Apple Silicon에 PyTorch 설치하기
아마 2020년이었나… 애플 실리콘 아키텍쳐의 Macbook이 출시되었다.
나는 현재 M1 macbook pro를 쓰고있는데, 이전에는 anaconda도 안되서 mini-forge라는 걸 사용했었다.
그리고 그 mini-forge에는 말도 안되는 반쪽짜리 pytorch를 설치해서 사용했었다.
이 pytorch가 구동이 안되는 것은 아니다. 어찌어찌해서 설치해서 하면 뭔가 되긴했었는데 GPU 가속도 안되고 여러 제약사항이 있었다.
(물론 개발은 서버가 있기 때문에 딱히 상관은 없었는데… 가벼운 것이라도 잘 돌리고 싶긴 하니까?!)
하지만! 드디어
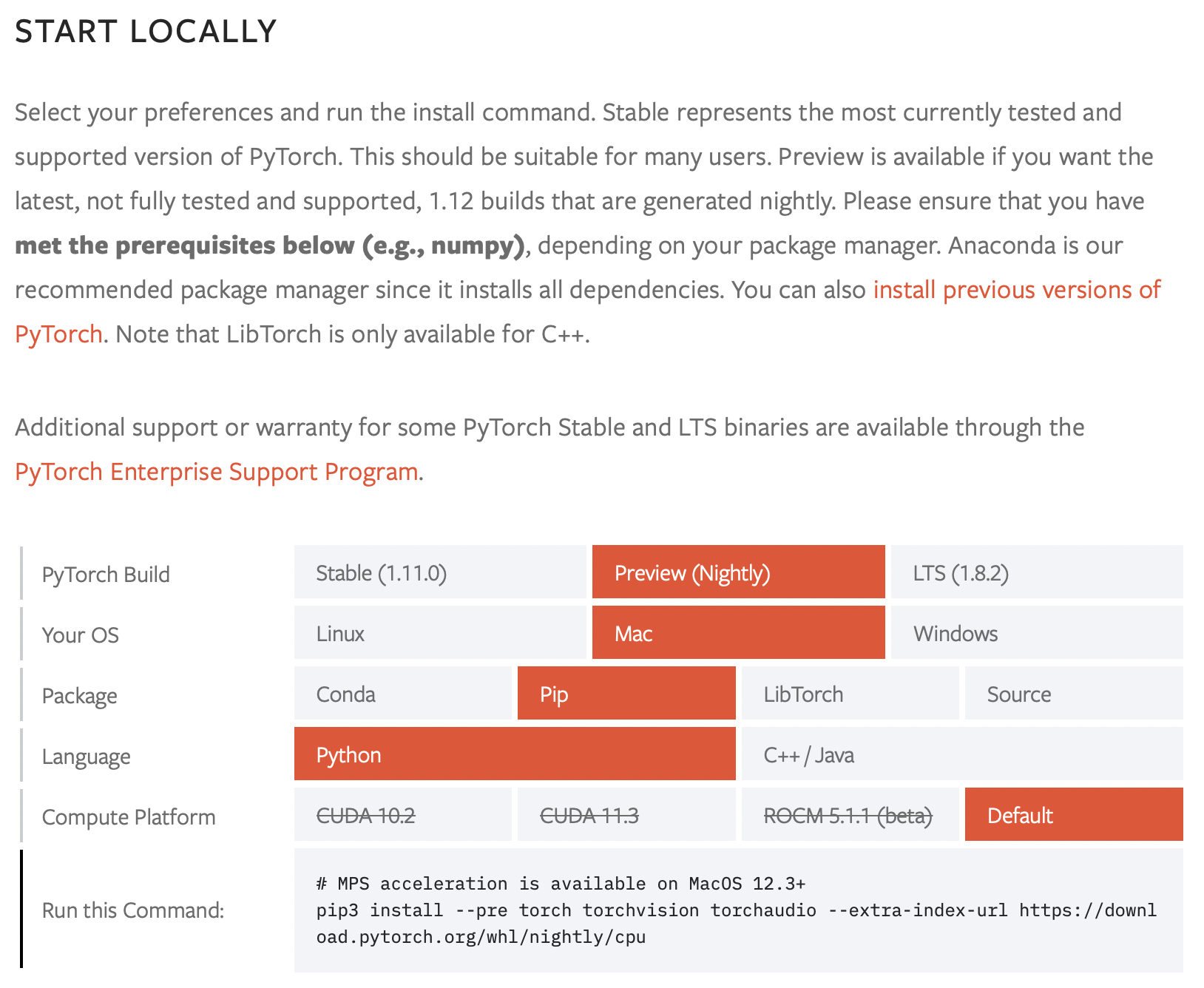
💡 Apple Silicon(M1) 을 위한 Anaconda 와 PyTorch가 정식 출시되었다!
- Pytorch 관련 기사 : Introducing Accelerated PyTorch Training on Mac
아직 Preview 버전이라는거니까 정식(?)은 아닌걸로…
1. Anaconda 설치
Anaconda 설치는 매우 쉽다. Anaconda 공식 홈페이지에서 pkg 파일을 다운로드 하여 그냥 더블클릭하고 설치하면 된다.
-
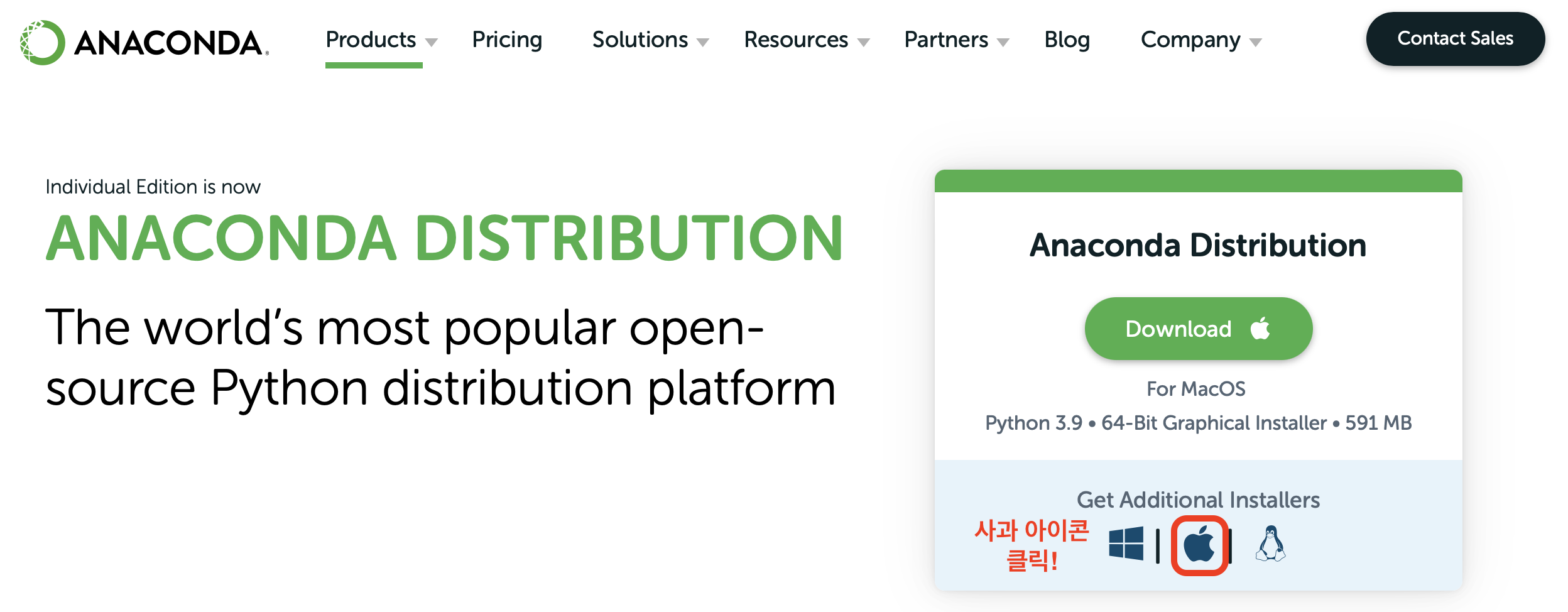
Anaconda download page 를 들어간다.
Anaconda | Anaconda Distribution -
사과 아이콘을 클릭한다. (맨 아래로 이동됨.)
-
맨 아래에서 64-Bit(M1) Graphical Installer (428MB) 를 클릭한다.

-
그러면 아래처럼 pkg 파일이 다운로드 된다. (arm64=apple silicon 아키텍쳐임.)
pkg 파일이 다운로드가 완료되면, 아래처럼 뭔가 경고도 뜨고 계약서 동의도 하고, 디스크 지정도 해줘야 한다.
| install-1 | install-2 | install-3 | install-4 |
|---|---|---|---|
 |  |  |  |
그리고는 설치하면 된다…
- 세팅도 자동으로 해줘서 매~우 편하다.
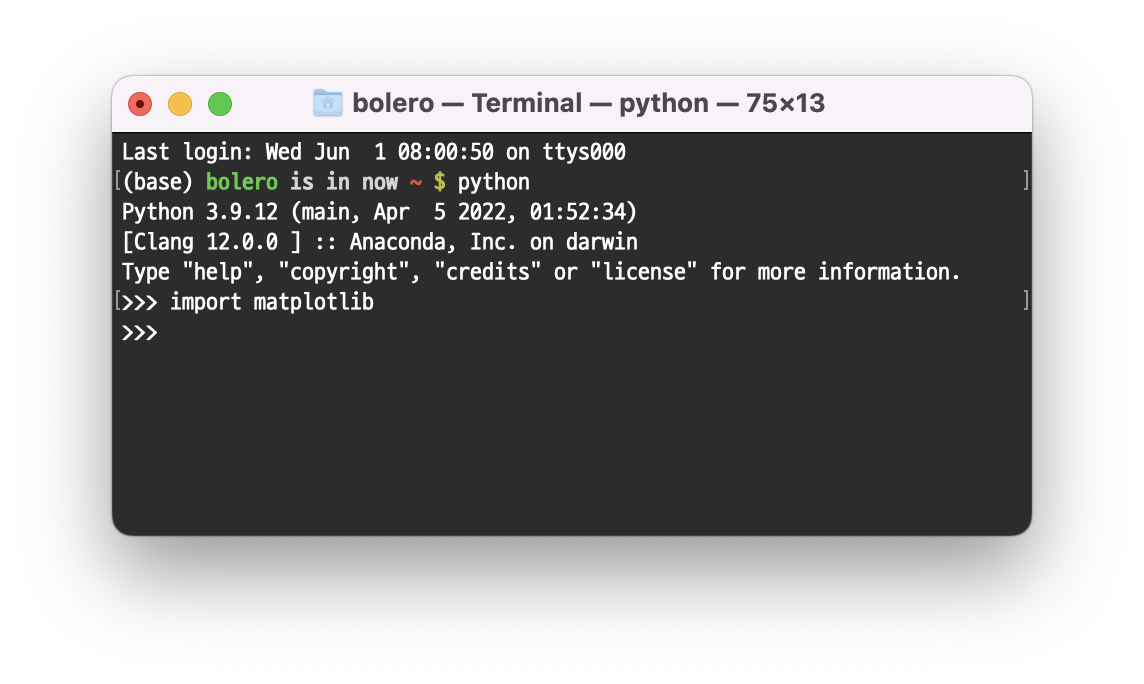
Anaconda 가 잘 뜨는지 확인하자.
matplotlib 패키지가 잘 import 되는 걸 보니 Anaconda가 틀림없다…
- conda init 세팅은
vi ~/.zshrc로 확인할 수 있다.
/Users/{username}/opt/anaconda3 에 실제 파일들이 들어있다.
삭제하고 싶으면 해당 폴더를 삭제해주자.
2. PyTorch 설치
Anaconda m1 버전을 잘 설치했으니, PyTorch를 설치해주자.
PyTorch 설치는 정말 매우 쉽다.
우선, https://pytorch.org/get-started/locally/ 로 가서 설치 커맨드를 알아야 한다.
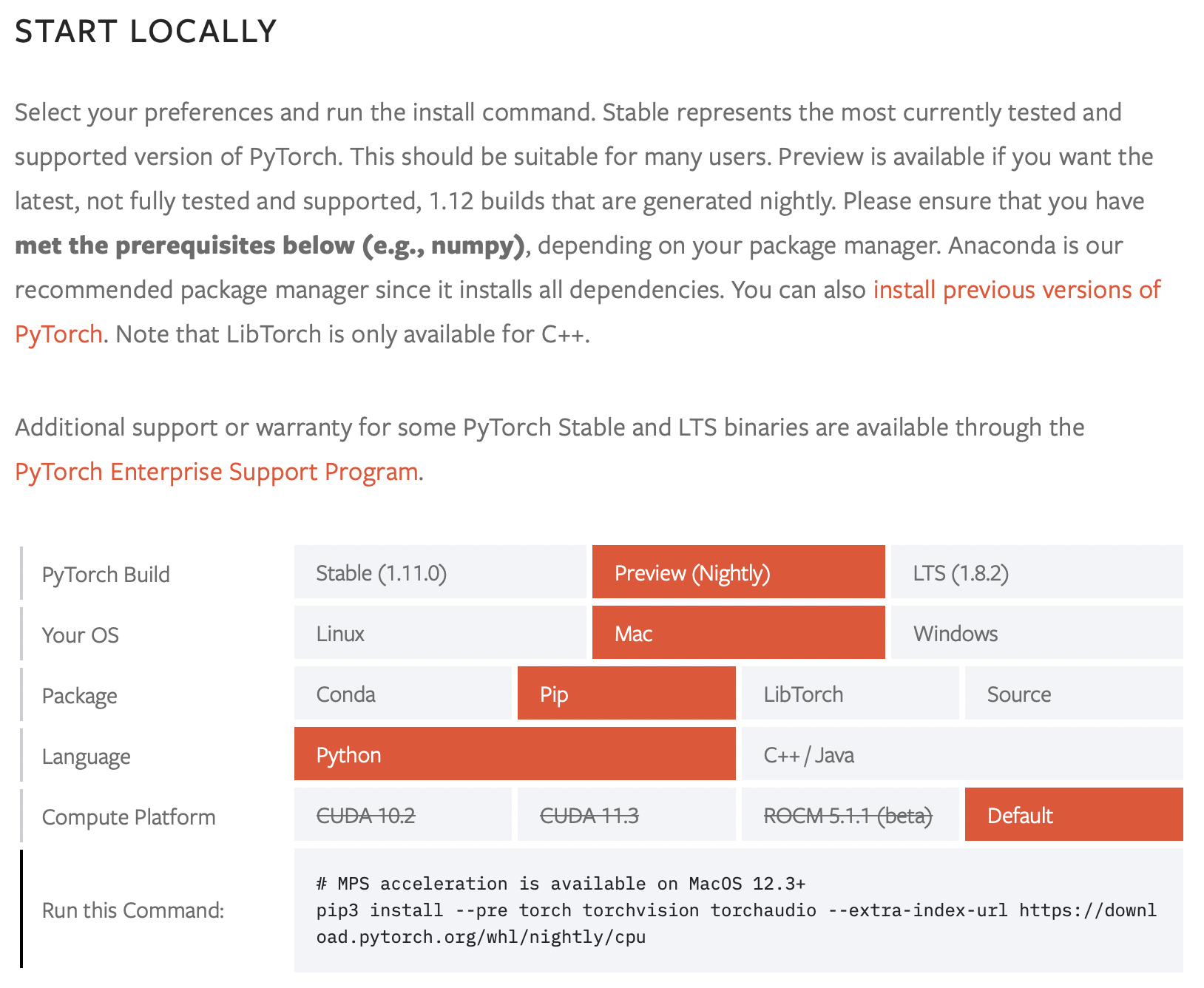
(아까 공식 칼럼에서 보았듯이, Nightly 버전으로 설치해야 한다.)
pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
로 설치하면 된다. 바로 설치해보자.
PyTorch 설치도 끝났다.
3. PyTorch in M1 - GPU Acceleration
일반적인 Nvidia gpu를 사용한다면 GPU 가속화를 위해 어떻게 해야 했을까.
import torch
device = torch.device('cuda:0')
print(f" - device : {device}")
sample = torch.Tensor([[10, 20, 30], [30, 20, 10]])
print(f" - cpu tensor : ")
print(sample)
sample = sample.to(device)
print(f" - gpu tensor : ")
print(sample)이렇게 하면 gpu 가속이 가능했다. (cuda:0번 gpu device에 tensor 할당)
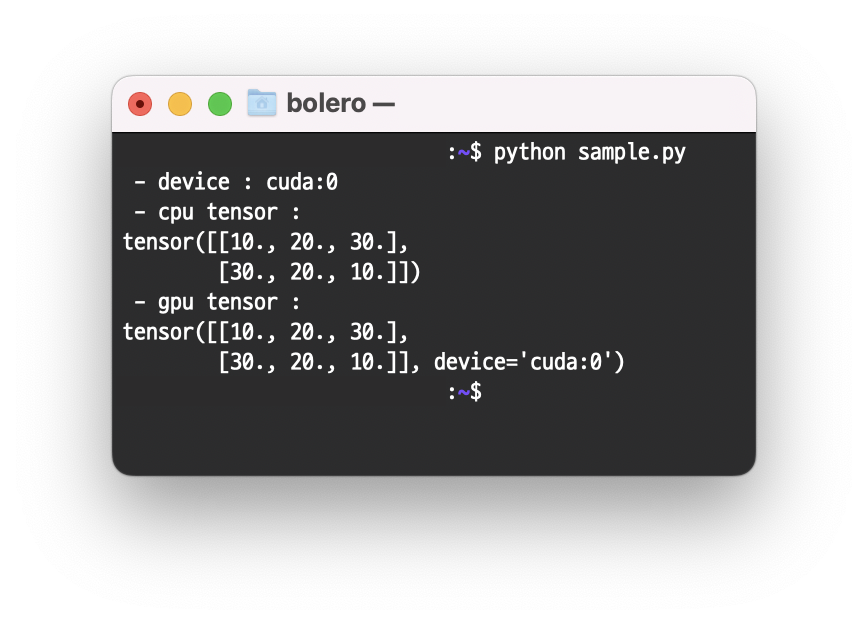
이렇게, gpu tensor 출력 부분의 device 쪽에 ‘cuda:0’이 잘 들어간 것을 볼 수 있다.
그렇다면 M1은 어디에 할당해줘야 할까?
M1 의 경우에는, ‘cuda’ 말고 ‘mps’에 할당해야 한다.
import torch
device = torch.device('mps')
print(f" - device : {device}")
sample = torch.Tensor([[10, 20, 30], [30, 20, 10]])
print(f" - cpu tensor : ")
print(sample)
sample = sample.to(device)
print(f" - gpu tensor : ")
print(sample)해당 스크립트를 실행하면
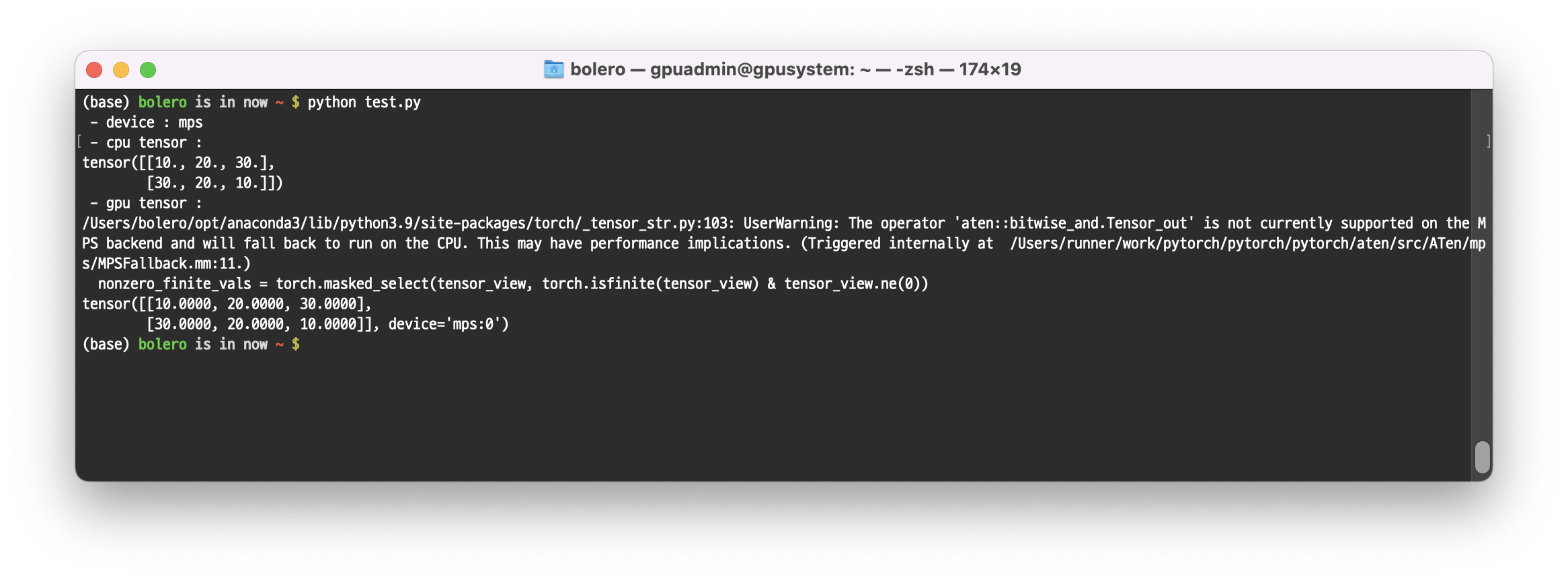
device= 쪽에 ‘cuda:0’ 이 아닌 ‘mps’ 가 들어가 있는 것을 확인할 수 있다.
4. Speed Comparison
속도 비교를 해보자.
당연히 nvidia gpu보다는 느릴 것으로 예상이 되긴 하지만… 얼마나 차이가 날까?
비교 대상은 총 4종류이다.
| Machine type | Name |
|---|---|
| Server GPU | Nvidia RTX A6000 |
| M1 GPU | M1 GPU, 8 Core |
| Server CPU | Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz * 40 Core |
| M1 CPU | M1 CPU |
간단하게 MNIST 데이터셋을 분류하는 torch 모델을 작성했다.
import time
import os
import datetime
import math
import numpy as np
import torch
from torch.nn.functional import softmax
from torch import nn
from torch import optim
import torchvision
import torchvision.transforms as transforms
# device setting, nvidia='cuda:0' | m1='mps' | cpu='cpu'
DEVICE = 'cuda:0' # "cuda:0" or "mps" or "cpu"
EPOCHS = 20
BATCH_SIZE = 16
LEARNING_RATE = 0.0001
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.num_classes = 10
self.ch = 1
self.conv1 = nn.Conv2d(self.ch, 128, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(128)
self.conv2 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.actv = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.dropout = nn.Dropout2d(p=0.5, inplace=False)
self.flatten = nn.Flatten()
self.fn1 = nn.Linear(7 * 7 * 256, 256)
self.fn2 = nn.Linear(256, 100)
self.fn3 = nn.Linear(100, self.num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.actv(x)
x = self.maxpool(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.actv(x)
x = self.maxpool(x)
x = self.dropout(x)
x = self.flatten(x)
x = self.fn1(x)
x = self.fn2(x)
x = self.fn3(x)
return softmax(x)
train_set = torchvision.datasets.MNIST(
root = './data/MNIST',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor() # 데이터를 0에서 255까지 있는 값을 0에서 1사이 값으로 변환
])
)
test_set = torchvision.datasets.MNIST(
root = './data/MNIST',
train = False,
download = True,
transform = transforms.Compose([
transforms.ToTensor() # 데이터를 0에서 255까지 있는 값을 0에서 1사이 값으로 변환
])
)
model = Model()
n_params = sum(p.numel() for p in model.parameters())
print("\n===== Model Architecture =====")
print(model, "\n")
print("\n===== Model Parameters =====")
print(" - {}".format(n_params), "\n\n")
train_loader = torch.utils.data.DataLoader(train_set, batch_size=BATCH_SIZE)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=BATCH_SIZE)
total_train_iter = math.ceil(len(train_set) / BATCH_SIZE)
total_valid_iter = math.ceil(len(test_set) / BATCH_SIZE)
device = torch.device(DEVICE)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
model.to(device)
train_start = time.time()
epochs_times = []
print("\n\nTraining start time : {}\n\n".format(datetime.datetime.now()))
for epoch in range(EPOCHS):
epoch_start = time.time()
train_loss, train_acc = 0.0, 0.0
for step, data in enumerate(train_loader):
iter_start = time.time()
model.train()
image, target = data
image = image.to(device)
target = target.to(device)
out = model(image)
acc = (torch.max(out, 1)[1].cpu().numpy() == target.cpu().numpy())
acc = float(np.count_nonzero(acc) / BATCH_SIZE)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += acc
if step % int(total_train_iter / 2) == 0:
print("[train %5s/%5s] Epoch: %4s | Time: %6.2fs | loss: %10.4f | Acc: %10.4f" % (
step + 1, total_train_iter, epoch + 1, time.time() - iter_start, round(loss.item(), 4), float(acc)))
train_loss = train_loss / total_train_iter
train_acc = train_acc / total_train_iter
epoch_runtime = time.time() - epoch_start
print("[Epoch {} training Ended] > Time: {:.2}s/epoch | Loss: {:.4f} | Acc: {:g}\n".format(
epoch + 1, epoch_runtime, np.mean(train_loss), train_acc))
epochs_times.append(epoch_runtime)
program_runtime = time.time() - train_start
print("\n\nTraining running time : {:.2}\n\n".format(program_runtime))
epochs_times = list(map(str, epochs_times))
epochs_times = list(map(lambda x: str(x) + "\n", epochs_times))
filename = os.path.basename(__file__).split('.')[0] + ".txt"
with open(filename, 'w') as f:
f.writelines(epochs_times)
print(f'save success epoch times! -> {filename}')4-1. M1 GPU vs Server GPU - 1 Epoch 경과 시간 비교
- M1 Macbook Pro
(base) bolero is in now ~ $ python m1_gpu.py
===== Model Architecture =====
Model(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(actv): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout2d(p=0.5, inplace=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fn1): Linear(in_features=12544, out_features=256, bias=True)
(fn2): Linear(in_features=256, out_features=100, bias=True)
(fn3): Linear(in_features=100, out_features=10, bias=True)
)
===== Model Parameters =====
- 3535446
Training start time : 2022-06-01 12:36:36.501451
/Users/bolero/m1_gpu.py:63: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return softmax(x)
[train 1/ 3750] Epoch: 1 | Time: 0.32s | loss: 2.3119 | Acc: 0.1250
[train 1876/ 3750] Epoch: 1 | Time: 0.03s | loss: 1.4933 | Acc: 0.9375
[Epoch 1 training Ended] > Time: 1.3e+02s/epoch | Loss: 1.5247 | Acc: 0.9397- Nvidia RTX A6000
(neural) NvidiaServer@NvidiaServer:~$ python server_gpu.py
===== Model Architecture =====
Model(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(actv): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout2d(p=0.5, inplace=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fn1): Linear(in_features=12544, out_features=256, bias=True)
(fn2): Linear(in_features=256, out_features=100, bias=True)
(fn3): Linear(in_features=100, out_features=10, bias=True)
)
===== Model Parameters =====
- 3535446
Training start time : 2022-06-01 03:36:49.959508
server_gpu.py:63: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return softmax(x)
[train 1/ 3750] Epoch: 1 | Time: 0.04s | loss: 2.3063 | Acc: 0.0000
[train 1876/ 3750] Epoch: 1 | Time: 0.01s | loss: 1.4613 | Acc: 1.0000
[Epoch 1 training Ended] > Time: 2.7e+01s/epoch | Loss: 1.5264 | Acc: 0.938167🧐 1 Epoch 까지만 봤을 때, Nvidia gpu 서버용(RTX A6000) 에서는 27초~28초/epoch가 걸렸고, m1 에서는 130초~140초/epoch가 걸렸다.
약 5배정도 차이나는데, 현재 서버용 GPU 가 너무 우월한 점도 있다.
4-2. M1 GPU vs Server CPU - 1 Epoch 경과 시간 비교
- M1 Macbook Pro
(base) bolero is in now ~ $ python m1_gpu.py
===== Model Architecture =====
Model(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(actv): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout2d(p=0.5, inplace=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fn1): Linear(in_features=12544, out_features=256, bias=True)
(fn2): Linear(in_features=256, out_features=100, bias=True)
(fn3): Linear(in_features=100, out_features=10, bias=True)
)
===== Model Parameters =====
- 3535446
Training start time : 2022-06-01 12:36:36.501451
/Users/bolero/m1_gpu.py:63: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return softmax(x)
[train 1/ 3750] Epoch: 1 | Time: 0.32s | loss: 2.3119 | Acc: 0.1250
[train 1876/ 3750] Epoch: 1 | Time: 0.03s | loss: 1.4933 | Acc: 0.9375
[Epoch 1 training Ended] > Time: 1.3e+02s/epoch | Loss: 1.5247 | Acc: 0.9397- Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz * 40 Core
(neural) NvidiaServer@NvidiaServer:~$ python server_cpu.py
===== Model Architecture =====
Model(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(actv): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout2d(p=0.5, inplace=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fn1): Linear(in_features=12544, out_features=256, bias=True)
(fn2): Linear(in_features=256, out_features=100, bias=True)
(fn3): Linear(in_features=100, out_features=10, bias=True)
)
===== Model Parameters =====
- 3535446
Training start time : 2022-06-01 03:37:22.395249
server_cpu.py:63: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return softmax(x)
[train 1/ 3750] Epoch: 1 | Time: 1.38s | loss: 2.3021 | Acc: 0.0625
[train 1876/ 3750] Epoch: 1 | Time: 0.04s | loss: 1.4617 | Acc: 1.0000
[Epoch 1 training Ended] > Time: 1.8e+02s/epoch | Loss: 1.5256 | Acc: 0.939617🧐 다행스럽게도(?) M1 GPU가 Server의 40 Core CPU보다는 빨랐다.
수치로 보자면 M1 GPU가 130초/epoch 정도 나오고, 40 Core CPU가 180초/epoch 정도 나온다. (약 1.4배정도 M1 GPU가 더 빠름)
4-3. M1 CPU vs M1 GPU - 1 Epoch 경과 시간 비교
- M1 Macbook Pro - CPU
(base) bolero is in now ~ $ python m1_cpu.py
===== Model Architecture =====
Model(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(actv): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout2d(p=0.5, inplace=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fn1): Linear(in_features=12544, out_features=256, bias=True)
(fn2): Linear(in_features=256, out_features=100, bias=True)
(fn3): Linear(in_features=100, out_features=10, bias=True)
)
===== Model Parameters =====
- 3535446
Training start time : 2022-06-01 12:36:37.141268
/Users/bolero/m1_cpu.py:63: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return softmax(x)
[train 1/ 3750] Epoch: 1 | Time: 0.09s | loss: 2.3023 | Acc: 0.1250
[train 1876/ 3750] Epoch: 1 | Time: 0.05s | loss: 1.4612 | Acc: 1.0000
[Epoch 1 training Ended] > Time: 1.7e+02s/epoch | Loss: 1.5262 | Acc: 0.938867- M1 Macbook Pro - GPU
(base) bolero is in now ~ $ python m1_gpu.py
===== Model Architecture =====
Model(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(actv): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout2d(p=0.5, inplace=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fn1): Linear(in_features=12544, out_features=256, bias=True)
(fn2): Linear(in_features=256, out_features=100, bias=True)
(fn3): Linear(in_features=100, out_features=10, bias=True)
)
===== Model Parameters =====
- 3535446
Training start time : 2022-06-01 12:36:36.501451
/Users/bolero/m1_gpu.py:63: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return softmax(x)
[train 1/ 3750] Epoch: 1 | Time: 0.32s | loss: 2.3119 | Acc: 0.1250
[train 1876/ 3750] Epoch: 1 | Time: 0.03s | loss: 1.4933 | Acc: 0.9375
[Epoch 1 training Ended] > Time: 1.3e+02s/epoch | Loss: 1.5247 | Acc: 0.9397🧐 솔직히 M1-CPU 나 M1-GPU 나 뭔가 코딩 잘못했을 줄 알고 기대 안했는데, 의외로 차이가 발생했다.
M1-CPU가 170초~180초/epoch 정도 나오고, M1-GPU는 130초/epoch 정도 나오는데, M1-CPU 의 수준이 Intel Xeon 4210R 2.40GHz 40 Core 정도의 수준을 보였다.
결론은… M1-GPU 는 엄청 쓸 정도는 아니다 아직! 그래도 CPU보다는 나으니 간단한 테스팅 정도는 무리없이 돌릴 수 있을 것으로 예상됨.
(단점은, 아까 실험해봤는데 image_size=[224, 224] 로 하고 batch_size=64 로 하니까 macbook에 5~7초마다 쓰로틀링이 발생했다…🥲)
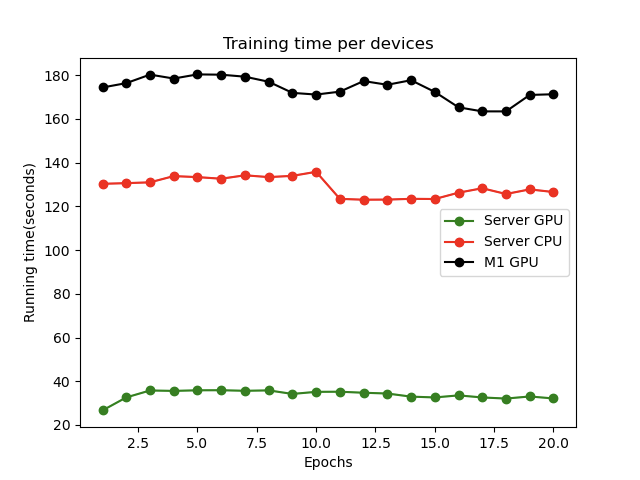
학습 종료 때 실험 방식 별 매 Epoch의 소요시간을 저장하는데, 그래프로 그려보는 걸로 포스팅을 마무리 하겠다.
(server CPU는 서버 머신의 다른 작업때문에 20 Epochs까지 측정하지 못함.)
소스코드
from matplotlib import pyplot as plt
server_gpu = [0 for x in range(0, 20)]
m1_gpu = [0 for x in range(0, 20)]
m1_cpu = [0 for x in range(0, 20)]
epochs = [x for x in range(1, 21)]
with open("server_gpu.txt", 'r') as f:
server_gpu = f.readlines()
server_gpu = list(map(float, server_gpu))
with open("m1_gpu.txt", 'r') as f:
m1_gpu = f.readlines()
m1_gpu = list(map(float, m1_gpu))
with open("m1_cpu.txt", 'r') as f:
m1_cpu = f.readlines()
m1_cpu = list(map(float, m1_cpu))
plt.figure()
plt.title('Training time per devices')
plt.plot(epochs, server_gpu, marker='o', color='green')
plt.plot(epochs, m1_gpu, marker='o', color='red')
plt.plot(epochs, m1_cpu, marker='o', color='black')
plt.legend(['Server GPU', 'Server CPU', 'M1 GPU', 'M1 CPU'])
plt.xlabel("Epochs")
plt.ylabel("Running time(seconds)")
# plt.show()
plt.savefig("runtime.png")결과 이미지

12개의 댓글

오 정보감사합니다 오늘 m1 max(cpu 10 gpu 32)구입하였는데 이제 anaconda에서도 지원을 하는군요 3090 25초 5900x (올코어 43배수고정상태) 170초나왔습니다 m1 max도 세팅 끝나면 같은 코드로 돌려볼게요 근데 m1 pro 코어 갯수가 정확히 어떻게 될까요?


맥미니 m2 pro 베이스모델로 구매하고 위에 코드 바로 돌려봤습니다 ㅎㅎ 첫번째 epoch은 49초 나오고, 그 다음 epoch 부터는 44초 나오네요! (python 3.11, pytorch 2.1.1 환경이었습니다)
안녕하세요!!
딥러닝 공부하고 있는 학생입니다.
이번에 새로 m1 맥북 프로를 구매하여서 아나콘다를 설치하고 있는데, 파일은 설치가 되는데 아나콘다 어플이 보이지가 않아서 찾아보다가 도저히 모르겠어서 댓글 남깁니다.