
📖 학습한 내용
- LLM 원리
📖 핵심내용
📌 LLM 원리
- 언어 모델이란?
모델이란 처리할 수 있는 패턴을 구축하고 아웃풋을 내는 것
언어모델이란 - 언어를 처리할 수 있고 아웃풋을 확률값으로 내는 것
LLM의 작동원리
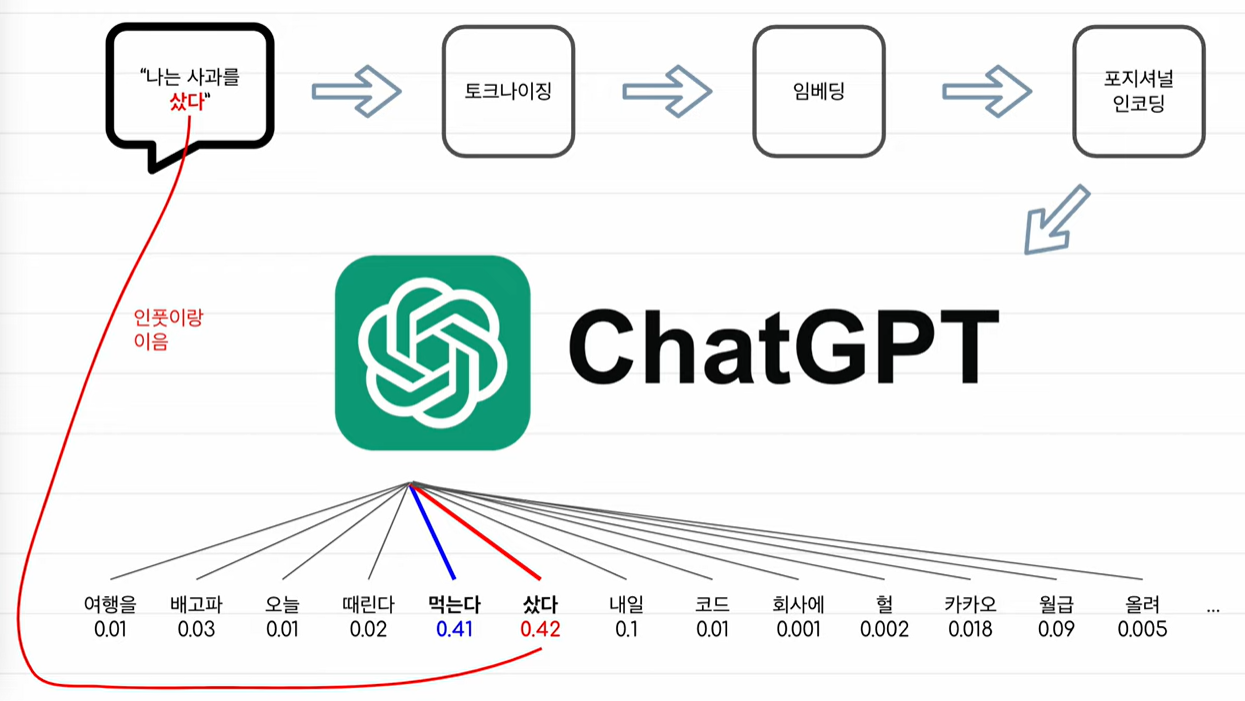
-> 문장에서 다음 단어를 예측하고, 예측된 문장을 다시 모델에 넣는 것을 반복하다 EOS 토큰이 나오면 종료
토크나이징
-
토크나이징
각언어마다 토크나이징 방식이 다르고, 같은 언어별로도 토크나이징 방식이 다르다.
토크나이징이란 각언어의 의미에 맞게 나누고 그것을 ID(숫자)로 만드는 것이다. -
벡터화
학습데이터를 기반으로 방대한 토큰 사전을 기반으로 만들어진다.
토큰들을 기준으로 토큰 아이디를 벡터로 변환한다.
그냥 숫자보다 벡터로 만들면 단어의 의미를 녹여낼 수 있기 떄문이다.
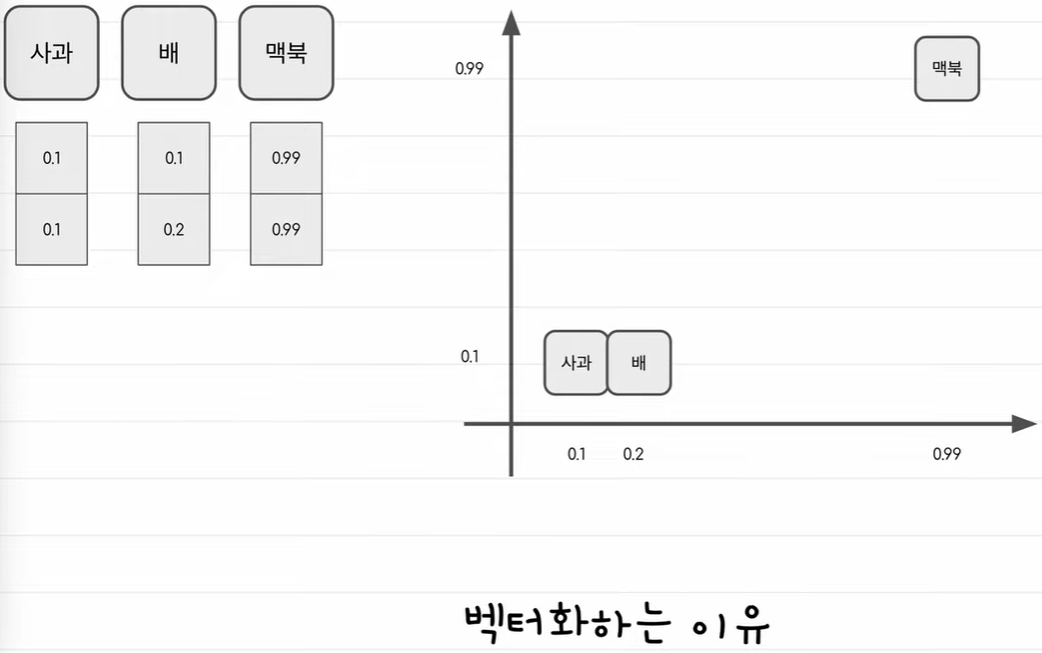
-> 어떤 특성을 기준으로 벡터화 시키면 더 단어의 의미를 이해하기 좋다.
트랜스포머
-
시퀀스변환
예시 : 문장을 다른형태로 바꾸는것 -> 기계번역 -
오리지날 트랜스포머 구조

-> 인코더와 디코더로 이뤄져있는 모델
-> 인코더에서 나온 벡터는 의미를 담고 있어서 콘텍스트벡터라고 불린다

attention(어텐션)
-
어텐션이란?
디코더에서 콘텍스트벡터를 참고하는 것
단어들과의 관계를 구했을때 관계가 깊은 것에 점수를 주는 줘서, 모델이 입력 데이터의 특정 부분에 집중할 수 있도록 하는 메커니즘

-
어텐션 필요성
자연어 처리에서 데이터의 길이(문장의길이)가 다양하고, 길면 중요정보를 놓칠 가능성이 있다. 예를들면 문장 뒤쪽에 중요 정보가 있는데, 설정한 문장길이 때문에 짤리는 것 -> 특정시점에 집중하게하므로 해결함 -
어텐션 스코어
유사도나 관련성을 기준으로, 입력 시퀀스의 각 부분에 대한 중요도를 나타내는 스코어를 계산
예를 들어, 번역 작업에서 특정 단어가 출력될 때, 입력 문장의 어느 단어에 주의를 기울여야 하는지 결정 -
컨텍스트 벡터 (Context Vector)
어텐션 스코어를 기반으로, 입력의 각 부분에 가중치를 부여한 가중합을 계산한 벡터
현재 시점에서 디코더가 참조하는 정보의 요약
-
self attention
똑같은 문장에서 서로 관계를 보는 것
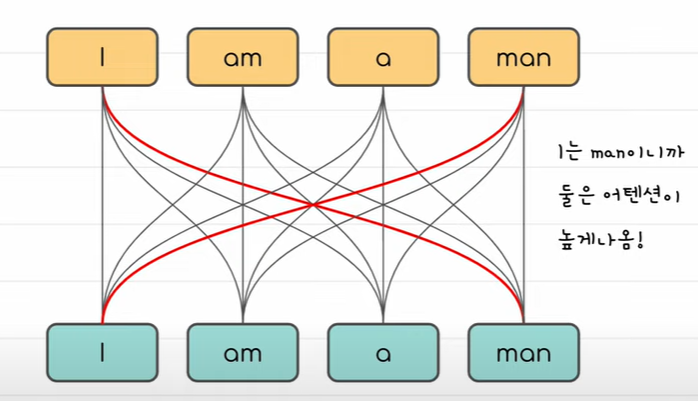
같은 문장 내에서 단어들과의 관계도 중요하다. i와 man이 관계가 있다.
-
multi-head attention
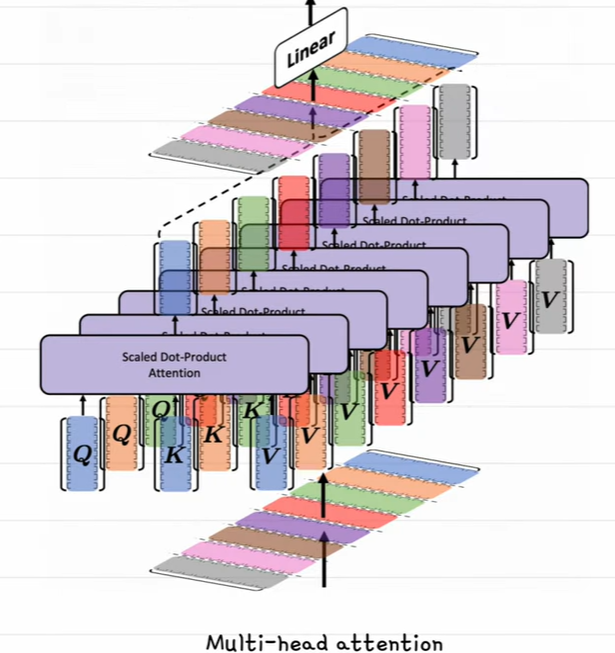
실제 attention을 구할때, 하나의 어텐션으로만 구하지 않는다
단어와 단어 사이의 관계를 보는 여러가지 컨셉을 학습하기 위해서, 문장을 여러개의 헤드라는 벡터로 나누구 각각의 어텐션을 구한 뒤 합친다. -
어텐션 요약
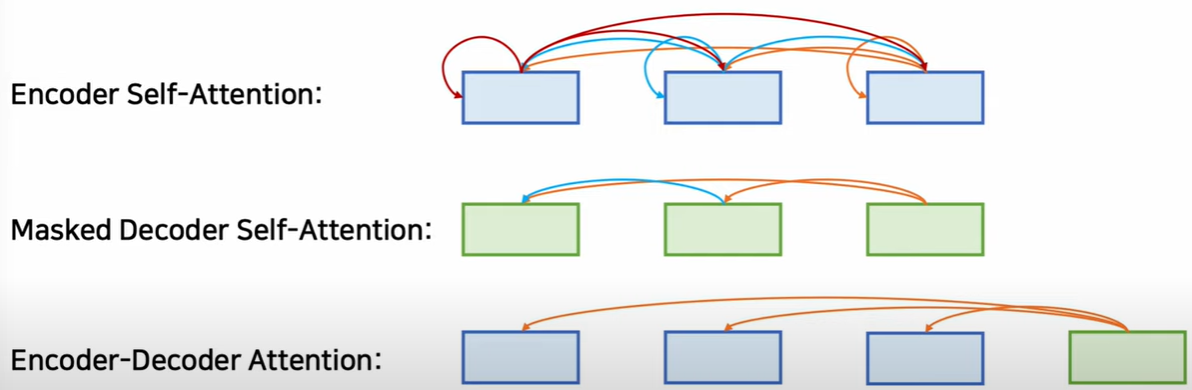
1) 인코더에서 자기자신의 어텐션을 구하면 셀프어텐션
2) 트랜스포머의 디코더 부분에서, 셀프어텐션을 할때 뒤쪽의 단어를 확인하면 치팅이다. 따라서 뒤쪽의 단어를 마스킹하고 앞쪽의 단어만 본다. 이것이 마스크드 디코더 셀프어텐션
3) 인코더에서 나온 context 벡터와 디코더에서 입력과의 관계를 구하는 것을 인코더 디코더 어텐션 이라고 한다.
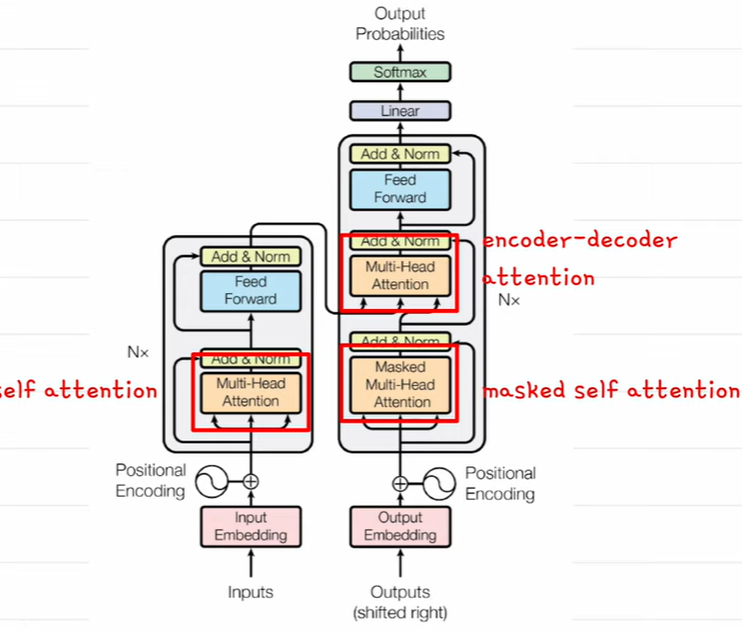
BERT와 GPT
-
주요 차이
트랜스포머 기반의 가장 유명한 모델 두가지
Bert - 인코더 기반, 가벼움, MLM
GPT - 디코더기반, 무거움 CLM -
사전학습?
방대한 양의 데이터로 일반적인 지식을 학습함
사전 학습된 모델을 이용하면, 필요한 도메인에 맞춰 미세조정 -> 시간과 돈을 아낄 수 있다.
Bert 사전학습 방식
-
MLM + NSP 로 이뤄짐
-
MLM
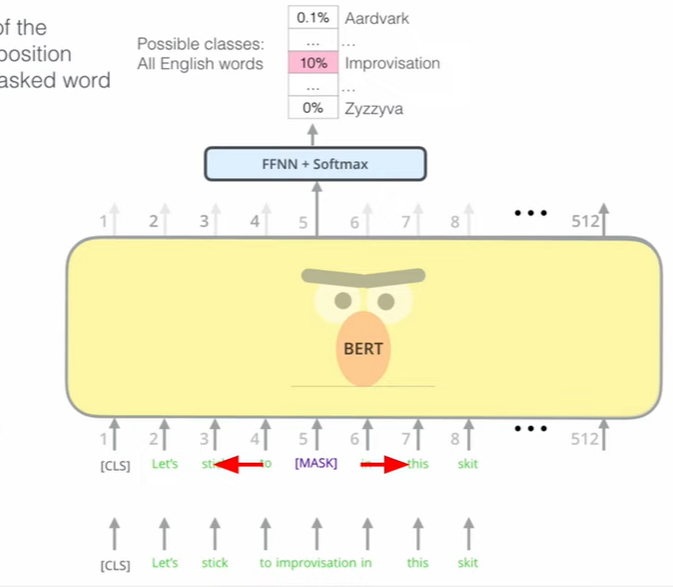
BERT는 주변의 단어로 마스킹된 부분을 학습한다
마스킹 시키고 양옆의 부분을 참고해서 맞춘다. -
NSP

문장을 1개가 아닌 2개를 넣는다. 문장1과 문장2를 구분하는 토큰(CLS)
CLS를 맞추는 훈련을 한다.
다음 문장 맞추는 것도 한다
GPT 사전학습 방식
- CLM

-> 단어 계속 인풋에 붙여가면서 문장을 만든다
-> 이런 형태를 Auto-regressive 라고 한다.
LoRA
-
Low-Rank Adaptation
-
LoRA는 기존 모델의 가중치를 고정하면서, 저차원 행렬로 분해된 새로운 가중치를 추가로 학습하는 방식
-
파인튜닝의 방식 크게 3가지
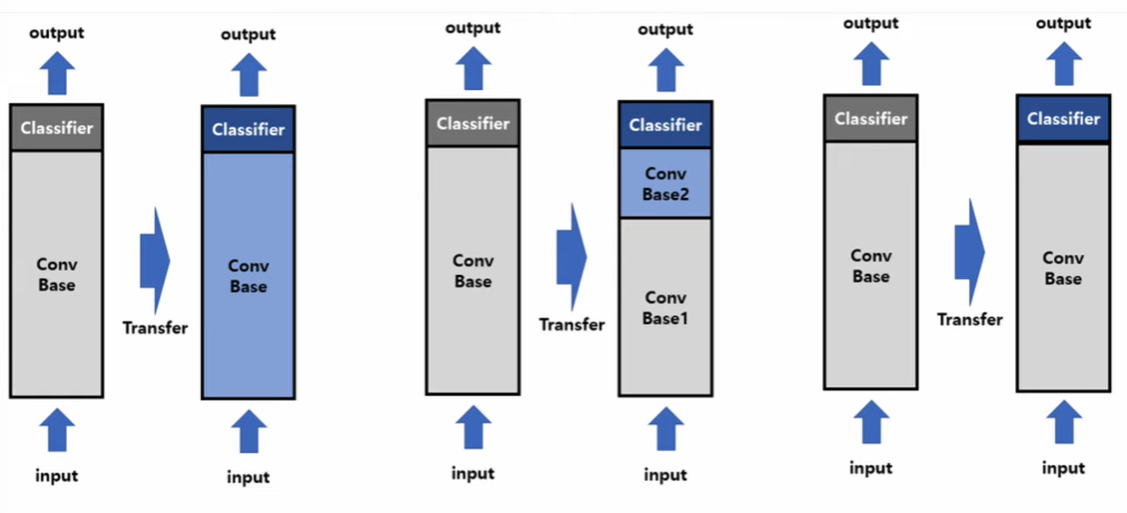
1) 새로운 데이터에 맞춰서 기존 가중치를 전부 업데이트하는 방식 -> 너무 커서 잘 사용하기 힘들다. 효율이 좋지 않음
2) 일부 입력층의 가중치를 고정(프리징)하고 나머지를 업데이트하는 방식
3) 전체를 가중치를 고정시키고 새로운 출력층이나 가중치를 추가해서 그것만 학습하는 방법 -> 로라가 이 방식 중 하나에 해당함 -
가중치 추가 후 파인튜닝
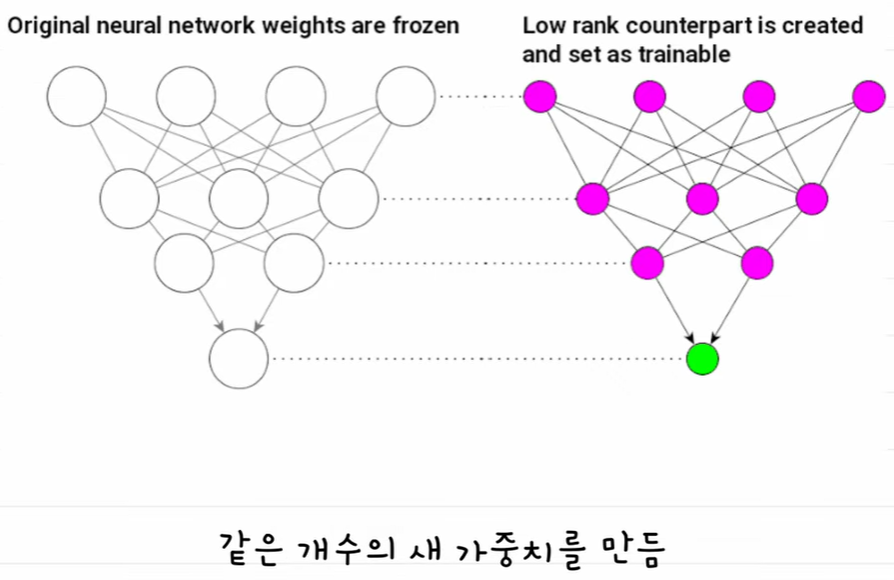
-> 좌측이 원래 가중치, 우측이 같은 모양의 가중치 행렬을 추가
-> 추가한 가중치를 파인튜닝 한다
-> 이것도 전체 파인튜닝하므로 비용이 많이든다. -
저차원 학습
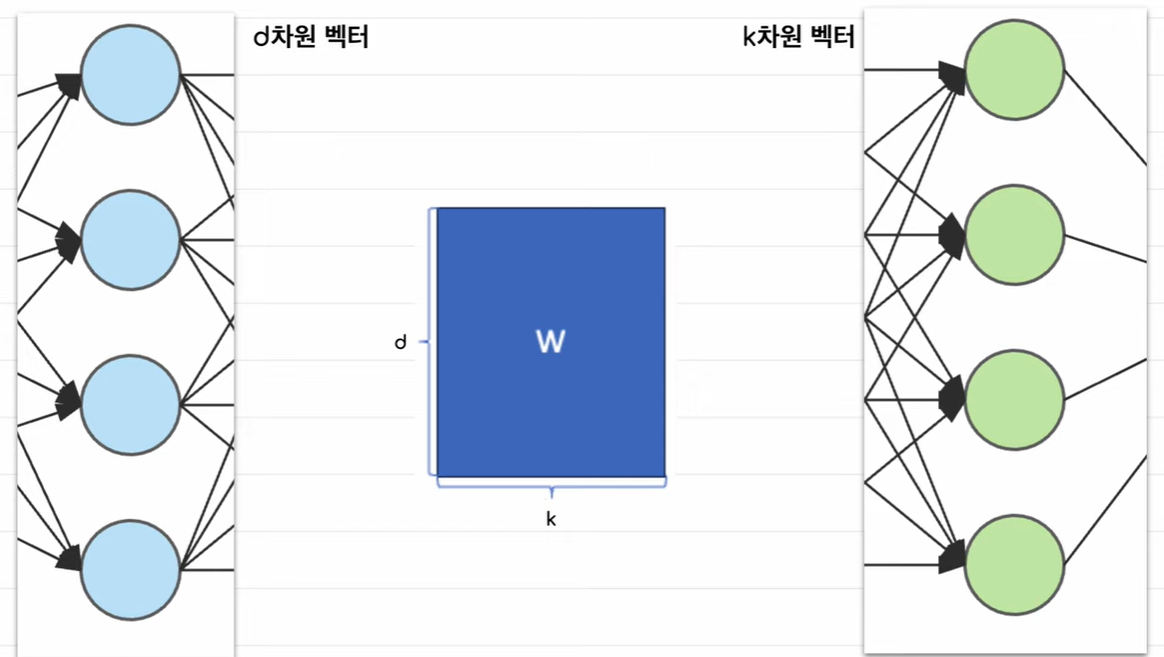
-> d차원 벡터와 k차원 벡터를 학습하려면 d*k 만큼의 파라미터가 생긴다.
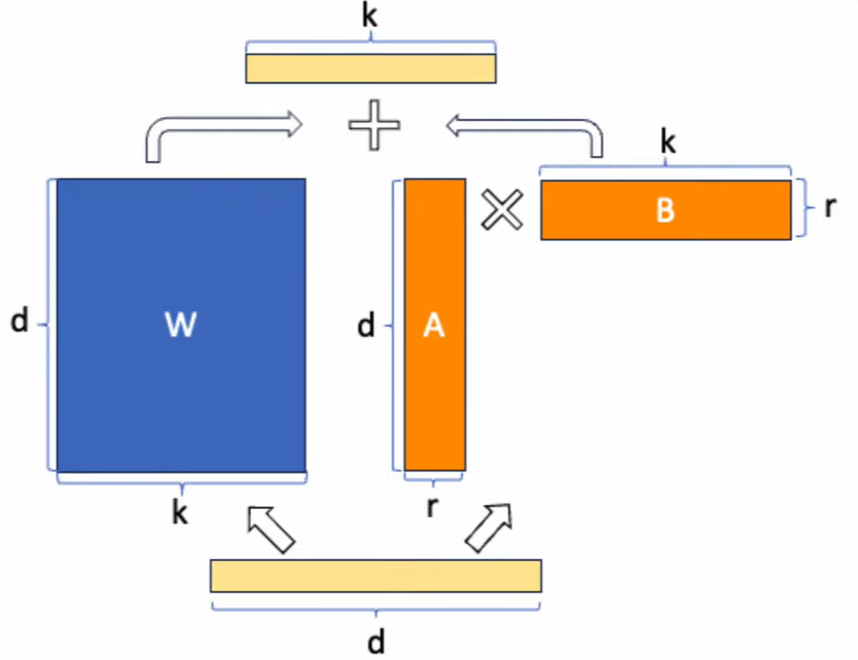
-> 이것을 d*k * k*r 행렬로 만들고 r을 매우 작게 만듦.
-> r 이 작아질 수록 단순해지지만, 학습해야할 가중치가 적어진다.
-> 파인튜닝 후 크기가 작아져서 공유하기 쉽다.
-> 파인튜닝 데이터 셋은 사전학습 데이터 셋보다 매우 작을 것이다. 이런 적은 데이터로 엄청난 양의 파라미터들 학습시키면, 학습데이터 자체를 기억한다. 이것이 바로 오버피팅의 문제가 생긴다.
📖 이후 학습
- 허깅페이스에 올린 모델 성능평가
- 주어진 PDF파일에서 오픈소스 모델을 활용하여 질의응답 데이터셋 추가 생성
- 질의응답 데이터 증강하여서 데이터셋 추가 생성
