
Word2Vec 실습
- 특정 단어에 해당되는 단어의 유사도를 찾고 가장 비슷한 단어가 어떻게 나오는지 결과를 확인함
- 한국어 데이터를 사용한 한국어 Word2Vec 모델 제작
Word2Vec
Word2Vec이란?
- 'Word to Vector'의 약자로 머신러닝을 통해 학습하는 모델
- 단어(Word)를 컴퓨터가 이해할 수 있도록 수치화된 벡터(Vector)로 표현하는 기법 중 하나
- 분산표현(Distributed Representation) 기반의 워드임베딩(Word Embedding) 기법 중 하나
워드 임베딩(Word Embedding)?
- 컴퓨터가 이해할 수 있도록 텍스트를 적절히 숫자로 변환
- 각 단어를 인공 신경망 학습을 통해 벡터화
분산표현(Distributed Representation)이란?
- 정한 개수의 차원으로 대상을 대응시켜서 표현
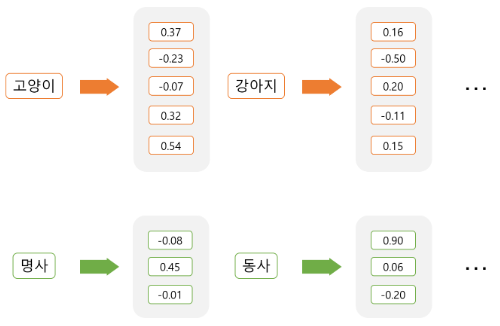
-> 해당 배열에 대한 Index 위치값을 다르게 지정
-> 배열의 벡터 표현
네이버 영화 리뷰 데이터를 이용한 Word2Vec 모델 생성
Word2Vec 단계
- 데이터 수집
- request 사용
- 데이터 정제
- 결측값 삭제
- 한글 외 문자 제거
- 불용어 제거
- 데이터 확인
- 분포도 시각화
- 모델 학습
- 추측
데이터 수집(불러오기)
사용할 데이터: 네이버 영화 리뷰 데이터
분석에 필요한 패키지 설치 및 준비
!pip install konlpy # 설치
import pandas as pd # 테이블구조
import matplotlib.pyplot as plt # 시각화
import urllib.request # 파일 불러오기
from gensim.models.word2vec import Word2Vec # 모델 라이브러리
from konlpy.tag import Okt # 형태소 분석기
from tqdm import tqdm # 진행 표시줄(Progress Bar)파일 다운 및 확인
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt") # 파일 다운
train_data = pd.read_table('ratings.txt') # 다운된 파일 읽기
train_data[25:30] # 중간 5개 출력 - [시작:끝]
-> 형태 파악
print(len(train_data))
-> 리뷰 총 갯수가 200000개인것을 확인
urlretrieve()
urllib.request.urlretrieve('경로', filename='파일명')
- 현재 디렉토리에 경로에 있는 파일을 다운로드한다.
read_table()
pandas.read_table('파일객체')
- 텍스트 파일이나 표 형식의 데이터를 DataFrame으로 읽어오는 데 사용
데이터 정제
결측값 삭제
print(train_data.isnull().values.any()) # 결측값이 있는지 확인
-> 어딘가에 결측값이 있는지 확인함
train_data = train_data.dropna(how = 'any') # Null 값이 존재하는 행 제거
print(train_data.isnull().values.any()) # Null 값이 존재하는지 다시 확인
print(len(train_data)) # 리뷰 개수 출력
-> 결측값이 삭제 후 리뷰 개수 199,992개인 것을 확인
한글 외 문자 제거
- 정규 표현식(Regular Expression, 레젝스(regex))을 통해 한글이 아니면 제거
- 한글이 아닌것 Regex = [^ㄱ-ㅎㅏ-ㅣ가-힣 ]
# 정규 표현식을 통한 한글외 문자 제거
# train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]+", "", regex=True)
train_data[25:30] # 중간 5개 출력 - [시작:끝]
-> 확인해보니 한글 제외하고 숫자나 영어가 사라짐
불용어 제거
- 형태소 분석기 Okt를 사용
- 학습(모델) 시에 사용하고 싶지 않은 단어들인 불용어를 제거
# 옵션(Optional)
# train_data = train_data.head(20000) #처음 20,000개만 사용
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
okt = Okt() # (시간소요: 총~14분, 20000개/~1분40초)
tokenized_data = [] # token을 저장할 배열(array)
for review in tqdm(train_data['document']):
tokenized_review = okt.morphs(review, stem=True) # 토큰화
stopwords_removed_review = [word for word in tokenized_review if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_review)데이터 확인
- 분포도 시각화 전처리 후 토큰화 데이터를 각 리뷰의 길이 분포 히
스토그램으로 확인
# 리뷰 길이 분포 확인
print('리뷰의 최대 길이 :',max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이 :',sum(map(len, tokenized_data))/len(tokenized_data))
plt.hist([len(review) for review in tokenized_data], bins=50)
plt.xlabel('length of samples') # 샘플 길이 - x축 레이블
plt.ylabel('number of samples') # 샘플 길이에 해당되는 빈도수 - y축 레이블
plt.show() # display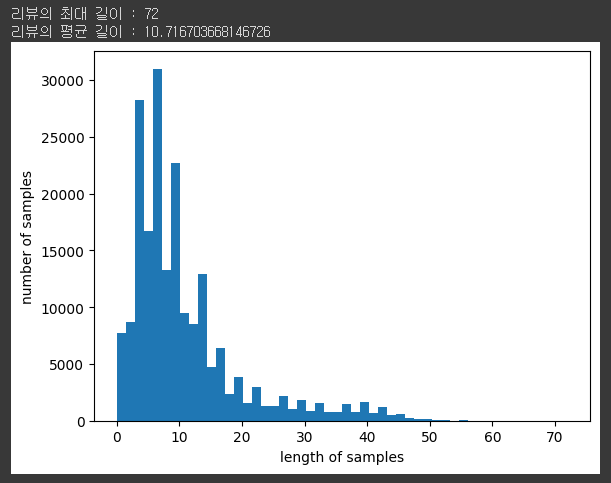
모델학습
- Word2Vec으로 토큰화 된 네이버 영화 리뷰 데이터를 학습한다
from gensim.models import Word2Vec # 모델 불러오기(import)
model = Word2Vec(sentences = tokenized_data, vector_size = 100, window = 5, min_count = 5, workers = 4)
# 약 20초 소요
model.wv.vectors.shape # 완성된 임베딩 매트릭스의 크기 확인
-> 단어: 16477개, 각 단어: 100차원
Word2Vec()
Word2Vec(sentences='None', vector_size=None, window=None, min_count=None, workers=None)
- Gensim 라이브러리에서 제공되는 함수로, 단어 임베딩을 학습하는 데 사용됩니다. 이 함수는 주어진 텍스트 데이터를 이용하여 단어 벡터를 학습하는 Word2Vec 모델을 생성합니다.
- sentences: 학습에 사용할 텍스트 데이터입니다. 텍스트 데이터는 토큰화된 문장의 리스트 형태로 전달됩니다.
- vector_size: 단어 벡터의 차원을 지정합니다.
- window: 학습할 때 고려할 주변 단어의 윈도우 크기를 지정합니다.
- min_count: 모델에 포함할 최소 단어 빈도를 지정합니다.
- workers: 학습을 수행하는 동안 사용할 스레드 수를 지정합니다.
wv
- wv는 Word2Vec 모델의 단어 벡터를 접근할 수 있는 KeyedVectors 객체를 나타냅니다.
- Word2Vec 모델을 학습하면 각 단어는 벡터로 표현되어 있습니다. wv 객체를 사용하여 특정 단어의 벡터를 가져올 수 있습니다
추측
- '이정재'과 유사한 단어
print(model.wv.most_similar("이정재"))
- '최민수'과 유사한 단어
print(model.wv.most_similar("최민수"))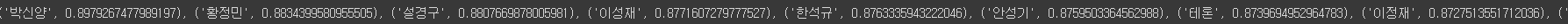
- '히어로'와 유사한 단어
print(model.wv.most_similar("히어로"))
most_similar()
word2vector객체.wv.most_similar(positive/negative='text', topn=None)
- positive: 유사한 단어를 찾기 위해 양의 가중치를 부여할 단어들의 리스트입니다.
- negative: 유사하지 않은 단어를 찾기 위해 음의 가중치를 부여할 단어들의 리스트입니다.
- topn: 반환할 유사한 단어들의 개수를 지정합니다. 기본값은 10입니다.
하다보니 정말 재미있는 프로젝트였다.

설계엔지니어의 변신