CS231. Non-linear function (비선형
1. Neural Network (신경망)
저번 글에서 언급했듯이 인공 신경망은 선형함수와 비선형 함수로 층을 쌓고 있다.
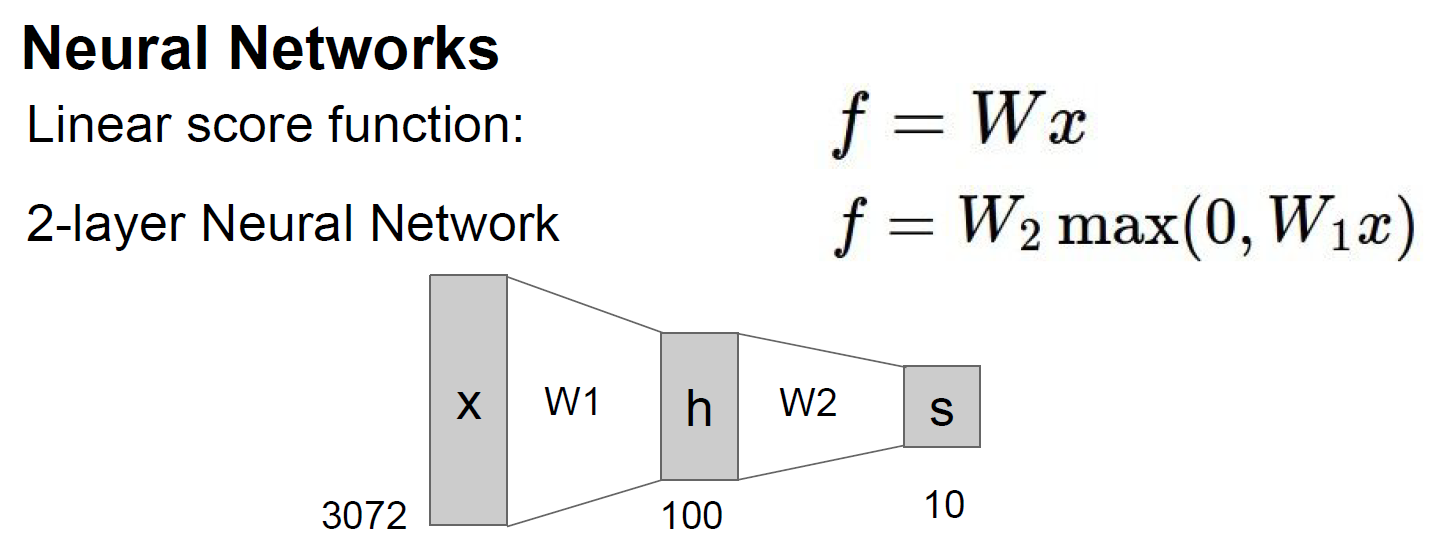
아래의 그림과 같이 입력 이미지가 선형함수(f1 = W1x)를 지나가고 비선형 함수 (f2 = max(0, f1))를 지난다. 마지막으로 선형(W2xf2)를 거쳐서 output 10개의 숫자를 나타낸다.
두가지 의문이 든다. 첫째, 왜 비선형 함수를 중간 중간 넣어줘야 하나? 둘째, 비선형 함수가 무엇인가? 이번 블로그에서 살펴보자.
2. 비선형 함수가 필요한 이유
신경망을 쌓을때 선형함수만 쌓으면 어떻게 될까? 3개를 다음과 같이 쌓아보자. x는 입력값이다.
f1 = W1*x + b1
f2 = W2*f1 + b2
f3 = W3*f2 + b3
f1과 f2를 f3에 대입해 보았다.
f3 = W3*(W2*(W1*x + b1) + b2) + b3
f3 = W3*((W2*W1*x + W2*b1) + b2) + b3
f3 = W3*W2*W1*x + W3*W2*b1 + W3*b2 + b3
W와 b는 결국은 상수이기 때문에 그냥 거대한 선형 함수처럼 보인다. 3개의 선형함수의 층은 아래와 같이 한개의 선형함수로 귀결된다.
f3 = W4*x + b4
(W4=W1*W2*W3, b4=(W3*W2*b1)+(W3*b2)+b3)
그러므로, 신경망에서는 선형함수 다음에는 꼭 비선형 함수를 넣어준다!
3. 비선형 함수
비선형 함수는 활성화 함수(activation function)에 들어간다. 비선형 함수에는 다음과 같은 함수들이 있다. 여기서 가장 자주 등장하는 Sigmoid, Tahn, ReLU, Leaky ReLU를 살펴보자.

일단 결론부터 말하자면 ReLU 함수가 신경망모델에서 가장 자주 사용된다. 때로 다른 함수들도 사용되기 때문에 한개씩 알아보도록 하자.
3.1 Sigmoid
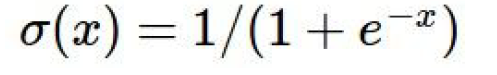
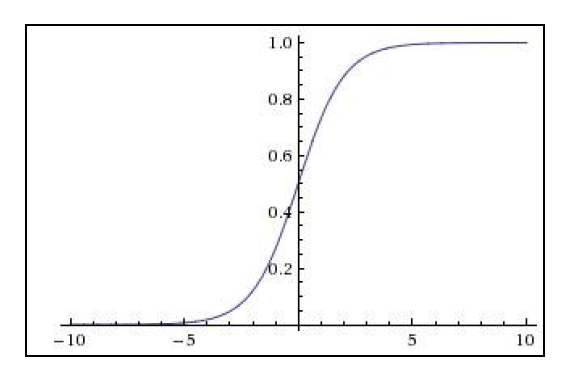
출력값: 0과 1 사이.
문제점
1. Saturated neurons "kill" the gradients
backpropogation(역전파)는 최적의 parameter(W)값을 찾는데 사용되는 기법으로 W의 미분값을 통해서 업데이트 된다. (역전파는 다음 블로그에서 자세히 다루겠다.)
예를들어, 신경망에 선형함수와 Sigmoid 함수가 쌓여있다고 가정해보자.
f(x) = sigmoid(W*x)
W의 미분값은 chain rule(체인룰)로 다음과 같이 구해진다.
1) 선형함수에 대한 미분값 * 2) sigmoid 함수의 미분값 * 3) loss에 대한 미분값
1)-3)중에서 하나라도 0이 있으면 전체 미분값은 0이 된다. 미분값은 함수의 기울기로 구할수 있다. 위의 sigmoid 함수에서 x좌표의 값이 -5보다 작거나 5보다 크면 기울기는 0이 된다. 따라서 이 부분에서의 미분값은 0이 되며 W의 전체 미분값을 0으로 만든다. 결국, W도 더이상 업데이트 할 수 없게 되고 모델의 학습은 중단된다.
- sigmoid outputs are not zero-centered
예를들어, f1 = sigmoid(W1*x), f2 = sigmoid(W2*f1) 같은 두개의layer로 된 모델이 있다가 해보자.
W2의 미분값:
1) W2의 선형함수에 대한 미분값 * 2) sigmoid 함수의 미분값 * 3) loss에 대한 미분값
1)은 f1. f1은 sigmoid함수를 거쳐서 나왔기 때문에 출력값이 항상 양수이다.
2) sigmoid 함수가 saturation 구간이 아닐때는 미분값은 항상 양수이다.
3) 결국 W2의 미분값은 3)에 의해서 양수가 될 수도 있고 음수가 될 수도 있다.
W1의 미분값:
1) W2의 미분값 * 2) W1의 선형함수에 대한 미분값 * 3) sigmoid 함수의 미분값
2) W1의 선형함수에 대한 미분값은 x이다. 여기서 입력값을 다 양수라고 가정한다.
3) sigmoid 함수가 saturation 구간이 아닐때는 미분값은 항상 양수이다.
그러므로, W1의 미분값은 W2의 미분값에 의해 결정된다. 즉, loss에 대한 미분값이 양수이면 W1과 W2둘다 양수, 미분값이 음수이면 W2, W2둘다 음수가 된다.
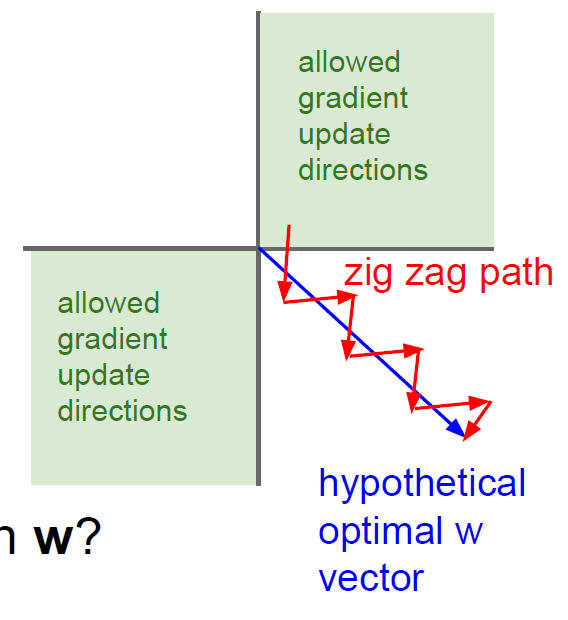
아래의 그림과 같이 최적의 W가 파란색 화살표 끝에 있다고 가정하고 W1, W2는 각 각 x축 y축이라고 해보자. 가장 빨리 최적점으로 가려면 파란 화살표 방향으로 가야 하지만 W1과 W2는 같은 방향(양수/양수 혹은 음수/음수)으로 밖에 이동하지 못하므로 지그재그로 움직이며 이는 W1,W2의 학습시간을 연장한다.
- expensive computation
sigmoid의 exp() 계산은 computing power가 많이 들기 때문에 모델을 돌리는데 오래 걸릴 수 있다.
3.2 Tahn
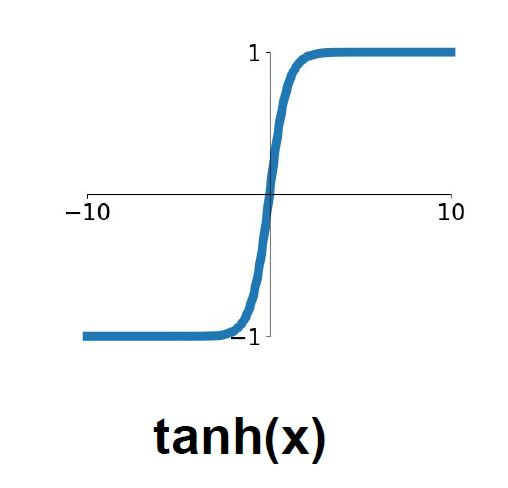
출력값: -1과 1 사이.
Sigmoid와 다르게 출력값이 음수도 존재한다.
문제점
Sigmoid함수의 가장 큰 문제점인 "Saturated neurons "kill" the gradients"이 역시 존재한다. 역전파 계산에 치명적이다.
Tahn 함수는 딥러닝 모델에서 자주 쓰이지 않기 때문에 간단하게 정리하고 넘어간다.
3.3 ReLU
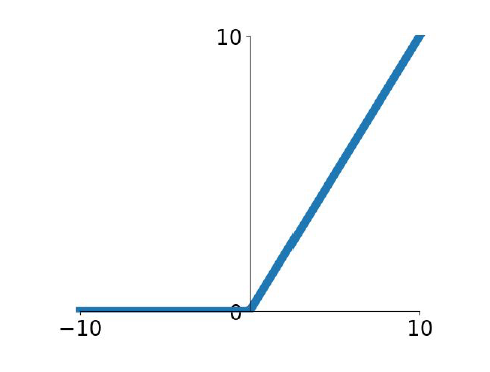
CNN등 딥러닝 모델에 자주 쓰이는 비선형함수이다.
출력값: 0과 무한대 양수
f(x) = max(0, x)
장점
1. 수식이 매우 간단하므로 계산이 빨라서 모델을 훈련시키는데 시간이 단축된다.
-
sigmoid/tahn 함수의 가장 큰 문제점인 neuron saturation(killed gradient) 문제점이 입력값이 0 이상일때 발생하지 않는다.
-
sigmoid와 tahn에 비해 실제 신경망의 작용과 비슷하다.
문제점
입력값이 음수일때는 미분값 0이므로 W의 업데이트를 진행할 수 없다.
3.4 Leaky ReLU
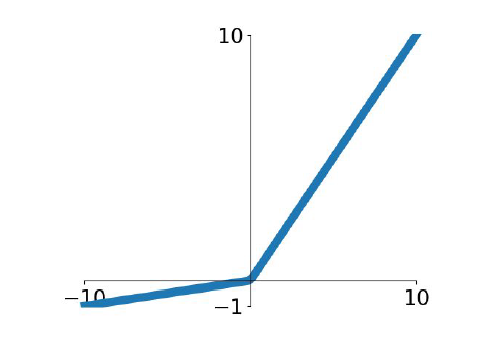
출력값: 무한대 음수 - 무한대 양수
f(x) = max(0.01x, x)
ReLU함수의 장점은 그대로 가지고 있고, neruon saturation 문제를 보완하기 위해 0대신 0.01x를 쓴다.
Brilliant!!
