
형태소 분석
형태소와 형태소 분석의 이해
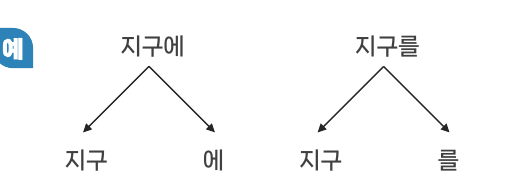
토큰
- 형태소와 같은말
- 더 이상 분해하면 의미를 가질 수 없는 가장 작은 말의 단위
- 어절보단 작지만 의미를 가진 명사
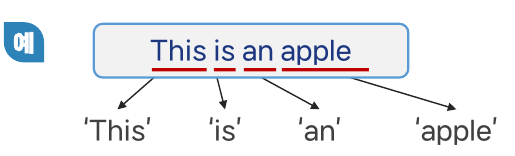
토큰화
- 말뭉치에서 토큰을 분리하는 작업
- 파이썬에서는 토큰을 분리하면 배열의 형태로 이루어짐
문장 토큰화
- 문장의 마침표(.), 개행문자(\n), 느낌표(!), 물음표(?) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것
- 문장에 따라 기호로 분리 안되는 경우도 있음

형태소 분석 기초 실습 사용 방법
split()
- 형태
텍스트.split('구분자')
- 구분자 기준으로 문자를 나눈다.
- 구분자를 지정하지 않으면 기본적으로 공백을 기준으로 분할
영화 평론을 토큰화 해보자
- 예시 문장
kor_text = '살인 용의자와 변호사가 주고받는 대화로 '\
'인해 달라지는 상황에 따라 얼굴을 바꾸는 배우들의 '\
'다양한 연기를 볼 수 있는 것 또한 장점이다'
print(kor_text.split())
print( type(kor_text.split()))
-> 용의자와, 변호사가, 대화로...등등 의 토큰으로 분리
결론
- 위의 예제에서는 '와', '가', '로', '을', '를' 들이 붙어있어 이를 제거해주시 않으면 기계는 다른 의미의 단어로 인식하게 된다.
MeCab 형태소 분석기
- 은전한닢 프로젝트에서 MeCab 엔진이 일본어와 한국어의 유사점으로 인해 한글 분석에도 동작하는 것을 확인하고 개발한 한국어 형태소 분석기
MeCab 사용하기
- Mecab-class라는 오픈 소스를 KoNLPy 모듈에 사용
- Git Clone 명령을 통해 소스 코드 가져오기
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git- Mecab-ko-for-Google-Colab으로 디렉토리 이동 후 install 시작
%cd Mecab-ko-for-Google-Colab # directory 변경
!bash install_mecab-ko_on_colab190912.sh # 인스톨은 3-4분 정도 소요됨- 형태소 분석
from konlpy.tag import Mecab
tokenizer = Mecab() # Mecab 객체를 불러옴
print(tokenizer.morphs(kor_text)) # morphs 함수를 사용
-> 와', '가', '로', '을', '들', '의' 같은 조사들이 다 다른 토큰으로 인식되고, 배열로 만들어짐
morphs()
- 형태
형태소분석기.morphs('텍스트')
- 한국어 형태소 분석을 수행하는 함수
KoNLPy 라이브러리 사용하기
KoNLPy
- "코엔엘파이"라고 읽으며. 한국어 자연어처리를 위한 파이썬 패키지
- korean natural language processing in python의 약자
종류
- 꼬꼬마 (Kkma)
- Kkma는 서울대학교의 지능형 데이터 시스템(IDS) 연구소에서 개발한 자바로 작성된 형태학적 분석기 및 자연어 처리 시스템이다.
- pprint: 인코딩을 잡아주는 기능의 함수로 konlpy.utils에 포함되어 있다.
- Komoran
- 자바 한국어 형태소 분석기 (Komoran)
- KOMORAN은 2013 년부터 Shineware가 개발 한 Java로 작성된 비교적 새로운 오픈 소스 한국어 형태 분석기이다
- 한나눔(Hannanum)
- JHannanum은 자바로 작성된 형태학적 분석기 및 POS(Part of Speech, 품사) 태거로, 1999년부터 KAIST의 시맨틱 웹 연구 센터(SWRC)에서 개발했습니다.
- Okt, 'Open Korean Text'(Twitter)
- 스칼라로 쓰여진 한국어 처리기로. 현재 텍스트 정규화와 형태소 분석, 스테밍을 지원하고 있다. 짧은 트윗으로 시작해서 지금은 긴 글도 처리할 수 있다. (twitter-korean-text)
- 은전한닢 프로젝트 (Mecab)
- 원래 교토대학교 정보학 대학원에서 개발한 일본의 형태학적 분석기이자 POS 태거인 MeCab은 한국어에 적응하기 위해 은전프로젝트(은전한닢 프로젝트, 오픈소스)에 의해 MeCab-ko로 수정되었다.
- 윈도우에서 사용불가한 단점이 있다.
꼬꼬마 코모란 트위터 한나눔 출력 비교
## 설치하기
!pip install konlpy
# -*- coding: utf-8 -*-
from konlpy.tag import Kkma
from konlpy.tag import Komoran
from konlpy.tag import Hannanum
from konlpy.tag import Okt
example = u'살인 용의자와 변호사가 주고받는 대화로 '\
'인해 달라지는 상황에 따라 얼굴을 바꾸는 배우들의 '\
'다양한 연기를 볼 수 있는 것 또한 장점이다'
taggers = [ ('꼬꼬마', Kkma()),
('코모란', Komoran()),
('트위터', Okt()),
('한나눔', Hannanum())]
####################################################
# 공통 함수 테스트
###################################################
for name,tagger in taggers:
print('%s %s %s'%('-'*10,name,'-'*10))
try:
print(tagger.pos(example)) # 품사 태깅
print(tagger.morphs(example)) # 형태소만 추출
print(tagger.nouns(example)) # 명사 추출
except Exception as e:
print(e)
#####################################################
# 단독 함수 및 옵션 테스트
#####################################################
print('='*50)
# [ 꼬꼬마 ]
print( taggers[0][1].sentences( example ) ) # 문장 추출
# [ 코모란 ]
print('-'*25, '코모란','-'*25)
print( taggers[1][1].pos( phrase=example, flatten=False ) ) # flatten=False이면, 어절 단위 PoS Tagging
print( taggers[1][1].pos( phrase=example, flatten=True ) ) # 차이 비교용
# [ Okt(트위터) ]
print('-'*25, 'otk(트위터)','-'*25)
print( taggers[2][1].pos( phrase=example, norm=True, stem=True) ) # norm=True 이면, 토큰 노멀라이즈, stem=True 이면, 토큰 스테밍
print( taggers[2][1].pos( phrase=example, norm=False, stem=False) ) # 차이 비교용

-> 같은 문장을 넣어도 분석기마다 형태소를 다르게 출력한다.
-> 노말라이즈와 스템은 형태소를 원형으로 출력하냐안하냐 차이
결과 저장하기
- pandas의 DataFrame() 함수가 필요하다.
to_csv()
- 형태
pandas.DataFrame.to_csv(위치, index=False, header=False)
to_excel()
- 형태
pandas.DataFrame.to_excel(위치, sheet_name='None')
형태소 분석과 불용어 제거
형태소 분석이란?
- 텍스트 토큰화(Text Tokenization)라고 하며 말뭉치(corpus)로부터 토큰을 분리하는 작업이다.
토큰은 형태소를 의미한다
불용어 제거
- 데이터 전처리(Date Processing) 혹은 데이터 정제(Date Cleaning)의 한 과정
- 형태소 분석(토큰화) 후 의미가 없거나 분석에 도움이 되지 않는 조사, 접속사 등을 제거하는 방법
- 불용어 제거를 통해 필요한 토큰 혹은 필요한 형태소만 저장함
nltk를 사용한 영어 불용어 제거
nltk(Natural Language Toolkit)
- 영어에 대한 기호 및 통계적 자연어 처리를 위한 라이브러리
- stopwords 라이브러리를 사용하면 불용어 제거
- 산업용으로 사용할 수 있을 정도 강한 NLP(자연어처리) 라이브러리를 위한 래퍼(wrapper)를 제공
- WordNet과 같은 50개 이상의 말뭉치 및 어휘 리소스에 대한 사용하기 쉬운 인터페이스를 제공
nltk 실습
nltk 설치 및 불용어 데이터셋 다운로드
# stopwords 다운로드 하기
import nltk
nltk.download('stopwords')영어의 불용어 데이터세트 보기
stop_words = nltk.corpus.stopwords.words('english') # nltk(큰패키지),corpus(작은패키지), stopwords(모듈), words(함수)
print('영어 불용어:', stop_words)
english_count = len(nltk.corpus.stopwords.words('english'))
print('영어 불용어 갯수:', english_count)
first40 = nltk.corpus.stopwords.words('english')[:40]
print('처음 40개:', first40)
- nltk.corpus 페키지/모듈 및 리더(reader)는 다양한 형식의 코퍼스 파일을 읽는 데 사용할 수 있는 함수를 제공
- nltk.corpus의 불용어 사전 데이터셋이다
불용어 제거하기 (영어) 실습
punkt
- 비지도 학습(unsupervised)이 가능한 모델(model)로 레이블이 지정되지 않은 데이터에 대해 학습할 수 있다
- word_tokenize를 사용하기 위해 다운로드
nltk.tokenize
- 토크나이저는 문자열(string)을 하위 문자열(substring) 목록으로 나눕니다.
- 예를 들어, 토크나이저를 사용하여 문자열에서 단어와 구두점(punctuation)을 찾을 수 있습니다.
- 구두점: 앰퍼샌드(&), 아포스트로피('), 콜론(:), 쉼표(,) 등
word_tokenize()
- 토큰화를 실행하는 함수
set()
- set() 함수를 사용하여 생성된 데이터형은 세트(set)
- 중복된 요소가 없는 컬렉션을 나타soa
- {} 중괄호 안에 요소들을 나열
- set() 함수를 사용하여 리스트, 튜플을 세트로 변환
punkt 다운로드 하기
import nltk
nltk.download('punkt')토큰에서 불용어 제거
from nltk.corpus import stopwords # 불용어 목록 만들기 위함
from nltk.tokenize import word_tokenize # 문장을 공백 따위 기준으로 토큰화 시키는함수
example = "Passion is not an important thing for me. It's everything."
stop_words = set(stopwords.words('english')) # 불용어 영어 데이터셋을 set형으로 만들어 중복제거
word_tokens = word_tokenize(example) # 문장을 토큰화
result = []
for token in word_tokens: # 토큰화 한 문장의 토큰을 불용어 리스트에 없다면, 공 리스트에 추가
if token not in stop_words:
result.append(token)
print(word_tokens)
print(result) 
-> 'thing', '.', 'It', "'s" 는 큰 의미 없는 불용어지만 살아있는 것을 확인
불용어 사전(stop words)에 직접 단어 추가하기
# stop words - 불용어 목록에 추가하기
stop_words.add('It')
stop_words.add("'s")
stop_words.add(".")
stop_words.add("thing")
result = []
for token in word_tokens: # 토큰화 한 문장의 토큰을 불용어 리스트에 없다면, 공 리스트에 추가
if token not in stop_words:
result.append(token)
print(word_tokens)
print(result) 
add()
- 형태
set형객체.add(데이터)
- set() 형 객체에 데이터를 추가한다.
- 이미 있는 데이터라면 아무일도 일어나지 않는다.
한국어 불용어 제거
- 한글은 영어와 다른점이 큰 이유로 한국어 형태소 분석으로 가장 많이 사용되는 konlpy의 okt를 사용
- nltk의 stopwords에서는 한국어 불용어를 지원하지 않기 때문에 별도로 처리
- 의미없는 단어 발견 시, 불용어 사전에 추가하는 작업 필요
- 한국어 불용어를 처리하는 가장 좋은 방법은 txt나 csv 파일에 불용어를 직접 정리해놓고, 이를 불러와서 사용하는 것
konply.tag
- tag 패키지는 KoNPLy의 subpackage중 하나로 여러 종류의 한국어 형태소 분석기 및 자연어 처리 시스템 모듈을 가지고 있다.
Okt 분석기
- 'Open Korean Text'의 줄임말로 Twitter란 이름으로 시작했다.
- 스칼라로 쓰여진 한국어 처리기로. 현재 텍스트 정규화와 형태소 분석, 스테밍을 지원하고 있다. 짧은 트윗으로 시작해서 지금은 긴 글도 처리할 수 있다. (twitter-korean-text)
코드 실행 준비
# KoNLPy 설치하기
!pip install konlpy
#필요한 라이브러리 불러오기(import)
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from konlpy.tag import Okt
okt = Okt()한국어 불용어 제거 실습
- 불용어를 직접 쓰고 제거하며 실습
okt = Okt()
example = '살인 용의자와 변호사가 주고받는 대화로 '\
'인해 달라지는 상황에 따라 얼굴을 바꾸는 배우들의 '\
'다양한 연기를 볼 수 있는 것 또한 장점이다' # 예제 텍스트
stop_words = "와 가 는 로 는 에 을 를 들 의 수 있는 것 이다" # 불용어 사전
stop_words = set(stop_words.split(' ')) # 스트링을 split()으로 공백기준으로 나눈뒤, 리스트형으로 만들고 그걸 중복을 없애기위해 set형으로 만듬
word_tokens = okt.morphs(example)
'''
result = []
for token in word_tokens:
if token not in stop_words:
result.append(token)
'''
result = [word for word in word_tokens if not word in stop_words] # 위와 같은 내용이지만 한줄로 표현 가능
print('불용어 제거 전 :',word_tokens)
print('불용어 제거 후 :',result)
-> 이렇게 불용어가 제거하여 전치리 완료하였다.
결국 핵심은 문장을 토큰화 만들고, 불용어 데이터 셋을 가져와서, if not을 이용하여 문장에서 불용어를 제거하여 전처리한다!
데이터 변환(Data Transformation)
- 단어사전를 사용하여 같은 의미의 단어를 변경. 이를 데이터 변환 (Data Transformation)이라고 한다.
이음동의어: 같은 의미를 다른 단어들의 모음(사전)
분석제외단어: 의미가 없어 제외하는 단어들의 모음(사전)
데이터 변환 과정
1.데이터 확인
2.이음동의어와 분석제외단어 데이터 확인
3.데이터 파일 버전확인 및 다음버전 준비
4.단어사전 데이터 준비하기
5.데이터 전처리
6.이음동의처 처리
7.분석제외단어 처리
8.변환된 데이터 확인
9.csv파일로 출력(export)하기
단계별 데이터 변환하기
데이터 확인

-> 각 문장 형식의 값을 하나의 Token 혹은 하나의 문자라고 계산하여 작업
-> 쉼표는 하나의 문장처럼 인식됨
이음동의어와 분석제외단어 데이터 확인
- 이음동이어 변환 데이터
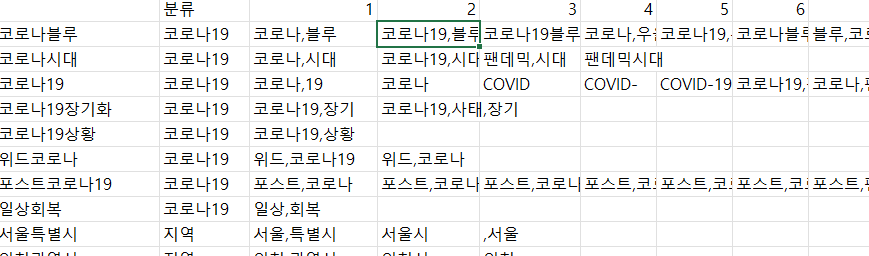
-> 이음 동의어 사전을 만듬
-> 예를 들면 코로나,블루’, ‘코로나19,블루’, ‘코로나19블루’ 등의 단어는 모두 ‘코로나블루’로 변환
- 분석제외단어 데이터
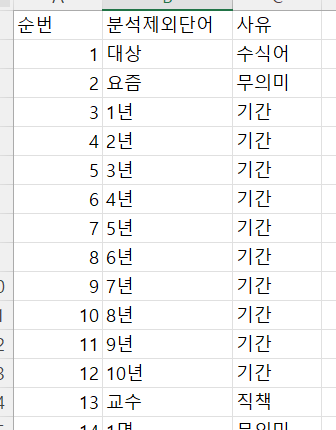
데이터 파일 버전확인 및 다음버전 준비
- 새로 파일을 Expert할 때 마지막 버전 +1한 버전을 만들기 위한 코드
listdir()
os.listdir(경로)
- 디렉토리에 있는 모든 파일 및 서브디렉토리의 이름을 리스트로 반환
- 경로가 빈갑이면 현재 작업 디렉토리의 파일 및 디렉토리 목록을 반환
import pandas as pd
import os # OS는 특정 파일에 어떤 Directiory가 있는지 확인할 수 있는 라이브러리
keyword = "covid"
dirs = os.listdir() # 현재 작업중인 디렉토리 파일 명을 리스트로 반환
files = list(filter((lambda x: x.find(f'{keyword}_unsep_v') == 0),dirs)) # dirs 리스트 안에서 covid_unsep_v으로 시작하는 파일들 모두 찾고 리스트형으로 반환
files = list(filter(lambda x: x.find('.csv') != -1,files)) # 찾은 파일 리스트들의 끝부분에 .csv를 포함하는지 찾고 리스트에 반환
versions = [int(f[len(f'{keyword}_unsep_v'): -len('.csv')]) for f in files] # 파일의 버전을 확인
version_latest = max(versions) # 버전이 가장 높은 값을 최신으로
version_new = version_latest + 1
print(dirs)
print(files)
print(versions)
print(version_latest)
print(version_new)
단어사전 데이터 준비하기
import sys
#load
filename = f"{keyword}_unsep_v{0}.csv"
data = pd.read_csv(filename, header = None, index_col = None, dtype = str)[0] # 판다스로 csv파일 읽음
print(data)
words_exclude = pd.read_excel("단어사전.xlsx", sheet_name = "분석제외단어")['분석제외단어'] #판다스로 단어사전의 분석제외단어 시트의 분석제외단어 열 반환
print(words_exclude)
synonyms = pd.read_excel("단어사전.xlsx", sheet_name="이음동의어", index_col = 0, header = 0) # 판다스로 단어사전 엑셀에서 이음동의어 시트를 반환
print(synonyms)
synonyms = synonyms[synonyms.columns[1:]].transpose() # 컬럼 중 가장 앞 분류 컬럼 제외하고 열을 행에 배치
synonyms.index = range(0, len(synonyms)) # 행 인덱스를 0~ 끝까지배치
print("--===== transpose() 후 =====--")
print(synonyms)

-> Transpose를 시키는 이유는 column 별로 묶여져 있는 형태가더 변환하기 쉽기 때문이다.
데이터 전처리
쉼표(,)로 묶기
단어를 구분하기 위해서 쉼표로 묶도록 함
분석에 해당되지 않는 단어들은 묶이지 않기 때문에 구분할 수있는 장점이 있음
- 분석제외단어
- null 값 정리
#preprocessing data for i in words_exclude.index: words_exclude[i] = f',{words_exclude[i]},' # 예) 코로나 => [ ,코로나, .... ,코로나19, ]
for to in synonyms: # dropna 함수를 사용한 것만 Na 혹은 NaN 부분은 쉼표 묶임이 Skip됨
a = synonyms[to].dropna() # Na를 없애주는 함수
for i in a.index:
a[i] = f',{a[i]},'
synonyms[to]=a
for i in data.index:
data[i]=f',{data[i]},'
#### 이음동의처 처리#processing data
##synonyms
for synonym in synonyms:
synonym_ls = synonyms[synonym].dropna() # Na 부분은 Skip
for s in synonym_ls:
for i in data.index:
data[i] = data[i].replace(s,f',{synonym},') # 이음동의어를 찾아 데이터로 변환
#print(f'{synonym} replaced')
print(data)
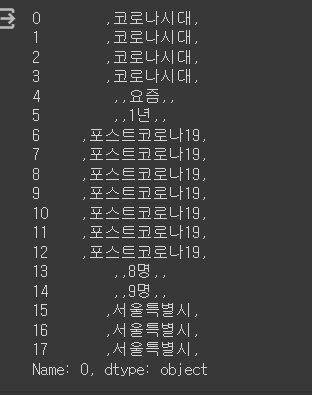
#### 분석제외단어 처리##exclude
for word in words_exclude:
for i in data.index: # 제거할 단어면 ','로 대체
data[i]=data[i].replace(word,',')
#print(f'{word[1:-1]} excluded')
print(data)
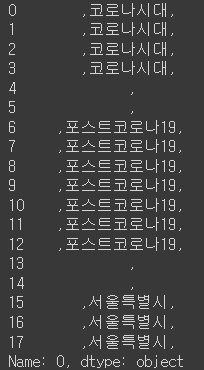
#### 변환된 데이터 확인postprocessing data
for i in data.index:
data[i] = data[i][1:-1] #슬라이싱 1 - 시작 index, -1 => 끝 index. 처음과 끝을 빼고 반환(앞뒤가 콤마므로 콤마만 제거하는 효과)
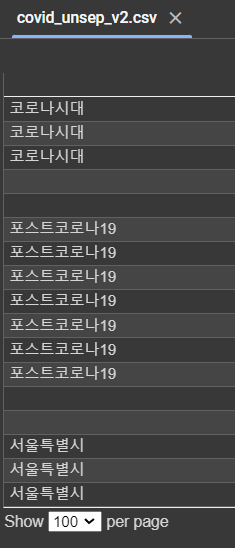
print(data)

#### csv파일로 출력(export)하기
cvs로 export하기
export to file
new_filename = f"{keyword}_unsep_v{version_new}.csv" # 최신버전의 파일이름 정하기
data.to_csv(new_filename, header = False, index = False, index_label = False, encoding="utf-8-sig") #csv파일을최신버전이름으로 생성
메세지 출력
print(f'{keyword}_v{version_new} created')
코딩이 생소한게 많아서 어려웠다.
하지만 원리는 정확이 이해했으므로 자주하다보면, 저절로 할 수 있다는 자신감이 들었다.
