0. Intro
EDA는 Machine Learning에서 중요한 단계임이 분명하다.
예를 들어, 어떠한 CSV 파일을 회귀 분석을 진행하고자 한다면,
각 변수 별 Correlation이 중요할 때가 분명 존재한다.
(Correlation을 고려하지 않고 분석을 진행한다면, 그 분석은 하나마나한 결과를 보이기 때문이다.)
그리고, 각 Columns, 즉 독립 변수가 몇 개가 존재하는지, 각 독립 변수가 연속형 자료인지 이산형 자료인지, 범주형 자료인지도 중요하고, histogram을 파악하는 것 역시 중요하다.
이렇게 EDA는 데이터 사이언티스트에게 있어서 굉장히 중요한 스텝 중 하나인데,
Pandas Profiling(Github)은 EDA를 한 번에, 단 코드 몇 줄로 어느정도는 해소할 수 있는 python package이다.
1. Installation
pandas profiling은 python package이기 때문에, 손쉽게 설치가 가능하다.
pip install pandas_profiling💡 단, 위의 코드를 실행하기 전에 package 의존성 문제로 인해
2개의 패키지를 pandas profiling 설치 이전에 install 하는 것을 추천한다.
pip install ruamel-yaml
pip install markupsafe==2.0.1이렇게 하면 pandas profiling 패키지 설치가 잘 될 것이다.
2. How-to-use Pandas Profiling?
사용법 역시 쉽다.
jupyter notebook으로 실습해보도록 하자.
(base) bolero is in now ~/dc/ml/Regression $ ls
00_pandas_profiling_test.zip linear_test.py pandas_profiling_test.ipynb pr_report.html
BostonHousing_noNaN_forRegressor.csv ols_test.py pandas_profiling_test.py pr_report.json
(base) bolero is in now ~/dc/ml/Regression $ jupyter notebook
[I 2022-07-08 13:53:38.042 LabApp] JupyterLab extension loaded from /Users/bolero/opt/anaconda3/lib/python3.9/site-packages/jupyterlab
[I 2022-07-08 13:53:38.042 LabApp] JupyterLab application directory is /Users/bolero/opt/anaconda3/share/jupyter/lab
[I 13:53:38.046 NotebookApp] Serving notebooks from local directory: /Users/bolero/dc/ml/Regression
[I 13:53:38.046 NotebookApp] Jupyter Notebook 6.4.8 is running at:
[I 13:53:38.046 NotebookApp] http://localhost:8888/?token=f93f2c0131c92ded124ded86a54d7956b767931f601ffd5c
[I 13:53:38.046 NotebookApp] or http://127.0.0.1:8888/?token=f93f2c0131c92ded124ded86a54d7956b767931f601ffd5c
[I 13:53:38.046 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 13:53:38.054 NotebookApp]
To access the notebook, open this file in a browser:
file:///Users/bolero/Library/Jupyter/runtime/nbserver-1396-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=f93f2c0131c92ded124ded86a54d7956b767931f601ffd5c
or http://127.0.0.1:8888/?token=f93f2c0131c92ded124ded86a54d7956b767931f601ffd5c
[W 13:53:39.612 NotebookApp] 404 GET /apple-touch-icon-precomposed.png (::1) 5.920000ms referer=None
[W 13:53:39.617 NotebookApp] 404 GET /apple-touch-icon.png (::1) 1.050000ms referer=Noneterminal에 jupyter notebook을 입력하면, 현재 로컬 머신의 python interpreter를 사용하는 주피터 노트북을 켤 수 있다.
(명령어가 인식이 안되는 경우는 jupyter notebook이 설치되지 않은 경우이다.
pip install jupyter jupyter notebook로 주피터 노트북을 설치하다.)
이런 화면이 보이는데, 여기서 ipynb 노트북 파일을 생성하거나, 기존의 노트북 파일을 열어보자.

ls command로 현재 디렉토리의 파일을 살펴보니, BostonHousing_noNaN_forRegressor.csv 파일이 있다.
해당 파일을 pandas 로 열어보자.
- 코드 : CSV 파일 읽기
import pandas as pd
data = pd.read_csv('BostonHousing_noNaN_forRegressor.csv')
print(data)- 결과
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222
4 0.02985 0.0 2.18 0 0.458 6.430 58.7 6.0622 3 222
.. ... ... ... ... ... ... ... ... ... ...
389 0.17783 0.0 9.69 0 0.585 5.569 73.5 2.3999 6 391
390 0.22438 0.0 9.69 0 0.585 6.027 79.7 2.4982 6 391
391 0.04527 0.0 11.93 0 0.573 6.120 76.7 2.2875 1 273
392 0.06076 0.0 11.93 0 0.573 6.976 91.0 2.1675 1 273
393 0.10959 0.0 11.93 0 0.573 6.794 89.3 2.3889 1 273
PTRATIO B LSTAT MEDV
0 15.3 396.90 4.98 24.0
1 17.8 396.90 9.14 21.6
2 17.8 392.83 4.03 34.7
3 18.7 394.63 2.94 33.4
4 18.7 394.12 5.21 28.7
.. ... ... ... ...
389 19.2 395.77 15.10 17.5
390 19.2 396.90 14.33 16.8
391 21.0 396.90 9.08 20.6
392 21.0 396.90 5.64 23.9
393 21.0 393.45 6.48 22.0
[394 rows x 14 columns]CSV 파일이 잘 읽힌다!
이제 Pandas profiling package를 사용해보자.
- 코드 : pandas profiling package를 사용해서, report를 html로 만들기
import pandas_profiling
pr = data.profile_report() # 프로파일링 결과 리포트를 pr에 저장
pr.to_file('./pr_report.html') # pr_report.html 파일로 저장
print(pr)- 결과
Summarize dataset: 100%
196/196 [00:08<00:00, 23.64it/s, Completed]
Generate report structure: 100%
1/1 [00:01<00:00, 1.63s/it]
Render HTML: 100%
1/1 [00:01<00:00, 1.72s/it]
Export report to file: 100%
1/1 [00:00<00:00, 60.83it/s]
html이 잘 만들어 진 것 같다.
html 파일을 살펴보자.
(위의 html 파일을 더블클릭하면, 새 브라우저가 열린다.)
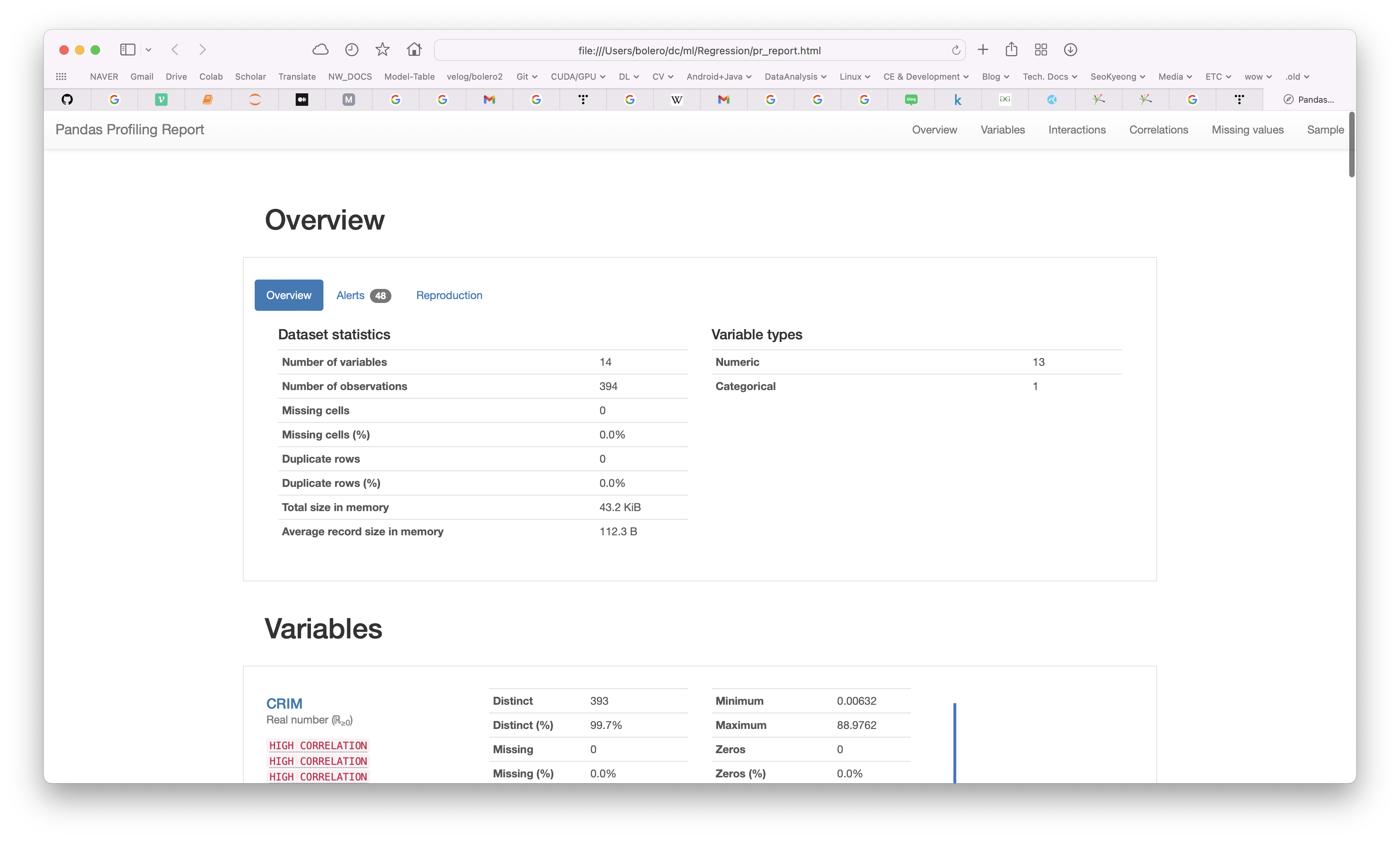
그러면 위처럼, Overview 부터 해서 Variables, Interactions, Correlations, Missing values, Sample 등을 살펴볼 수 있다.
3. Pandas Profiling Report 살펴보기
위에서 언급한 6개 종류에 대해서 어떤 것들이 있는지 알아보자.
3-1. Overview
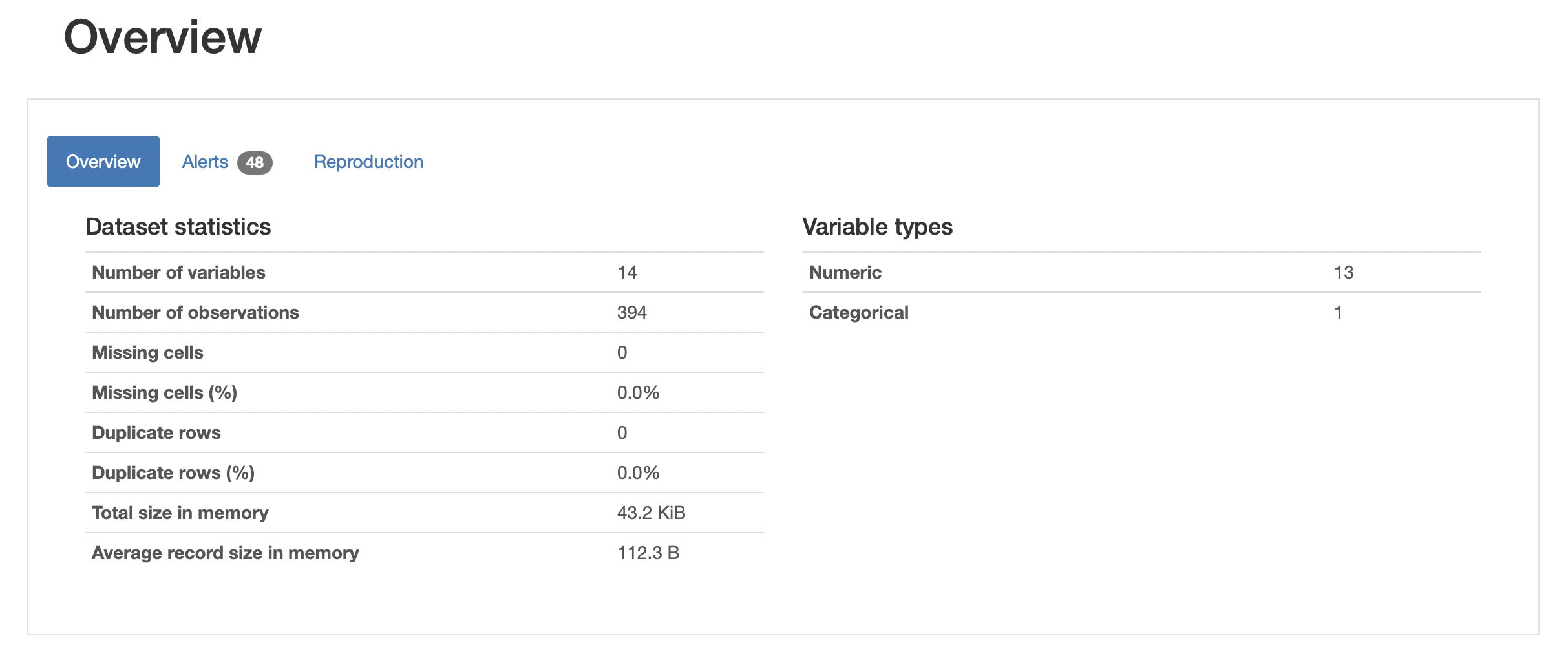
데이터셋의 개요에 해당되는 부분이다.
1) Dataset statistics
| 이름 | 의미 |
|---|---|
| Number of variables | 독립 변수의 개수 (= Columns 개수) |
| Number of observations | 행의 수 (= 관측 가능한 값의 수) |
| Missing cells(%) | 결측치 cell의 개수와 비율 |
| Duplicate rows(%) | 중복되는 행의 개수와 비율(%) |
2) Variable Types
| 이름 | 의미 |
|---|---|
| Numeric | 수치형 자료 |
| Categorical | 범주형 자료 |
그리고 Reproduction 쪽에는 pandas-profiling의 버전과
해당 profile의 생성 시간과 생성에 소요된 시간 등이 적혀있다.
3-2. Variables
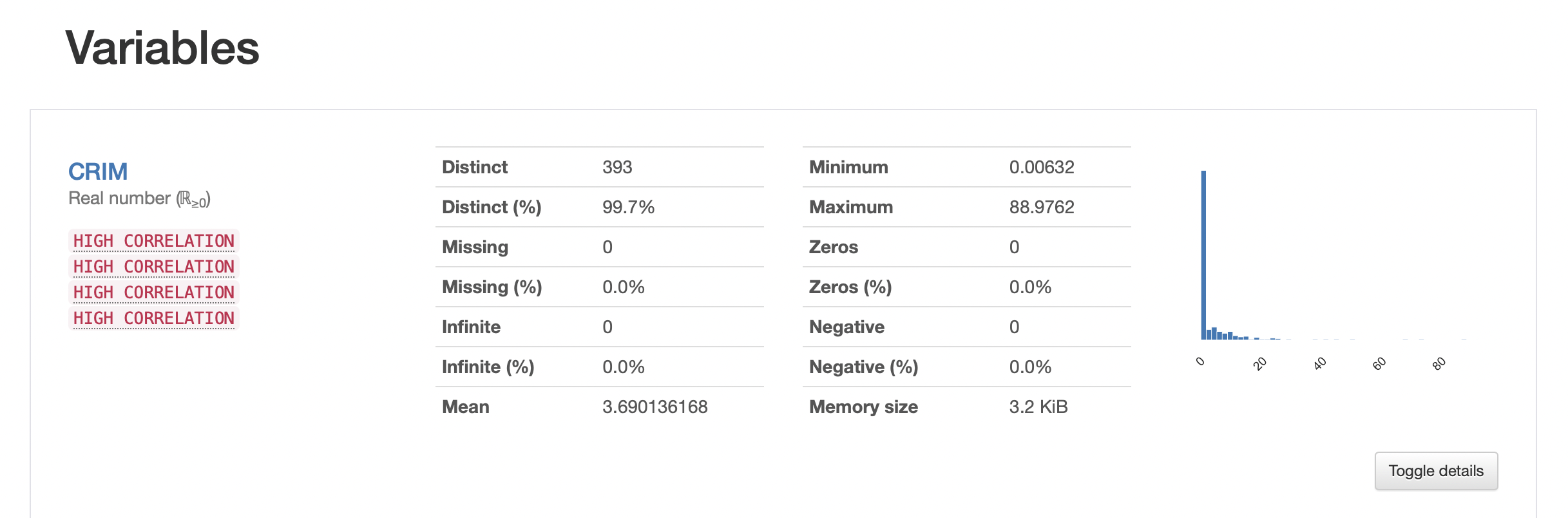
💡 실제 독립 변수에 대한 정보가 나와있다.
왼쪽에 HIGH CORRELATION은 어떤 변수와 상관 정도가 높은지에 대해서 나와있고, 오른쪽에는 Mean, Max, Min, Zero 값의 개수와 비율, 결측치의 개수와 비율 등이 나와있다.
그리고 오른쪽 하단에 Toggle details 를 클릭하면
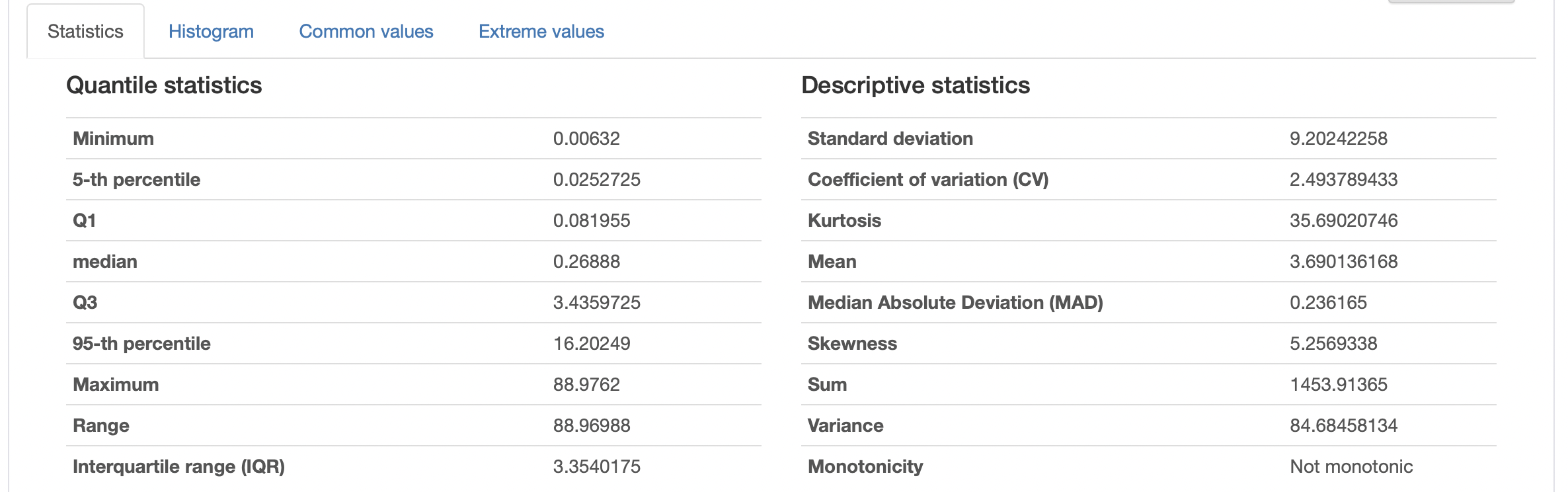
다음과 같은 정보를 볼 수 있다.
일반적인 Mean, Max, Min 뿐만 아니라,
| 이름 | 의미 |
|---|---|
| median | 중앙값 |
| Q1, Q3 | 제 1 사분위수, 제 3 사분위수 |
| IQR | 사분범위 |
| Sum | 총 합 |
| Variance | 분산 |
| CV(Coefficient of variation |
등이 있다.
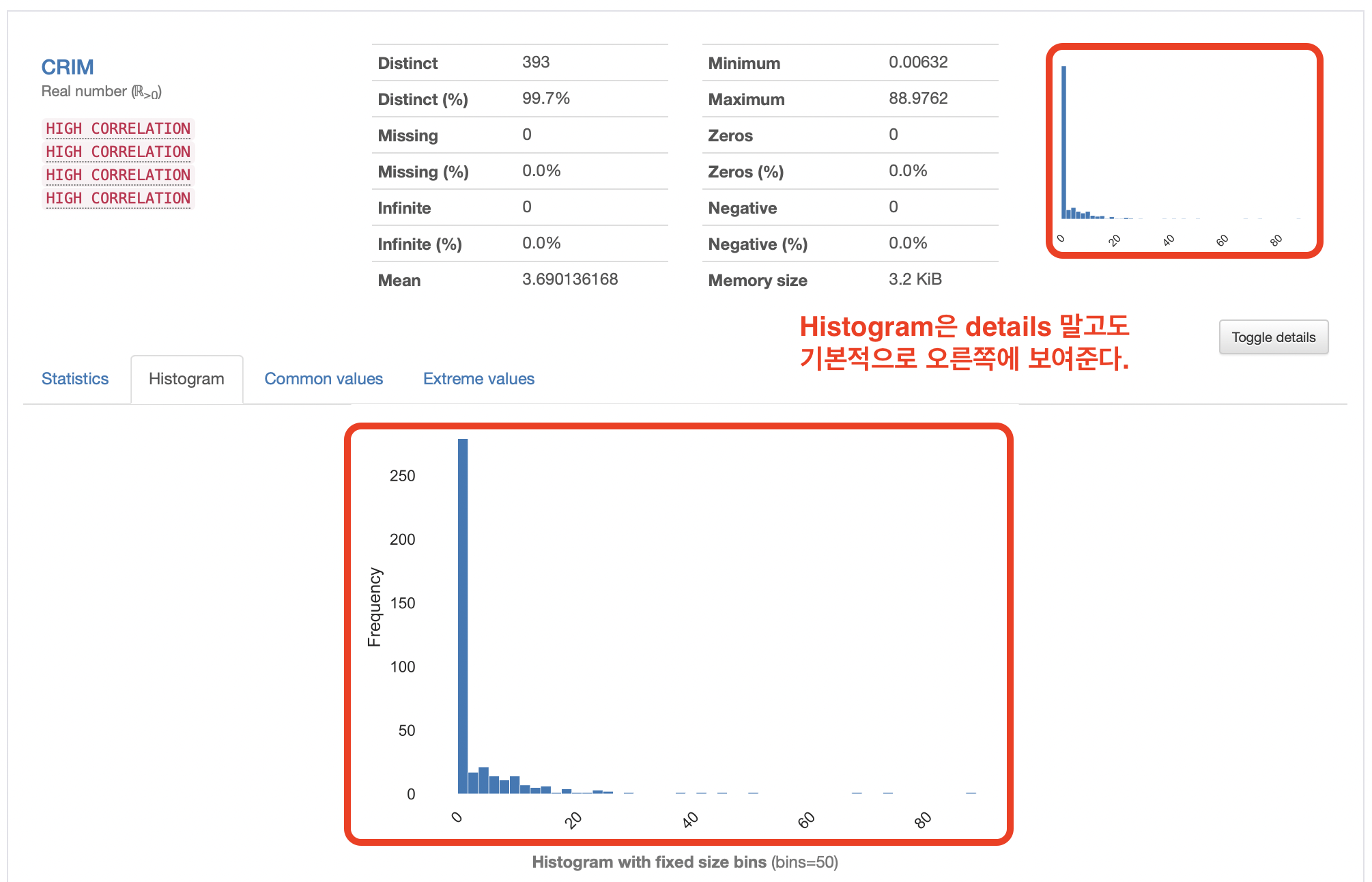
CRIM(=범죄율) 변수는 범주형 자료(Categorical)가 아니고 일반적인 수치 자료이기 때문에,
통계학적인 것들(Statistics), 히스토그램(Histogram, 값의 빈도), 공통 값들(Common values), 최소값과 최대값(Extreme values) 등이 나와있다.
3-3. Interactions
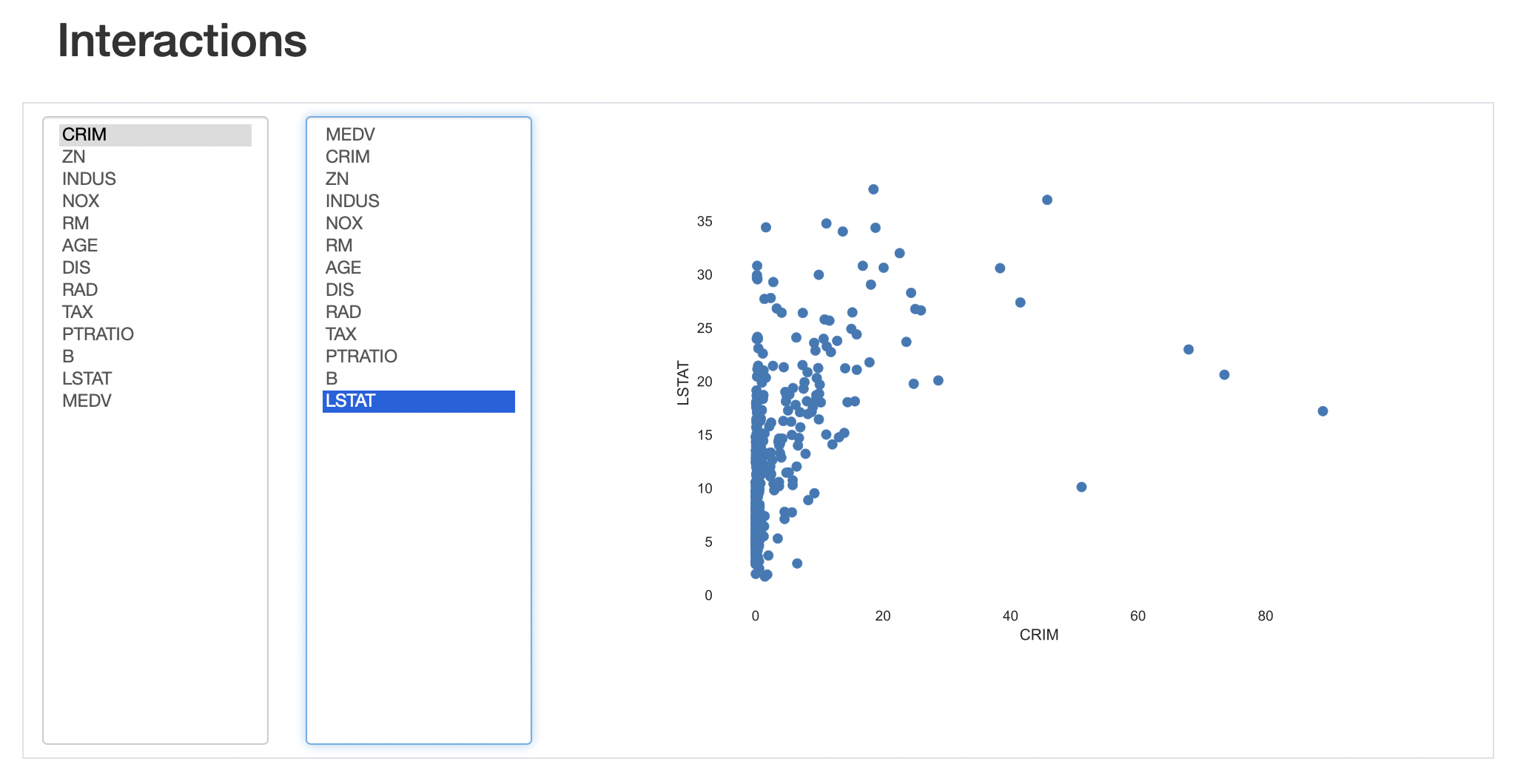
💡 scatter plot을 보여준다.
왼쪽이 X-axis, 오른쪽이 Y-axis에 해당된다.
색상은 blue로 되어있는데, 이건 pandas profiling 코드를 보면 아마 수정이 가능할 것이다...?
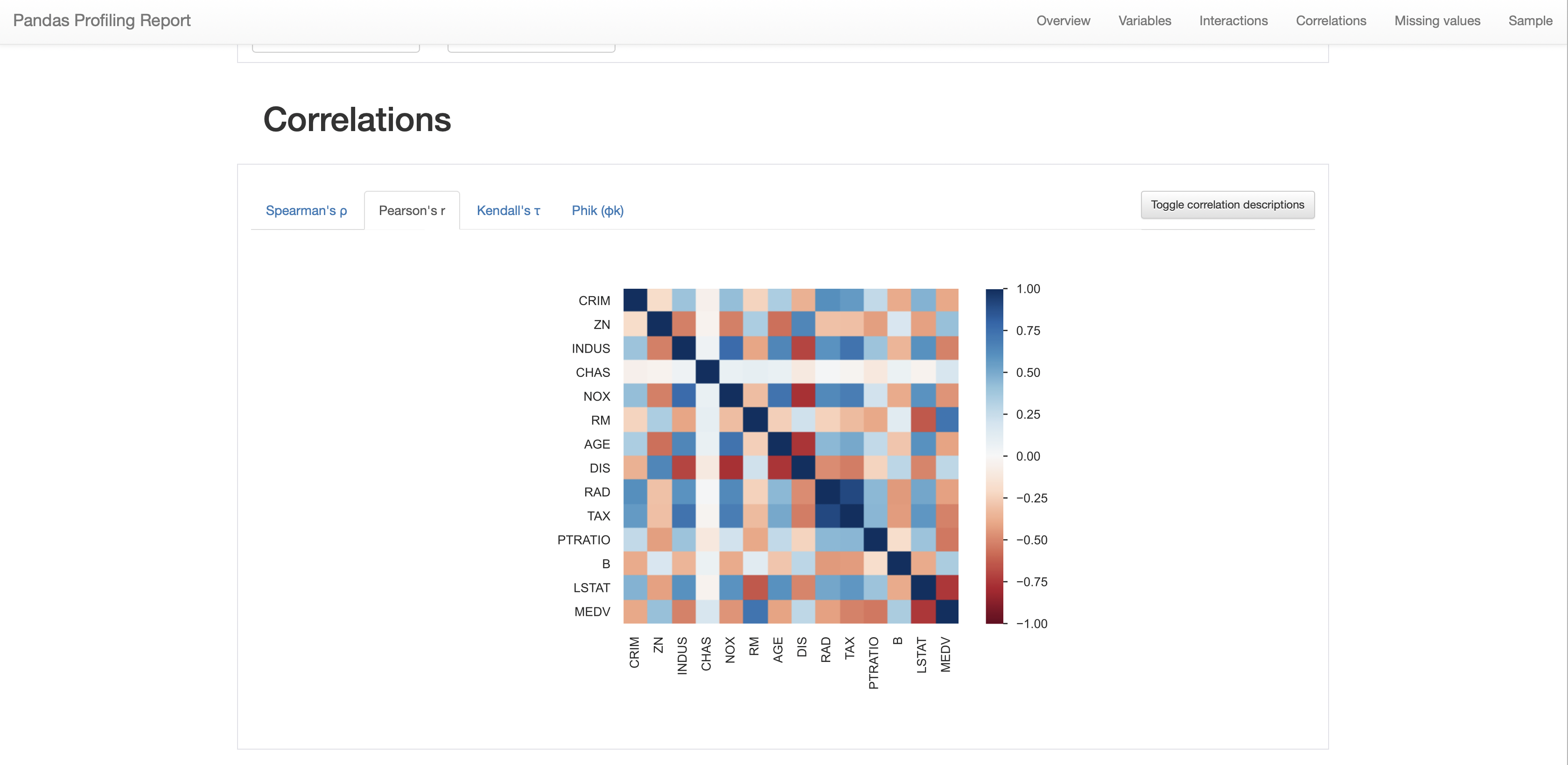
3-4. Correlations
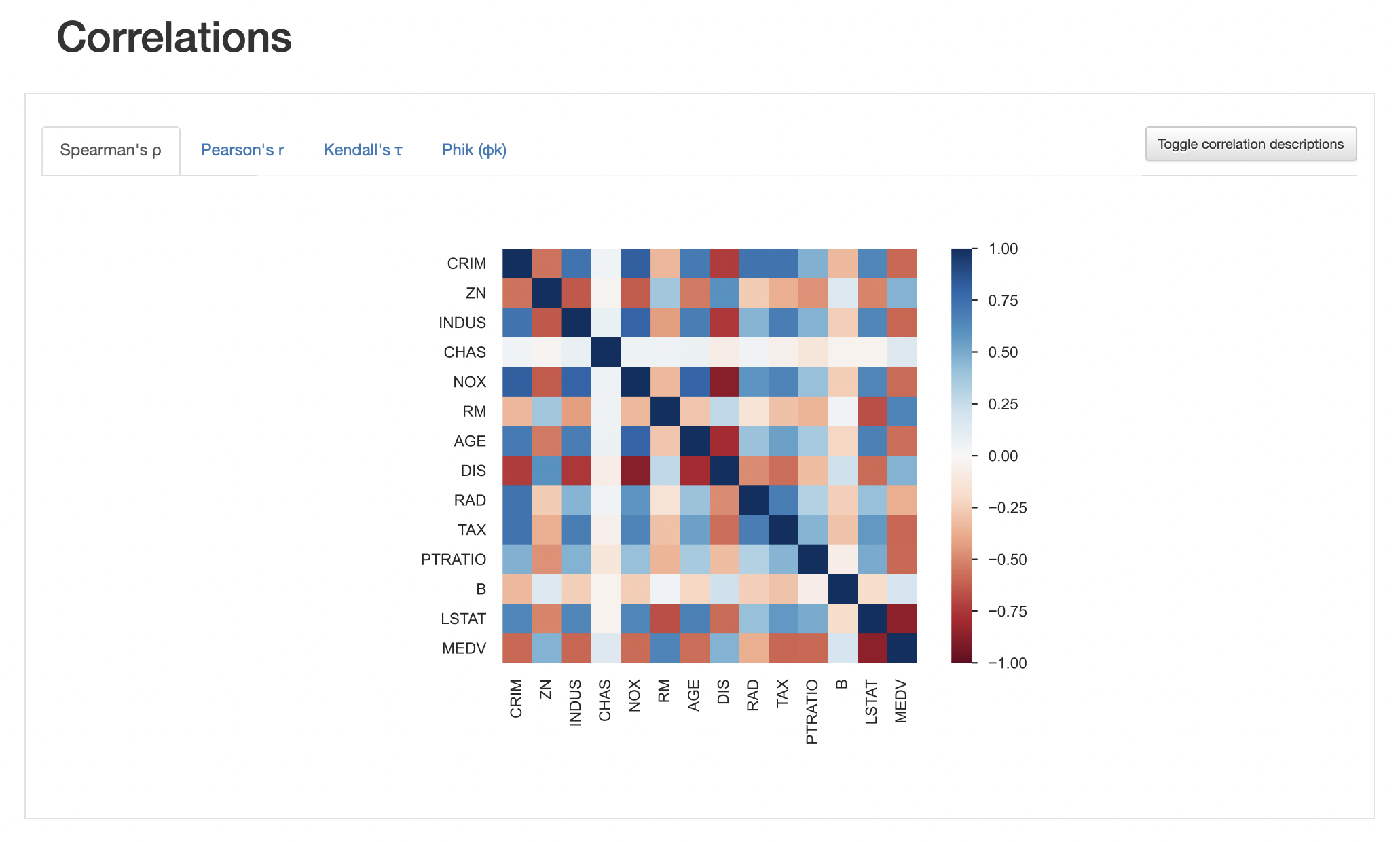
💡 변수 별 상관계수를 보여준다.
총 4개의 종류가 있다.
- Spearman
- Pearson
- Kendall
- Phik
우측 상단에 Toggle correlation descriptions를 누르면, 각각의 종류에 대한 간략한 설명이 나와있다.
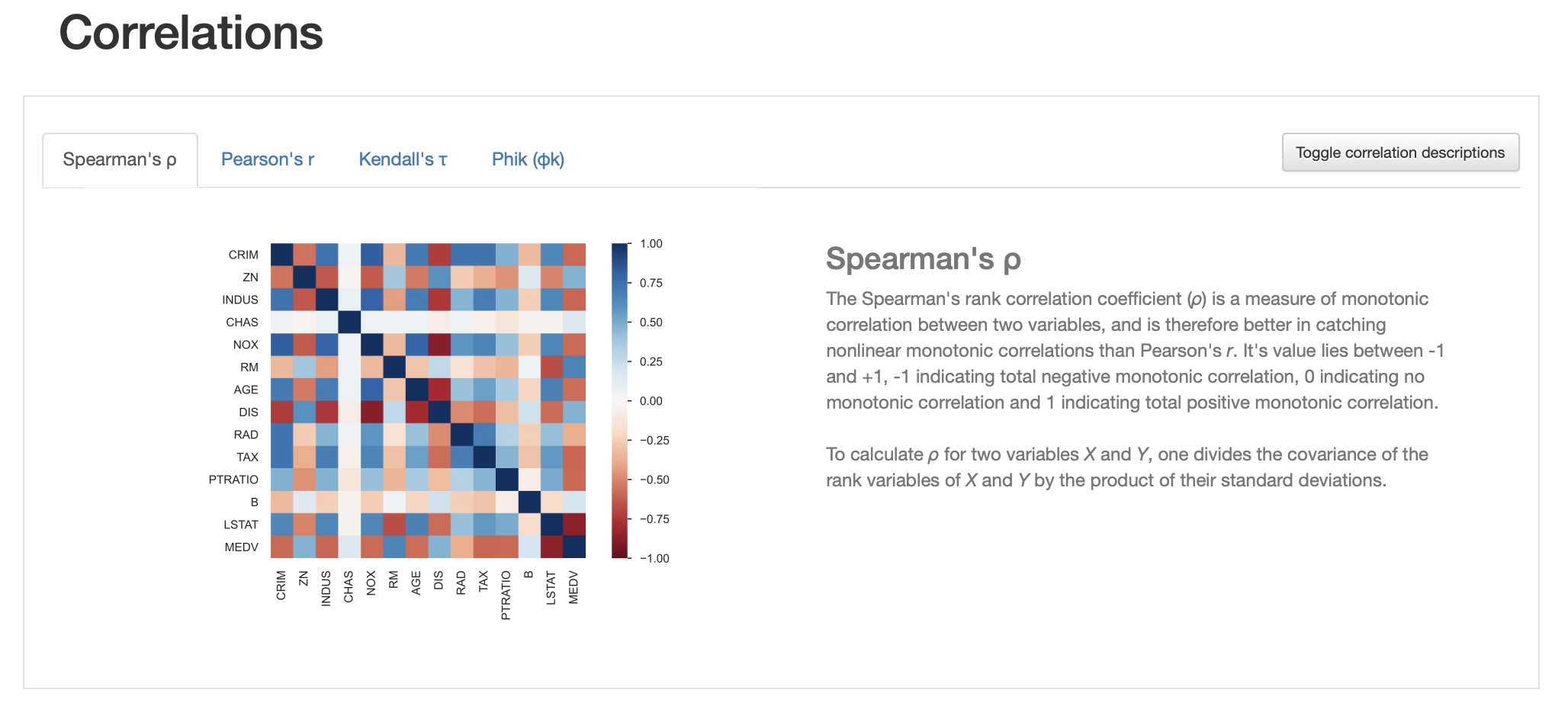
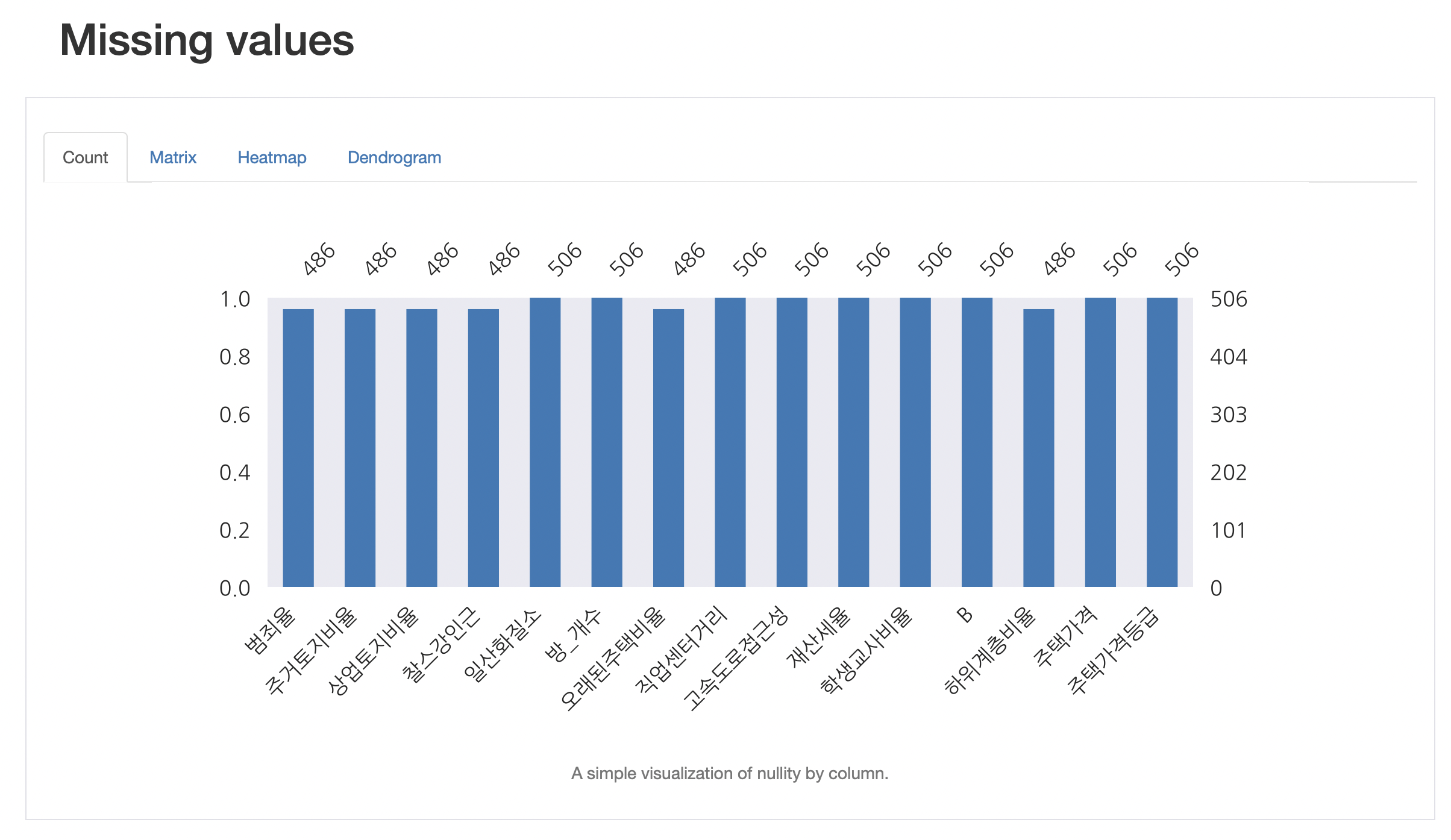
3-5. Missing Values
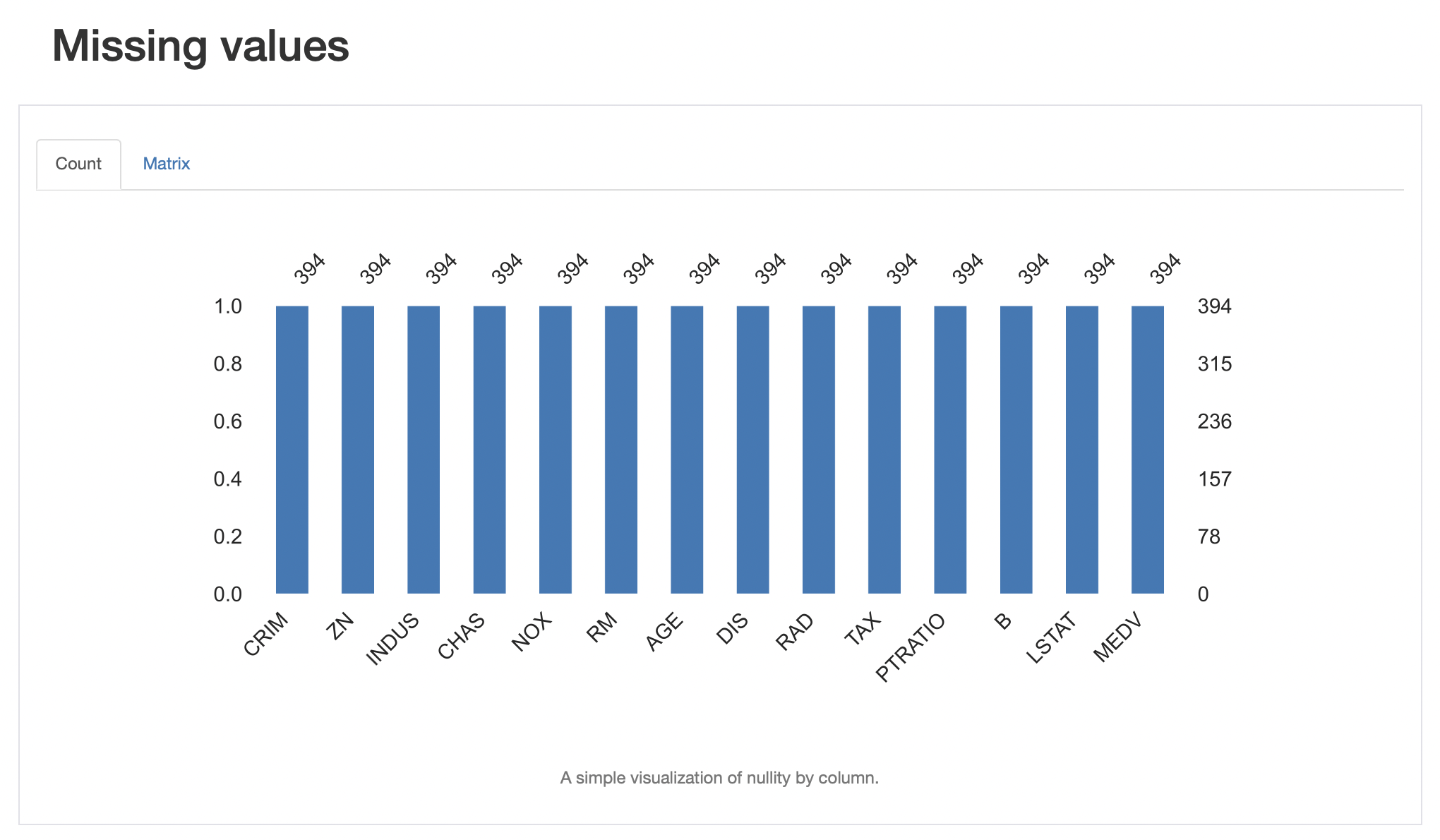
💡 결측치에 대한 통계이다.
결측치를 처리하는 방법은 2개가 있다.
- 행 삭제 : 결측치가 있는 행을 그냥 날려버림
- 값 대체 : 결측치의 자리를 최소 값, 최대 값, 평균 값, 0 등으로 채움
3-6. Samples
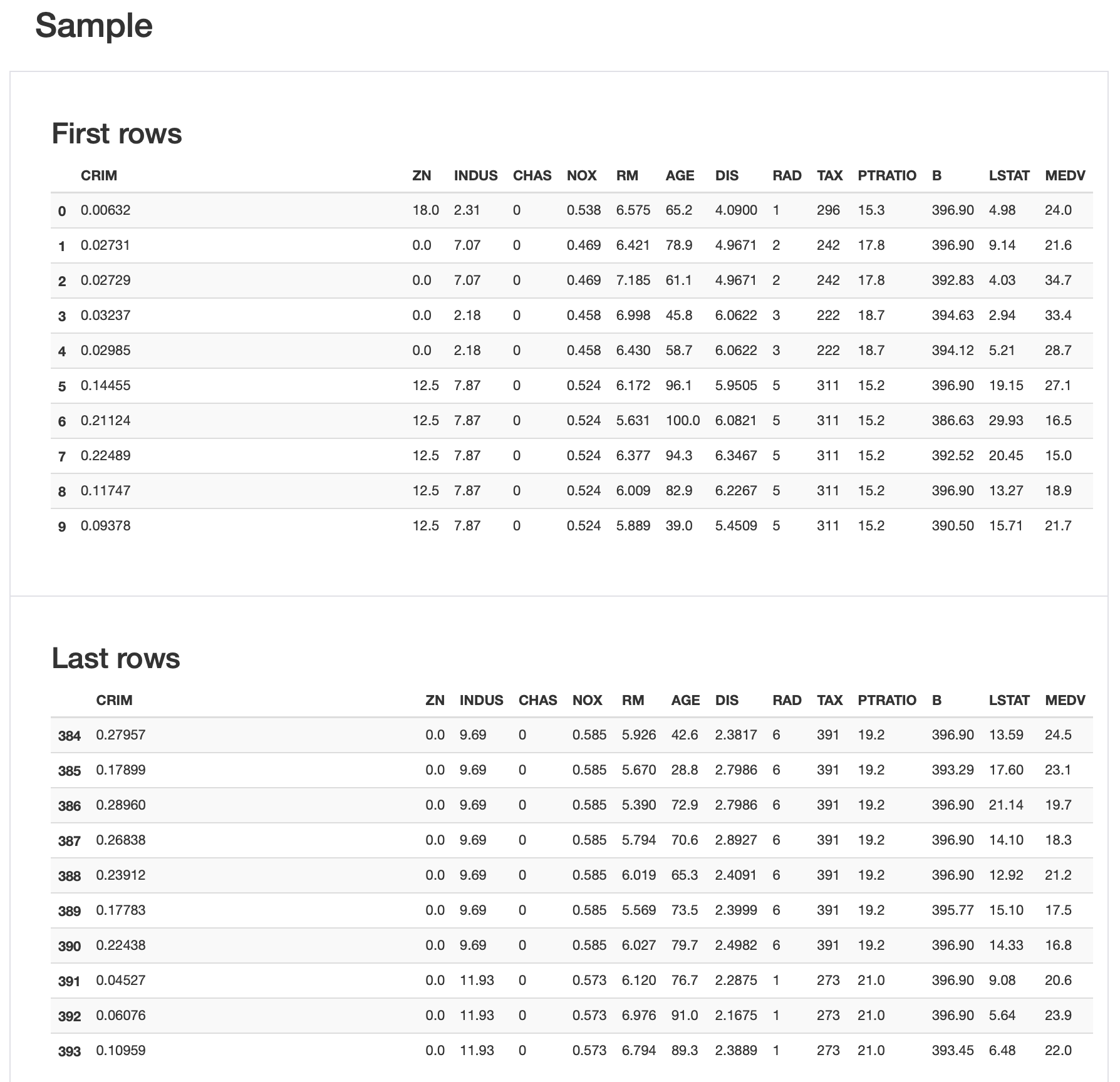
여기는 그냥 Dataframe의 head 10 과 tail 10 을 보여준다.
4. 독립 변수가 한글이라면?
이렇게 간략하게 pandas-profiling에 대해서 살펴보았다.
하지만, 가장 큰 문제가 있다.
지금은 독립 변수가 영어라서 잘 나오지만, 독립 변수가 한글로 이루어져 있으면 Correlation과 Missing Values 쪽에서 글자가 깨지게 된다.
이렇게.
하지만, 이건 해결 가능한 문제이다.
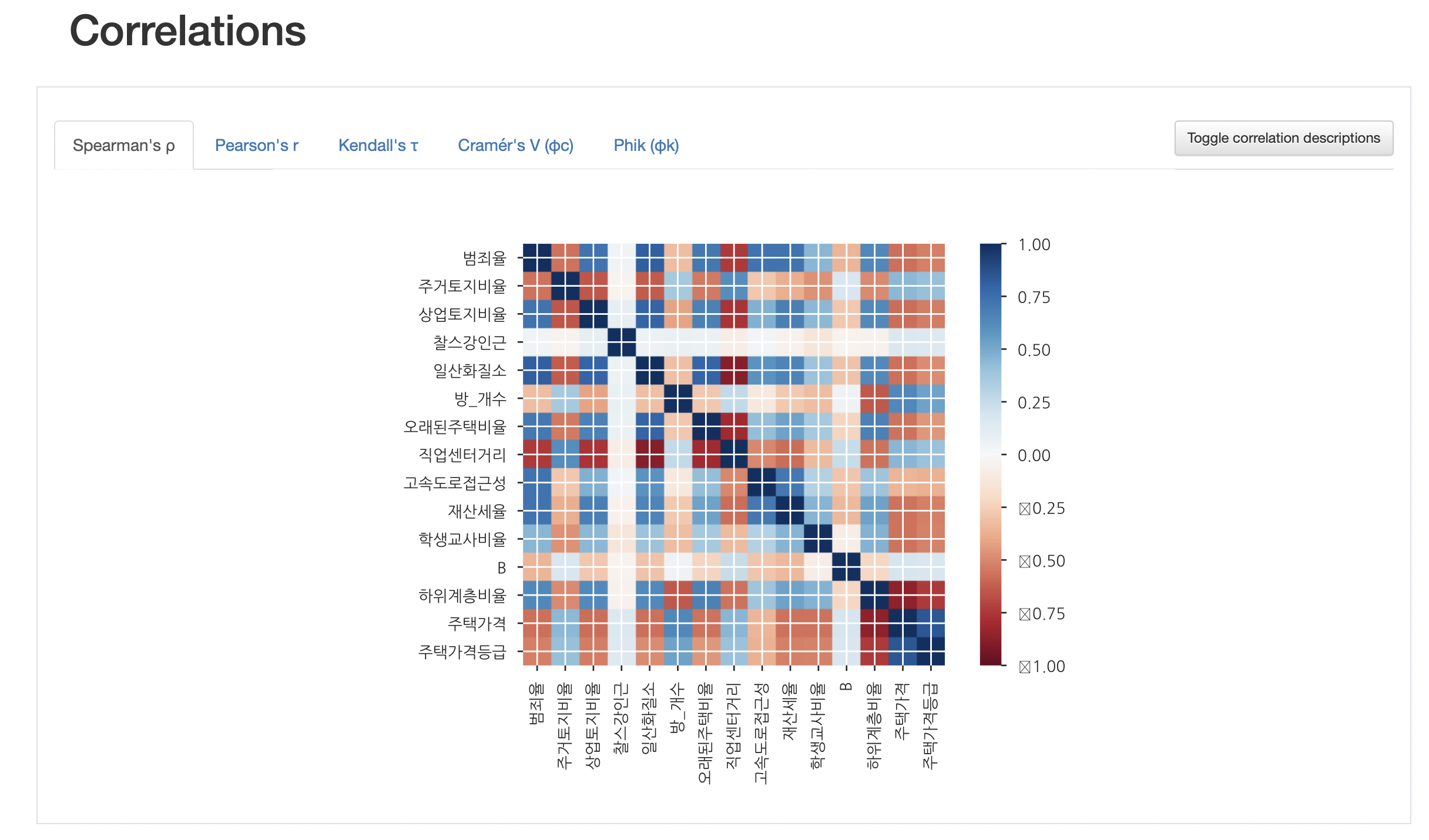
이렇게.
해당 정보에 대해서는 다음 포스팅을 살펴보자.
[ML] Pandas Profiling 한글 패치하기
