
📖 학습한 내용
- 파인튜닝
📖 핵심내용
📌 파인튜닝
-
목표
특정 문서를 기반으로 답변을 잘하는 모델 만들기 -
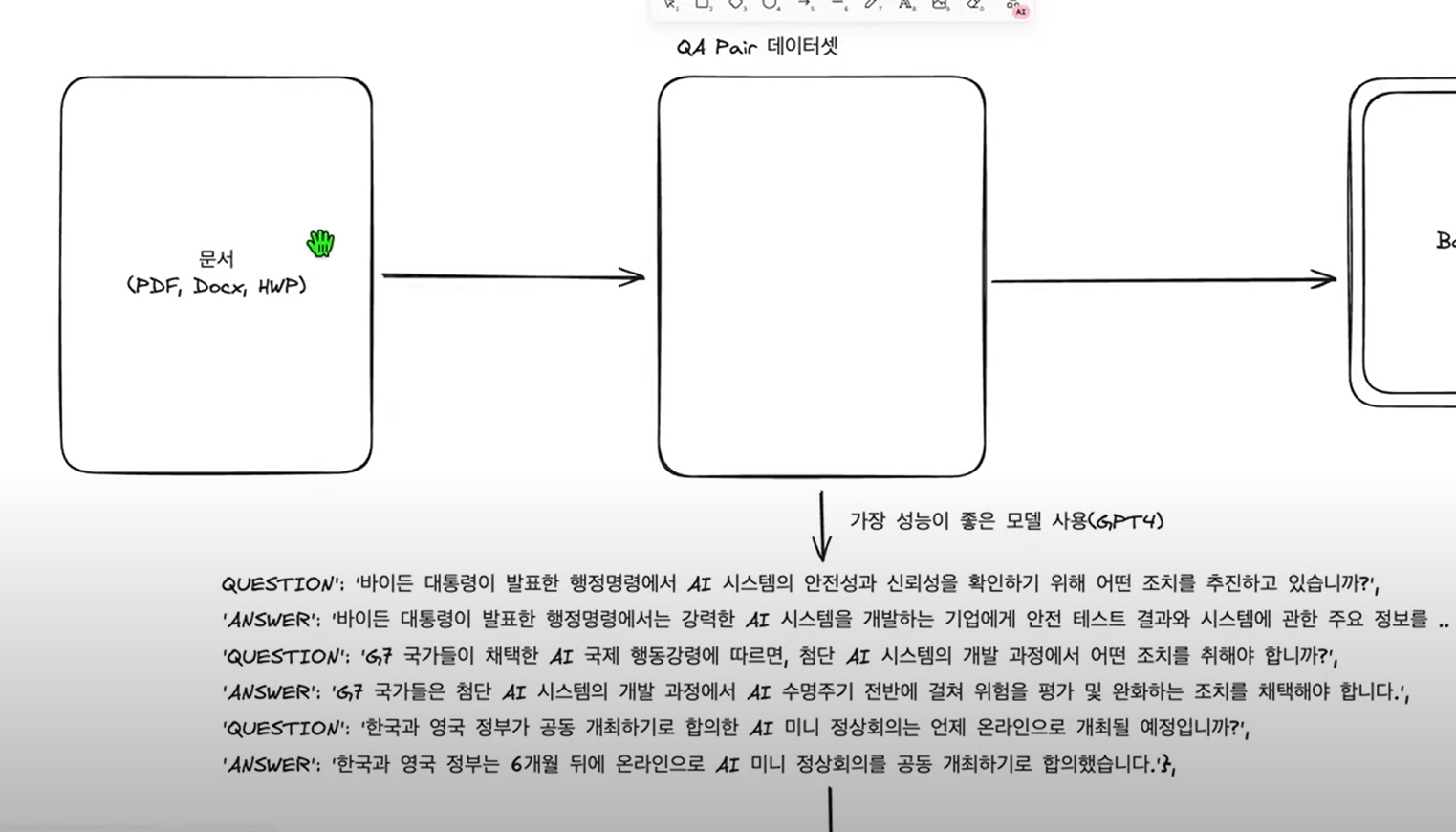
파인튜닝 프로세스
PDF 따위의 어떤 문서를 학습시키기 어렵다
이것을 QA Pair 데이터셋을 만든다. 왜냐하면 GPT따위에서는 모두 묻고 답하는 것으로 이뤄져있기때문이다.
이것을 렝체인의 레그시스템으로 QA 페어를 만든다.
이때 들어가는 데이터의 품질이 이 모든 전체 과정에서 매우 매우 중요하다. 형식도 중요하다.
이때 사람이 하나하나하면 시간이 오래걸리므로 가장 성능이 좋은 모델을 사용한다.
생성된 페어를 첫번째로 jsonl로 로컬에 저장한다. 두번째는 huggungFaceHub에 올린다. 이는 팀프로젝트할때 팀원이 공개데이터를 가져오기 용이하게 한다.
페어가 준비되었다면 모델을 튜닝한다.
이때 베이스모델에 LoRA나 QLoRA를 사용해서 학습한다. (LoRA나 QLoRA 논문 따위 참조) -> 전체는 학습이 현실적으로 불가능하므로, 별도의 어댑터를 만든다. (전체 베이스모델의 1프로 정도)
이후 인퍼런스하거나, 바로 베이스 모델과 로라모델을 병합한다.
이렇게 파인튜닝한 모델이 완성된다.
이것을 Ollama나 LM studio



설계엔지니어의 변신