0. Intro
Python을 사용하여 Crawling 할 때는, 보통
requests패키지beautifulsoup패키지
이 2개 패키지를 활용하여 대부분 하게 될 것이다.
하지만, 만약에 어떤 값을 크롤링을 하고자 하는데, soup.find('div', class_='abcd') 이렇게 해도 도저히 값이 보이지 않는다면? 그 부분은 동적 페이지일 가능성이 매우 크다.
위에서 언급한 2개의 패키지는 정적 페이지 크롤링할 때 사용되는 패키지이다.
하지만, 동적 페이지(ajax, js를 쓰는 경우)는 Selenium을 사용하여 마치 사람이 직접 개발자 도구에서 보는 방식처럼 크롤링을 할 수 있다.
나는 총 2개의 환경에서 테스트를 해보았다.
- Safari (MacOS)
- Firefox (ubuntu, WSL2의 ubuntu에서도 가능함.)
그리고, 이 게시글의 댓글 부분을 Crawling 할 것이다(dcinside 식물 갤러리) : https://gall.dcinside.com/board/view/?id=tree&no=498770&page=1
(dcinside 제태크 쪽의 글들을 크롤링할 일이 있었는데, dcinside의 posting 자체는 정적 페이지이지만 댓글 부분은 동적 페이지였다.)
- 참고 - Selenium official docs : https://www.selenium.dev/documentation/
1. Before Development
이제, Selenium을 사용하여 크롤링을 해보자.
- 만약 MacOS를 쓴다면 무조건 Safari를 쓰는 것을 추천한다.
: Safari 브라우저가 MacOS에 최적화 되어있기도 하지만, Chrome이나 Firefox처럼 뭔가 option 값을 설정해주지 않아도 된다. - Linux 혹은 Windows의 WSL(Windows Subsystem for Linux)을 사용하는 Linux Dist를 쓴다면, Chrome browser 보다는 Firefox를 추천한다.
: Chrome browser를 사용하려고 여러 시도를 해봤지만, 엄청난 오류투성이에 결국 백기를 들고 Firefox를 시도했는데, 10분만에 성공해버렸다...!
1-1. Installation
Selenium 설치는 간단하다. pip install selenium 으로 설치해주자.
그리고, webdriver_manager 패키지도 설치하는 것을 추천한다.
pip install seleniumpip install webdriver_manager
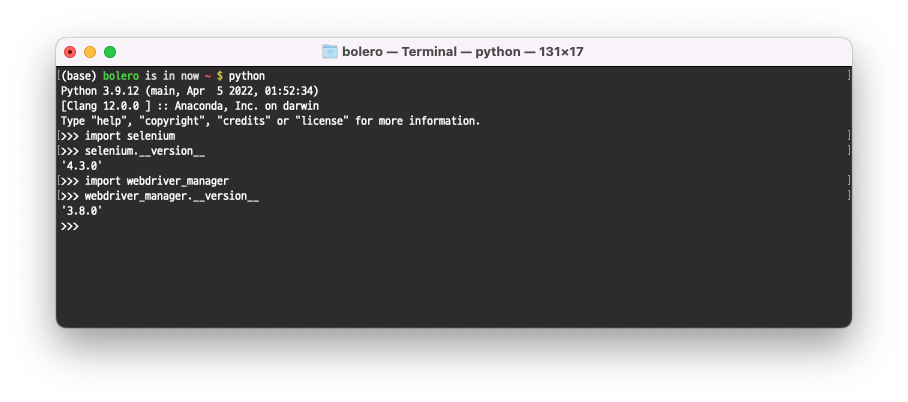
python prompt를 켜서 import 와 __version__ 이 잘 되면 설치는 완료된 것이다.
1-2. Crawling 부분 살펴보기
위의 게시글에서, 댓글 부분의 구조를 살펴보자.
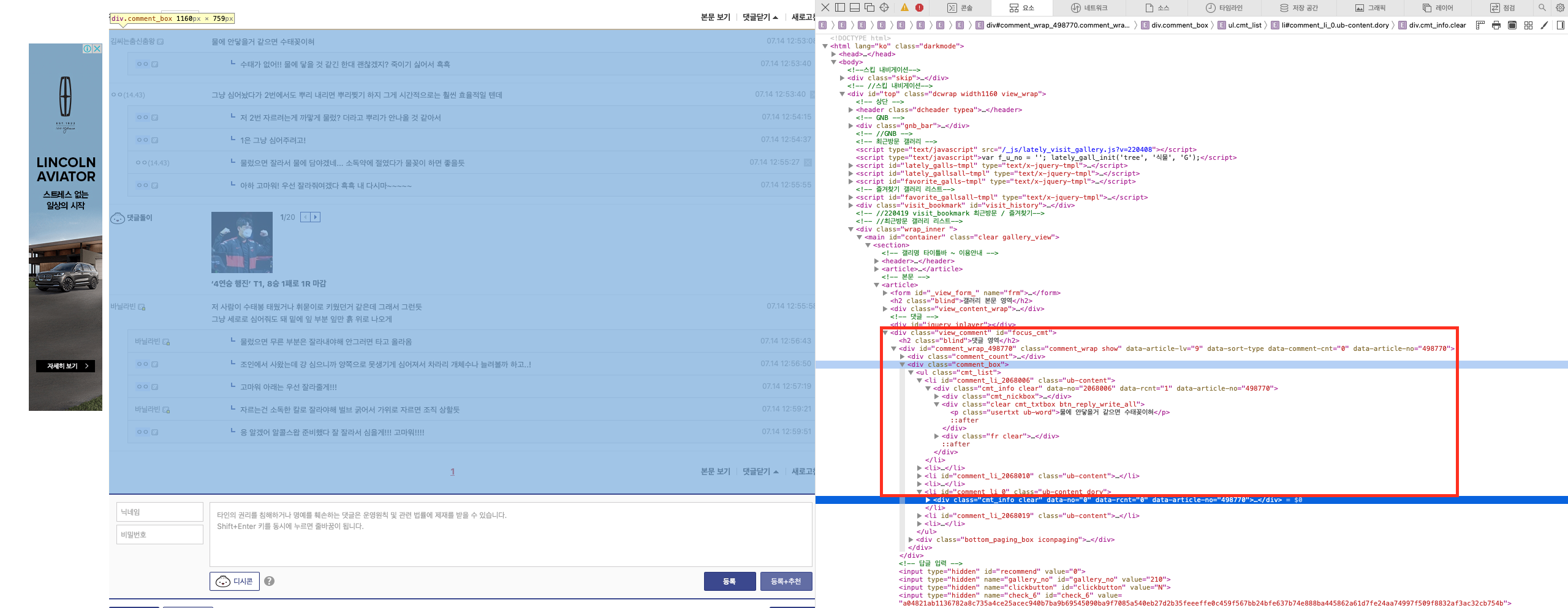
이렇게, 개발자 도구(Safari라면 우클릭 > 요소 점검)를 통해서 해당 부분에 대한 html 코드를 살펴볼 수 있다.
살펴보니, 구조가 아래처럼 되어있다.
- div tag + comment_box class
- ul tag + cmt_list class
- (실제 댓글) p tag + usertxt class
- ul tag + cmt_list class
이 정도로 구조를 파악하고, 실제 코드를 작성해보자.
2. Development
Selenium 패키지를 사용해서, 어떠한 게시물 내에서 댓글 부분을 전부 가져오는 코드를 작성해보자.
2-1. Safari Browser
첫 번째는 MacOS의 사파리 브라우저 이다.
Safari 브라우저는 기본적으로 webdriver가 기기 자체에 내장되어 있다.
Chrome이나 Firefox는 그 브라우저와 브라우저 버전에 맞는 driver를 다운로드하여 $PATH 부분에 넣어줘야 하는데, Safari는 그럴 필요가 없다.
우리가 해줘야 할 것은 딱 하나가 있다.
Safari 브라우저를 실행하고, 맨 위에 보면 파일, 편집 등의 toolbar가 있는데, 여기에 개발자용 > 원격 자동화 허용 을 켜줘야 한다.
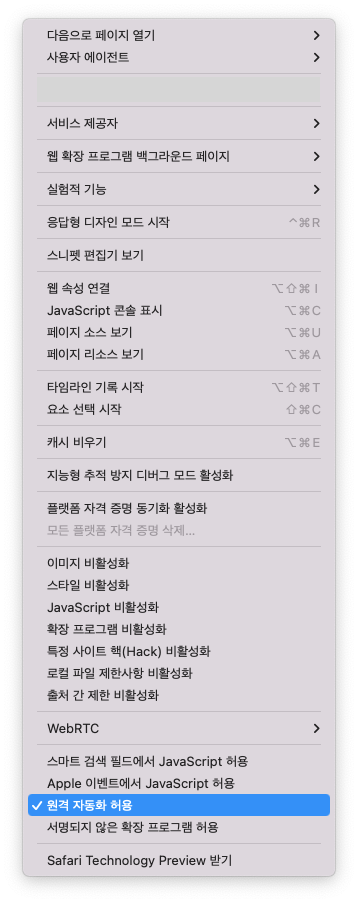
이걸 해주면, 세팅은 끝났다.
코드를 작성해보자.
- 코드 :
seleniumtest.py
from selenium import webdriver
url = "https://gall.dcinside.com/board/view/?id=tree&no=498770&page=1"
browser = webdriver.Safari()
browser.get(url)이렇게 작성하고, python seleniumtest.py 를 입력하면 webdriver의 세션이 작동된다.

웹 드라이버가 잘 열리는 것을 확인했으니, 우리가 원하는 댓글을 크롤링해보자.
위의 코드에 아래 부분을 추가해준다.
- 댓글 크롤링 부분
from selenium.webdriver.common.by import By
html_comments = browser.find_elements(By.CLASS_NAME, "usertxt")
for comment in html_comments:
print(comment.text)browser 객체에서 우리가 실제 보고자 하는 댓글은 usertxt 클래스 부분이므로, find_elements 메소드로 해당 부분을 전부 다 가져오도록 하자.
find_elements는 위의 클래스 이름을 가지고 있는 모든 부분을 가져온다. 이는list type을 반환하고,
만약s가 없는find_element메소드를 사용한다면 해당 클래스 이름을 가진 바로 다음 것 1개만을 가져온다.find_elements부분에서 댓글이 없는 경우에는 빈 리스트가 반환된다.html_comments는html object의 일부분이라고 생각하면 된다. 여기서.text를 사용해서 실제 text 부분만 가져올 수 있다.

이렇게 해서, Safari browser를 사용하여 동적 크롤링을 할 수 있었다.
2-2. Firefox browser
Firefox는 아마 ubuntu machine에는 자동으로 깔려있겠지만, WSL의 ubuntu의 경우에는 깔려있지 않을 것이다.
sudo apt install firefox 로 firefox부터 설치하자.
그리고 터미널에 firefox를 쳐서, 터미널에 명령어가 잘 인식이 된다면 firefox 브라우저가 잘 설치된 것이다.
(WSL의 경우에는 DISPLAY가 별도의 작업으로 설정한 것이 아니라면, CLI 화면만 보일것이다. 하지만 크롤링 자체에는 문제가 되지 않는다.)
Firefox는 Safari와 다르게 webdriver를 설치해줘야 된다.
mozilla github 사이트에서 geckodriver 를 다운로드하자.
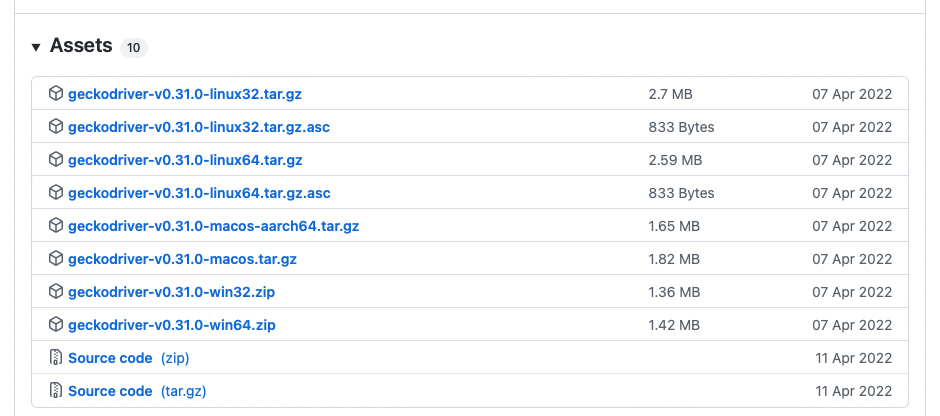
geckodriver-v0.31.0-linux64.tar.gz 를 다운로드 하면 될 것이다.
해당 압축파일을 다운로드받고, 압축을 풀면 geckodriver 파일이 하나 있는데, 해당 파일을 echo $PATH 를 쳤을 때 나오는 경로에 집어넣어야 한다.
(나는 /usr/bin 아래에 넣어두었다.)
이제 코드를 살펴보자.
- 코드
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver import FirefoxOptions
url = "https://gall.dcinside.com/board/view/?id=tree&no=498770&page=1"
webdriver_service = Service('/usr/bin/geckodriver')
opts = FirefoxOptions()
opts.add_argument("--headless") # turn off GUI
browser = webdriver.Firefox(service=webdriver_service, options=opts)
browser.get(url)
html_comments = browser.find_elements(By.CLASS_NAME, "usertxt")
for comment in html_comments:
print(comment.text)이렇게 하면 firefox로 동적 페이지 크롤링이 가능하다.
(결과는 Safari 때와 동일함.)
Safari와 다른점은
- webdriver를 설정해주어야 한다 : MacOS의 Safari는 자동으로 해주지만, Chrome이나 Firefox는
webdriver_service = Service('/usr/bin/geckodriver')와 같이 직접 webdriver 를 설정해주어야 한다. --headless옵션을 주어야 한다 : WSL이나 서버용 ubuntu 의 경우에는 GUI display 가 없다. (X-server 같은 걸 써도 되지만, 귀찮으니까...)- 위의 정보들을 이제
webdriver.Firefox()함수 내에 적절한 인자로 집어넣어주어야 한다.
정도가 되겠다.
3. End
이렇게, Safari와 Firefox를 사용해서 동적 페이지 크롤링에 대해서 간단하게 알아보았다.
- 만약 실험 중에 잘 안되는 경우는 댓글 부탁드립니다!
- Firefox, WSL 같은 경우는 root user인지도 중요하고, 여러 조건들이 까다롭기 때문에 잘 안되는 경우도 있습니다.
댓글로 말씀주시면 제가 테스트는 해볼 수 있습니다!

2개의 댓글

chrome이 잘 안된건 아마 chrome driver가 기본으로 제공하는 버전이 arm64기반의 M1칩을 지원하지 않아서 일거에요. arm64 용으로 컴파일된 chrome driver를 사용하면 됩니다.
사파리 창 열리고 나서 바로 꺼지던데 추가 설정해야하는 부분이 있을까요?