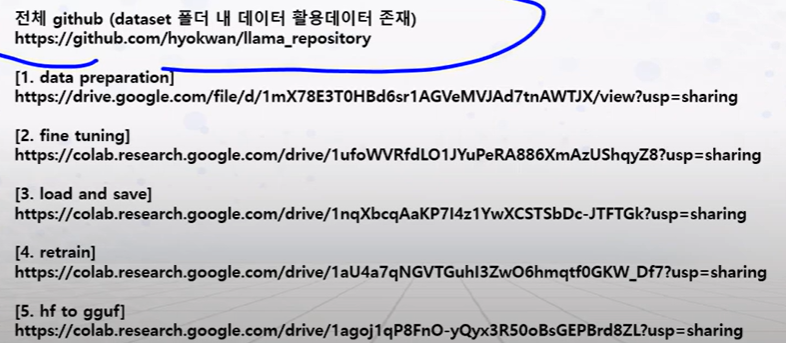
데이터 준비
- 데이터 준비 프로세스
데이터 준비
파인튜닝용으로 변경
허깅페이스 업로드
📌 파인튜닝 준비
파인튜닝
-
파인튜닝 정의
포메팅 되어있는 포멧에 데이터를 집어넣는 것 -
프로세스
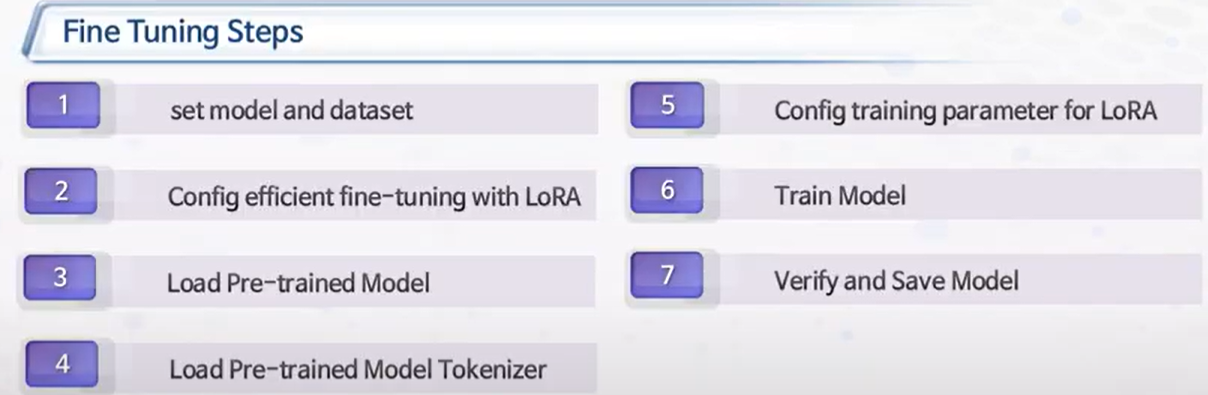
데이터준비
큐로라 방식 튜닝
모델불러오기
토큰 불러오기 -> 마지막 endoftext추가 -
데이터모델과 데이터셋 준비
라마 3을 이용할때 Instruct 모델을 사용 -> 명령어를 따르도록 설계되어서, 주어진 지침이나 명령을 더 잘 이해하고 따를 수 있도록 훈련되어 있다.
base_model = "meta-llama/Meta-Llama-3-8B-Instruct"
dataset_namehk = "harry2341/llm_test"
datasethk = load_dataset(dataset_namehk, split="train")
# load_dataset() : 허깅페이스의 데이터셋을 가져옴
# split="train : 데이터셋의 특정 분할을 로드한다. train, validation, test 가 보통 있고 여기서는 train 데이터만 로드한다.
datasethk[100]
한국어 파인튜닝 모델
야놀자팀에서 라마3를 한국어로 파인튜닝한게 있음.
사용가능할까?
https://huggingface.co/yanolja/EEVE-Korean-Instruct-10.8B-v1.0/blob/main/README.md
📌 언어 모델 평가
언어 처리능력 평가
LLM이 어떤 언어를 잘 이해하는지에 대한 성능 평가가 필요
가장 좋은 것은 사람이 일일히 평가하는 것이지만 시간과 비용이 많이 들어서 정량적인 방법들을 사용한다
MRC
-
정의

-> 질문과 관련된 콘텍스트, 질문과 답변 3가지 데이터를 사용한다
-> llm이 context 문장에서 문제를 만들고 답을 잘하는지 측정한다. -
성능평가 방식
SQUAD 데이터셋
정량적으로 평가를 하기위해서 학계에서 이미 만들어 놓은 데이터 셋들이 있다.

EM 정확하게 얼마나 맞췄는지
F1 너무 타이트한 것보다 좀 더 유연함
CoQA

context 와 사람이 만든 데이터셋이 있고 그것을 비교함
- 결국 머신러닝이 텍스트를 잘 이해하고 있어야 답을 맞출 수 있게 만들어진 데이터셋들이다
한국에 데이터셋
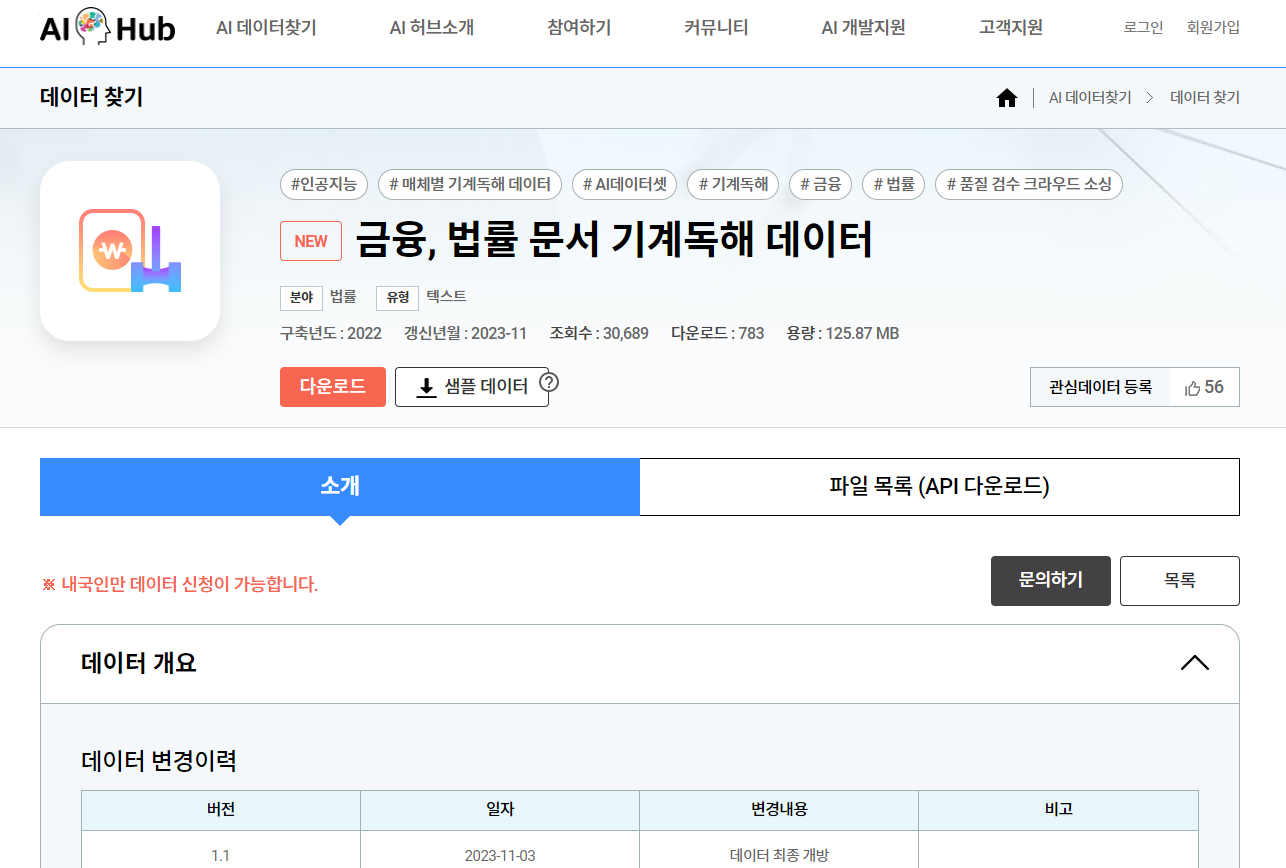
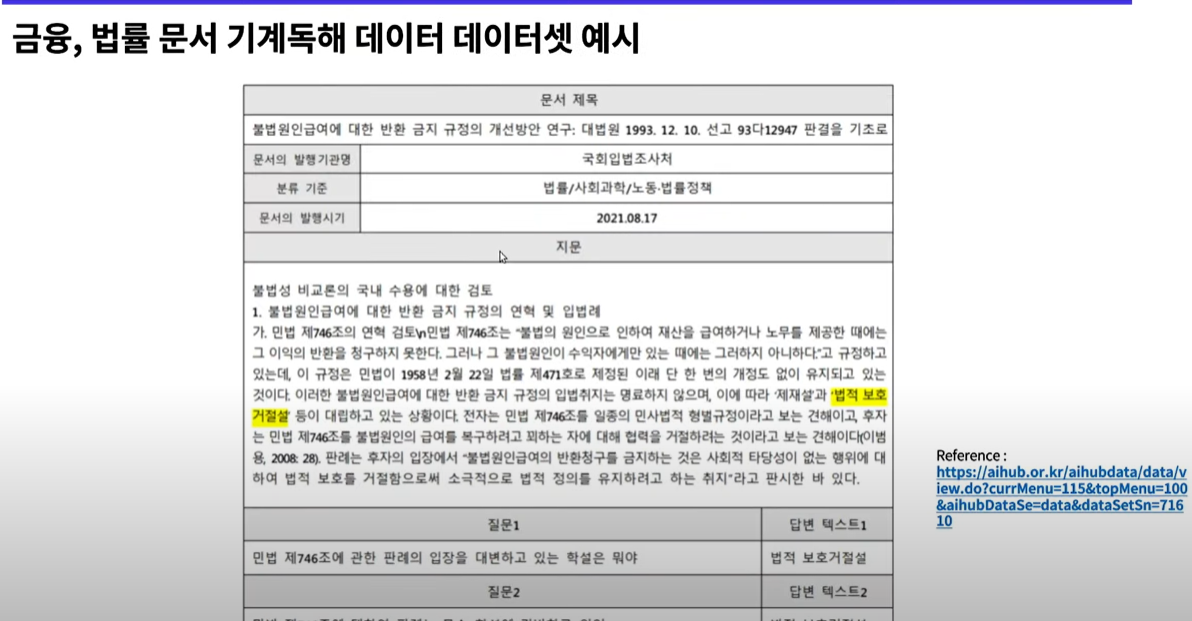
마찬가지로 데이터셋이 있고 질문을 얼마나 잘맞추는지 평가
사람이 파악하기도 힘듦
📖 이후 학습 계획
- 구글 colab으로 파인튜닝 진행

설계엔지니어의 변신