
📚 Before starting off
시계열 모멘텀 투자 전략에 새로운 날개를 달아주자!
첫 포스트에서 시계열 모멘텀 전략에 관하여 다뤘던 것을 기억하는가? 시계열 모멘텀 전략은 과거 수익률의 추세를 기반으로 자산의 미래 방향성을 예측 및 투자하는 단순하지만, 강력한 투자 전략이었다.
시계열 모멘텀 전략은 다양한 하이퍼파라미터가 존재한다. 대표 하이퍼파라미터로 모멘텀 측정 기간과 리밸런싱 기간 등을 이야기할 수 있겠다. 또한, 하이퍼파라미터들의 조합에 따라 시계열 모멘텀 전략의 수익률과 위험은 큰 폭으로 변화하는 것을 확인할 수 있다. 이에 따라, 현 포스트는 CAGR(Compound Annual Growth Rate; 연평균수익률), 그리고 Sharpe Ratio(샤프 지수) - 총 두 가지 투자지표를 활용해 투자 전략 내 최적의 하이퍼파라미터 조합을 도출하고자 한다.
이 외에도, 본 포스트는 평균 시계열 모멘텀 전략에 대해 다루고자 한다. 평균 시계열 모멘텀 전략은 하나의 시계열 모멘텀 전략에 투자하는 대신, 하이퍼파라미터의 조합이 다른 다수의 시계열 모멘텀 전략에 분산 투자함으로써 위험을 낮추는 투자 전략이라고 할 수 있겠다.
정리하자면, 본 포스트에서는 CAGR과 Sharpe Ratio에 기반해 구현된 시계열 모멘텀 전략, 그리고 평균 시계열 모멘텀 전략까지 총 3가지의 투자 전략을 구현하고, 비교 및 분석하겠다.
⛔ 본 포스트는 Code Explanation을 기반으로 진행된다. 시계열 모멘텀 전략에 대한 개념 설명은 Time-series momentum(시계열 모멘텀) 포스트를 참고 바란다. 시계열 모멘텀 전략을 완벽히 이해한 다음, 본 포스트를 읽는 것을 추천한다.
📚 Code Explanation
상단의 과정을 Python 코드로 진행해보자.
⛔ [0. Libraries]부터 [2-1. Benchmark function]까지의 Python 코드는 Time-series momentum(시계열 모멘텀) 포스트의 Python 코드와 동일하다.
0. Libraries
# Essential Libraries
import pandas as pd
import numpy as np
from itertools import product
import matplotlib.pyplot as plt
from matplotlib import gridspec
import seaborn as sns
from tabulate import tabulate
# Optional Libraries
import dataframe_image as dfi
from tqdm import tqdm1. Data
데이터 특성 및 설명
| 특성 | 설명 |
|---|---|
| 위험자산 | KOSPI200지수 |
| 무위험자산 | CD1개월 금리 |
| 단위 | 1개월 단위 데이터 |
| 기간 | 1990/01/31 ~ 2021/11/30 |
| 출처 | FnGuide & DataGuide |
| 파일 형식 | Excel(rawdata.xlsx) |
데이터 구성 예시
| Date | KOSPI200 | CD1m |
|---|---|---|
| 1990-01-31 | 97.83 | 14.00 |
| 1990-02-28 | 94.06 | 14.00 |
| 1990-03-31 | 92.10 | 14.00 |
| 2021-09-30 | 401.30 | 0.98 |
| 2021-10-31 | 388.47 | 0.94 |
| 2021-11-30 | 373.24 | 1.16 |
# Extract excel data
data_excel = pd.ExcelFile('./rawdata.xlsx')
# Convert rawdata to dataframe
data_df = data_excel.parse(sheet_name='Sheet1', index_col='Date') # Excel to dataframe
rawTime = data_df.index.copy() # Time to dataframe
rawRisky = data_df.iloc[:,0].copy() # Risky asset to dataframe
rawRf = data_df.iloc[:,1].copy() # Risk-free asset to dataframe
# Return dataframe
rawR1 = rawRisky.pct_change() * 100 # Risky asset return dataframe (%)
rawR2 = rawRf.shift(1)/12 # Risk-free asset return dataframe (Chracteristic of interest)2. Time-series momentum function
시계열 모멘텀 전략을 Python 코드로 구현하기 전, 본 포스트에서 활용할 CAGR, 그리고 Sharpe Ratio의 계산 과정에 대해 간단히 살펴보자.
CAGR은 연평균수익률로, 이름 그대로 총 누적 수익률을 연 단위로 환산한 수익률을 의미한다. CAGR의 산식은 다음과 같다:
Sharpe Ratio는 위험조정수익률로, 위험자산에 투자하여 얻을 수 있는 초과수익을 의미한다. Sharpe Ratio의 산식은 다음과 같다:
⛔ Sharpe Ratio의 는 본 포스트에서 구현되지 않았다. 즉, 이라고 가정한다.
시계열 모멘텀 전략, 그리고 투자 전략의 CAGR과 Sharpe Ratio 계산을 Python 코드로 구현해보자:
# Hyperparameters
# lag2 = past period
# lag1 = past period (lag2 is closer to present period than lag1)
# data_time = date dataframe (Ex.rawTime)
# data_Risky = risky asset dataframe (Ex.rawRisky)
# return_Risky = risky asset return dataframe (Ex.rawR1)
# return_Rf = risk-free asset return dataframe (Ex.rawR2)
# stDtaeNum = Back-test starting date (Ex.'19941228')
# stMoney = Initial amount invested (Ex.100)
# Time-series momentum(TSM) function
def TSM(lag2, lag1, data_Time, data_Risky, return_Risky, return_Rf, stDateNum, stMoney):
# Momentum observation parameters
tau = lag1 - lag2
rawMom = data_Risky.shift(lag2).pct_change(tau) * 100 # Momentum return dataframe
rawSignal = 1 * (rawMom > 0) # Signal(weight) dataframe
# If the value in momentum return dataframe(rawMom) is >0, invest to risky asset (1)
# If the value in momentum return dataframe(rawMom) is <0, invest to risk-free asset (0)
# Back-testing
stDate = pd.to_datetime(str(stDateNum), format = '%Y%m%d') # Back-test starting date
# Slice dataframes to back-test starting date
Time = data_Time[data_Time >= stDate].copy()
R1 = return_Risky[data_Time >= stDate].copy()
R2 = return_Rf[data_Time >= stDate].copy()
Signal = rawSignal.iloc[data_Time >= stDate].copy()
numData = Time.shape[0] # Length of data used in back-testing
# Weight dataframe
W1 = Signal
W2 = 1 - W1
# Portfolio return & value series
Rp = pd.Series(np.zeros(numData)) # Return series
Vp = pd.Series(np.zeros(numData)) # Value series
Vp[0] = stMoney # Initial amount invested in TSM portfolio
for i in range(1, numData):
Rp[i] = W1[i-1] * R1[i] + W2[i-1] * R2[i] # Return calculation for TSM
Vp[i] = Vp[i-1] * (1 + Rp[i]/100) # Value calculation for TSM
# Drawdown
MAXp = Vp.cummax()
DDp = (Vp / MAXp - 1) * 100
# Essential calculation for performance observation
# CAGR calculation
CAGR = round(((Vp.iloc[-1] / Vp.iloc[0]) ** (1/12) - 1) * 100,2)
if lag1 <= lag2:
CAGR = 0
# Sharpe Ratio calculation (* Risk-free asset not considered)
Sharpe = round(np.mean(Rp) / np.std(Rp) * np.sqrt(12), 2)
if lag1 <= lag2:
Sharpe = 0
# Final datas to be extracted
return Time, Rp, Vp, DDp, CAGR, Sharpe2-1. Benchmark function
향후 성과 비교를 위해 벤치마크(Benchmark; BM)를 설정한다. 벤치마크는 위험자산으로 활용한 KOSPI200 지수를 사용했다.
# Hyperparameters
# data_time = date dataframe (Ex.rawTime)
# data_Risky = risky asset dataframe (Ex.rawRisky)
# stDtaeNum = Back-test starting date (Ex.'19941228')
# stMoney = Initial amount invested (Ex.100)
# Benchmark function
def BM(data_Time, data_Risky, stDate, stMoney):
# Slice dataframes to back-test starting date
BM = data_Risky[data_Time >= stDate].copy()
Rb = return_Rf[data_Time >= stDate].copy()
# Value
Vb = (BM / BM[0]) * stMoney
# Drawdown
MAXb = Vb.cummax()
DDb = (Vb / MAXb - 1) * 100
# Final datas to be extracted
return Vb, DDb3. Maximization of CAGR & Sharpe Ratio
앞서 이야기했듯, 본 포스트의 목표 중 하나는 CAGR과 Sharpe Ratio를 활용해 투자 전략 내 최적의 하이퍼파라미터 조합을 찾는 것이었다.
우선, 궁극적으로 도출해야 하는 결과에 대해 정의하자. CAGR과 Sharpe Ratio는 모두 수익률과 관련한 투자지표로, 다다익선(多多益善)이라고 할 수 있다. 이에 따라, 본 포스트에서는 시계열 모멘텀 전략의 CAGR과 Sharpe Ratio를 최대화할 수 있는 하이퍼파라미터들의 조합을 최적의 조합으로 고려하며, 이를 찾는 것에 목적을 둔다.
다음으로, 최적의 조합을 찾기 위해 사용할 하이퍼파라미터를 정의하자. 상단의 [2. Time-series momentum function]에서 활용된 하이퍼파라미터의 종류는 총 8가지이다. 이 중, 다른 하이퍼파라미터는 고정한 체, 모멘텀 측정 기간에 해당하는 하이퍼파라미터 과 에 변화를 줌으로써 투자 전략의 CAGR과 Sharpe Ratio를 최대화하겠다.
⛔ CAGR과 Sharpe Ratio 두 투자지표를 동시에 최대화하는 하이퍼파라미터 조합 1개를 찾는 것이 아니다. 각 투자지표를 최대화하는 하이퍼파라미터 조합 2개를 찾는 것이다.
예시를 통해 정리하겠다. 시계열 모멘텀 전략을 운용하고 싶어하는 투자자 A가 있다고 가정하자. 투자자 A는 모멘텀 측정 기간에 따라 시계열 모멘텀 전략의 수익률과 위험이 급격히 변화함을 알고 있다. 투자자 A는 백테스팅을 통해 모멘텀 측정 기간에 따른 각 투자 전략들의 CAGR과 Sharpe Ratio를 계산하기로 했고, 이 중 두 투자지표가 가장 큰 두 개의 시계열 모멘텀 전략에 투자하기로 했다. 투자자 A는 을 0~12개월, 를 1~12개월로 선정하였다. 이후, 총 156(12 x 13)가지의 과 하이퍼파라미터의 조합을 기반으로 각 시계열 모멘텀 전략들의 CAGR과 Sharpe Ratio를 계산, 그리고 최적의 조합을 찾기에 이르렀다. 이 예시가 곧 [3. Maximization of CAGR & Sharpe Ratio]와 동일하다고 할 수 있겠다.
과 에 변화를 주며, 시계열 모멘텀 전략의 CAGR과 Sharpe Ratio를 최대화하는 하이퍼파라미터 조합을 선정하는 함수를 Python 코드로 구현해보자:
# CAGR & Sharpe Ratio maximization function
def Maximization(select, lag2, lag1, data_Time, data_Risky, return_Risky, return_Rf, stDateNum, stMoney):
# Possible outcomes
# Since lag1 > lag2 , the starting point of the list is different
lag2_list = list(range(0, lag2 + 1))
lag1_list = list(range(1, lag1 + 1))
# Search possible outcomes by using itertools product function
items = [lag2_list, lag1_list]
items_possible = list(product(*items))
items_len = len(items_possible)
# Indicator dataframe
# Calculate every CAGR & Sharpe Ratio of TSM for every possible outcomes in lag1 & lag2 earned above
ind_df = pd.DataFrame()
for i in tqdm(range(items_len), position=0, leave=True):
if select == 'CAGR':
combination_df = pd.DataFrame([TSM(items_possible[i][0], items_possible[i][1], data_Time,
data_Risky, return_Risky, return_Rf, stDateNum, stMoney)[4]]) # [4] is CAGR
ind_df = pd.concat([ind_df, combination_df], axis=0)
elif select == 'Sharpe':
combination_df = pd.DataFrame([TSM(items_possible[i][0], items_possible[i][1], data_Time,
data_Risky, return_Risky, return_Rf, stDateNum, stMoney)[-1]]) # [-1] is Sharpe
ind_df = pd.concat([ind_df, combination_df], axis=0)
# Process for visualization
# Index & column names for ind_df calculated above
ind_name = []
for i in range(items_len):
ind_name.append('Lag2 & Lag1 at {}'.format(items_possible[i]))
ind_df.index = ind_name
if select == 'CAGR':
ind_df.columns = ['CAGR']
elif select == 'Sharpe':
ind_df.columns = ['Sharpe']
# Search which parameter combination maximizes CAGR & Sharpe Ratio
max_index = ind_df.idxmax()
max_data = list(ind_df.max())
if select == 'CAGR':
res_df = pd.DataFrame([max_data], columns = ['CAGR'], index = max_index)
elif select == 'Sharpe':
res_df = pd.DataFrame([max_data], columns = ['Sharpe'], index = max_index)
# Pivot table for visualization
pivot_df = pd.DataFrame(items_possible)
pivot_df.columns = ['Lag2', 'Lag1']
pivot_df = pd.concat([pivot_df, ind_df.reset_index(drop=True)], axis=1)
if select == 'CAGR':
pivot_df_total = pd.pivot_table(pivot_df, index = ['Lag2'],
columns = ['Lag1'], values = 'CAGR')
elif select == 'Sharpe':
pivot_df_total = pd.pivot_table(pivot_df, index = ['Lag2'],
columns = ['Lag1'], values = 'Sharpe')
# Styler for visualization
pivot_df_final = pivot_df_total.style.format('{:.2f}').\
bar(align='mid', color=['#FCC0CB', '#90EE90']).\
set_caption('Lag1 & Lag2 Table').\
set_properties(padding='5px', border='2px solid white', width='150px')
# Print which paramter combination maximizes CAGR & Sharpe Ratio
if select == 'CAGR':
print(f'Max CAGR:\n{res_df}\n')
elif select == 'Sharpe':
print(f'Max Sharpe:\n{res_df}\n')
# Final datas to be extracted
return ind_df, pivot_df_final4. Results
본 절에서는 상단의 Maximization 함수를 사용해 시계열 모멘텀 전략의 CAGR과 Sharpe Ratio를 최대화하는 과 하이퍼파라미터 조합을 찾는다. 더 나아가, 과 의 변화에 따른 투자 전략의 CAGR과 Sharpe Ratio를 기록한 pivot table을 도출하겠다.
Maximization 함수 구성 예시
| 파라미터 | 설명 |
|---|---|
| select | 'CAGR', 'Sharpe Ratio' |
| lag2 | 12 (0 ~ 12) |
| lag1 | 12 (1 ~ 12) |
| data_Time | rawTime |
| data_Risky | rawRisky |
| return_Risky | rawR1 |
| return_Rf | rawR2 |
| stDate | '19941228' |
| stMoney | 100 |
1. CAGR
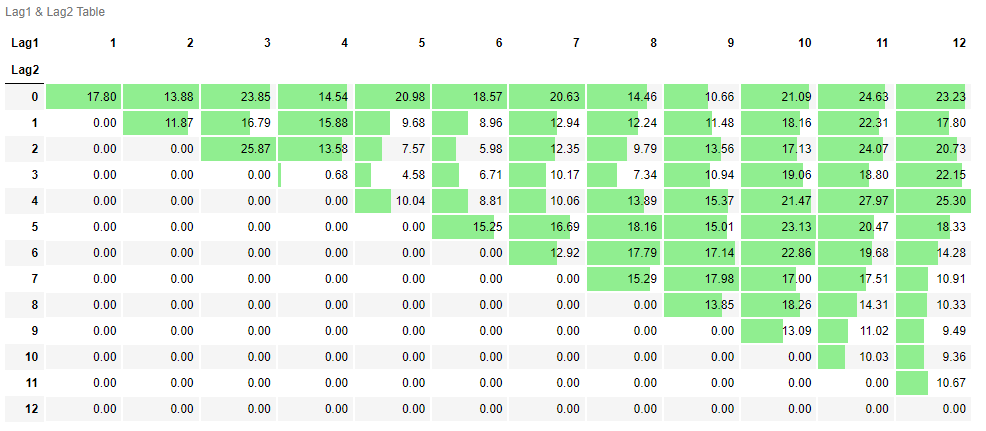
CAGR_df, pivot_df = Maximization('CAGR',12,12,rawTime,rawRisky,rawR1,rawR2,'19941228',100)- Max CAGR: 27.97% ( & at 4, 11)
# Calculate value & drawdown for TSM with maximized CAGR
Vp_cagr = TSM(4,11,rawTime,rawRisky,rawR1,rawR2,'19941228',100)[2]
DDp_cagr = TSM(4,11,rawTime,rawRisky,rawR1,rawR2,'19941228',100)[3]
# Print pivot table which contains CAGR for various lag1 & lag2
pivot_df- CAGR pivot table
⛔ : 은 에 비해 더 먼 과거 시점을 의미한다. 이에 따라, 의 경우, 0으로 대체 표기하였다.
2. Sharpe Ratio
Sharpe_df, Sharpe_pivot_df = Maximization('Sharpe',12,12,rawTime,rawRisky,rawR1,rawR2,'19941228',100)- Max Sharpe Ratio: 0.65 ( & at 2, 3)
# Calculate value & drawdown for TSM with maximized Sharpe Ratio
Vp_sharpe = TSM(2,3,rawTime,rawRisky,rawR1,rawR2,'19941228',100)[2]
DDp_sharpe = TSM(2,3,rawTime,rawRisky,rawR1,rawR2,'19941228',100)[3]
# Print pivot table which contains Sharpe Ratio for various lag1 & lag2
Sharpe_pivot_df- Sharpe Ratio pivot table
⛔ : 은 에 비해 더 먼 과거 시점을 의미한다. 이에 따라, 의 경우, 0으로 대체 표기하였다.
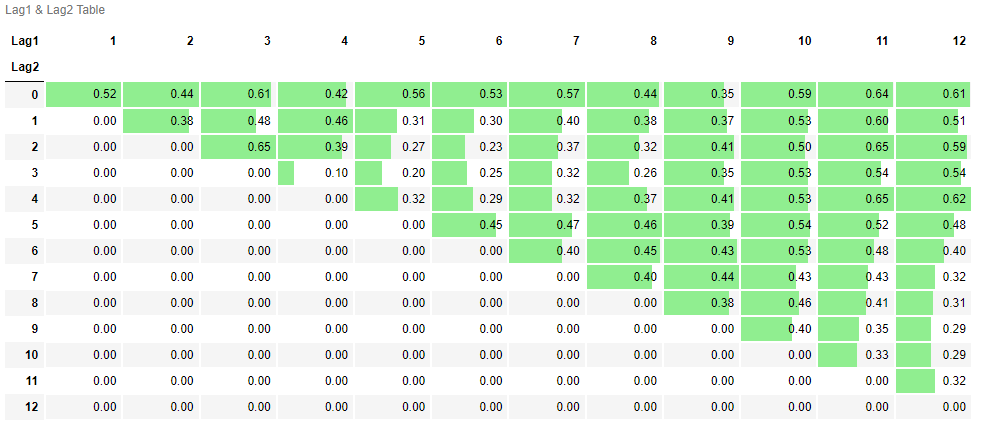
각 pivot table을 통해 과 가 ~로 설정된 모든 시계열 모멘텀 전략은 양의 CAGR과 Sharpe Ratio를 도출하는 것을 확인할 수 있다.
또한, 위의 pivot table처럼 전 구간 양의 값이 도출되는 경우, Maximization 함수를 통해 산출된 최적의 하이퍼파라미터 조합[ & at (4, 11), (2, 3)]은 과적합(overfitting)된 결과가 아니라고 이야기할 수 있겠다.
결국, 백테스팅 시 CAGR과 Sharpe Ratio가 가장 큰 시계열 모멘텀 전략에 투자하고 싶다면, 와 이 (4, 11) 또는 (2, 3)으로 설정된 시계열 모멘텀 전략에 투자하면 될 것이다.
5. Average time-series momentum
지금까지 시계열 모멘텀 전략의 과 를 변화하며 투자 전략의 CAGR과 Sharpe Ratio가 최대화되는 하이퍼파라미터의 조합을 도출했다. 다음으로, 평균 시계열 모멘텀 전략에 대해 살펴보고자 한다.
앞서 이야기했듯, 평균 시계열 모멘텀 전략은 하나의 시계열 모멘텀 전략에 투자하지 않고, 서로 다른 시계열 모멘텀 전략에 분산 투자하여 안정적인 수익을 창출하는 투자 전략이라고 할 수 있다. 지도교수님의 격언을 인용하자면, 평균 시계열 모멘텀 전략은 다음의 한 문장으로 표현될 수 있다:
후라이드 치킨을 먹을지, 또는 양념 치킨을 먹을지 고민된다면, 모두 포함된 반반 치킨을 시켜라!
간단한 예시와 함께 평균 시계열 모멘텀 전략을 이야기해보겠다. 시계열 모멘텀 전략을 운용하고 싶어하는 투자자 B의 상황을 고려해보자. 투자자 B는 수익률이 가장 높은 시계열 모멘텀 전략에 투자하기 위해 투자 전략의 하이퍼파라미터인 과 를 수시로 변경하며 3개월, 6개월, 9개월, 12개월, 그리고 12-1개월까지 총 5개의 시계열 모멘텀 전략 백테스팅을 진행했다. 이 과정 속, 투자자 B는 구간별로 우세한 시계열 모멘텀 전략이 존재함을 확인할 수 있었고, 고민에 빠졌다.
투자자 B의 고민을 더 자세히 들여다보겠다. 투자자 B가 진행한 시계열 모멘텀 전략들의 백테스팅 결과, 2010년부터 2015년까지는 (3개월) 시계열 모멘텀 전략이 우세했으나, 2015년부터 2020년까지는 (12-1개월) 시계열 모멘텀 전략이 우세하고, 3개월 시계열 모멘텀 전략은 오히려 손실이 발생하는 것을 확인할 수 있었다. 만일 투자자 B가 2010년부터 2015년의 결과를 기반으로 3개월 시계열 모멘텀 전략에 투자한다면, 이는 과연 미래 수익으로 이어질 수 있을까? 반대로, 2015년부터 2020년의 결과를 기반으로 12-1개월 시계열 모멘텀 전략에 투자한다면, 이를 올바른 투자 판단이라고 할 수 있을까? 이에 대한 확신을 갖고 싶다면, 당시의 시장과 현 시장 흐름의 유사성 등을 철저히 분석하고, 근거를 제시해야 할 것이다.
그러나, 투자자 B는 속전속결로 시계열 모멘텀 전략에 투자하고 싶었고, 결국 명쾌한 해답을 내놓기에 이른다. 3개월, 그리고 12-1개월 시계열 모멘텀 전략에 총자산의 50%씩 분산 투자함으로써 낮은 위험, 그리고 안정적인 수익을 일궈내기로 결정한 것이다. 비록 3개월 시계열 모멘텀 전략이 우세한 구간에서는 이에 100%를 투자한 인원에 비해 낮은 수익을 얻겠지만, 반대의 구간에서는 12-1개월 시계열 모멘텀에서 창출되는 수익으로 3개월 시계열 모멘텀 전략의 손실을 방어할 수 있을 것이다. 그리고, 이 투자 전략은 평균 시계열 모멘텀 전략으로 일컬어진다.
평균 시계열 모멘텀 전략을 그림으로 표현하면 다음과 같다:

1. Average time-series momentum function
상단의 과정을 Python 코드로 구현해보자.
⛔ 하단의 Python 코드는 는 사용자 설정 하에 고정된 체, 의 변화에 따라 각 별 TSM에 동일비중으로 분산 투자하는 방식으로 이루어져 있다.
⛔ 분산투자되는 TSM은 모두 상단의 TSM function과 동일히 진행된다.
# Hyperparmeters (Same as TSM function, with some exceptions)
# lag2_num = number of lag2 which will be fixed
# start_num = starting number of lag1; 1,2, ... (>1, >end_num)
# end_num = ending number of lag1; 1,2, ...
# Average time-series momentum function
def AVGTSM(lag2_num, start_num, end_num, data_Time, data_Risky, return_Risky, return_Rf, stDateNum, stMoney):
Rp_df = pd.DataFrame()
for i in range(start_num, end_num+1):
Rp_extract = pd.DataFrame(TSM(lag2_num,i,data_Time,data_Risky,
return_Risky,return_Rf,stDateNum,stMoney)[1]) # Only for TSM with Lag2 = num
Rp_extract.columns = [i]
Rp_df = pd.concat([Rp_df, Rp_extract], axis=1)
# Diversify funds for each TSM portfolio
divMoney = round(stMoney / (end_num - start_num + 1),2)
numData = len(Rp_df)
divVp = Rp_df.copy()
divVp[:] = 0
divVp.loc[0] = divMoney
for i in range(1,numData):
divVp.loc[i] = divVp.loc[i-1] * (1 + Rp_df.loc[i]/100)
Vp = divVp.sum(axis=1)
Rp_total = Vp.pct_change() * 100
MAXp = Vp.cummax()
DDp = (Vp / MAXp - 1) * 100
# Final datas to be extracted
return divVp, Vp, DDp, Rp_total2. Rolling return calculation
상단의 과정을 통해 평균 시계열 모멘텀 전략이 무엇인지 연구했고, 이를 Python 코드로 구현했다. 그렇다면, 평균 시계열 모멘텀 전략의 성과는 어떠한가? 이를 직관적으로, 그리고 쉽게 파악하기 위해 rolling return(이동평균수익률)을 하나의 방안으로 제시하고자 한다.
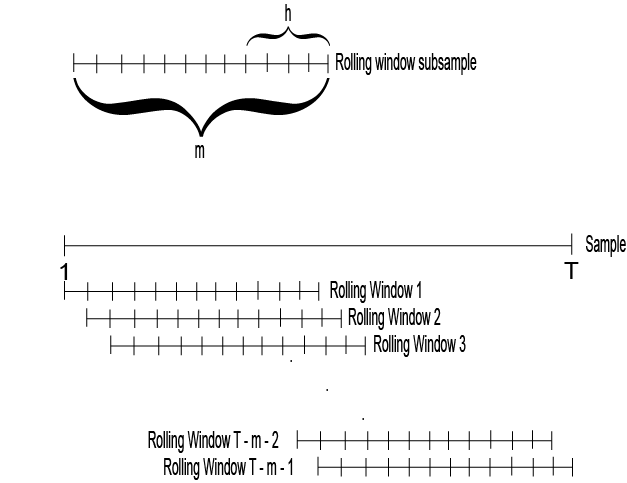
금융에 무지한 투자자 C를 가정하자. 투자자 C는 평균 시계열 모멘텀 전략의 낮은 위험 대비 안정적인 수익률에 이끌려 해당 투자 전략을 다루는 펀드에 투자하고자 한다. 그러나, 펀드 매니저가 설명하는 시계열 모멘텀 전략의 개념이 도통 이해되지 않았고, 애써 노력하여 이해하고 싶지도 않았다. 운용보고서에 적힌 다양한 투자지표 또한 투자자 C에게는 그저 영문모를 숫자들일 뿐이었다. 그가 이해할 수 있고, 또 궁금했던 것은 단 하나 - N일 투자할 경우, 평균수익률은 어떻게 되는지였다.
Rolling return은 위 궁금증을 해결하기에 용이하다. 일례로, N-day rolling return을 계산해보자. 이 경우, 상단의 그림처럼 초기 백테스팅 시점부터 N일간의 rolling window를 설정한 후, 이에 따른 평균 수익률을 한 단위씩 옮겨가며 계산하여 N-day rolling return을 도출할 수 있다. 이를 통해 투자자들은 N일간 투자 시 전략에서 도출될 수익률들의 분포(수익률 Histogram 등)를 직관적으로 확인할 수 있다.
Rolling return을 Python 코드를 통해 구현해보자:
# Hyperparamters
# Time = date dataframe (Ex. Time)
# Value = value dataframe(EX. Vp)
# shift_num = period for rolling return to be calculated (Ex. 12, 24, ...)
# Rolling return function
def RollingR(Time, Value, shift_num):
# For annualization
InvHor = shift_num / 12
# Rolling return calculation
rolling_return = (Value / Value.shift(shift_num))
rolling_return.index = Time
# Max rolling return
rolling_return_max = round((rolling_return.max()**(1/InvHor)-1)*100,2) # %
rolling_return_idxmax = rolling_return.idxmax()
rolling_return_max = ['{}% : {}'.format(rolling_return_max, pd.Timestamp.date(rolling_return_idxmax))]
# Min rolling return
num = rolling_return.min()**(1/InvHor)
rolling_return_min = round((rolling_return.min()**(1/InvHor)-1)*100,2) # %
rolling_return_idxmin = rolling_return.idxmin()
rolling_return_min = ['{}% : {}'.format(rolling_return_min, pd.Timestamp.date(rolling_return_idxmin))]
#Mean rolling return
rolling_return_mean = round((np.mean(rolling_return)**(1/InvHor)-1)*100,2) # %
# Print using tabulate
print(tabulate([['Investment Horizon', 'MAX (Annualized)', 'MIN (Annualized)', 'MEAN (Annualized)'],
[InvHor, rolling_return_max, rolling_return_min,
'{}%'.format(round(rolling_return_mean,2))]], headers = 'firstrow'))
# Final datas to be extracted
return rolling_return상단의 Rolling return 함수를 기반으로 평균 시계열 모멘텀 전략의 성과평가를 진행하겠다. 본 성과평가에서 활용된 투자 전략은 , 그리고 ~ 로 총 12개의 시계열 모멘텀 전략에 동일비중으로 분산 투자한 평균 시계열 모멘텀 전략이다. 이는 다음의 표로 정리될 수 있겠다:
Average time-series momentum 함수 구성 예시
| 파라미터 | 설명 |
|---|---|
| lag2_num | 0 |
| start_num | 1 |
| end_num | 12 |
| data_Time | rawTime |
| data_Risky | rawRisky |
| return_Risky | rawR1 |
| return_Rf | rawR2 |
| stDate | '19941228' |
| stMoney | 100 |
# Average time-series function
divVp, avgVp, avgDDp, avgRp = AVGTSM(0, 1,12,rawTime,rawRisky,rawR1,rawR2,'19941228',100)
# ===================================================
# Rolling return calculation
print('\n\nIndicators table: \n\n')
print('TSM rolling return with different investment horizon\n')
for i in range(12,121,12):
RollingR(Time, avgVp, i)
print('\n')결과는 다음과 같이 도출된다:

3. Benchmark comparison
상단의 rolling return 외에도 투자자에게 직관적으로 결과를 제시하는 방안은 다양히 존재한다. 투자 전략과 BM을 비교하는 것 또한 상대적인 성과를 보여주는 방안 중 하나이다. 본 절에서는 평균 시계열 모멘텀 전략과 BM의 수익률의 최대값, 최소값, 그리고 평균값을 비교하고, 히스토그램으로 시각화하고자 한다.
위의 과정을 Python 코드로 구현해보자:
# BM Function (Refer to [2-1.Benchmark function])
Rb, Vb, DDb = BM(rawTime, rawRisky, '19941228', 100)
# ===================================================
# Hyperparameters
# Strategy = strategy name (You name it!)
# Time = date dataframe (Ex. Time)
# Return = return dataframe (Ex. Rp)
# Indicators for Average time-series momentum vs. BM
def Indicators(Strategy, Time, Return):
Return.index = Time
# Max return calculation
return_max = round(Return.max(),2)
return_idxmax = Return.idxmax()
return_max_list = ['{}% : {}'.format(return_max, pd.Timestamp.date(return_idxmax))]
# Min return calculation
return_min = round(Return.min(),2)
return_idxmin = Return.idxmin()
return_min_list = ['{}% : {}'.format(return_min, pd.Timestamp.date(return_idxmin))]
#Mean return calculation
return_mean = np.mean(Return)
# Print using tabulate
print(tabulate([['Strategy', 'MAX', 'MIN', 'MEAN'],
[Strategy, return_max_list, return_min_list,
'{}%'.format(round(return_mean,2))]], headers = 'firstrow'))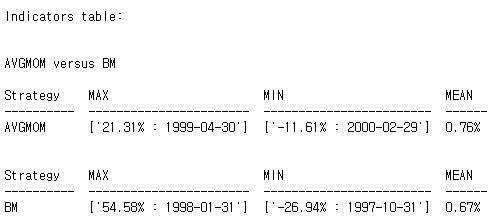
# Return histogram for Average time-series moemntum vs. BM
fig = plt.figure(figsize=(10,5))
sns.distplot(avgRp, color='blue',label='AVGMOM')
sns.distplot(Rb, color='red',label='BM')
plt.xlabel('Return (%)')
plt.title('<Return Histogram: AVGMOM vs BM>')
plt.legend()
plt.show()
print('\n\nIndicators table: \n\n')
print('AVGMOM versus BM\n')
Indicators('AVGMOM', Time, avgRp)
print('\n')
Indicators('BM', Time, Rb)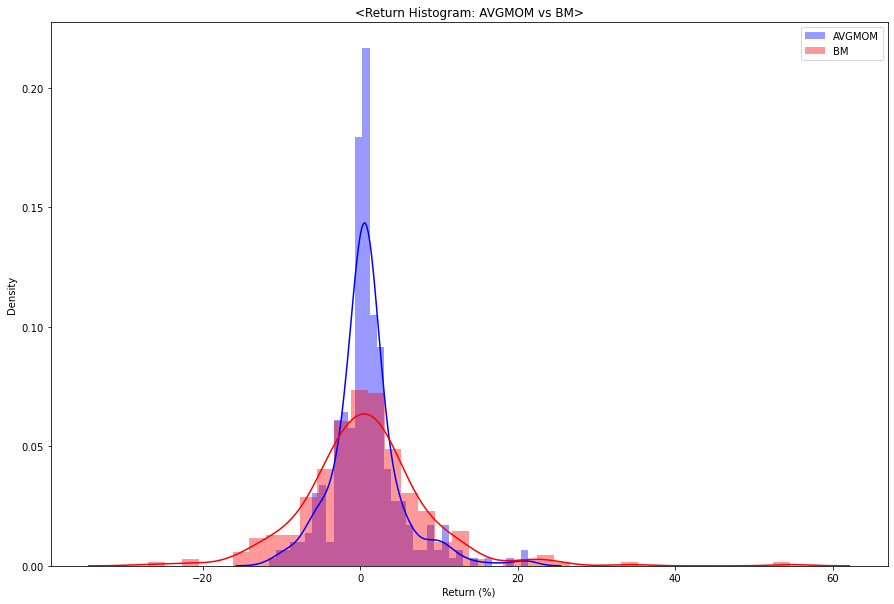
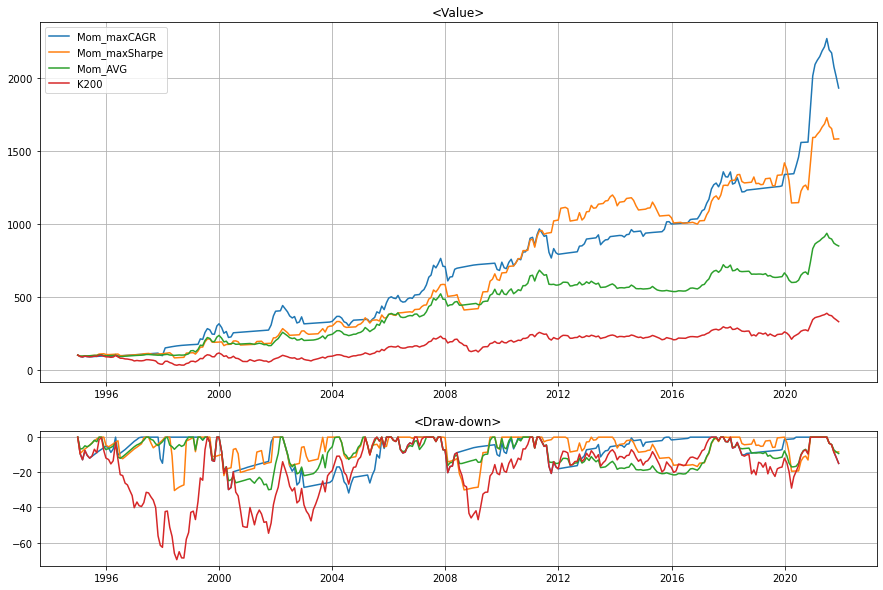
6. Graphs
지금까지 과 를 변화하며 CAGR과 Sharpe Ratio가 가장 큰 시계열 모멘텀 전략을 구현했다. 또한, 평균 시계열 모멘텀 전략을 구현하고, 이에 따른 성과 평가를 진행했다. 마지막으로, 상단의 함수들을 활용하여 총 4개의 투자 전략을 그래프로 비교하겠다. 사용된 투자 전략들은 다음과 같다:
투자 전략 구성
| 투자 전략 이름 | 설명 |
|---|---|
| Mom_maxCAGR | 백테스팅 시 CAGR이 가장 큰 시계열 모멘텀 전략 () |
| Mom_maxSharpe | 백테스팅 시 Sharpe Ratio가 가장 큰 시계열 모멘텀 전략 () |
| Mom_AVG | 평균 시계열 모멘텀 전략 ( 고정, ~) |
| K200 | BM |
Graph는 다음과 같이 도출된다:
📚 마치며
이상으로 평균 시계열 모멘텀 전략 포스트를 마치겠다.
향후 포스트에서는 횡단면 모멘텀 전략(Cross-sectional momentum), 그리고 듀얼 모멘텀 전략(Dual momentum)에 대해 다뤄보겠다.
출처:
Thumbnail Arrow: Average icons created by Freepik - Flaticon
[2. Rolling return calculation]에서 활용된 사진 자료는 다음의 출처에서 제공되었습니다:
본 포스트는 숭실대학교 금융학부 데이터 기반 투자전략 수업자료를 활용하여 제작되었습니다.
학부생으로서 직접 배운 것을 바탕으로 작성된 포스트로, 오류가 존재할 수 있습니다.
읽어주셔서 감사합니다 🥰
